Microsoft Entra ID(이전의 Azure Active Directory) 자격 증명 통과를 사용하여 Azure Data Lake Storage에 액세스(레거시)
Important
이 설명서는 사용 중지되었으며 업데이트되지 않을 수 있습니다.
자격 증명 통과는 Databricks Runtime 15.0부터 사용되지 않으며 이후 Databricks 런타임 버전에서 제거됩니다. Databricks는 Unity 카탈로그로 업그레이드하는 것을 권장합니다. Unity 카탈로그는 계정의 여러 작업 영역에서 데이터 액세스를 관리 및 감사할 수 있는 중앙 위치를 제공하여 데이터 보안 및 거버넌스를 단순화합니다. Unity 카탈로그란?을 참조하세요.
보안 및 거버넌스 태세를 강화하려면 Azure Databricks 계정 팀에 문의하여 Azure Databricks 계정에서 자격 증명 통과를 사용하지 않도록 설정합니다.
참고 항목
이 문서에는 Azure Databricks에서 사용하지 않는 용어인 허용 목록에 대한 참조가 포함되어 있습니다. 소프트웨어에서 용어가 제거되면 이 문서에서 해당 용어가 제거됩니다.
Azure Databricks에 로그인하는 데 사용하는 것과 동일한 Microsoft Entra ID(이전의 Azure Active Directory) ID를 사용하여 Azure Databricks (ADLS Gen1) 및 Azure Databricks 클러스터의 ADLS Gen2 에서 Azure Data Lake Storage Gen1에 자동으로 인증할 수 있습니다. 클러스터를 Azure Data Lake Storage 자격 증명 통과에 사용하도록 설정하면 스토리지에 액세스하기 위해 서비스 주체 자격 증명을 구성하지 않고도 해당 클러스터에서 실행하는 명령을 통해 Azure Data Lake Storage에서 데이터를 읽고 쓸 수 있습니다.
Azure Data Lake Storage 자격 증명 통과는 Azure Data Lake Storage Gen1 및 Gen2에서만 지원됩니다. Azure Blob Storage는 자격 증명 통과를 지원하지 않습니다.
이 문서에서 다루는 내용:
- 표준 및 높은 동시성 클러스터에 대한 자격 증명 통과를 사용하도록 설정합니다.
- ADLS 계정에서 자격 증명 통과 구성 및 스토리지 리소스를 초기화합니다.
- 자격 증명 통과를 사용하는 경우 ADLS 리소스에 직접 액세스합니다.
- 자격 증명 통과를 사용하는 경우 탑재 지점을 통해 ADLS 리소스에 액세스합니다.
- 자격 증명 통과를 사용할 때 지원되는 기능 및 제한 사항입니다.
Notebook은 ADLS Gen1 및 ADLS Gen2 스토리지 계정에서 자격 증명 통과를 사용하는 예제를 제공하기 위해 포함됩니다.
요구 사항
- 프리미엄 플랜. 표준 요금제를 프리미엄 요금제로 업그레이드하는 방법에 대한 자세한 내용은 Azure Databricks Workspace 업그레이드 또는 다운그레이드를 참조하세요.
- Azure Data Lake Storage Gen1 또는 Gen2 스토리지 계정. Azure Data Lake Storage Gen2 스토리지 계정은 계층 구조 네임스페이스를 사용하여 Azure Data Lake Storage 자격 증명 통과에서 작동해야 합니다. 계층 구조 네임스페이스를 사용하도록 설정하는 방법을 포함하여 새 ADLS Gen2 계정을 만드는 방법에 대한 지침은 스토리지 계정 만들기를 참조하세요.
- Azure Data Lake Storage에 대한 사용자 권한을 올바르게 구성했습니다. Azure Databricks 관리자는 사용자에게 Azure Data Lake Storage에 저장된 데이터를 읽고 쓸 수 있는 올바른 역할(예: Storage Blob Data Contributor)이 있는지 확인해야 합니다. Azure Portal을 사용하여 Blob 및 큐 데이터에 액세스하기 위한 Azure 역할 할당을 참조하세요.
- 통과에 사용할 수 있는 작업 영역에서 작업 영역 관리자의 권한을 이해하고 기존 작업 영역 관리자 할당을 검토합니다. 작업 영역 관리자는 사용자 및 서비스 주체 추가, 클러스터 만들기 및 다른 사용자를 작업 영역 관리자로 위임하는 등 작업 영역에 대한 작업을 관리할 수 있습니다. 작업 소유권 관리 및 Notebook 보기와 같은 작업 영역 관리 작업은 Azure Data Lake Storage에 등록된 데이터에 간접적으로 액세스할 수 있습니다. 작업 영역 관리자는 신중하게 배포해야 하는 권한 있는 역할입니다.
- ADLS 자격 증명(예: 서비스 주체 자격 증명)으로 구성된 클러스터를 자격 증명 통과와 함께 사용할 수 없습니다.
Important
Microsoft Entra ID에 대한 트래픽을 허용하도록 구성되지 않은 방화벽 뒤에 있는 경우 Microsoft Entra ID 자격 증명으로 Azure Data Lake Storage에 인증할 수 없습니다. Azure Firewall은 기본적으로 Active Directory 액세스를 차단합니다. 액세스를 허용하려면 AzureActiveDirectory 서비스 태그를 구성합니다. Azure IP 범위 및 서비스 태그 JSON 파일의 AzureActiveDirectory 태그 아래에서 네트워크 가상 어플라이언스에 대한 동등한 정보를 찾을 수 있습니다. 자세한 내용은 Azure Firewall 서비스 태그 및 퍼블릭 클라우드용 Azure IP 주소를 참조하세요.
로깅 권장 사항
Azure 스토리지 진단 로그에서 ADLS 스토리지로 전달된 ID를 기록할 수 있습니다. 로깅 ID를 사용하면 ADLS 요청을 Azure Databricks 클러스터의 개별 사용자에 연결할 수 있습니다. 스토리지 계정에서 진단 로깅을 켜서 다음 로그 수신을 시작합니다.
- Azure Data Lake Storage Gen1: Data Lake Storage Gen1 계정에 대한 진단 로깅 사용 지침을 따릅니다.
- Azure Data Lake Storage Gen2:
Set-AzStorageServiceLoggingProperty명령과 함께 PowerShell을 사용하여 구성합니다. 로그 항목 형식 2.0에는 요청에 사용자 계정 이름이 포함되어 있으므로 버전으로 2.0을 지정합니다.
동시성이 높은 클러스터는 여러 사용자가 공유할 수 있습니다. Azure Data Lake Storage 자격 증명 통과를 사용하여 Python과 SQL만 지원합니다.
Important
Azure Data Lake Storage 높은 동시성 클러스터에 대한 자격 증명 통과를 사용하도록 설정하면 포트 44, 53, 80을 제외한 클러스터의 모든 포트가 차단됩니다.
- 클러스터를 만들 때클러스터 모드를 높은 동시성으로 설정합니다.
- 고급 옵션에서 사용자 수준 데이터 액세스를 위한 자격 증명 통과를 사용하도록 설정 및 Python 및 SQL 명령만 허용을 선택합니다.

작업 영역에 대한 Azure Data Lake Storage 자격 증명 통과 사용
자격 증명 통과가 있는 표준 클러스터는 단일 사용자로 제한됩니다. 표준 클러스터는 Python, SQL, Scala 및 R을 지원합니다. Databricks Runtime 10.4 LTS 이상에서는 sparklyr가 지원됩니다.
클러스터를 만들 때 사용자를 할당해야 하지만 언제든지 CAN MANAGE 권한이 있는 사용자가 클러스터를 편집하여 원래 사용자를 바꿀 수 있습니다.
Important
클러스터에 할당된 사용자는 클러스터에서 명령을 실행하려면 적어도 클러스터에 대한 CAN ATTACH TO 권한이 있어야 합니다. 작업 영역 관리자와 클러스터 작성자는 CAN MANAGE 권한을 가지고 있지만 지정된 클러스터 사용자가 아니면 클러스터에서 명령을 실행할 수 없습니다.
- 클러스터를 만들 때클러스터 모드를 표준으로 설정합니다.
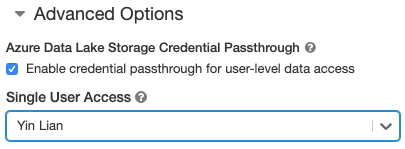
- 고급 옵션에서 사용자 수준 데이터 액세스에 대한 자격 증명 통과 사용을 선택하고 단일 사용자 액세스 드롭다운에서 사용자 이름을 선택합니다.
컨테이너 만들기
컨테이너는 Azure Storage 계정에서 개체를 구성하는 방법을 제공합니다.
Azure Data Lake Storage 자격 증명 통과를 구성하고 저장소 컨테이너를 만든 후에는 adl:// 경로를 사용하여 Azure Data Lake Storage Gen1의 데이터에 직접 액세스하고 abfss:// 경로를 사용하여 Azure Data Lake Storage Gen2에 액세스할 수 있습니다.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
<storage-account-name>을 ADLS Gen1 스토리지 계정 이름으로 바꿉니다.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
<container-name>을 ADLS Gen2 스토리지 계정의 컨테이너 이름으로 바꿉니다.<storage-account-name>을 ADLS Gen2 스토리지 계정 이름으로 바꿉니다.
Azure Data Lake Storage 계정 또는 그 안에 있는 폴더를 DBFS란?에 탑재할 수 있습니다. 탑재는 데이터 레이크 저장소에 대한 포인터이므로 데이터가 로컬로 동기화되지 않습니다.
Azure Data Lake Storage 자격 증명 통과로 사용하도록 설정된 클러스터를 사용하여 데이터를 탑재하는 경우 탑재 지점에 대한 모든 읽기 또는 쓰기는 Microsoft Entra ID 자격 증명을 사용합니다. 이 탑재 지점은 다른 사용자에게 표시되지만 다음과 같은 사용자에게만 읽기 및 쓰기 액세스 권한이 있습니다.
- 기본 Azure Data Lake Storage 스토리지 계정에 대한 액세스 권한이 있습니다.
- Azure Data Lake Storage 자격 증명 통과에 사용하도록 설정된 클러스터를 사용합니다.
Azure Data Lake Storage Gen1
Azure Data Lake Storage Gen1 리소스 또는 그 안에 폴더를 탑재하려면 다음 명령을 사용합니다.
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
<storage-account-name>을 ADLS Gen2 스토리지 계정 이름으로 바꿉니다.<mount-name>을 DBFS에서 의도한 탑재 지점 이름으로 바꿉니다.
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 파일 시스템 또는 그 안에 있는 폴더를 탑재하려면 다음 명령을 사용합니다.
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
<container-name>을 ADLS Gen2 스토리지 계정의 컨테이너 이름으로 바꿉니다.<storage-account-name>을 ADLS Gen2 스토리지 계정 이름으로 바꿉니다.<mount-name>을 DBFS에서 의도한 탑재 지점 이름으로 바꿉니다.
Warning
탑재 지점에 인증하기 위해 스토리지 계정 액세스 키 또는 서비스 주체 자격 증명을 제공하지 마세요. 그러면 다른 사용자가 해당 자격 증명을 사용하여 파일 시스템에 액세스할 수 있습니다. Azure Data Lake Storage 자격 증명 통과의 목적은 이러한 자격 증명을 사용하지 못하게 하고 파일 시스템에 대한 액세스가 기본 Azure Data Lake Storage 계정에 대한 액세스 권한이 있는 사용자로 제한되도록 하는 것입니다.
보안
Azure Data Lake Storage 자격 증명 통과 클러스터를 다른 사용자와 공유하는 것이 안전합니다. 서로 격리되며 서로의 자격 증명을 읽거나 사용할 수 없습니다.
지원되는 기능
| 기능 | 최소 Databricks Runtime 버전 | 주의 |
|---|---|---|
| Python 및 SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | 자격 증명은 DBFS 경로가 Azure Data Lake Storage Gen1 또는 Gen2의 위치로 확인되는 경우에만 전달됩니다. 다른 스토리지 시스템으로 확인되는 DBFS 경로의 경우 다른 방법을 사용하여 자격 증명을 지정합니다. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| 디스크 캐싱 | 5.5 | |
| PySpark ML API | 5.5 | 다음 ML 클래스는 지원되지 않습니다. * org/apache/spark/ml/classification/RandomForestClassifier* org/apache/spark/ml/clustering/BisectingKMeans* org/apache/spark/ml/clustering/GaussianMixture* org/spark/ml/clustering/KMeans* org/spark/ml/clustering/LDA* org/spark/ml/evaluation/ClusteringEvaluator* org/spark/ml/feature/HashingTF* org/spark/ml/feature/OneHotEncoder* org/spark/ml/feature/StopWordsRemover* org/spark/ml/feature/VectorIndexer* org/spark/ml/feature/VectorSizeHint* org/spark/ml/regression/IsotonicRegression* org/spark/ml/regression/RandomForestRegressor* org/spark/ml/util/DatasetUtils |
| 브로드캐스트 변수 | 5.5 | PySpark 내에서는 큰 UDF가 브로드캐스트 변수로 전송되므로 구성할 수 있는 Python UDF의 크기에 제한이 있습니다. |
| Notebook 범위 라이브러리 | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6.0 | |
| sparklyr | 10.1 | |
| 다른 Notebook에서 Databricks Notebook 실행 | 6.1 | |
| PySpark ML API | 6.1 | 모든 PySpark ML 클래스가 지원됩니다. |
| 클러스터 메트릭 | 6.1 | |
| Databricks Connect | 7.3 | 통과는 표준 클러스터에서 지원됩니다. |
제한 사항
Azure Data Lake Storage 자격 증명 통과에서는 다음 기능이 지원되지 않습니다.
%fs(대신 이에 상응하는 dbutils.fs 명령을 사용).- Databricks 워크플로.
- Databricks REST API 참조입니다.
- Unity 카탈로그.
- 테이블 액세스 제어. Azure Data Lake Storage 자격 증명 통과에서 부여한 권한은 테이블 ACL의 세분화된 권한을 우회하는 데 사용할 수 있지만 테이블 ACL의 추가 제한은 자격 증명 통과에서 얻을 수 있는 몇 가지 이점을 제한합니다. 특히 다음을 수행합니다.
- 특정 테이블의 기반이 되는 데이터 파일에 액세스할 수 있는 Microsoft Entra ID 권한이 있는 경우 테이블 ACL을 통해 적용되는 제한 사항에 관계없이 RDD API를 통해 해당 테이블에 대한 모든 권한을 갖게 됩니다.
- DataFrame API를 사용하는 경우에만 테이블 ACL 권한이 제한됩니다. RDD API를 통해 직접 파일을 읽을 수 있더라도 DataFrame API로 직접 파일을 읽으려고 하면 파일에 대한
SELECT권한이 없다는 경고가 표시됩니다. - 테이블을 읽을 수 있는 테이블 ACL 권한이 있더라도 Azure Data Lake Storage 이외의 파일 시스템에 의해 지원되는 테이블에서 읽을 수 없습니다.
- SparkContext() 및 SparkSession(
scspark) 개체에 대한 다음 메서드는 다음과 같습니다.- 사용되지 않는 메서드.
- 관리자가 아닌 사용자가 Scala 코드를 호출할 수 있도록 하는
addFile()및addJar()와 같은 메서드입니다. - Azure Data Lake Storage Gen1 또는 Gen2 이외의 파일 시스템에 액세스하는 모든 메서드(Azure Data Lake Storage 자격 증명 통과를 사용하도록 설정된 클러스터의 다른 파일 시스템에 액세스하려면 다른 방법을 사용하여 자격 증명을 지정하고 문제 해결에서 신뢰할 수 있는 파일 시스템에 대한 섹션을 참조하세요).
- 이전 Hadoop API(
hadoopFile()및hadoopRDD())입니다. - 스트림이 실행되는 동안 통과된 자격 증명이 만료되므로 스트리밍 API.
- DBFS 탑재(
/dbfs)는 Databricks Runtime 7.3 LTS 이상에서만 사용할 수 있습니다. 자격 증명 통과가 구성된 탑재 지점은 이 경로를 통해 지원되지 않습니다. - Azure Data Factory.
- 높은 동시성 클러스터의 MLflow.
- 높은 동시성 클러스터의 azureml-sdk Python 패키지.
- Microsoft Entra ID 토큰 수명 정책을 사용하여 Microsoft Entra ID 통과 토큰의 수명을 연장할 수 없습니다. 따라서 1시간보다 오래 걸리는 명령을 클러스터에 보내는 경우 Azure Data Lake Storage 리소스가 1시간 표시된 후 액세스되면 실패합니다.
- Hive 2.3 이상을 사용하는 경우 자격 증명 통과를 사용하도록 설정된 클러스터에 파티션을 추가할 수 없습니다. 자세한 내용은 관련 문제 해결 섹션을 참조하세요.
예제 Notebook
다음 Notebook에서는 Azure Data Lake Storage Gen1 및 Gen2에 대한 Azure Data Lake Storage 자격 증명 통과를 보여 줍니다.
Azure Data Lake Storage Gen1 통과 Notebook
Azure Data Lake Storage Gen2 통과 Notebook
문제 해결
py4j.security.Py4JSecurityException: … 허용 목록에 없음
Azure Databricks가 Azure Data Lake Storage 자격 증명 통과 클러스터에 안전하다고 명시적으로 표시되지 않은 메서드에 액세스한 경우에 이 예외가 throw됩니다. 대부분의 경우 이는 메서드를 통해 Azure Data Lake Storage 자격 증명 통과 클러스터의 사용자가 다른 사용자의 자격 증명에 액세스할 수 있음을 의미합니다.
org.apache.spark.api.python.PythonSecurityException: Path … 신뢰할 수 없는 파일 시스템을 사용
이 예외는 Azure Data Lake Storage 자격 증명 통과 클러스터에서 안전하지 않은 파일 시스템에 액세스하려고 하면 throw됩니다. 신뢰할 수 없는 파일 시스템을 사용하면 Azure Data Lake Storage 자격 증명 통과 클러스터의 사용자가 다른 사용자의 자격 증명에 액세스할 수 있으므로 안전하게 사용되지 않는 모든 파일 시스템을 허용하지 않습니다.
Azure Data Lake Storage 자격 증명 통과 클러스터에서 신뢰할 수 있는 파일 시스템 집합을 구성하려면 해당 클러스터에서 Spark conf 키 spark.databricks.pyspark.trustedFilesystems를 org.apache.hadoop.fs.FileSystem의 신뢰할 수 있는 구현인 클래스 이름의 쉼표로 구분된 목록으로 설정합니다.
자격 증명 통과를 사용하도록 설정한 경우 AzureCredentialNotFoundException과 함께 파티션 추가 실패
Hive 2.3-3.1을 사용하는 경우 자격 증명 통과를 사용하도록 설정된 클러스터에 파티션을 추가하려고 하면 다음 예외가 발생합니다.
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
이 문제를 해결하려면 자격 증명 통과를 사용하지 않고 클러스터에 파티션을 추가합니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기