HDInsight에서 Apache Hadoop과 Apache Ambari Hive 보기 사용
Apache Ambari Hive 보기를 사용하여 Hive 쿼리를 실행하는 방법을 알아봅니다. Hive 보기를 사용하면 웹 브라우저에서 Hive 쿼리를 작성, 최적화 및 실행할 수 있습니다.
필수 조건
HDInsight의 Hadoop 클러스터. Linux에서 HDInsight 시작을 참조하세요.
HIVE 쿼리 실행
Azure Portal에서 디렉터리를 선택합니다. 지침에 대해서는 클러스터 나열 및 표시를 참조하세요. 클러스터가 새 포털 보기에서 열립니다.
클러스터 대시보드에서 Ambari 보기를 선택합니다. 인증하라는 메시지가 표시되면 클러스터를 만들 때 제공한 클러스터 로그인(기본값
admin) 계정 이름과 암호를 사용합니다. 브라우저에서 클러스터의 이름이CLUSTERNAME인https://CLUSTERNAME.azurehdinsight.net/#/main/views로 이동할 수도 있습니다.보기 목록에서 Hive 보기를 선택합니다.
Hive 보기 페이지는 다음 이미지와 유사합니다.
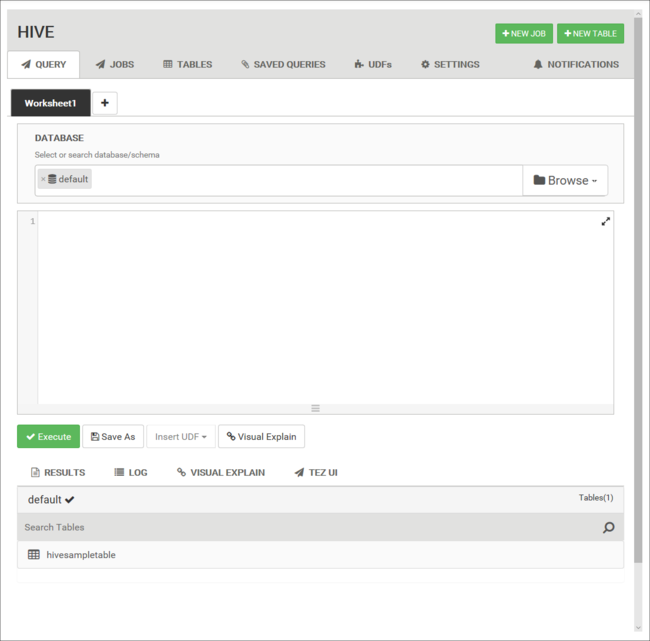
쿼리 탭에서 다음 HiveQL 문을 워크시트에 붙여넣습니다.
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;이러한 문은 다음 작업을 수행합니다.
문 설명 DROP TABLE 테이블이 이미 있는 경우 테이블과 데이터 파일을 삭제합니다. CREATE EXTERNAL TABLE Hive에서 새 “외부” 테이블을 만듭니다. 외부 테이블은 테이블 정의만 Hive에 저장합니다. 데이터는 원래 위치에 그대로 유지됩니다. ROW FORMAT 데이터의 형식을 지정하는 방법을 보여 줍니다. 이 경우, 각 로그의 필드는 공백으로 구분됩니다. STORED AS TEXTFILE LOCATION 데이터가 저장된 위치 및 텍스트로 저장되었음을 보여 줍니다. SELECT t4 열에 [ERROR] 값이 포함된 모든 행의 수를 선택합니다. Important
데이터베이스 선택 영역을 기본값으로 둡니다. 이 문서의 예제에서는 HDInsight에 포함된 기본 데이터베이스를 사용합니다.
쿼리를 시작하려면 워크시트 아래에서 실행을 선택합니다. 단추가 주황색으로 바뀌고 텍스트가 중지로 변경됩니다.
쿼리가 완료된 후에 결과 탭에 작업 결과가 표시됩니다. 다음 텍스트는 쿼리 결과입니다.
loglevel count [ERROR] 3LOG 탭을 사용하여 작업에서 생성된 로깅 정보를 볼 수 있습니다.
팁
결과 탭의 작업 드롭다운 대화 상자에서 결과를 다운로드하거나 저장합니다.
시각적 개체 설명
쿼리 계획의 시각화를 표시하려면 워크시트 아래에서 시각적 개체 설명 탭을 선택합니다.
쿼리의 시각적 개체 설명 보기는 복잡한 쿼리 흐름을 이해하는 데 도움이 됩니다.
Tez UI
쿼리에 대한 Tez UI를 표시하려면 워크시트 아래에서 Tez UI 탭을 선택합니다.
Important
Tez는 모든 쿼리를 해결하는 데 사용되지 않습니다. Tez를 사용하지 않고도 많은 쿼리를 확인할 수 있습니다.
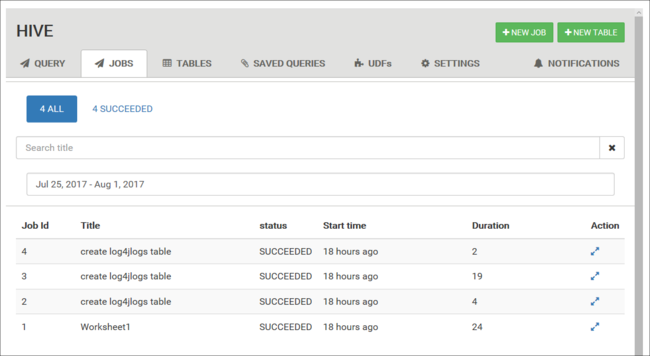
작업 기록 보기
작업 탭에 Hive 쿼리의 기록이 표시됩니다.
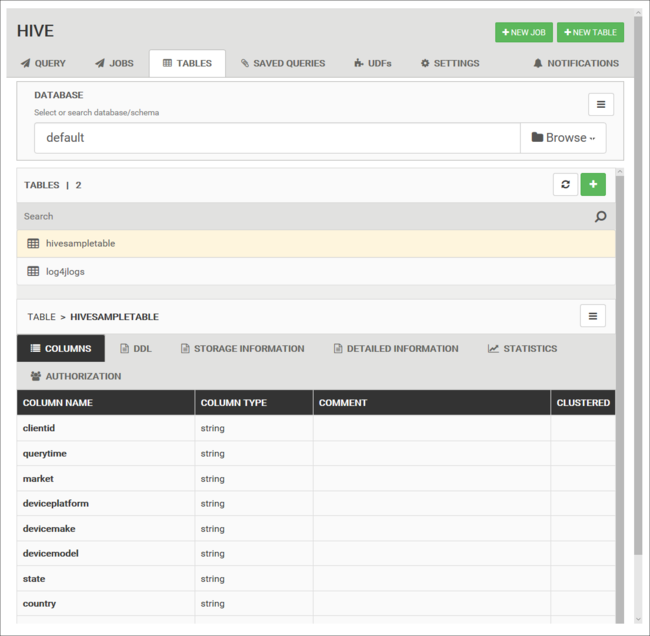
데이터베이스 테이블
테이블 탭을 사용하여 Hive 데이터베이스 내의 테이블을 사용할 수 있습니다.
저장된 쿼리
쿼리 탭에서 필요에 따라 쿼리를 저장할 수 있습니다. 쿼리를 저장한 후에 저장된 쿼리 탭에서 다시 사용할 수 있습니다.
팁
저장된 쿼리는 기본 클러스터 스토리지에 저장됩니다. /user/<username>/hive/scripts 경로에서 저장된 쿼리를 찾을 수 있습니다. 이러한 쿼리는 일반 텍스트 .hql 파일로 저장됩니다.
클러스터를 삭제하지만 스토리지는 유지하는 경우 Azure Portal에서 Azure Storage Explorer 또는 Data Lake Storage Explorer와 같은 유틸리티를 사용하여 쿼리를 검색할 수 있습니다.
사용자 정의 함수
UDF(사용자 정의 함수)를 통해 Hive를 확장할 수 있습니다. UDF를 사용하여 HiveQL에서 쉽게 모델링할 수 있는 기능 또는 논리를 구현합니다.
Hive 보기 위쪽의 UDF 탭을 사용하여 UDF 집합을 선언하고 저장합니다. UDF는 쿼리 편집기를 통해 사용할 수 있습니다.
udf 삽입 단추가 쿼리 편집기 아래쪽에 표시됩니다. 이 항목은 Hive 뷰에서 정의된 UDF의 드롭다운 목록이 표시됩니다. UDF를 선택하면 쿼리에 HiveQL 문을 추가하여 UDF를 사용하도록 설정합니다.
예를 들어 다음 속성으로 UDF를 정의하는 경우:
리소스 이름: myudfs
리소스 경로: /myudfs.jar
UDF 이름: myawesomeudf
UDF 클래스 이름: com.myudfs.Awesome
udf 삽입 단추를 사용하면 해당 리소스에 정의된 각 UDF에 대한 또 다른 드롭다운 목록과 함께 myudfs라는 항목이 표시됩니다. 이 경우에 myawesomeudf입니다. 이 항목을 선택하면 쿼리의 시작 부분에 다음을 추가합니다.
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
그런 다음 쿼리에서 UDF를 사용할 수 있습니다. 예: SELECT myawesomeudf(name) FROM people;.
HDInsight에서 Hive를 통해 UDF를 사용하는 방법에 대한 자세한 내용은 다음 문서를 참조하세요.
Hive 설정
Tez(기본값)에서 MapReduce로 Hive에 대한 실행 엔진을 변경하는 등 다양한 Hive 설정을 변경할 수 있습니다.
다음 단계
HDInsight의 Hive에 대한 일반적인 정보:
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기