이 문서에서는 Azure HDInsight에서 최상의 성능을 위해 Apache Spark 클러스터의 메모리 관리를 최적화하는 방법을 설명합니다.
개요
Spark는 메모리에 데이터를 배치하여 작동합니다. 따라서 메모리 리소스 관리는 Spark 작업 실행을 최적화하는 핵심적인 측면입니다. 클러스터 메모리를 효율적으로 사용하기 위해 적용할 수 있는 여러 가지 기술이 있습니다.
- 더 작은 데이터 파티션을 선호하고 분할 전략에서 데이터 크기, 유형 및 배포를 고려합니다.
- 기본 Java 직렬화보다는 최신의 더 효율적인
Kryo data serialization방법을 고려합니다. - YARN은 배치별로
spark-submit를 구분하므로 YARN을 사용하는 것이 좋습니다. - Spark 구성 설정을 모니터링하고 조정합니다.
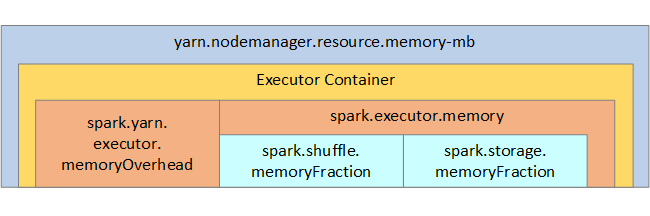
참조용으로 Spark 메모리 구조와 일부 핵심 실행기 메모리 매개 변수가 다음 이미지에 표시됩니다.
Spark 메모리 고려 사항
Apache Hadoop YARN을 사용하는 경우 YARN은 각 Spark 노드의 모든 컨테이너에서 사용하는 메모리를 제어합니다. 다음 다이어그램에서는 주요 개체 및 해당 관계를 보여 줍니다.
'메모리 부족' 메시지를 해결하려면 다음을 시도합니다.
- DAG 관리 순서 섞기를 검토합니다. 맵 쪽에서 원본 데이터를 줄이거나 사전 분할(또는 버킷화)하여 줄이고 단일 순서 섞기로 최대화하여 전송된 데이터 양을 줄입니다.
ReduceByKey은 고정 메모리 제한을 가지고 있기 때문에GroupByKey보다 선호됩니다.GroupByKey은 집계, 창 및 기타 함수를 제공하지만, 메모리 제한이 없습니다.- 드라이버에서 모든 작업을 수행하는
Reduce보다 실행기 또는 파티션에서 더 많은 작업을 수행하는TreeReduce를 선호합니다. - 하위 수준 RDD 개체 대신 DataFrame을 사용합니다.
- "상위 N개", 다양한 집계 또는 창 작업 같이 작업을 캡슐화하는 ComplexTypes를 만듭니다.
추가 문제 해결 단계는 Azure HDInsight의 Apache Spark에 대한 OutOfMemoryError 예외를 참조하세요.