팁
이 콘텐츠는 Azure용 클라우드 네이티브 .NET 애플리케이션 설계 eBook 에서 발췌한 것으로, .NET 문서에서 제공되거나 오프라인 상태에서도 읽을 수 있는 PDF(무료 다운로드 가능)로 제공됩니다.

관계형(SQL)과 비관계형(NoSQL)은 클라우드 네이티브 앱에서 일반적으로 구현되는 두 가지 형식의 데이터베이스 시스템입니다. 이러한 두 시스템은 서로 다르게 빌드되고, 데이터를 다르게 저장하고, 다르게 액세스됩니다. 이 섹션에서는 두 시스템을 모두 살펴보겠습니다. 이 장 뒷부분에서는 NewSQL이라는 새로운 데이터베이스 기술을 살펴볼 것입니다.
‘관계형 데이터베이스’는 수십 년 동안 널리 사용되어온 기술이었습니다. 완성되었고, 입증되었고, 널리 구현되고 있습니다. 다양한 경쟁 데이터베이스 제품, 도구 및 전문 지식이 있습니다. 관계형 데이터베이스는 관련 데이터 테이블의 저장소를 제공합니다. 이러한 테이블에는 고정된 스키마가 있고 SQL(구조적 쿼리 언어)을 사용하여 데이터를 관리하며 원자성, 일관성, 격리 및 내구성과 같은 ACID 보장을 지원합니다.
NoSQL 데이터베이스는 고성능 비관계형 데이터 저장소를 나타냅니다. 사용 편의성, 스케일링 기능, 복원력 및 가용성이 탁월합니다. 정규화된 데이터의 테이블을 조인하는 대신 NoSQL은 비정형 또는 반전형 데이터를 키-값 쌍 또는 JSON 문서에 저장합니다. NoSQL 데이터베이스는 일반적으로 단일 데이터베이스 파티션의 범위를 벗어나는 ACID 보증을 제공하지 않습니다. 1초 미만의 응답 시간이 필요한 대용량 서비스는 NoSQL 데이터 저장소를 선호합니다.
분산 클라우드 네이티브 시스템에 미치는 NoSQL 기술의 영향은 상당할 수 있습니다. 이 분야에서 새로운 데이터 기술이 확산되면서 한때 관계형 데이터베이스에만 의존했던 솔루션은 중단되었습니다.
NoSQL 데이터베이스에는 데이터에 액세스하고 관리하기 위한 여러 가지 모델이 포함되어 있으며, 각 모델은 특정 사용 사례에 적합합니다. 그림 5-9는 네 가지 일반적인 모델을 보여 줍니다.
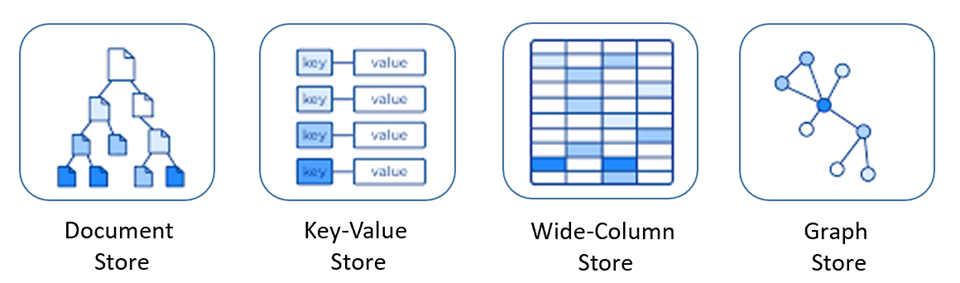
그림 5-9: NoSQL 데이터베이스에 대한 데이터 모델
| 모델 | 특징 |
|---|---|
| 문서 저장소 | 데이터 및 메타데이터는 데이터베이스 내의 JSON 기반 문서에 계층적으로 저장됩니다. |
| 키 값 저장소 | NoSQL 데이터베이스 중 가장 간단하며, 데이터가 키-값 쌍 컬렉션으로 표시됩니다. |
| 와이드-열 저장소 | 관련 데이터가 단일 열 내부에 중첩 키/값 쌍 세트로 저장됩니다. |
| 그래프 저장소 | 데이터가 그래프 구조에 노드, 에지 및 데이터 속성으로 저장됩니다. |
CAP 및 PACELC 정리
이러한 유형의 데이터베이스 간 차이점을 이해하는 방법으로, 상태를 저장하는 분산 시스템에 적용되는 원칙인 CAP 원리를 고려하세요. 그림 5-10은 CAP 원리의 세 가지 속성을 보여 줍니다.
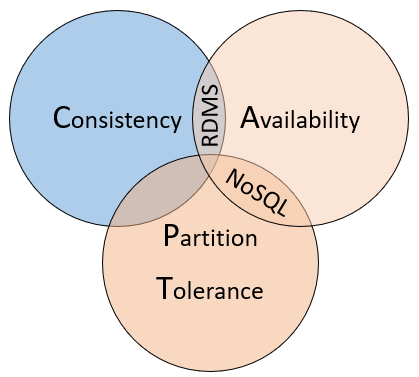
그림 5-10. CAP 정리
이 원리에 따르면 분산 데이터 시스템은 일관성, 가용성 및 파티션 허용 오차 간 균형을 제공합니다. 또한 데이터베이스는 세 가지 속성 중 ‘2’개만 보증합니다.
일관성. 모든 복제본이 업데이트될 때까지 시스템에서 반드시 요청을 차단해야 하는 경우에도 클러스터의 모든 노드는 가장 최신 데이터로 응답합니다. 현재 업데이트 중인 항목에 대해 "일관된 시스템"을 쿼리하는 경우 모든 복제본이 성공적으로 업데이트될 때까지 응답을 대기하게 됩니다. 그러나 최신 데이터를 받습니다. CAP 정리의 컨텍스트에서 사용되는 "일관성"이라는 용어는 ACID 보장의 컨텍스트에서 "일관성"이 정의되는 방식과 구별되는 기술적 의미를 갖는다는 점을 이해해야 합니다.
가용성 시스템에서 장애가 없는 노드가 수신한 모든 요청에 대한 응답은 반드시 생성되어야 합니다. 간단히 말해 업데이트 중인 항목에 대해 "사용 가능한 시스템"을 쿼리하는 경우 해당 순간에 서비스에서 제공할 수 있는 최상의 답변을 얻을 수 있습니다. 그러나 CAP 정리에서 정의하는 “가용성”은 분산 시스템에서 일반적으로 알려진 “고가용성”과는 엄밀히 말해 다르다는 점에 유의하세요.
파티션 허용 오차 복제된 데이터 노드가 다른 복제된 데이터 노드와의 연결에 실패하거나 연결이 끊어지더라도 시스템이 계속 작동하도록 보장합니다.
CAP 원리는 네트워크 파티션 동안 일관성 및 가용성 관리와 관련된 장단점을 설명합니다. 그러나 네트워크 파티션이 없는 경우에는 일관성 및 성능과 관련된 장단점도 있습니다.
참고 항목
일관성 대신 가용성을 선택하더라도 네트워크 파티션이 있는 경우 가용성이 저하될 수 있습니다. CAP 가용성 시스템은 일부 고객에게 더 많은 가용성을 제공하지만 모든 고객에게 반드시 "고가용성"을 제공하는 것은 아닙니다.
CAP 원리는 이러한 장단점을 보다 포괄적으로 설명하기 위해 종종 PACELC로 확장되기도 합니다. CAP 정리는 IoT(사물 인터넷), 환경 모니터링 및 모바일 애플리케이션과 관련된 환경과 같이 간헐적으로 연결된 환경에서 특히 관련이 있습니다. 이러한 컨텍스트에서 장치는 정전과 같은 까다로운 물리적 조건 또는 엘리베이터와 같은 제한된 공간에 들어갈 때 분할될 수 있습니다. 클라우드 애플리케이션과 같은 분산 시스템의 경우 더 포괄적이며 네트워크 파티션이 없는 경우에도 대기 시간 및 일관성과 같은 장단 부분을 고려하는 PACELC 정리를 사용하는 것이 더 적합합니다.
관계형 데이터베이스는 일반적으로 일관성과 가용성을 제공하지만 파티션 허용 오차는 제공하지 않습니다. 일반적으로 이 데이터베이스는 머신에 리소스를 더 추가하여 단일 서버에 프로비저닝되고 수직으로 스케일링됩니다.
많은 관계형 데이터베이스 시스템은 주 데이터베이스를 다른 보조 서버 인스턴스로 복사할 수 있는 기본 제공 복제 기능을 지원합니다. 쓰기 작업은 주 인스턴스에 만들어지고 각 보조 인스턴스에 복제됩니다. 실패 시 주 인스턴스는 보조 인스턴스로 장애 조치(failover)되어 고가용성을 제공할 수 있습니다. 보조 복제본을 사용하여 읽기 작업을 분산시킬 수도 있습니다. 쓰기 작업은 항상 주 복제본으로 진행되지만 읽기 작업을 보조 복제본으로 라우팅하여 시스템 부하를 줄일 수 있습니다.
분할(sharding)을 사용할 때처럼 여러 노드에서 데이터를 수평으로 분할할 수도 있습니다. 그러나 분할은 쉽게 통신할 수 없는 여러 부분으로 데이터를 내보내므로 운영 오버헤드가 크게 증가됩니다. 관리하는 데 비용이 많이 들고 시간이 오래 걸릴 수 있습니다. 분할된 배포에서 테이블 조인, 트랜잭션 및 참조 무결성을 포함하는 관계형 기능을 사용하게 되면 성능이 크게 저하됩니다.
복제를 동기적으로 발생할지 여부를 구성하여 복제 일관성 및 복구 지점 목표를 조정할 수 있습니다. "일관성이 높은" 또는 동기식 관계형 데이터베이스 클러스터에서 데이터 복제본의 네트워크 연결을 끊어야 하는 경우 데이터베이스에 쓸 수 없게 됩니다. 시스템은 해당 변경 내용을 다른 데이터 복제본에 복제할 수 없으므로 쓰기 작업을 거부합니다. 트랜잭션이 완료되려면 먼저 모든 데이터 복제본을 업데이트해야 합니다.
NoSQL 데이터베이스는 일반적으로 고가용성 및 파티션 허용 오차를 지원합니다. 종종 상용 서버에서 수평으로 스케일링됩니다. 이 방법은 지리적 지역 내 및 지역 전체에서 보다 저렴한 비용으로 뛰어난 가용성을 제공합니다. 이러한 머신 또는 노드에서 데이터를 분할하고 복제하여 중복성 및 내결함성을 제공합니다. 일관성은 일반적으로 합의 프로토콜 또는 쿼럼 메커니즘을 통해 조정됩니다. 이러한 방식은 관계형 시스템의 튜닝 동기 복제와 비동기 복제 간의 장단점을 파악할 때 더 보다 세밀하게 제어할 수 있습니다.
“고가용성” NoSQL 데이터베이스 클러스터에서는 데이터 복제본의 연결이 끊어져도 데이터베이스에 대한 쓰기 작업을 완료할 수 있습니다. 데이터베이스 클러스터는 쓰기 작업을 허용하고 가능한 경우 각 데이터 복제본을 업데이트합니다. 쓰기 가능한 여러 복제본을 지원하는 NoSQL 데이터베이스는 복구 시간 목표를 최적화할 때 장애 조치가 필요하지 않도록 하여 고가용성을 보다 강화할 수 있습니다.
최신 NoSQL 데이터베이스는 일반적으로 분할 기능을 시스템 디자인 기능으로서 구현합니다. 파티션 관리는 종종 데이터베이스에 기본적으로 제공되며, 라우팅은 종종 파티션 키라고 하는 배치 힌트를 통해 수행됩니다. 유연한 데이터 모델을 사용하면 NoSQL 데이터베이스로 스키마 관리 부담을 낮추고 데이터 모델 변경이 필요한 애플리케이션 업데이트를 배포할 때 가용성을 향상시킬 수 있습니다.
비즈니스에는 관계형 테이블 조인 및 참조 무결성보다 고가용성 및 대규모 스케일링 기능이 더 중요한 경우가 많습니다. 개발자는 최종 일관성을 수용하기 위해 Sagas, CQRS 및 비동기 메시징과 같은 기술 및 패턴을 구현할 수 있습니다.
현재, CAP 원리 제약 조건을 고려할 때는 주의해야 합니다. NewSQL이라는 새로운 유형의 데이터베이스가 등장했습니다. 이 데이터베이스는 관계형 데이터베이스 엔진을 확장하여 수평 스케일링 기능과 NoSQL 시스템의 스케일링 가능한 성능을 모두 지원합니다.
관계형 및 NoSQL 시스템에 대한 고려 사항
특정 데이터 요구 사항에 따라 클라우드 네이티브 기반 마이크로 서비스는 관계형, NoSQL 데이터 저장소 또는 둘 다를 구현할 수 있습니다.
| 다음과 같은 경우 NoSQL 데이터 저장소를 고려합니다. | 다음과 같은 경우 관계형 데이터베이스를 고려합니다. |
|---|---|
| 대규모의 예측 가능한 대기 시간(예: 초당 수백만 개의 트랜잭션을 수행하는 동안 측정된 대기 시간(밀리초))이 필요한 대량 워크로드가 있습니다. | 워크로드 볼륨은 일반적으로 초당 수천 개의 트랜잭션에 해당합니다. |
| 데이터는 동적이며 자주 변경됩니다. | 데이터는 고도로 구조화되어 있으며 참조 무결성이 필요합니다. |
| 관계는 정규화되지 않은 데이터 모델일 수 있습니다. | 관계는 정규화된 데이터 모델에서 테이블 조인을 통해 표현됩니다. |
| 데이터 검색은 간단하며 테이블 조인 없이 표현됩니다. | 복잡한 쿼리 및 보고서를 사용합니다. |
| 데이터는 일반적으로 지리적 지역 간에 복제되며 일관성, 가용성 및 성능에 대한 보다 세부적인 제어가 필요합니다. | 데이터는 일반적으로 중앙 집중식이거나 비동기적으로 지역 간에 복제할 수 있습니다. |
| 애플리케이션은 퍼블릭 클라우드와 같은 상용 하드웨어에 배포됩니다. | 애플리케이션은 대형 고급 하드웨어에 배포됩니다. |
다음 섹션에서는 클라우드 네이티브 데이터를 저장하고 관리하기 위해 Azure 클라우드에서 사용할 수 있는 옵션을 살펴봅니다.
서비스로서의 데이터베이스
시작하려면 Azure 가상 머신을 프로비저닝하고 각 서비스에 대해 원하는 데이터베이스를 설치할 수 있습니다. 환경을 완전히 제어할 수 있지만 클라우드 플랫폼의 많은 기본 제공 기능을 포기해야 합니다. 또한 각 서비스에 대한 가상 머신 및 데이터베이스를 관리할 책임이 있습니다. 이 방법은 시간이 오래 걸리고 비용이 많이 들 수 있습니다.
대신, 클라우드 네이티브 애플리케이션은 DBaaS(Database as a Service)로 노출되는 데이터 서비스를 선호합니다. 클라우드 공급업체를 통해 완벽하게 관리되는 이러한 서비스는 기본 제공 보안, 확장성 및 모니터링을 제공합니다. 서비스를 소유하는 대신, 지원 서비스로 사용합니다. 공급자는 대규모로 리소스를 운영하며 성능 및 유지 관리에 대한 책임을 집니다.
고가용성을 달성하기 위해 클라우드 가용성 영역 및 지역에서 구성할 수 있습니다. 모두 Just-In-Time 용량과 종량제 모델을 지원합니다. Azure는 다양한 종류의 관리형 데이터 서비스 옵션을 특징으로 하며, 각 옵션에는 특정 이점이 있습니다.
먼저 Azure에서 사용할 수 있는 관계형 DBaaS 서비스를 살펴보겠습니다. Microsoft의 주력 SQL Server 데이터베이스는 몇 가지 오픈 소스 옵션과 함께 사용할 수 있습니다. 그런 다음, Azure의 NoSQL 데이터 서비스에 대해 알아보겠습니다.
Azure 관계형 데이터베이스
관계형 데이터가 필요한 클라우드 네이티브 마이크로 서비스의 경우 Azure는 그림 5-11에 표시된 것과 같은 4개의 관리형 관계형 DBaaS(Database as a Service) 제품을 제공합니다.

그림 5-11. Azure에서 사용할 수 있는 관리형 관계형 데이터베이스
이전 그림에서는 각 데이터베이스가 추가 비용 없이 주요 기능을 제공하는 일반적인 DBaaS 인프라에 배치되는 방식을 확인합니다.
이러한 기능은 많은 수의 데이터베이스를 프로비저닝하지만 관리할 리소스가 제한된 조직에 특히 중요합니다. 처리 코어, 메모리 및 기본 스토리지의 양을 선택하여 몇 분 안에 Azure 데이터베이스를 프로비저닝할 수 있습니다. 가동 중지 시간을 거의 또는 전혀 발생하지 않으면서 데이터베이스를 즉시 스케일링하고 동적으로 리소스를 조정할 수 있습니다.
Azure SQL 데이터베이스
Microsoft SQL Server에 대한 전문 지식을 갖춘 개발 팀은 Azure SQL Database를 고려해야 합니다. Microsoft SQL Server 데이터베이스 엔진을 기준으로 하는 완전 관리형 관계형 DBaaS(database-as-a-service)입니다. 이 서비스는 온-프레미스 버전의 SQL Server에 있는 많은 기능을 공유하고 안정적인 최신 버전의 SQL Server 데이터베이스 엔진을 실행합니다.
클라우드 네이티브 마이크로 서비스와 함께 사용하기 위해 Azure SQL Database는 다음 세 가지 배포 옵션으로 사용할 수 있습니다.
단일 데이터베이스는 Azure 클라우드의 Azure SQL Database 서버에서 실행되는 완전 관리형 SQL Database를 나타냅니다. 데이터베이스는 기본 데이터베이스 서버에 대한 구성 종속성이 없으므로 ‘포괄형’으로 간주됩니다.
관리형 인스턴스는 온-프레미스 SQL Server와의 거의 100% 호환성을 제공하는 Microsoft SQL Server 데이터베이스 엔진의 완전 관리형 인스턴스입니다. 이 옵션은 최대 35TB의 보다 큰 데이터베이스를 지원하며 더 나은 격리를 위해 Azure Virtual Network에 배치됩니다.
Azure SQL Database 서버리스는 워크로드 수요에 따라 자동으로 스케일링되는 단일 데이터베이스에 대한 컴퓨팅 계층입니다. 초당 사용되는 컴퓨팅 양에 대해서만 비용이 청구됩니다. 이 서비스는 비활성 기간과 예측할 수 없는 사용 패턴이 번갈아 발생하는 워크로드에 적합합니다. 또한 서버리스 컴퓨팅 계층은 스토리지 비용만 청구되도록 비활성 기간 동안 데이터베이스를 자동으로 일시 중지합니다. 활동 상태로 돌아가면 자동으로 다시 시작됩니다.
기존 Microsoft SQL Server 스택 외에도 Azure는 인기 있는 세 개의 오픈 소스 데이터베이스의 관리형 버전도 제공합니다.
Azure의 오픈 소스 데이터베이스
오픈 소스 관계형 데이터베이스는 클라우드 네이티브 애플리케이션에 널리 사용되고 있습니다. 많은 기업에서는 특히 비용 절감을 위해 상용 데이터베이스 제품보다 오픈 소스 데이터베이스를 선호합니다. 많은 개발 팀은 유연성, 커뮤니티 지원 개발 및 도구/확장 에코시스템을 활용합니다. 오픈 소스 데이터베이스를 여러 클라우드 공급자에 배포할 수 있으므로 “공급업체 종속성” 문제를 최소화할 수 있습니다.
개발자는 Azure VM에서 오픈 소스 데이터베이스를 쉽게 자체 호스팅할 수 있습니다. 이 접근 방식은 모든 권한을 제공하지만, 사용자가 데이터베이스 및 VM의 관리, 모니터링 및 유지 관리를 수행할 수 밖에 없는 상황이 됩니다.
그러나 Microsoft는 여러 인기 있는 오픈 소스 데이터베이스를 완전 관리형 DBaaS 서비스로 제공하여 Azure를 “개방형 플랫폼”으로 유지하려는 노력을 계속하고 있습니다.
Azure Database for MySQL (MySQL을 위한 Azure 데이터베이스)
MySQL은 오픈 소스 관계형 데이터베이스이며 LAMP 소프트웨어 스택을 기준으로 빌드된 애플리케이션의 핵심 요소입니다. 대량 읽기 워크로드에 널리 선택되며 Facebook, Twitter 및 YouTube를 비롯한 많은 대규모 조직에서 사용됩니다. Community Edition은 무료로 사용할 수 있지만 엔터프라이즈 버전에는 라이선스 구매가 필요합니다. 1995년에 처음 만들어진 이 제품은 2008년에 Sun Microsystems에서 구입했습니다. Oracle은 2010년에 Sun 및 MySQL을 인수했습니다.
Azure Database for MySQL은 MySQL 오픈 소스 서버 엔진을 기준으로 하는 관리형 관계형 데이터베이스 서비스입니다. MySQL Community Edition을 사용합니다. Azure MySQL 서버는 서비스의 관리 지점입니다. 온-프레미스 배포에 사용되는 것과 동일한 MySQL 서버 엔진입니다. 엔진은 서버당 단일 데이터베이스 또는 리소스를 공유하는 서버당 여러 데이터베이스를 만들 수 있습니다. 새 기술을 배우거나 가상 머신을 관리할 필요 없이 동일한 오픈 소스 도구를 사용하여 데이터를 계속 관리할 수 있습니다.
MariaDB를 위한 Azure 데이터베이스
MariaDB Server는 또 다른 인기 있는 오픈 소스 데이터베이스 서버입니다. Oracle이 MySQL을 소유한 Sun Microsystems를 구매했을 때 mySQL의 ‘포크’로 만들어졌습니다. 이것은 MariaDB가 오픈 소스로 유지되도록 하기 위한 것이었습니다. MariaDB는 MySQL의 포크이므로 데이터 및 테이블 정의는 호환되며 클라이언트 프로토콜, 구조 및 API는 긴밀하게 구성되어 있습니다.
MariaDB는 강력한 커뮤니티를 유지하며 많은 대기업에서 사용됩니다. Oracle은 MySQL을 계속 유지 관리, 개선 및 지원하지만 MariaDB foundation은 MariaDB를 관리하여 제품 및 설명서에 대한 공개적으로 기여할 수 있도록 합니다.
Azure Database for MariaDB는 Azure 클라우드에서 서비스로 사용되는 완전 관리형 관계형 데이터베이스입니다. 이 서비스는 MariaDB 커뮤니티 버전 서버 엔진을 기준으로 합니다. 예측 가능한 성능과 동적 스케일링 기능으로 중요 업무용 워크로드를 처리할 수 있습니다.
PostgreSQL용 Azure 데이터베이스
PostgreSQL은 30년 이상 개발되어 온 오픈 소스 관계형 데이터베이스입니다. PostgresSQL은 안정성 및 데이터 무결성에 대해 좋은 평판을 유지하고 있습니다. 특히 복잡한 쿼리와 많은 쓰기가 있는 워크로드에서 MySQL보다 풍부한 기능, SQL 규정 준수 및 더 높은 성능을 나타냅니다. Apple, Red Hat 및 Fujitsu를 비롯한 많은 대기업은 PostgreSQL을 사용하여 제품을 제작했습니다.
Azure Database for PostgreSQL은 오픈 소스 Postgres 데이터베이스 엔진을 기반으로 한 완전 관리형 관계형 데이터베이스 서비스입니다. 이 서비스는 C++, Java, Python, Node, C# 및 PHP를 비롯한 많은 개발 플랫폼을 지원합니다. 명령줄 인터페이스 도구 또는 Azure Data Migration Service를 사용하여 PostgreSQL 데이터베이스를 이러한 서비스로 마이그레이션할 수 있습니다.
Azure Database for PostgreSQL은 다음 두 가지 배포 옵션과 함께 사용할 수 있습니다.
단일 서버 배포 옵션은 여러 데이터베이스를 배포할 수 있는 여러 데이터베이스용 중앙 관리 지점입니다. 가격은 코어 및 스토리지를 기준으로 서버별로 구성됩니다.
Hyperscale(Citus) 옵션은 Citus Data 기술로 구동됩니다. 수백 개의 노드에서 단일 데이터베이스를 수평으로 스케일링하여 빠른 성능과 규모를 제공함으로써 높은 성능을 달성합니다. 이 옵션을 사용하면 엔진이 메모리에 더 많은 데이터를 추가하고, 수백 개의 노드에서 쿼리를 병렬 처리하고, 데이터를 더 빠르게 인덱싱할 수 있습니다.
Azure의 NoSQL 데이터
Cosmos DB는 Azure 클라우드에서 완전 관리형, 전역적으로 분산된 NoSQL 데이터베이스 서비스입니다. Coca-Cola, Skype, ExxonMobil 및 Liberty Mutual 등의 전 세계 많은 대기업에서 채택되었습니다.
서비스가 전 세계 어디에서나 빠른 응답, 고가용성 또는 탄력적 확장성을 요구하는 경우 Cosmos DB를 선택하는 것이 좋습니다. 그림 5-12는 Cosmos DB를 보여 줍니다.
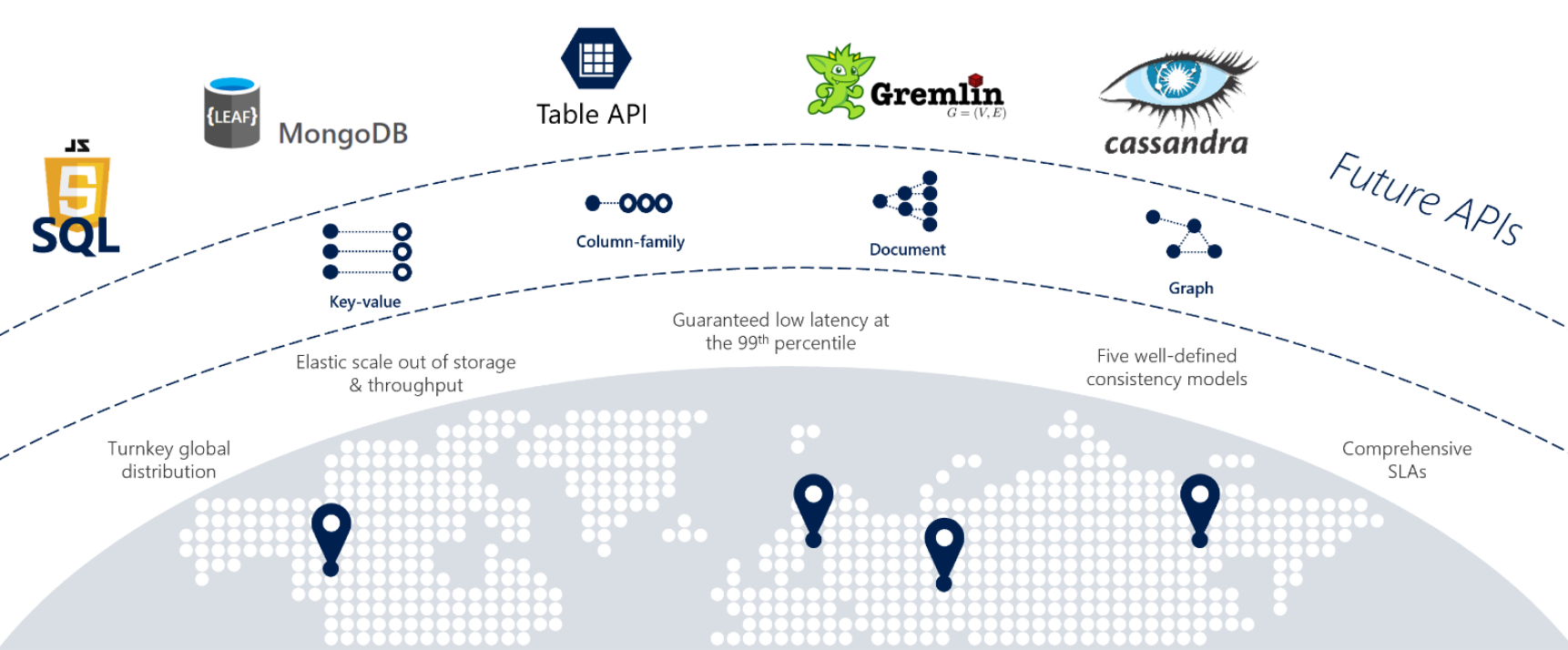
그림 5-12: Azure Cosmos DB 개요
이전 그림에서는 Cosmos DB에서 사용할 수 있는 많은 기본 제공 클라우드 네이티브 기능을 제공합니다. 이 섹션에서 자세히 살펴보겠습니다.
글로벌 지원
클라우드 네이티브 애플리케이션은 종종 전 세계의 대상 그룹을 가지며 전역 규모가 필요합니다.
Cosmos 데이터베이스를 여러 지역 또는 전 세계에 배포하고, 데이터를 사용자와 가깝게 배치하고, 응답 시간을 개선하고, 대기 시간을 줄일 수 있습니다. 서비스를 일시 중지하거나 다시 배포하지 않고, 한 지역에서 데이터베이스를 추가하거나 제거할 수 있습니다. 백그라운드에서 Cosmos DB는 구성된 각 지역에 데이터를 투명하게 복제합니다.
Cosmos DB는 전역 수준에서 활성/활성 클러스터링을 지원하므로 ‘쓰기 및 읽기를 둘 다’ 지원하도록 데이터베이스 영역을 구성할 수 있습니다.
다중 지역 쓰기 프로토콜은 Cosmos DB에서 다음 기능을 지원하는 중요한 기능입니다.
무제한 탄력적 쓰기 및 읽기 확장성.
전 세계의 99.999% 읽기 및 쓰기 가용성
99번째 백분위에서 10밀리초 미만으로 제공되는 보장된 읽기 및 쓰기
Cosmos DB 멀티 호밍(Multi-Homing) API를 사용하면 마이크로 서비스가 가장 가까운 Azure 지역을 자동으로 인식하고 요청을 보냅니다. 가장 가까운 지역은 구성 변경 없이 Cosmos DB에서 식별됩니다. 지역을 사용할 수 없게 되면 멀티 호밍 기능은 요청을 다음으로 가까운 사용 가능한 지역으로 자동 라우팅합니다.
다중 모델 지원
모놀리식 애플리케이션을 클라우드 네이티브 아키텍처로 다시 배치하는 경우 개발 팀은 때때로 오픈 소스 NoSQL 데이터 저장소를 마이그레이션해야 합니다. Cosmos DB는 다중 모델 데이터 플랫폼을 사용하여 이러한 NoSQL 데이터 저장소에 대한 투자를 유지하는 데 도움이 될 수 있습니다. 다음 표에서는 지원되는 NoSQL 호환성 API를 보여 줍니다.
| 공급자 | 설명 |
|---|---|
| NoSQL API | NoSQL용 API는 데이터를 문서 형식으로 저장합니다. |
| Mongo DB API | Mongo DB API 및 JSON 문서 지원 |
| Gremlin API | 그래프 기반 노드 및 에지 데이터 표현을 사용하여 Gremlin API 지원 |
| Cassandra API | 와이드 열 데이터 표현을 위해 Casandra API 지원 |
| 테이블 API | 향상된 프리미엄 기능으로 Azure Table Storage 지원 |
| PostgreSQL API | 모든 규모에서 PostgreSQL을 실행하기 위한 관리되는 서비스 |
개발 팀은 데이터 또는 코드를 최소한으로 변경하면서 기존 Mongo, Gremlin 또는 Cassandra 데이터베이스를 Cosmos DB로 마이그레이션할 수 있습니다. 새 앱의 경우 개발 팀은 오픈 소스 옵션 또는 기본 제공 SQL API 모델 중에서 선택할 수 있습니다.
내부적으로 Cosmos는 기본 데이터 형식으로 구성된 간단한 구조체 형식으로 데이터를 저장합니다. 각 요청이 있을 때 데이터베이스 엔진은 기본 데이터를 선택한 모델 표현으로 변환합니다.
이전 표에 나온 Table API 옵션을 확인합니다. 이 API는 Azure Table Storage가 진화한 것입니다. 둘 다 동일한 기본 테이블 모델을 공유하지만 Cosmos DB Table API는 Azure Storage API에서 사용할 수 없는 향상된 프리미엄 기능을 추가합니다. 다음 표에서는 기능을 대조해서 설명합니다.
| 기능 | Azure Table Storage (애저 테이블 저장소) | Azure Cosmos DB (애저 코스모스 DB) |
|---|---|---|
| 대기 시간 | 고속 | 전 세계 어디에서나 읽기 및 쓰기에 대해 한 자릿수 밀리초 대기 시간 유지 |
| 처리량 | 테이블당 20,000개 작업 제한 | 테이블당 무제한 작업 |
| 글로벌 배포 | 선택적 단일 보조 읽기 지역이 있는 단일 지역 | 자동 장애 조치를 사용하여 모든 지역에 턴키 배포 |
| 인덱싱 | 파티션 및 행 키 속성에만 사용 가능 | 모든 속성의 자동 인덱싱 |
| 가격 책정 | 콜드 워크로드에 최적화됨(낮은 처리량: 스토리지 비율) | 핫 워크로드에 최적화됨(높은 처리량: 스토리지 비율) |
Azure Table Storage를 사용하는 마이크로 서비스는 Cosmos DB Table API로 쉽게 마이그레이션할 수 있습니다. 코드 변경은 필요하지 않습니다.
튜닝 가능한 일관성
‘관계형 및 NoSQL’ 섹션 앞부분에서 ‘데이터 일관성’ 주제에 대해 논의했습니다. 데이터 일관성은 데이터의 ‘무결성’을 나타냅니다. 분산 데이터가 있는 클라우드 네이티브 서비스는 복제에 의존하며 읽기 일관성, 가용성 및 대기 시간 간에 적절한 균형을 유지해야 합니다.
대부분의 분산 데이터베이스를 통해 개발자는 강력한 일관성과 최종 일관성이라는 두 가지 일관성 모델 중에서 선택할 수 있습니다. ‘강력한 일관성’은 데이터 프로그래밍 기능의 전형입니다. 시스템에서 업데이트가 모든 데이터베이스 복사본에 복제되는 데 대기 시간이 발생하더라도 쿼리는 항상 최신 데이터를 반환합니다. 최종 일관성을 위해 구성된 데이터베이스는 해당 데이터가 최신 복사본이 아니더라도 데이터를 즉시 반환합니다. 최종 일관성 옵션을 사용하면 고가용성, 늘어난 규모 및 성능 향상이 제공됩니다.
Azure Cosmos DB는 그림 5-13에 표시된 5개의 잘 정의된 일관성 모델을 제공합니다.

그림 5-13: Cosmos DB 일관성 수준
이러한 옵션을 사용하면 데이터의 일관성, 가용성 및 성능에 대한 정확한 선택 및 보다 세밀한 조정을 수행할 수 있습니다. 수준은 다음 표에 표시됩니다.
| 일관성 수준 | 설명 |
|---|---|
| 최종 | 읽기의 순서는 보장되지 않습니다. 복제본은 결국 수렴됩니다. |
| 상수 접두사 | 읽기는 여전히 최종적이지만 데이터는 기록되는 순서대로 반환됩니다. |
| 세션 | 현재 세션 중에 작성된 모든 데이터를 읽을 수 있습니다. 기본 일관성 수준입니다. |
| 제한된 부실 | 지정한 간격별로 내역 쓰기를 읽습니다. |
| 강력 | 읽기를 통해 항목의 커밋된 최신 버전 반환이 보장됩니다. 클라이언트는 커밋되지 않은 읽기 또는 부분 읽기를 볼 수 없습니다. |
Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained 문서에서 Microsoft 프로그램 관리자인 Jeremy Likness는 다섯 가지 모델을 잘 설명해 주었습니다.
분할
Azure Cosmos DB는 자동 분할을 활용하여 클라우드 네이티브 서비스의 성능 요구 사항을 충족하도록 데이터베이스를 스케일링합니다.
데이터베이스, 컨테이너 및 항목을 만들어 Cosmos DB 데이터에서 데이터를 관리합니다.
컨테이너는 Cosmos DB 데이터베이스에 있으며 스키마와 관계없이 항목을 그룹화합니다. 항목은 컨테이너에 추가하는 데이터입니다. 문서, 행, 노드 또는 에지로 표시됩니다. 컨테이너에 추가된 모든 항목은 자동으로 인덱싱됩니다.
컨테이너를 분할하기 위해 항목은 논리 파티션이라는 고유한 하위 집합으로 나뉩니다. 논리 파티션은 컨테이너의 각 항목과 연결된 파티션 키의 값에 따라 채워집니다. 그림 5-14에서는 파티션 키 값을 기준으로 논리 파티션이 있는 두 개의 컨테이너를 보여 줍니다.
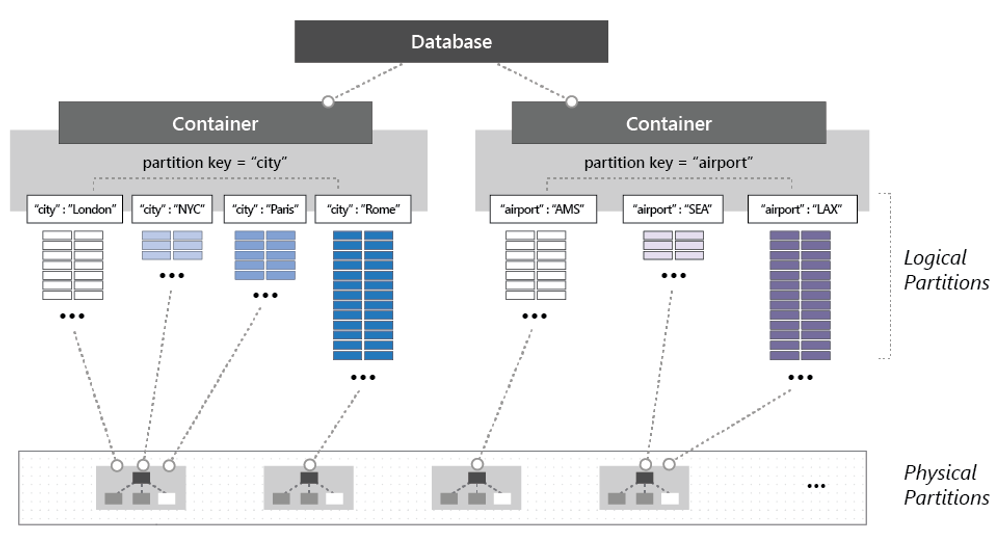
그림 5-14: Cosmos DB 분할 메커니즘
이전 그림에서는 각 항목에 파티션 키 'city' 또는 'airport'가 어떻게 포함되어 있는지 확인합니다. 키는 항목의 논리 파티션을 결정합니다. 도시 코드가 있는 항목은 왼쪽의 컨테이너에 할당되고 공항 코드가 있는 항목은 오른쪽의 컨테이너에 할당됩니다. 파티션 키 값을 ID 값과 결합하면 항목을 고유하게 식별하는 항목의 인덱스가 만들어집니다.
내부적으로 Cosmos DB는 컨테이너의 확장성 및 성능 요구 사항을 충족하기 위해 실제 파티션에 논리 파티션을 배치하는 작업을 자동으로 관리합니다. 애플리케이션 처리량 및 스토리지 요구 사항이 증가함에 따라 Azure Cosmos DB는 더 많은 수의 서버에서 논리 파티션을 재배포합니다. 재배포 작업은 Cosmos DB에서 관리되며 중단 또는 가동 중지 시간 없이 호출됩니다.
NewSQL 데이터베이스
NewSQL은 관계형 데이터베이스의 ACID 보장과 NoSQL의 분산 스케일링 기능을 결합하는 새로운 데이터베이스 기술입니다. NewSQL 데이터베이스는 완전한 트랜잭션 지원 및 ACID 규정 준수를 통해 분산된 환경에서 대량의 데이터를 처리해야 하는 비즈니스 시스템에 중요합니다. NoSQL 데이터베이스는 대규모 스케일링 기능을 제공할 수 있지만 데이터 일관성을 보장하지는 않습니다. 일관성 없는 데이터로 인한 일시적인 문제는 개발 팀에 부담을 줍니다. 개발자는 일관성 없는 데이터로 인한 문제를 관리하기 위해 마이크로 서비스 코드에 보호 장치를 구성해야 합니다.
CNCF(Cloud Native Computing Foundation)는 여러 NewSQL 데이터베이스 프로젝트를 제공합니다.
| 프로젝트 | 특징 |
|---|---|
| CockroachDB | 전역적으로 스케일링되는 ACID 규격 관계형 데이터베이스입니다. 클러스터에 새 노드를 추가하면 CockroachDB는 인스턴스 및 지리적 지역 간에 데이터의 균형을 조정합니다. 안정성을 보장하기 위해 복제본을 만들고, 관리하고, 배포합니다. 오픈 소스이며 자유롭게 사용할 수 있습니다. |
| TiDB | HTAP(하이브리드 트랜잭션 및 분석 처리) 워크로드를 지원하는 오픈 소스 데이터베이스입니다. MySQL과 호환되며 수평 스케일링 기능, 강력한 일관성 및 고가용성을 제공합니다. TiDB는 MySQL 서버처럼 작동합니다. 애플리케이션에 대한 광범위한 코드 변경 없이 기존 MySQL 클라이언트 라이브러리를 계속 사용할 수 있습니다. |
| YugabyteDB | 오픈 소스 고성능 분산 SQL 데이터베이스입니다. 낮은 쿼리 대기 시간, 오류에 대한 복원력 및 전역 데이터 배포를 지원합니다. YugabyteDB는 PostgreSQL과 호환되며 스케일 아웃 RDBMS 및 인터넷 규모의 OLTP 워크로드를 처리합니다. 또한 이 제품은 NoSQL을 지원하며 Cassandra와 호환됩니다. |
| 바이트 수 | Vitess는 MySQL 인스턴스의 대규모 클러스터를 배포, 스케일링 및 관리하기 위한 데이터베이스 솔루션입니다. 퍼블릭 또는 프라이빗 클라우드 아키텍처에서 실행할 수 있습니다. Vitess는 여러 중요한 MySQL 기능을 결합하고 확장하며 수직 분할 및 수평 분할 지원을 제공합니다. YouTube에서 시작된 Vitess는 2011년부터 모든 YouTube 데이터베이스 트래픽을 제공하고 있습니다. |
이전 그림에 나온 오픈 소스 프로젝트는 Cloud Native Computing Foundation에서 사용할 수 있습니다. 세 가지 제품은 .NET 지원을 포함하는 전체 데이터베이스 제품입니다. 다른 제품인 Vitess는 MySQL 인스턴스의 큰 클러스터를 수평으로 스케일링하는 데이터베이스 클러스터링 시스템입니다.
NewSQL 데이터베이스의 주요 디자인 목표는 Kubernetes에서 기본적으로 작동하며 플랫폼의 복원력과 스케일링 기능을 활용하는 것입니다.
NewSQL 데이터베이스는 기본 가상 머신을 잠시 후에 다시 시작하거나 다시 예약할 수 있는 임시 클라우드 환경에서 성장하도록 설계되었습니다. 데이터베이스는 데이터 손실이나 가동 중지 시간 없이 노드 오류에도 유지되도록 설계되었습니다. 예를 들어 CockroachDB는 클러스터의 노드에서 모든 데이터의 일관된 복제본을 3개 유지 관리하여 머신 손실에서도 유지될 수 있습니다.
Kubernetes는 서비스 생성을 사용하여 클라이언트가 단일 DNS 항목에서 동일한 NewSQL 데이터베이스 프로세스 그룹을 처리할 수 있도록 합니다. 연결된 서비스의 주소에서 데이터베이스 인스턴스를 분리하면 기존 애플리케이션 인스턴스를 중단하지 않고도 스케일링할 수 있습니다. 지정된 시간에 모든 서비스에 요청을 보내면 항상 동일한 결과가 생성됩니다.
이 시나리오에서는 모든 데이터베이스 인스턴스가 동일합니다. 즉, 기본 또는 보조 관계가 없습니다. 합의 복제와 같은 기술은 모든 데이터베이스 노드가 모든 요청을 처리할 수 있도록 허용합니다. 부하 분산 요청을 수신하는 노드에 로컬로 필요한 데이터가 있으면 즉시 응답합니다. 그렇지 않은 경우 노드는 게이트웨이가 되고 적절한 노드에 요청을 전달하여 올바른 답변을 얻습니다. 클라이언트의 관점에서 모든 데이터베이스 노드는 동일합니다. 백그라운드에서 수십 개 또는 수백 개의 노드가 작동하고 있더라도 단일 머신 시스템의 일관성을 보장하는 단일 논리 데이터베이스로 나타납니다.
NewSQL 데이터베이스의 메커니즘에 대한 자세한 내용은 DASH: Four Properties of Kubernetes-Native Databases(DASH: Kubernetes-Native Databases의 네 가지 속성) 문서를 참조하세요.
클라우드로의 데이터 마이그레이션
시간이 많이 걸리는 작업 중 하나는 데이터를 한 데이터 플랫폼에서 다른 데이터 플랫폼으로 마이그레이션하는 것입니다. Azure Data Migration Service를 사용하면 이러한 작업을 신속하게 수행할 수 있습니다. 가동 중지 시간을 최소화하면서 여러 외부 데이터베이스 원본에서 Azure Data 플랫폼으로 데이터를 마이그레이션할 수 있습니다. 대상 플랫폼에는 다음 서비스가 포함됩니다.
- Azure SQL 데이터베이스
- Azure Database for MySQL (MySQL을 위한 Azure 데이터베이스)
- MariaDB를 위한 Azure 데이터베이스
- PostgreSQL용 Azure 데이터베이스
- Azure Cosmos DB (애저 코스모스 DB)
이 서비스는 규모가 작거나 큰 마이그레이션을 실행하는 데 필요한 변경 내용을 안내하는 권장 사항을 제공합니다.
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET