Microsoft Fabric은 분석 환경으로 데이터를 가져오는 여러 가지 방법을 제공합니다. 스트리밍 이벤트를 실시간으로 처리하거나, 운영 데이터베이스를 복제하거나, 일괄 처리 파이프라인을 오케스트레이션하거나, 데이터를 복사하지 않고 데이터에 액세스해야 하는지에 관계없이 Fabric은 각 시나리오를 지원하는 기본 제공 기능을 제공합니다.
이 문서에서는 Fabric의 기본 데이터 수집 및 데이터 이동 옵션에 대해 설명합니다. 다음을 다룹니다.
- Eventstreams 및 Eventhouse를 사용한 실시간 데이터 통합
- 일괄 처리 오케스트레이션을 Data Factory 파이프라인 및 복사 작업을 통해 수행합니다.
- 미러링을 사용하여 근 실시간 복제
- OneLake 바로 가기를 사용하여 데이터 가상화
이 개요를 사용하여 각 접근 방식의 작동 방식을 이해하고 대기 시간, 변환 및 운영 복잡성에 대한 워크로드 요구 사항에 가장 적합한 전략을 선택합니다.
실시간 데이터 수집
Real-Time Intelligence 워크로드의 Eventstreams 및 Eventhouse 항목은 스트리밍 데이터 시나리오를 지원합니다. Eventstreams는 실시간 이벤트를 수집하고 처리하며 Eventhouses는 대규모로 해당 이벤트를 저장하고 쿼리합니다. 일반적으로 Eventstream을 사용하여 데이터를 캡처하고 Eventhouse로 라우팅합니다. 요구 사항에 따라 각 기능을 독립적으로 사용할 수도 있습니다. 다음 다이어그램은 실시간 데이터 세트가 패브릭의 Eventstream 및 Eventhouse로 흐르는 방법을 보여 줍니다.
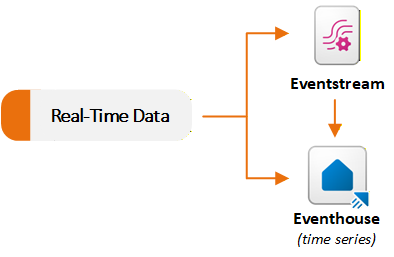
Eventstream을 사용하여 이벤트 수집 및 라우팅
Eventstream 은 패브릭으로 이벤트를 수집하고, 스트림 내 변환을 적용하고, 데이터를 여러 대상으로 라우팅하는 코드 없는 환경을 제공합니다. Eventstream은 실시간 수집 파이프라인 역할을 합니다. Eventstream을 만들고 하나 이상의 원본 커넥터를 추가합니다. Fabric은 패브릭 작업 영역 이벤트, OneLake 파일 이벤트 및 파이프라인 작업 이벤트와 같은 내부 패브릭 이벤트를 포함하여 많은 스트리밍 원본을 지원합니다.
이벤트가 흐르기 시작하면 끌어서 놓기 편집기를 통해 선택적 실시간 변환을 적용할 수 있습니다. 예를 들어 코드를 작성하지 않고 이벤트를 필터링하거나, 시간 창 집계를 계산하거나, 여러 스트림을 조인하거나, 필드를 다시 변경할 수 있습니다.
처리된 스트림을 하나 이상의 지원되는 대상으로 보낼 수 있습니다. Eventstreams는 사용자 지정 엔드포인트 원본 및 대상을 통해 Apache Kafka 엔드포인트를 노출할 수 있습니다. 이 기능을 사용하면 Kafka 생산자가 이벤트를 Fabric으로 스트리밍하고 Kafka 소비자가 Fabric에서 이벤트를 수신할 수 있습니다.
Eventstreams는 데이터를 영구적으로 저장하지 않습니다. 메모리를 통해 이벤트를 스트리밍하고 구성된 대상으로 전달합니다. 이 설계를 통해 Eventstreams는 실시간 ETL(추출, 변환, 로드) 시나리오 및 스트리밍 데이터를 여러 대상에 배포하는 데 적합합니다. 예를 들어 IoT(사물 인터넷) 센서에서 원격 분석을 수집하고, 실시간으로 데이터를 필터링 및 집계하고, 분석을 위해 구체화된 스트림을 Eventhouse로 보내고, 경고를 위해 변칙 이벤트를 Activator로 라우팅할 수 있습니다.
Eventhouse에 직접 데이터 수집
Eventhouses는 여러 원본에서 직접 데이터를 수집할 수 있습니다. 패브릭에는 Eventhouse 내에서 통합 된 데이터 가져오기 환경이 포함되어 있습니다. 마법사는 로컬 파일, Azure Storage, Amazon S3, Azure Event Hubs 및 OneLake와 같은 원본에 연결합니다. Eventhouse 사용자 인터페이스를 사용하여 실시간으로 또는 일괄 처리 모드에서 KQL(Kusto Query Language) 데이터베이스 테이블에 데이터를 로드할 수 있습니다.
패브릭에서 기존 Eventstream을 원본으로 선택할 수도 있습니다. 예를 들어 IoT Hub 또는 Kafka에서 데이터를 수집하는 Eventstream을 사용하는 경우 추가 구성 없이 해당 출력을 KQL 데이터베이스 테이블로 직접 라우팅할 수 있습니다.
배치 데이터 적재
Data Factory는 기존의 ETL(추출, 변환, 로드) 및 ELT(추출, 로드, 변환) 파이프라인에 대한 기본 환경을 제공합니다. 여기에는 대형 커넥터 라이브러리가 포함되어 있습니다. Fabric Data Factory는 데이터베이스, SaaS(Software as a Service) 애플리케이션 및 파일 기반 시스템을 포함하여 온-프레미스 및 클라우드 데이터 저장소에 대한 네이티브 커넥터 목록을 제공합니다. 이러한 커넥터는 거의 모든 원본 시스템에 연결하는 데 도움이 됩니다.
파이프라인을 사용하여 데이터 이동을 조율합니다.
이러한 커넥터를 사용하여 OneLake 또는 분석 저장소로 데이터를 복사하거나 이동하는 파이프라인 을 빌드할 수 있습니다. 이 방법은 다음을 지원합니다.
- 이미지, 비디오 및 오디오와 같은 구조화되지 않은 데이터 세트
- JSON, CSV 및 XML과 같은 반구조화된 데이터 세트
- 지원되는 관계형 데이터베이스 시스템의 구조적 데이터 세트
파이프라인에서는 여러 오케스트레이션 구성 요소를 다음과 같이 결합합니다.
- 데이터 복사 및 복사 작업과 같은 데이터 이동 작업
- 데이터 흐름 Gen2, 데이터 삭제, 패브릭 Notebook 및 SQL 스크립트와 같은 데이터 변환 작업
- ForEach, 조회, 변수 설정 및 웹후크와 같은 흐름 작업 제어
요청 시, 일정에 따라 또는 이벤트에 대한 응답으로 파이프라인을 실행할 수 있습니다. 예를 들어 평일 2시간마다 실행되도록 파이프라인을 예약하거나 OneLake에서 새 파일을 만들 때 트리거할 수 있습니다.
복사 작업을 사용하여 데이터 이동 간소화
복사 작업은 대량 복사, 증분 복사 및 CDC(변경 데이터 캡처) 복제를 비롯한 여러 데이터 배달 패턴을 지원합니다. 복사 작업을 사용하여 파이프라인을 만들지 않고 원본에서 OneLake로 데이터를 이동하면서 고급 구성 옵션에 계속 액세스할 수 있습니다. 복사 작업은 많은 원본 및 대상을 지원합니다. 복사 작업을 사용하는 파이프라인을 관리하는 것보다 미러링보다 제어가 더 많고 운영 복잡성이 줄어듭니다.
미러링을 사용하여 데이터 복제
미러링이 자동화된 설치를 통해 거의 실시간으로 외부 시스템의 데이터를 패브릭으로 복제합니다. Azure SQL Database, SQL Server, Oracle, SAP 또는 Snowflake와 같은 외부 시스템에 연결합니다. 패브릭은 데이터 또는 메타데이터를 OneLake에 지속적으로 복제합니다. 미러링에서는 다음 세 가지 유형을 지원합니다.
- 데이터베이스 미러링이 전체 데이터베이스 및 테이블을 복제합니다.
- 메타데이터 미러링에서는 데이터를 물리적으로 이동하는 대신 카탈로그 이름, 스키마 및 테이블과 같은 메타데이터를 동기화합니다. 이 방법은 패브릭에서 계속 액세스할 수 있는 동안 데이터가 원본 시스템에 유지되도록 바로 가기를 사용합니다.
- 개방형 미러링 에서는 개방형 Delta Lake 테이블 형식을 사용합니다. 개발자는 공용 API를 사용하여 OneLake의 미러된 데이터베이스 항목에 애플리케이션 변경 내용을 직접 작성할 수 있습니다.
패브릭은 변경 데이터 캡처 또는 유사한 방법을 통해 원본 시스템 변경 내용을 수신 대기하고 미러된 복사본에 거의 실시간으로 해당 변경 내용을 적용합니다. 결과는 복잡한 ETL 파이프라인 없이 짧은 대기 시간과 동기화된 상태로 유지되는 쿼리 가능한 라이브 데이터 세트입니다.
미러링에서는 현재 Azure SQL Database, SQL Managed Instance, Azure Cosmos DB, Azure Database for PostgreSQL, Google BigQuery, Oracle, SAP, Snowflake 및 SQL Server를 비롯한 다양한 원본을 지원합니다. 또한 Open Mirroring API를 구현한 파트너 솔루션의 데이터 원본을 지원합니다. 미러된 데이터는 oneLake에 up-to-date Delta 테이블로 저장됩니다. 패브릭은 이러한 테이블을 자동으로 유지 관리하므로 실시간 분석에 사용하거나 다른 패브릭 데이터와 결합할 수 있습니다. 이 기능은 운영 데이터가 분석 플랫폼으로 지속적으로 흐르는 하이브리드 트랜잭션 및 분석 처리 시나리오를 지원합니다.
미러링을 통해 증분 부하 파이프라인을 수동으로 빌드할 필요가 없습니다. 미러링 비용 관점에서 미러된 데이터베이스를 동기화 상태로 유지하는 컴퓨팅 작업은 패브릭 용량의 CPU(용량 단위)를 사용하지 않습니다. OneLake의 미러된 데이터 스토리지는 패브릭 SKU의 테라바이트 한도까지 무료입니다(예: F64에는 64TB의 무료 미러된 데이터베이스 스토리지가 포함됨).
바로 가기를 사용하여 외부 데이터에 액세스
Fabric은 데이터 가상화를 활성화하는 바로 가기를 제공합니다. OneLake의 바로 가기는 Azure Data Lake Storage Gen2, Amazon S3 또는 SharePoint와 같은 외부 시스템에 저장된 데이터를 참조합니다. 바로 가기를 사용하면 데이터를 복사하는 대신 OneLake가 통합 데이터 레이크의 일부로 외부 파일을 참조할 수 있습니다. 초기 마이그레이션을 수행하지 않고도 외부 데이터를 로컬 데이터와 쿼리하거나 조인할 수 있습니다. 이 복사되지 않은 수집 방법은 데이터 상주 요구 사항 또는 중복 문제가 데이터 이동을 방지하는 경우에 유용합니다. 다음 다이어그램은 바로 가기가 데이터를 복사하지 않고 외부 스토리지 시스템을 패브릭 항목에 연결하는 방법을 보여 줍니다.
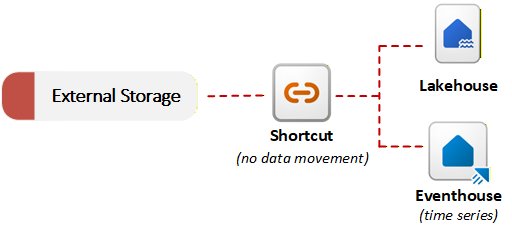
OneLake는 바로 가기에서 참조하는 데이터 형식을 검색하고 파이프라인 또는 사용자 지정 코드 없이 파일 변환 또는 AI 변환 을 적용할 수 있습니다. OneLake는 원본과 자동으로 동기화된 결과 델타 테이블을 유지 관리합니다. 예를 들어, .csv 파일을 델타 테이블로 변환하거나 .txt 파일에 AI 기반 감정 분석을 폴더에 적용할 수 있습니다.
미러링과 결합된 바로 가기는 유연한 데이터 액세스 패턴을 제공합니다. 바로 가기를 사용하여 데이터를 제자리에 유지하거나 미러링을 사용하여 데이터를 복제할 수 있습니다. 두 경우 모두 복잡한 ETL 없이 패브릭 분석 도구에 대한 데이터가 준비됩니다.
의사 결정 가이드: 데이터 이동 전략 선택
Microsoft Fabric은 실시간 처리를 위한 Eventstreams, 미러링, 복사 작업이 있는 파이프라인, 복사 작업 및 바로 가기를 포함하여 패브릭으로 데이터를 가져오는 몇 가지 옵션을 제공합니다. 각 옵션은 제어, 자동화 및 운영 복잡성의 다른 균형을 제공합니다.
시나리오에 적합한 방법을 선택하는 방법에 대한 지침은 Microsoft Fabric 의사 결정 가이드: 데이터 이동 전략 선택을 참조하세요.