Troubleshoot performance issues with Intelligent Insights - Azure SQL Database & Azure SQL Managed Instance
Applies to: ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
This page provides information on Azure SQL Database and Azure SQL Managed Instance performance issues detected through the Intelligent Insights resource log. Metrics and resource logs can be streamed to Azure Monitor logs, Azure Event Hubs, Azure Storage, or a third-party solution for custom DevOps alerting and reporting capabilities.
Note
For a quick performance troubleshooting guide using Intelligent Insights, see the Recommended troubleshooting flow flowchart in this document.
Intelligent insights is a preview feature, not available in the following regions: West Europe, North Europe, West US 1 and East US 1.
Detectable database performance patterns
Intelligent Insights automatically detects performance issues based on query execution wait times, errors, or time-outs. Intelligent Insights outputs detected performance patterns to the resource log. Detectable performance patterns are summarized in the table below.
| Detectable performance patterns | Azure SQL Database | Azure SQL Managed Instance |
|---|---|---|
| Reaching resource limits | Consumption of available resources, database worker threads, or database login sessions available on the monitored subscription has reached its resource limits. This is affecting performance. | Consumption of CPU resources is reaching its resource limits. This is affecting the database performance. |
| Workload increase | Workload increase or continuous accumulation of workload on the database was detected. This is affecting performance. | Workload increase has been detected. This is affecting the database performance. |
| Memory pressure | Workers that requested memory grants have to wait for memory allocations for statistically significant amounts of time, or an increased accumulation of workers that requested memory grants exist. This is affecting performance. | Workers that have requested memory grants are waiting for memory allocations for a statistically significant amount of time. This is affecting the database performance. |
| Locking | Excessive database locking was detected affecting performance. | Excessive database locking was detected affecting the database performance. |
| Increased MAXDOP | The maximum degree of parallelism option (MAXDOP) has changed affecting the query execution efficiency. This is affecting performance. | The maximum degree of parallelism option (MAXDOP) has changed affecting the query execution efficiency. This is affecting performance. |
| Pagelatch contention | Multiple threads are concurrently attempting to access the same in-memory data buffer pages resulting in increased wait times and causing pagelatch contention. This is affecting performance. | Multiple threads are concurrently attempting to access the same in-memory data buffer pages resulting in increased wait times and causing pagelatch contention. This is affecting database the performance. |
| Missing Index | Missing index was detected affecting performance. | Missing index was detected affecting the database performance. |
| New Query | New query was detected affecting the overall performance. | New query was detected affecting the overall database performance. |
| Increased Wait Statistic | Increased database wait times were detected affecting performance. | Increased database wait times were detected affecting the database performance. |
| TempDB Contention | Multiple threads are trying to access the same tempdb resource causing a bottleneck. This is affecting performance. |
Multiple threads are trying to access the same tempdb resource causing a bottleneck. This is affecting the database performance. |
| Elastic pool DTU shortage | Shortage of available eDTUs in the elastic pool is affecting performance. | Not available for Azure SQL Managed Instance as it uses the vCore model. |
| Plan Regression | New plan, or a change in the workload of an existing plan was detected. This is affecting performance. | New plan, or a change in the workload of an existing plan was detected. This is affecting the database performance. |
| Database-scoped configuration value change | Configuration change on the database was detected affecting the database performance. | Configuration change on the database was detected affecting the database performance. |
| Slow client | Slow application client is unable to consume output from the database fast enough. This is affecting performance. | Slow application client is unable to consume output from the database fast enough. This is affecting the database performance. |
| Pricing tier downgrade | Pricing tier downgrade action decreased available resources. This is affecting performance. | Pricing tier downgrade action decreased available resources. This is affecting the database performance. |
Tip
For continuous performance optimization of databases, enable automatic tuning. This built-in intelligence feature continuously monitors your database, automatically tunes indexes, and applies query execution plan corrections.
The following section describes detectable performance patterns in more detail.
Reaching resource limits
What is happening
This detectable performance pattern combines performance issues that are related to reaching available resource limits, worker limits, and session limits. After this performance issue is detected, a description field of the diagnostics log indicates whether the performance issue is related to resource, worker, or session limits.
Resources on Azure SQL Database are typically referred to DTU or vCore resources, and resources on Azure SQL Managed Instance are referred to as vCore resources. The pattern of reaching resource limits is recognized when detected query performance degradation is caused by reaching any of the measured resource limits.
The session limits resource denotes the number of available concurrent logins to the database. This performance pattern is recognized when applications that are connected to the databases have reached the number of available concurrent logins to the database. If applications attempt to use more sessions than are available on a database, the query performance is affected.
Reaching worker limits is a specific case of reaching resource limits because available workers aren't counted in the DTU or vCore usage. Reaching worker limits on a database can cause the rise of resource-specific wait times, which results in query performance degradation.
Troubleshoot resource limits
The diagnostics log outputs query hashes of queries that affected the performance and resource consumption percentages. You can use this information as a starting point for optimizing your database workload. In particular, you can optimize the queries that affect the performance degradation by adding indexes. Or you can optimize applications with a more even workload distribution. If you're unable to reduce workloads or make optimizations, consider increasing the pricing tier of your database subscription to increase the amount of resources available.
If you have reached the available session limits, you can optimize your applications by reducing the number of logins made to the database. If you're unable to reduce the number of logins from your applications to the database, consider increasing the pricing tier of your database subscription. Or you can split and move your database into multiple databases for a more balanced workload distribution.
For more suggestions on resolving session limits, see How to deal with the limits of maximum logins. See Resource management in Azure SQL Database for information about limits at the server and subscription levels.
Workload increase
What is happening
This performance pattern identifies issues caused by a workload increase or, in its more severe form, a workload pile-up.
This detection is made through a combination of several metrics. The basic metric measured is detecting an increase in workload compared with the past workload baseline. The other form of detection is based on measuring a large increase in active worker threads that is large enough to affect the query performance.
In its more severe form, the workload might continuously pile up due to the inability of a database to handle the workload. The result is a continuously growing workload size, which is the workload pile-up condition. Due to this condition, the time that the workload waits for execution grows. This condition represents one of the most severe database performance issues. This issue is detected through monitoring the increase in the number of aborted worker threads.
Troubleshoot workload growth
The diagnostics log outputs the number of queries whose execution has increased and the query hash of the query with the largest contribution to the workload increase. You can use this information as a starting point for optimizing the workload. The query identified as the largest contributor to the workload increase is especially useful as your starting point.
You might consider distributing the workloads more evenly to the database. Consider optimizing the query that is affecting the performance by adding indexes. You also might distribute your workload among multiple databases. If these solutions aren't possible, consider increasing the pricing tier of your database subscription to increase the amount of resources available.
Memory pressure
What is happening
This performance pattern indicates degradation in the current database performance caused by memory pressure, or in its more severe form a memory pile-up condition, compared to the past seven-day performance baseline.
Memory pressure denotes a performance condition in which there is a large number of worker threads requesting memory grants. The high volume causes a high memory utilization condition in which the database is unable to efficiently allocate memory to all workers that request it. One of the most common reasons for this issue is related to the amount of memory available to the database on one hand. On the other hand, an increase in workload causes the increase in worker threads and the memory pressure.
The more severe form of memory pressure is the memory pile-up condition. This condition indicates that a higher number of worker threads are requesting memory grants than there are queries releasing the memory. This number of worker threads requesting memory grants also might be continuously increasing (piling up) because the database engine is unable to allocate memory efficiently enough to meet the demand. The memory pile-up condition represents one of the most severe database performance issues.
Troubleshoot memory pressure
The diagnostics log outputs the memory object store details with the clerk (that is, worker thread) marked as the highest reason for high memory usage and relevant time stamps. You can use this information as the basis for troubleshooting.
You can optimize or remove queries related to the clerks with the highest memory usage. You also can make sure that you aren't querying data that you don't plan to use. Good practice is to always use a WHERE clause in your queries. In addition, we recommend that you create nonclustered indexes to seek the data rather than scan it.
You also can reduce the workload by optimizing or distributing it over multiple databases. Or you can distribute your workload among multiple databases. If these solutions aren't possible, consider increasing the pricing tier of your database to increase the amount of memory resources available to the database.
For additional troubleshooting suggestions, see Memory grants meditation: The mysterious SQL Server memory consumer with many names. For more information on out of memory errors in Azure SQL Database, see Troubleshoot out of memory errors with Azure SQL Database.
Locking
What is happening
This performance pattern indicates degradation in the current database performance in which excessive database locking is detected compared to the past seven-day performance baseline.
In modern RDBMS, locking is essential for implementing multithreaded systems in which performance is maximized by running multiple simultaneous workers and parallel database transactions where possible. Locking in this context refers to the built-in access mechanism in which only a single transaction can exclusively access the rows, pages, tables, and files that are required and not compete with another transaction for resources. When the transaction that locked the resources for use is done with them, the lock on those resources is released, which allows other transactions to access required resources. For more information on locking, see Lock in the database engine.
If transactions executed by the SQL engine are waiting for prolonged periods of time to access resources locked for use, this wait time causes the slowdown of the workload execution performance.
Troubleshoot locking and blocking
The diagnostics log outputs locking details that you can use as the basis for troubleshooting. You can analyze the reported blocking queries, that is, the queries that introduce the locking performance degradation, and remove them. In some cases, you might be successful in optimizing the blocking queries.
The simplest and safest way to mitigate the issue is to keep transactions short and to reduce the lock footprint of the most expensive queries. You can break up a large batch of operations into smaller operations. Good practice is to reduce the query lock footprint by making the query as efficient as possible. Reduce large scans because they increase chances of deadlocks and adversely affect overall database performance. For identified queries that cause locking, you can create new indexes or add columns to the existing index to avoid the table scans.
For more suggestions, see:
- Understand and resolve Azure SQL Database blocking problems
- How to resolve blocking problems that are caused by lock escalation in SQL Server
Increased MAXDOP
What is happening
This detectable performance pattern indicates a condition in which a chosen query execution plan was parallelized more than it should have been. The query optimizer can enhance the workload performance by executing queries in parallel to speed up things where possible. In some cases, parallel workers processing a query spend more time waiting on each other to synchronize and merge results compared to executing the same query with fewer parallel workers, or even in some cases compared to a single worker thread.
The expert system analyzes the current database performance compared to the baseline period. It determines if a previously running query is running slower than before because the query execution plan is more parallelized than it should be.
The MAXDOP server configuration option is used to control how many CPU cores can be used to execute the same query in parallel.
Troubleshoot parallelism
The diagnostics log outputs query hashes related to queries for which the duration of execution increased because they were parallelized more than they should have been. The log also outputs CXP wait times. This time represents the time a single organizer/coordinator thread (thread 0) is waiting for all other threads to finish before merging the results and moving ahead. In addition, the diagnostics log outputs the wait times that the poor-performing queries were waiting in execution overall. You can use this information as the basis for troubleshooting.
First, optimize or simplify complex queries. Good practice is to break up long batch jobs into smaller ones. In addition, ensure that you created indexes to support your queries. You can also manually enforce the maximum degree of parallelism (MAXDOP) for a query that was flagged as poor performing. To configure this operation by using T-SQL, see Configure the MAXDOP server configuration option.
Setting the MAXDOP server configuration option to zero (0) as a default value denotes that database can use all available CPU cores to parallelize threads for executing a single query. Setting MAXDOP to one (1) denotes that only one core can be used for a single query execution. In practical terms, this means that parallelism is turned off. Depending on the case-per-case basis, available cores to the database, and diagnostics log information, you can tune the MAXDOP option to the number of cores used for parallel query execution that might resolve the issue in your case.
Pagelatch contention
What is happening
This performance pattern indicates the current database workload performance degradation due to pagelatch contention compared to the past seven-day workload baseline.
Latches are lightweight synchronization mechanisms used to enable multithreading. They guarantee consistency of in-memory structures that include indices, data pages, and other internal structures.
There are many types of latches available. For simplicity purposes, buffer latches are used to protect in-memory pages in the buffer pool. IO latches are used to protect pages not yet loaded into the buffer pool. Whenever data is written to or read from a page in the buffer pool, a worker thread needs to acquire a buffer latch for the page first. Whenever a worker thread attempts to access a page that isn't already available in the in-memory buffer pool, an IO request is made to load the required information from the storage. This sequence of events indicates a more severe form of performance degradation.
Contention on the page latches occurs when multiple threads concurrently attempt to acquire latches on the same in-memory structure, which introduces an increased wait time to query execution. In the case of pagelatch IO contention, when data needs to be accessed from storage, this wait time is even larger. It can affect workload performance considerably. Pagelatch contention is the most common scenario of threads waiting on each other and competing for resources on multiple CPU systems.
Troubleshoot pagelatch contention
The diagnostics log outputs pagelatch contention details. You can use this information as the basis for troubleshooting.
Because a pagelatch is an internal control mechanism, it automatically determines when to use them. Application decisions, including schema design, can affect pagelatch behavior due to the deterministic behavior of latches.
One method for handling latch contention is to replace a sequential index key with a nonsequential key to evenly distribute inserts across an index range. Typically, a leading column in the index distributes the workload proportionally. Another method to consider is table partitioning. Creating a hash partitioning scheme with a computed column on a partitioned table is a common approach for mitigating excessive latch contention. In the case of pagelatch IO contention, introducing indexes helps to mitigate this performance issue.
For more information, see Diagnose and resolve latch contention on SQL Server (PDF download).
Missing index
What is happening
This performance pattern indicates the current database workload performance degradation compared to the past seven-day baseline due to a missing index.
An index is used to speed up the performance of queries. It provides quick access to table data by reducing the number of dataset pages that need to be visited or scanned.
Specific queries that caused performance degradation are identified through this detection for which creating indexes would be beneficial to the performance.
Troubleshoot expensive queries with indexes
The diagnostics log outputs query hashes for the queries that were identified to affect the workload performance. You can build indexes for these queries. You also can optimize or remove these queries if they aren't required. A good performance practice is to avoid querying data that you don't use.
Tip
Did you know that built-in intelligence can automatically manage the best-performing indexes for your databases?
For continuous performance optimization, we recommend that you enable automatic tuning. This unique built-in intelligence feature continuously monitors your database and automatically tunes and creates indexes for your databases.
New query
What is happening
This performance pattern indicates that a new query is detected that is performing poorly and affecting the workload performance compared to the seven-day performance baseline.
Writing a good-performing query sometimes can be a challenging task. For more information on writing queries, see Writing SQL queries. To optimize existing query performance, see Query tuning.
Troubleshoot query performance
The diagnostics log outputs information up to two new most CPU-consuming queries, including their query hashes. Because the detected query affects the workload performance, you can optimize your query. Good practice is to retrieve only data you need to use. We also recommend using queries with a WHERE clause. We also recommend that you simplify complex queries and break them up into smaller queries. Another good practice is to break down large batch queries into smaller batch queries. Introducing indexes for new queries is typically a good practice to mitigate this performance issue.
In Azure SQL Database, consider using Query Performance Insight for Azure SQL Database.
Increased wait statistic
What is happening
This detectable performance pattern indicates a workload performance degradation in which poor-performing queries are identified compared to the past seven-day workload baseline.
In this case, the system can't classify the poor-performing queries under any other standard detectable performance categories, but it detected the wait statistic responsible for the regression. Therefore, it considers them as queries with increased wait statistics, where the wait statistic responsible for the regression is also exposed.
Troubleshoot wait stats
The diagnostics log outputs information on increased wait time details and query hashes of the affected queries.
Because the system couldn't successfully identify the root cause for the poor-performing queries, the diagnostics information is a good starting point for manual troubleshooting. You can optimize the performance of these queries. A good practice is to fetch only data you need to use and to simplify and break down complex queries into smaller ones.
For more information on optimizing query performance, see Query tuning.
Tempdb contention
What is happening
This detectable performance pattern indicates a database performance condition in which a bottleneck of threads trying to access tempdb resources exists. (This condition isn't IO-related.) The typical scenario for this performance issue is hundreds of concurrent queries that all create, use, and then drop small tempdb tables. The system detected that the number of concurrent queries using the same tempdb tables increased with sufficient statistical significance to affect database performance compared to the past seven-day performance baseline.
Troubleshoot tempdb contention
The diagnostics log outputs tempdb contention details. You can use the information as the starting point for troubleshooting. There are two things you can pursue to alleviate this kind of contention and increase the throughput of the overall workload: You can stop using the temporary tables. You also can use memory-optimized tables.
For more information, see Introduction to memory-optimized tables.
Elastic pool DTU shortage
What is happening
This detectable performance pattern indicates a degradation in the current database workload performance compared to the past seven-day baseline. It's due to the shortage of available DTUs in the elastic pool of your subscription.
Azure elastic pool resources are used as a pool of available resources shared between multiple databases for scaling purposes. When available eDTU resources in your elastic pool aren't sufficiently large to support all the databases in the pool, an elastic pool DTU shortage performance issue is detected by the system.
Troubleshoot elastic pool DTU shortage
The diagnostics log outputs information on the elastic pool, lists the top DTU-consuming databases, and provides a percentage of the pool's DTU used by the top-consuming database.
Because this performance condition is related to multiple databases using the same pool of eDTUs in the elastic pool, the troubleshooting steps focus on the top DTU-consuming databases. You can reduce the workload on the top-consuming databases, which includes optimization of the top-consuming queries on those databases. You also can ensure that you aren't querying data that you don't use. Another approach is to optimize applications by using the top DTU-consuming databases and redistribute the workload among multiple databases.
If reduction and optimization of the current workload on your top DTU-consuming databases aren't possible, consider increasing your elastic pool pricing tier. Such increase results in the increase of the available DTUs in the elastic pool.
Plan regression
What is happening
This detectable performance pattern denotes a condition in which the database utilizes a suboptimal query execution plan. The suboptimal plan typically causes increased query execution, which leads to longer wait times for the current and other queries.
The database engine determines the query execution plan with the least cost to a query execution. As the type of queries and workloads change, sometimes the existing plans are no longer efficient, or perhaps the database engine didn't make a good assessment. As a matter of correction, query execution plans can be manually forced.
This detectable performance pattern combines three different cases of plan regression: new plan regression, old plan regression, and existing plans changed workload. The particular type of plan regression that occurred is provided in the details property in the diagnostics log.
The new plan regression condition refers to a state in which the database engine starts executing a new query execution plan that isn't as efficient as the old plan. The old plan regression condition refers to the state when the database engine switches from using a new, more efficient plan to the old plan, which isn't as efficient as the new plan. The existing plans changed workload regression refers to the state in which the old and the new plans continuously alternate, with the balance going more toward the poor-performing plan.
For more information on plan regressions, see What is plan regression in SQL Server?
Troubleshoot plan regression
The diagnostics log outputs the query hashes, good plan ID, bad plan ID, and query IDs. You can use this information as the basis for troubleshooting.
You can analyze which plan is better performing for your specific queries that you can identify with the query hashes provided. After you determine which plan works better for your queries, you can manually force it.
For more information, see Learn how SQL Server prevents plan regressions.
Tip
Did you know that the built-in intelligence feature can automatically manage the best-performing query execution plans for your databases?
For continuous performance optimization, we recommend that you enable automatic tuning. This built-in intelligence feature continuously monitors your database and automatically tunes and creates best-performing query execution plans for your databases.
Database-scoped configuration value change
What is happening
This detectable performance pattern indicates a condition in which a change in the database-scoped configuration causes performance regression that is detected compared to the past seven-day database workload behavior. This pattern denotes that a recent change made to the database-scoped configuration doesn't seem to be beneficial to your database performance.
Database-scoped configuration changes can be set for each individual database. This configuration is used on a case-by-case basis to optimize the individual performance of your database. The following options can be configured for each individual database: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES, and CLEAR PROCEDURE_CACHE.
Troubleshoot database-scoped configuration changes
The diagnostics log outputs database-scoped configuration changes that were made recently that caused performance degradation compared to the previous seven-day workload behavior. You can revert the configuration changes to the previous values. You also can tune value by value until the desired performance level is reached. You can copy database-scope configuration values from a similar database with satisfactory performance. If you're unable to troubleshoot the performance, revert to the default values and attempt to fine-tune starting from this baseline.
For more information on optimizing database-scoped configuration and T-SQL syntax on changing the configuration, see Alter database-scoped configuration (Transact-SQL).
Slow client
What is happening
This detectable performance pattern indicates a condition in which the client using the database can't consume the output from the database as fast as the database sends the results. Because the database isn't storing results of the executed queries in a buffer, it slows down and waits for the client to consume the transmitted query outputs before proceeding. This condition also might be related to a network that isn't sufficiently fast enough to transmit outputs from the database to the consuming client.
This condition is generated only if a performance regression is detected compared to the past seven-day database workload behavior. This performance issue is detected only if a statistically significant performance degradation occurs compared to previous performance behavior.
Troubleshoot client-side applications
This detectable performance pattern indicates a client-side condition. Troubleshooting is required at the client-side application or client-side network. The diagnostics log outputs the query hashes and wait times that seem to be waiting the most for the client to consume them within the past two hours. You can use this information as the basis for troubleshooting.
You can optimize performance of your application for consumption of these queries. You also can consider possible network latency issues. Because the performance degradation issue was based on change in the last seven-day performance baseline, you can investigate whether recent application or network condition changes caused this performance regression event.
Price tier downgrade
What is happening
This detectable performance pattern indicates a condition in which the pricing tier of your database subscription was downgraded. Because of reduction of resources available to the database, the system detected a drop in the current database performance compared to the past seven-day baseline.
In addition, there could be a condition in which the pricing tier of your database subscription was downgraded and then upgraded to a higher tier within a short period of time. Detection of this temporary performance degradation is outputted in the details section of the diagnostics log as a pricing tier downgrade and upgrade.
Troubleshoot pricing tier downgrades
If you reduced your pricing tier, and you're satisfied with the performance, there's nothing you need to do. If you reduced your pricing tier and you're unsatisfied with your database performance, reduce your database workloads or consider increasing the pricing tier to a higher level.
Recommended troubleshooting flow
Follow the flowchart for a recommended approach to troubleshoot performance issues by using Intelligent Insights.
Access Intelligent Insights through the Azure portal by going to Azure SQL Analytics. Attempt to locate the incoming performance alert, and select it. Identify what is happening on the detections page. Observe the provided root cause analysis of the issue, query text, query time trends, and incident evolution. Attempt to resolve the issue by using the Intelligent Insights recommendation for mitigating the performance issue.
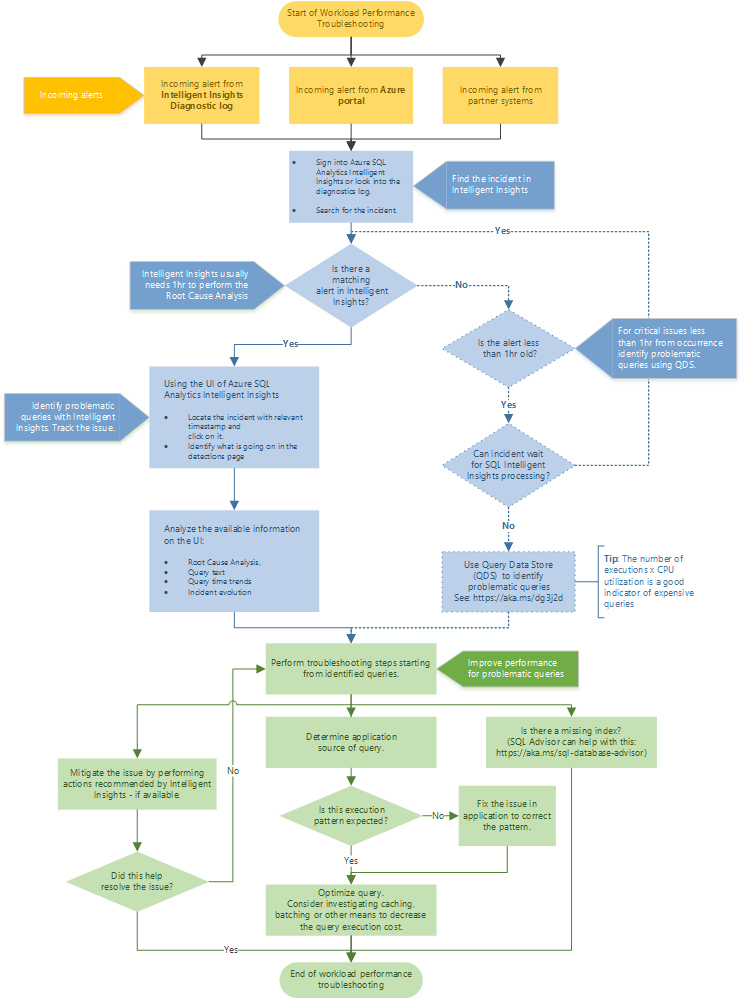
Tip
Select the flowchart to download a PDF version.
Intelligent Insights usually needs one hour of time to perform the root cause analysis of the performance issue. If you can't locate your issue in Intelligent Insights and it's critical to you, use the Query Store to manually identify the root cause of the performance issue. (Typically, these issues are less than one hour old.) For more information, see Monitor performance by using the Query Store.