Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
I denne opplæringen lærer du hvordan du utfører utforskende dataanalyse (EDA) for å undersøke og undersøke dataene mens du oppsummerer de viktigste egenskapene ved bruk av datavisualiseringsteknikker.
Du bruker seaborn, et Python-datavisualiseringsbibliotek som gir et grensesnitt på høyt nivå for å bygge visualobjekter på datarammer og matriser. Hvis du vil ha mer informasjon om seaborn, kan du se Seaborn: Visualisering av statistiske data.
Du vil også bruke Data Wrangler, et notatblokkbasert verktøy som gir deg en engasjerende opplevelse for å utføre utforskende dataanalyse og rengjøring.
Hovedtrinnene i denne opplæringen er:
- Les dataene som er lagret fra en deltatabell i lakehouse.
- Konverter en Spark DataFrame til Pandas DataFrame, som python-visualiseringsbiblioteker støtter.
- Bruk Data Wrangler til å utføre første datarengjøring og transformasjon.
- Utfør utforskende dataanalyse ved hjelp av
seaborn.
Forutsetninger
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis Prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bytt til Fabric ved å bruke erfaringsbryteren nederst til venstre på hjemmesiden din.

Dette er del 2 av 5 i opplæringsserien. Hvis du vil fullføre denne opplæringen, må du først fullføre:
Følg med i notatblokken
2-explore-cleanse-data.ipynb er notatblokken som følger med denne opplæringen.
Hvis du vil åpne den medfølgende notatblokken for denne opplæringen, følger du instruksjonene i Klargjøre systemet for opplæringer om datavitenskap importere notatblokken til arbeidsområdet.
Hvis du heller vil kopiere og lime inn koden fra denne siden, kan du opprette en ny notatblokk.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Viktig
Fest det samme lakehouse du brukte i del 1.
Les rådata fra lakehouse
Les rådata fra Files-delen av lakehouse. Du lastet opp disse dataene i den forrige notatblokken. Kontroller at du har festet det samme lakehouse du brukte i del 1 til denne notatblokken før du kjører denne koden.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Opprette en pandas DataFrame fra datasettet
Konverter spark DataFrame til pandas DataFrame for enklere behandling og visualisering.
df = df.toPandas()
Vis rådata
Utforsk rådataene med display, gjør noen grunnleggende statistikker og vis diagramvisninger. Vær oppmerksom på at du først må importere de nødvendige bibliotekene, for eksempel Numpy, Pnadas, Seabornog Matplotlib for dataanalyse og visualisering.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
Bruk Data Wrangler til å utføre første datarengjøring
Hvis du vil utforske og transformere eventuelle pandaer datarammer i notatblokken, starter du Data Wrangler direkte fra notatblokken.
Notat
Data-Wrangler kan ikke åpnes mens notatblokkkjernen er opptatt. Kjøringen av cellen må fullføres før du starter Data Wrangler.
- Velg Start data-Wrangler-under notatblokkbåndet Fanen Data . Du vil se en liste over aktiverte pandaer DataFrames tilgjengelig for redigering.
- Velg datarammen du vil åpne i Data Wrangler. Siden denne notatblokken bare inneholder én DataFrame, velger
dfdf.
Data Wrangler starter og genererer en beskrivende oversikt over dataene. Tabellen i midten viser hver datakolonne. Sammendragspanelet

Hver operasjon du gjør kan brukes i et spørsmål om klikk, oppdatere datavisningen i sanntid og generere kode som du kan lagre tilbake til notatblokken som en gjenbrukbar funksjon.
Resten av denne delen veileder deg gjennom trinnene for å utføre datarengjøring med Data Wrangler.
Slipp dupliserte rader
I venstre panel er en liste over operasjoner (for eksempel Søk etter og erstatt, Formater, Formler, numeriske) du kan utføre på datasettet.
Utvid Søk etter og erstatt, og velg Slipp dupliserte rader.
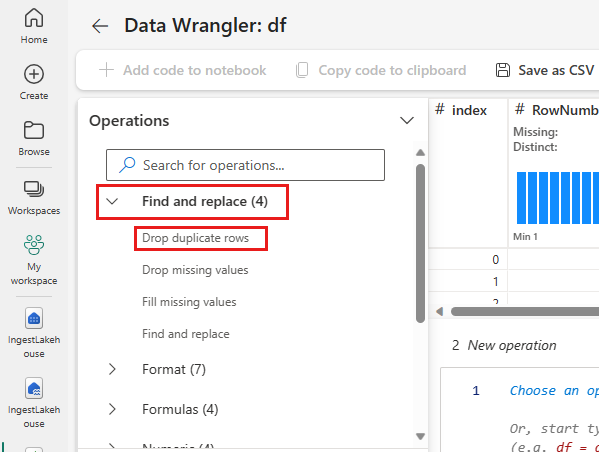
Det vises et panel der du kan velge listen over kolonner du vil sammenligne for å definere en duplisert rad. Velg RowNumber og CustomerId.
I det midterste panelet er en forhåndsvisning av resultatene av denne operasjonen. Under forhåndsvisningen er koden for å utføre operasjonen. I dette tilfellet ser dataene ut til å være uendret. Men siden du ser på en avkortet visning, er det lurt å fortsatt bruke operasjonen.
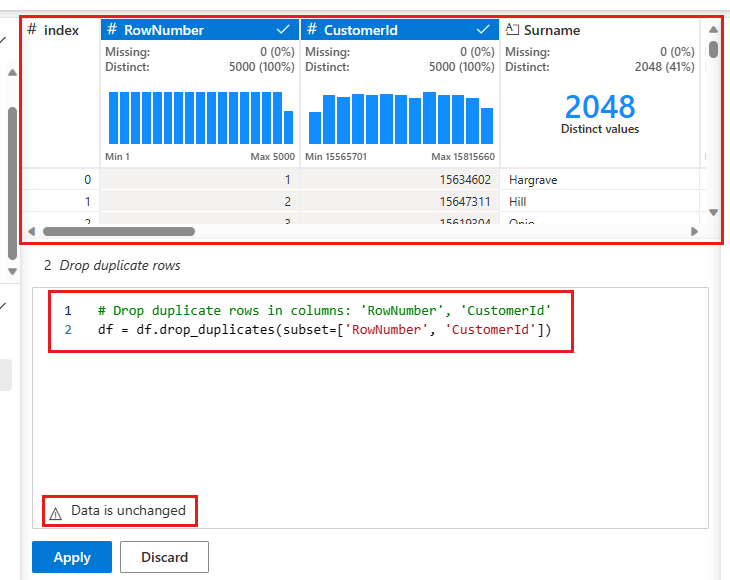
Velg Bruk (enten på siden eller nederst) for å gå til neste trinn.

Slipp rader med manglende data
Bruk Data Wrangler til å slippe rader med manglende data på tvers av alle kolonner.
Velg Slipp manglende verdier fra Søk etter og erstatt.
Velg Merk alle fra målkolonnene.
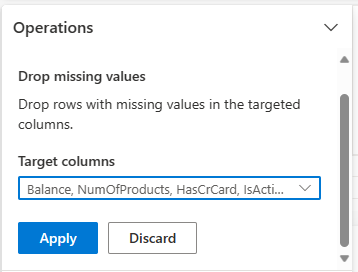
Velg Bruk for å gå videre til neste trinn.

Slipp kolonner
Bruk Data Wrangler til å slippe kolonner du ikke trenger.
Utvid skjema, og velg Slipp kolonner.
Velg RowNumber, CustomerId, Surname. Disse kolonnene vises i rødt i forhåndsvisningen for å vise at de er endret av koden (i dette tilfellet droppet.)
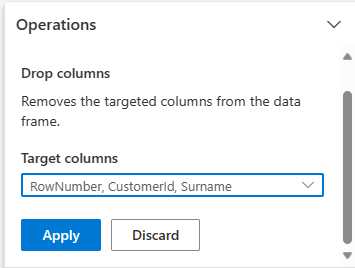
Velg Bruk for å gå videre til neste trinn.

Legge til kode i notatblokken
Hver gang du velger Bruk, opprettes et nytt trinn i Rengjøringstrinn panelet nederst til venstre. Nederst i panelet velger du forhåndsvisningskode for alle trinn for å vise en kombinasjon av alle de separate trinnene.
Velg Legg til kode i notatblokk øverst til venstre for å lukke Data Wrangler og legge til koden automatisk. Legg til kode i notatblokken bryter koden i en funksjon, og kaller deretter funksjonen.
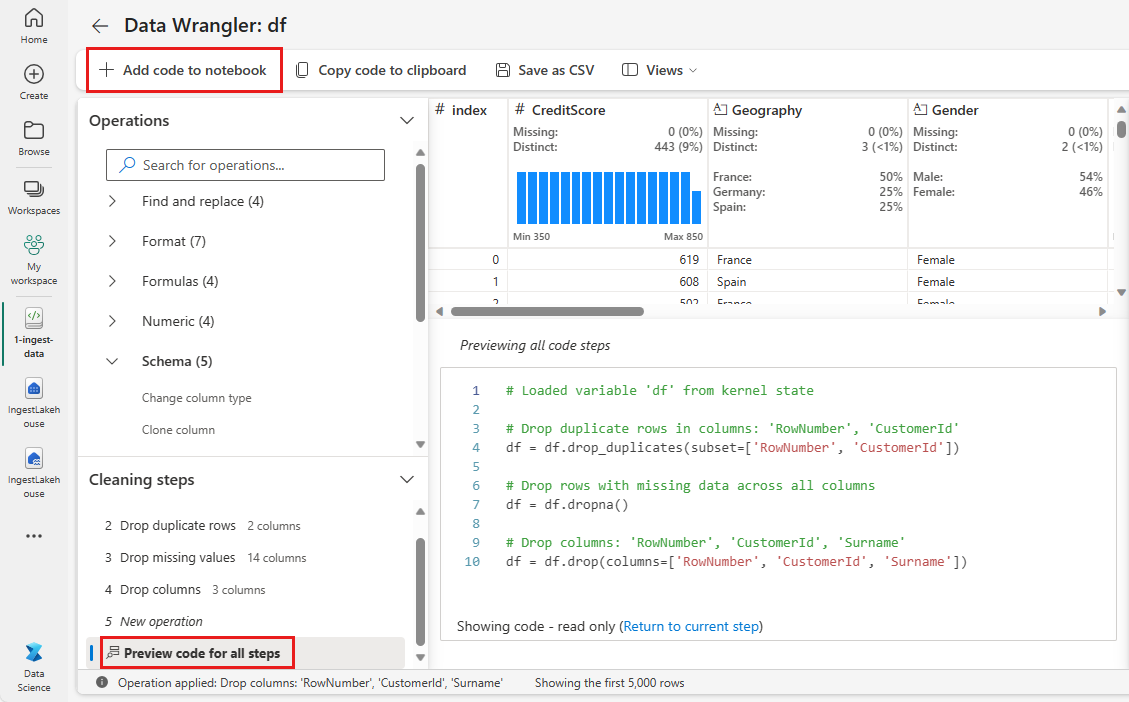
Tips
Koden som genereres av Data Wrangler, brukes ikke før du kjører den nye cellen manuelt.
Hvis du ikke brukte Data Wrangler, kan du i stedet bruke denne neste kodecellen.
Denne koden ligner koden som produseres av Data Wrangler, men legger i argumentet inplace=True til hver av de genererte trinnene. Ved å angi inplace=Trueoverskriver pandaer den opprinnelige DataFrame i stedet for å produsere en ny DataFrame som utdata.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Utforsk dataene
Vis noen sammendrag og visualiseringer av de rensede dataene.
Bestemme kategoriske, numeriske attributter og målattributter
Bruk denne koden til å bestemme kategoriske, numeriske attributter og målattributter.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Sammendrag med fem tall
Vis sammendraget med fem tall (minimumspoengsum, første kvartil, median, tredje kvartil, maksimal poengsum) for de numeriske attributtene ved hjelp av bokstegn.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
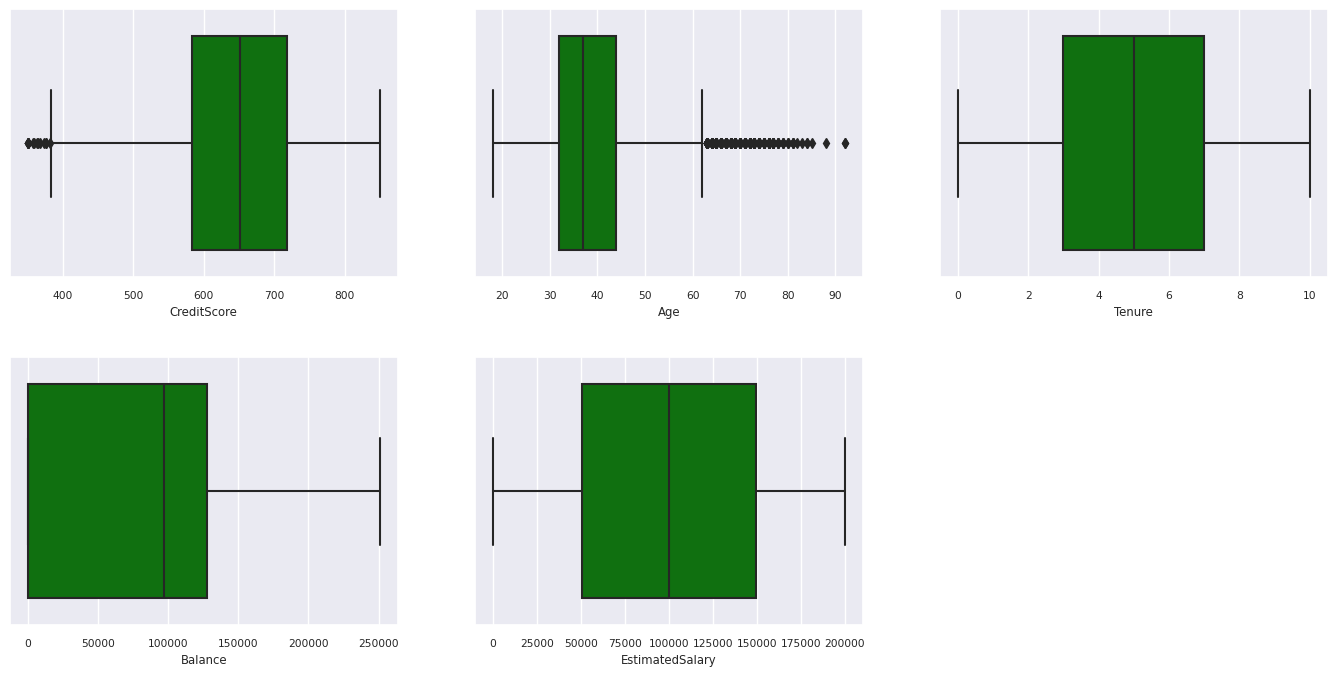
Distribusjon av avsluttede og ikke-skadelige kunder
Vis fordelingen av avsluttede eller ikke-skadelige kunder på tvers av de kategoriske attributtene.
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

Distribusjon av numeriske attributter
Vis frekvensfordelingen av numeriske attributter ved hjelp av histogram.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Utfør funksjonsteknikk
Utfør funksjonsteknikk for å generere nye attributter basert på gjeldende attributter:
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Bruk Data Wrangler til å utføre en varm koding
Data-Wrangler kan også brukes til å utføre en-varm koding. Hvis du vil gjøre dette, åpner du Data Wrangler på nytt. Denne gangen velger du de df_clean dataene.
- Utvid formler, og velg one-hot-kode.
- Det vises et panel der du kan velge listen over kolonner du vil utføre en varm koding på. Velg geografi og kjønn.
Du kan kopiere den genererte koden, lukke Data Wrangler for å gå tilbake til notatblokken, og deretter lime inn i en ny celle. Eller velg Legg til kode i notatblokk øverst til venstre for å lukke Data Wrangler og legge til koden automatisk.
Hvis du ikke brukte Data Wrangler, kan du i stedet bruke denne neste kodecellen:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Sammendrag av observasjoner fra den utforskende dataanalysen
- De fleste av kundene er fra Frankrike sammenlignet med Spania og Tyskland, mens Spania har den laveste churn rate sammenlignet med Frankrike og Tyskland.
- De fleste av kundene har kredittkort.
- Det finnes kunder som har en alders- og kredittvurdering på henholdsvis over 60 og under 400, men de kan ikke betraktes som ytterpunkter.
- Svært få kunder har mer enn to av bankens produkter.
- Kunder som ikke er aktive, har høyere frafallsrate.
- Kjønns- og ansettelsesår ser ikke ut til å ha noen innvirkning på kundens beslutning om å stenge bankkontoen.
Opprette en deltatabell for de rensede dataene
Du bruker disse dataene i den neste notatblokken i denne serien.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Neste trinn
Lær opp og registrer maskinlæringsmodeller med disse dataene: