Veiledning for Power BI-modellering for Power Platform
Microsoft Dataverse er standard dataplattform for mange Microsoft Business Application-produkter, inkludert Dynamics 365 Customer Engagement og Power Apps lerretsapper, og også Dynamics 365 Customer Voice (tidligere Microsoft Forms Pro), Power Automate-godkjenninger, Power Apps-portaler og andre.
Denne artikkelen gir veiledning om hvordan du oppretter en Power BI-datamodell som kobler til Dataverse. Den beskriver forskjeller mellom et Dataverse-skjema og et optimalisert Power BI-skjema, og gir veiledning for å utvide synligheten til forretningsprogramdataene i Power BI.
Datavers lagrer og administrerer et økende antall data i miljøer på tvers av organisasjoner på tvers av organisasjoner, på grunn av enkel konfigurasjon, rask distribusjon og omfattende innføring. Det betyr at det er enda større behov og muligheter til å integrere analyser med disse prosessene. Salgsmuligheter inkluderer:
- Rapporter om alle dataverse data som beveger seg utover begrensningene i de innebygde diagrammene.
- Gi enkel tilgang til relevante, kontekstavhengig filtrerte rapporter i en bestemt post.
- Forbedre verdien av dataverse data ved å integrere dem med eksterne data.
- Dra nytte av Power BIs innebygde kunstig intelligens (AI) uten å måtte skrive kompleks kode.
- Øk bruken av Power Platform-løsninger ved å øke nytten og verdien.
- Lever verdien av dataene i appen til beslutningstakere i bedriften.
Koble Power BI til Dataverse
Å koble Power BI til Dataverse innebærer å opprette en Power BI-datamodell. Du kan velge mellom tre metoder for å opprette en Power BI-modell.
- Importere dataverse data ved hjelp av Dataverse-koblingen: Denne metoden bufrer (lagrer) dataverse data i en Power BI-modell. Den leverer rask ytelse takket være spørring i minnet. Det gir også utformingsfleksibilitet til modellerere, slik at de kan integrere data fra andre kilder. På grunn av disse styrkene er import av data standardmodus når du oppretter en modell i Power BI Desktop.
- Importere dataverse data ved hjelp av Azure Synapse Link: Denne metoden er en variasjon på importmetoden, fordi den også bufrer data i Power BI-modellen, men gjør det ved å koble til Azure Synapse Analytics. Ved hjelp av Azure Synapse Link for Dataverse replikeres dataverse tabeller kontinuerlig til Azure Synapse eller Azure Data Lake Storage (ADLS) Gen2. Denne tilnærmingen brukes til å rapportere om hundretusener eller millioner av poster i dataverse miljøer.
- Opprette en DirectQuery-tilkobling ved hjelp av dataverskoblingen: Denne metoden er et alternativ til import av data. En DirectQuery-modell består bare av metadata som definerer modellstrukturen. Når en bruker åpner en rapport, sender Power BI opprinnelige spørringer til Dataverse for å hente data. Vurder å opprette en DirectQuery-modell når rapporter må vise dataverse data i nær sanntid, eller når Dataverse må håndheve rollebasert sikkerhet, slik at brukere bare kan se dataene de har tilgangsrettigheter til.
Viktig
Selv om en DirectQuery-modell kan være et godt alternativ når du trenger nær sanntidsrapportering eller håndhevelse av datavers sikkerhet i en rapport, kan det føre til treg ytelse for denne rapporten.
Du kan lære om vurderinger for DirectQuery senere i denne artikkelen.
Hvis du vil finne riktig metode for Power BI-modellen, bør du vurdere:
- Spørringsytelse
- Datavolum
- Ventetid for data
- Rollebasert sikkerhet
- Installasjonskompleksitet
Tips
Hvis du vil ha en detaljert diskusjon om modellrammeverk (import, DirectQuery eller sammensatt), fordelene og begrensningene og funksjonene for å optimalisere Power BI-datamodeller, kan du se Velg et rammeverk for Power BI-modeller.
Spørringsytelse
Spørringer som sendes til importmodeller, er raskere enn opprinnelige spørringer som sendes til DirectQuery-datakilder. Det er fordi importerte data bufres i minnet, og det er optimalisert for analytiske spørringer (filter, gruppe og sammendragsoperasjoner).
DirectQuery-modeller henter derimot bare data fra kilden etter at brukeren åpner en rapport, noe som resulterer i sekunder med forsinkelse etter hvert som rapporten gjengis. I tillegg krever brukersamhandlinger i rapporten at Power BI kan søke kilden på nytt, noe som reduserer responsstyrken ytterligere.
Datavolum
Når du utvikler en importmodell, bør du strebe etter å minimere dataene som lastes inn i modellen. Det gjelder spesielt for store modeller, eller modeller som du forventer vil vokse til å bli store over tid. Hvis du vil ha mer informasjon, kan du se Teknikker for datareduksjon for importmodellering.
En DirectQuery-tilkobling til Dataverse er et godt valg når rapportens spørringsresultat ikke er stort. Et stort spørringsresultat har mer enn 20 000 rader i rapportens kildetabeller, eller resultatet som returneres til rapporten etter at filtre er brukt, er mer enn 20 000 rader. I dette tilfellet kan du opprette en Power BI-rapport ved hjelp av dataverskoblingen.
Merk
Radstørrelsen på 20 000 er ikke en hard grense. Hver datakildespørring må imidlertid returnere et resultat innen 10 minutter. Senere i denne artikkelen vil du lære hvordan du arbeider innenfor disse begrensningene og om andre vurderinger av Dataverse DirectQuery-utformingen.
Du kan forbedre ytelsen til større semantiske modeller ved å bruke Datavers-koblingen til å importere dataene til datamodellen.
Enda større semantiske modeller – med flere hundretusener eller millioner rader – kan dra nytte av å bruke Azure Synapse Link for Dataverse. Denne fremgangsmåten setter opp et pågående administrert datasamlebånd som kopierer dataverse data til ADLS Gen2 som CSV- eller Parquet-filer. Power BI kan deretter spørre et Azure Synapse serverløst SQL-utvalg for å laste inn en importmodell.
Ventetid for data
Når dataversedata endres raskt og rapportbrukere trenger å se oppdaterte data, kan en DirectQuery-modell levere spørringsresultater nær sanntid.
Tips
Du kan opprette en Power BI-rapport som bruker automatisk sideoppdatering til å vise oppdateringer i sanntid, men bare når rapporten kobles til en DirectQuery-modell.
Importer datamodeller må fullføre en dataoppdatering for å tillate rapportering om nylige dataendringer. Husk at det er begrensninger på antall daglige planlagte dataoppdateringsoperasjoner. Du kan planlegge opptil åtte oppdateringer per dag på en delt kapasitet. På en Premium-kapasitet eller Microsoft Fabric-kapasitet kan du planlegge opptil 48 oppdateringer per dag, noe som kan oppnå en 15-minutters oppdateringsfrekvens.
Viktig
Til tider refererer denne artikkelen til Power BI Premium eller dets kapasitetsabonnementer (P SKU-er). Vær oppmerksom på at Microsoft for øyeblikket konsoliderer kjøpsalternativer og trekker tilbake Power BI Premium per kapasitet sKU-er. Nye og eksisterende kunder bør vurdere å kjøpe Fabric-kapasitetsabonnementer (F SKU-er) i stedet.
Hvis du vil ha mer informasjon, kan du se Viktige oppdateringer som kommer til Power BI Premium-lisensiering og vanlige spørsmål om Power BI Premium.
Du kan også vurdere å bruke trinnvis oppdatering for å oppnå raskere oppdateringer og nær sanntidsytelse (bare tilgjengelig med Premium eller Fabric).
Rollebasert sikkerhet
Når det er behov for å håndheve rollebasert sikkerhet, kan det påvirke valget av Power BI-modellrammeverk direkte.
Datavers kan håndheve kompleks rollebasert sikkerhet for å kontrollere tilgangen til bestemte poster til bestemte brukere. En selger kan for eksempel bare se salgsmulighetene sine, mens salgssjefen kan se alle salgsmuligheter for alle selgere. Du kan skreddersy kompleksiteten basert på behovene til organisasjonen.
En DirectQuery-modell basert på Dataverse kan koble til ved hjelp av sikkerhetskonteksten til rapportbrukeren. På den måten vil rapportbrukeren bare se dataene de har tilgang til. Denne fremgangsmåten kan forenkle rapportutformingen, forutsatt at ytelsen er akseptabel.
Hvis du vil ha bedre ytelse, kan du opprette en importmodell som kobler til Dataverse i stedet. I dette tilfellet kan du legge til sikkerhet på radnivå (RLS) i modellen om nødvendig.
Merk
Det kan være utfordrende å replikere noen dataverse rollebaserte sikkerheter som Power BI RLS, spesielt når Dataverse håndhever komplekse tillatelser. Videre kan det kreve kontinuerlig administrasjon for å holde Power BI-tillatelser synkronisert med dataverse tillatelser.
Hvis du vil ha mer informasjon om Power BI RLS, kan du se veiledning for sikkerhet på radnivå (RLS) i Power BI Desktop.
Installasjonskompleksitet
Bruk av Dataverse-koblingen i Power BI – enten det gjelder import- eller DirectQuery-modeller – er enkelt og krever ingen spesiell programvare eller utvidede dataverse tillatelser. Det er en fordel for organisasjoner eller avdelinger som kommer i gang.
Alternativet Azure Synapse Link krever systemansvarlig tilgang til Dataverse og visse Azure-tillatelser. Disse Azure-tillatelsene kreves for å konfigurere lagringskontoen og et Synapse-arbeidsområde.
Anbefalte fremgangsmåter
Denne delen beskriver utformingsmønstre (og antimønstre) du bør vurdere når du oppretter en Power BI-modell som kobler til Dataverse. Bare noen få av disse mønstrene er unike for Dataverse, men de pleier å være vanlige utfordringer for dataverse beslutningstakere når de bygger Power BI-rapporter.
Fokuser på et bestemt brukstilfelle
I stedet for å prøve å løse alt, kan du fokusere på det spesifikke brukstilfellet.
Denne anbefalingen er trolig den vanligste og lett mest utfordrende anti-mønster å unngå. Det er utfordrende å prøve å bygge en enkelt modell som oppnår alle selvbetjente rapporteringsbehov. Realiteten er at vellykkede modeller er bygget for å svare på spørsmål rundt et sentralt sett med fakta over et enkelt kjerneemne. Selv om det i utgangspunktet ser ut til å begrense modellen, er det faktisk styrkende fordi du kan justere og optimalisere modellen for å svare på spørsmål i dette emnet.
For å sikre at du har en klar forståelse av modellens formål, kan du stille deg selv følgende spørsmål.
- Hvilket emneområde vil denne modellen støtte?
- Hvem er målgruppen for rapportene?
- Hvilke spørsmål prøver rapportene å svare på?
- Hva er den minste levedyktige semantiske modellen?
Motstå å kombinere flere emneområder til én enkelt modell bare fordi rapportbrukeren har spørsmål på tvers av flere emneområder som de vil behandles av én enkelt rapport. Ved å dele rapporten ut i flere rapporter, hver med fokus på et annet emne (eller faktatabell), kan du produsere mye mer effektive, skalerbare og håndterbare modeller.
Utforme et stjerneskjema
Dataverse utviklere og administratorer som er komfortable med Dataverse-skjemaet, kan bli fristet til å gjenskape det samme skjemaet i Power BI. Denne tilnærmingen er et anti-mønster, og det er sannsynligvis den tøffeste å overvinne fordi det bare føles riktig å opprettholde konsistens.
Datavers, som en relasjonsmodell, er godt egnet for formålet. Den er imidlertid ikke utformet som en analytisk modell som er optimalisert for analytiske rapporter. Det mest utbredte mønsteret for modellering av analysedata er en utforming av stjerneskjema. Stjerneskjema er en moden modelleringstilnærming som er mye tatt i bruk av relasjonelle datalagre. Det krever at modellerere klassifiserer modelltabellene som enten dimensjon eller fakta. Rapporter kan filtrere eller gruppere ved hjelp av dimensjonstabell kolonner og oppsummere faktatabellkolonner.
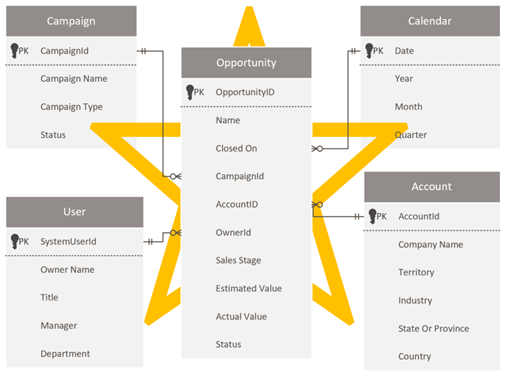
Hvis du vil ha mer informasjon, kan du se Forstå stjerneskjema og viktigheten for Power BI.
Optimalisere Power Query-spørringer
Power Query-mashup-motoren forsøker å oppnå spørringsdelegering når det er mulig på grunn av effektivitet. En spørring som oppnår spørringsbehandling for delegering av representanter til kildesystemet.
Kildesystemet, i dette tilfellet Dataverse, trenger da bare å levere filtrerte eller oppsummerte resultater til Power BI. En brettet spørring er ofte betydelig raskere og mer effektiv enn en spørring som ikke brettes.
Hvis du vil ha mer informasjon om hvordan du kan oppnå spørringsdelegering, kan du se Power Query-spørringsdelegering.
Merk
Optimalisering av Power Query er et bredt emne. Hvis du vil oppnå en bedre forståelse av hva Power Query gjør ved redigering og oppdateringstidspunkt for modell i Power BI Desktop, kan du se Spørringsdiagnose.
Minimere antall spørringskolonner
Når du bruker Power Query som standard til å laste inn en dataverstabell, henter den alle rader og alle kolonner. Når du for eksempel spør etter en systembrukertabell, kan den inneholde mer enn 1000 kolonner. Kolonnene i metadataene inkluderer relasjoner til andre enheter og oppslag til alternativetiketter, slik at det totale antallet kolonner vokser med kompleksiteten i dataverstabellen.
Forsøk på å hente data fra alle kolonner er et antimønster. Det resulterer ofte i utvidede dataoppdateringsoperasjoner, og det vil føre til at spørringen mislykkes når tiden det tar å returnere dataene, overskrider 10 minutter.
Vi anbefaler at du bare henter kolonner som kreves av rapporter. Det er ofte lurt å revurdere og refaktorere spørringer når rapportutviklingen er fullført, slik at du kan identifisere og fjerne ubrukte kolonner. Hvis du vil ha mer informasjon, kan du se Teknikker for datareduksjon for importmodellering (Fjern unødvendige kolonner).
I tillegg må du sørge for at du introduserer Power Query Remove-kolonnene tidlig, slik at den brettes tilbake til kilden. På denne måten kan Power Query unngå unødvendig arbeid med å trekke ut kildedata bare for å forkaste dem senere (i et utfoldet trinn).
Når du har en tabell som inneholder mange kolonner, kan det være upraktisk å bruke det interaktive spørringsverktøyet for Power Query. I dette tilfellet kan du begynne med å opprette en tom spørring. Deretter kan du bruke avansert redigering til å lime inn i en minimal spørring som oppretter et utgangspunkt.
Vurder følgende spørring som henter data fra bare to kolonner i account tabellen.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Skrive opprinnelige spørringer
Når du har spesifikke transformasjonskrav, kan du oppnå bedre ytelse ved hjelp av en opprinnelig spørring skrevet i Datavers SQL, som er et delsett av Transact-SQL. Du kan skrive en opprinnelig spørring til:
- Redusere antall rader (ved hjelp av en
WHEREsetningsdel). - Aggreger data (ved hjelp
GROUP BYav ogHAVING-setningene). - Koble sammen tabeller på en bestemt måte (ved hjelp
JOINav ellerAPPLYsyntaksen). - Bruk støttede SQL-funksjoner.
Hvis du vil ha mer informasjon, kan du se:
Utfør opprinnelige spørringer med alternativet EnableFolding
Power Query utfører en opprinnelig spørring ved hjelp Value.NativeQuery av funksjonen.
Når du bruker denne funksjonen, er det viktig å legge til EnableFolding=true alternativet for å sikre at spørringer brettes tilbake til Dataverse-tjenesten. En opprinnelig spørring vil ikke brettes med mindre dette alternativet legges til. Aktivering av dette alternativet kan resultere i betydelige ytelsesforbedringer – opptil 97 prosent raskere i enkelte tilfeller.
Vurder følgende spørring som bruker en opprinnelig spørring til å hente merkede kolonner fra account-tabellen. Den opprinnelige spørringen vil brettes fordi EnableFolding=true alternativet er angitt.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
Du kan forvente å oppnå de største ytelsesforbedringene når du henter et delsett med data fra et stort datavolum.
Tips
Ytelsesforbedring kan også avhenge av hvordan Power BI spør kildedatabasen. Et mål som bruker COUNTDISTINCT DAX-funksjonen, viste for eksempel nesten ingen forbedring med eller uten foldetipset. Når målformelen ble omskrevet for å bruke SUMX DAX-funksjonen, ble spørringen brettet, noe som resulterte i en forbedring på 97 prosent i forhold til den samme spørringen uten hintet.
Hvis du vil ha mer informasjon, kan du se Value.NativeQuery. (Alternativet EnableFolding er ikke dokumentert fordi det bare er spesifikt for bestemte datakilder.)
Få fart på evalueringsfasen
Hvis du bruker Dataverse-koblingen (tidligere kjent som Common Data Service), kan du legge til CreateNavigationProperties=false alternativet for å øke hastigheten på evalueringsfasen av en dataimport.
Evalueringsfasen for en dataimport itererer gjennom metadataene til kilden for å bestemme alle mulige tabellrelasjoner. Metadataene kan være omfattende, spesielt for Dataverse. Ved å legge til dette alternativet i spørringen lar du Power Query vite at du ikke har tenkt å bruke disse relasjonene. Med alternativet kan Power BI Desktop hoppe over dette stadiet av oppdateringen og gå videre til å hente dataene.
Merk
Ikke bruk dette alternativet når spørringen avhenger av utvidede relasjonskolonner.
Vurder et eksempel som henter data fra account-tabellen. Den inneholder tre kolonner relatert til distrikt: territory, territoryidog territoryidname.
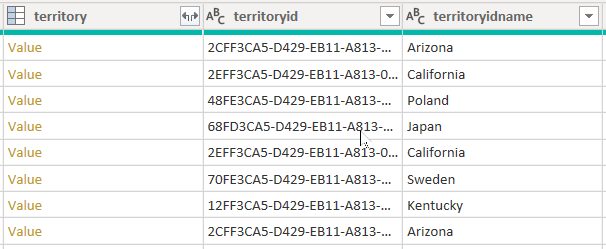
Når du angir alternativet CreateNavigationProperties=false, beholdes kolonnene territoryid og territoryidname, men kolonnen territory, som er en relasjonskolonne (den viser verdi koblinger), utelates. Det er viktig å forstå at Power Query-relasjonskolonner er et annet konsept for modellrelasjoner, som overfører filtre mellom modelltabeller.
Vurder følgende spørring som bruker CreateNavigationProperties=false alternativet (i kildetrinnet) til å øke hastigheten på evalueringsfasen av en dataimport.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Når du bruker dette alternativet, vil du sannsynligvis oppleve betydelig ytelsesforbedring når en datavers tabell har mange relasjoner til andre tabeller. Siden for eksempel SystemUser tabellen er relatert til alle andre tabeller i databasen, vil oppdateringsytelsen for denne tabellen være til nytte ved å angi alternativet CreateNavigationProperties=false.
Merk
Dette alternativet kan forbedre ytelsen til dataoppdatering av importtabeller eller tabeller i dobbel lagringsmodus, inkludert prosessen med å bruke Power Query-redigering vindusendringer. Det forbedrer ikke ytelsen til interaktiv kryssfiltrering av DirectQuery-lagringsmodustabeller.
Løse tomme valgetiketter
Hvis du oppdager at dataverse valgetiketter er tomme i Power BI, kan det skyldes at etikettene ikke har blitt publisert til tabelldatastrømmens endepunkt (TDS).
I dette tilfellet åpner du Dataverse Maker Portal, navigerer til Løsninger-området og velger deretter Publiser alle tilpasninger. Publiseringsprosessen oppdaterer TDS-endepunktet med de nyeste metadataene, noe som gjør alternativetikettene tilgjengelige for Power BI.
Større semantiske modeller med Azure Synapse Link
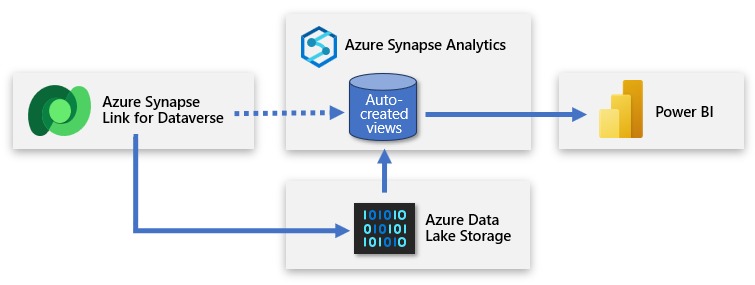
Datavers inkluderer muligheten til å synkronisere tabeller til Azure Data Lake Storage (ADLS) og deretter koble til dataene via et Azure Synapse-arbeidsområde. Med minimal innsats kan du konfigurere Azure Synapse Link til å fylle ut dataverse data i Azure Synapse og gjøre det mulig for datateam å oppdage dypere innsikter.
Azure Synapse Link muliggjør en kontinuerlig replikering av data og metadata fra Dataverse til datasjøen. Det gir også et innebygd serverløst SQL-utvalg som en praktisk datakilde for Power BI-spørringer.
Styrkene til denne tilnærmingen er betydelige. Kunder får muligheten til å kjøre arbeidsbelastninger for analyse, forretningsintelligens og maskinlæring på tvers av dataverse data ved hjelp av ulike avanserte tjenester. Avanserte tjenester inkluderer Apache Spark, Power BI, Azure Data Factory, Azure Databricks og Azure Machine Learning.
Opprette en Azure Synapse-kobling for datavers
Hvis du vil opprette en Azure Synapse Link for Dataverse, trenger du følgende forutsetninger på plass.
- Systemansvarlig har tilgang til dataversmiljøet.
- For the Azure Data Lake Storage:
- Du må ha en lagringskonto for bruk med ADLS Gen2.
- Du må være tilordnet lagringsblobdataeier og lagrings-BLOB-databidragsytertilgang til lagringskontoen. Hvis du vil ha mer informasjon, kan du se Rollebasert tilgangskontroll (Azure RBAC).
- Lagringskontoen må aktivere hierarkisk navneområde.
- Det anbefales at lagringskontoen bruker geo-redundant lagringsplass med lesetilgang (RA-GRS).
- For Synapse-arbeidsområdet:
- Du må ha tilgang til et Synapse-arbeidsområde og få tilordnet administratortilgang for Synapse . Hvis du vil ha mer informasjon, kan du se innebygde Synapse RBAC-roller og -omfang.
- Arbeidsområdet må være i samme område som ADLS Gen2-lagringskontoen.
Oppsettet innebærer å logge på Power Apps og koble Dataverse til Azure Synapse-arbeidsområdet. Med en veiviserlignende opplevelse kan du opprette en ny kobling ved å velge lagringskontoen og tabellene du vil eksportere. Azure Synapse Link kopierer deretter data til ADLS Gen2-lagring og oppretter automatisk visninger i det innebygde Serverløse SQL-utvalget i Azure Synapse. Deretter kan du koble til disse visningene for å opprette en Power BI-modell.
Tips
Hvis du vil ha fullstendig dokumentasjon om hvordan du oppretter, administrerer og overvåker Azure Synapse Link, kan du se Opprette en Azure Synapse Link for Dataverse med Azure Synapse Workspace.
Opprette en annen serverløs SQL-database
Du kan opprette en annen serverløs SQL-database og bruke den til å legge til egendefinerte rapportvisninger. På denne måten kan du presentere et forenklet sett med data til Power BI-oppretteren som gjør det mulig for dem å opprette en modell basert på nyttige og relevante data. Den nye serverløse SQL-databasen blir oppretterens primære kildetilkobling og en egendefinert representasjon av dataene som hentes fra datasjøen.
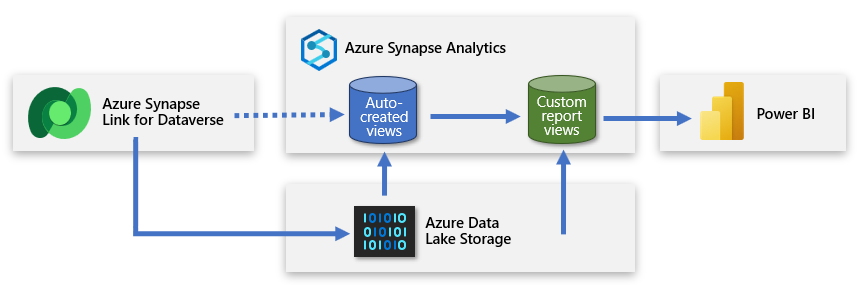
Denne tilnærmingen leverer data til Power BI som er fokusert, beriket og filtrert.
Du kan opprette en serverløs SQL-database i Azure Synapse-arbeidsområdet ved hjelp av Azure Synapse Studio. Velg Serverless som SQL-databasetype, og skriv inn et databasenavn. Power Query kan koble til denne databasen ved å koble til SQL-endepunktet for arbeidsområdet.
Opprette egendefinerte visninger
Du kan opprette egendefinerte visninger som bryter serverløse SQL-utvalgsspørringer. Disse visningene fungerer som enkle, rene datakilder som Power BI kobler til. Visningene bør:
- Inkluder etikettene som er knyttet til valgfelt.
- Reduser kompleksiteten ved å inkludere bare kolonnene som kreves for datamodellering.
- Filtrer ut unødvendige rader, for eksempel inaktive poster.
Vurder følgende visning som henter kampanjedata.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Legg merke til at visningen bare inneholder fire kolonner, hver alias med et egendefinert navn. Det finnes også en WHERE setning for å returnere bare nødvendige rader, i dette tilfellet aktive kampanjer. Visningen spør også kampanjetabellen som er koblet til OptionsetMetadata- og StatusMetadata-tabellene, som henter valgetiketter.
Tips
Hvis du vil ha mer informasjon om hvordan du henter metadata, kan du se Access-valgetiketter direkte fra Azure Synapse Link for Dataverse.
Spørring av passende tabeller
Azure Synapse Link for Dataverse sikrer at dataene kontinuerlig synkroniseres med dataene i datasjøen. Når det gjelder aktivitet med høy bruk, kan samtidig skriving og lesing opprette låser som fører til at spørringer mislykkes. To versjoner av tabelldataene synkroniseres i Azure Synapse for å sikre pålitelighet ved henting av data.
- Nær sanntidsdata: Gir en kopi av data synkronisert fra Dataverse via Azure Synapse Link på en effektiv måte ved å oppdage hvilke data som er endret siden de først ble trukket ut eller sist synkronisert.
- øyeblikksbildedata: Inneholder en skrivebeskyttet kopi av data i nær sanntid som oppdateres med jevne mellomrom (i dette tilfellet hver time). Navn på øyeblikksbildedatatabeller har _partitioned tilføyd navnet.
Hvis du forventer at et stort antall lese- og skriveoperasjoner utføres samtidig, henter du data fra øyeblikksbildetabellene for å unngå spørringsfeil.
Hvis du vil ha mer informasjon, kan du se Access nær sanntidsdata og skrivebeskyttede øyeblikksbildedata.
Koble til Synapse Analytics
Hvis du vil spørre etter et Azure Synapse serverløst SQL-utvalg, trenger du SQL-endepunktet for arbeidsområdet. Du kan hente endepunktet fra Synapse Studio ved å åpne de serverløse SQL-utvalgsegenskapene.
I Power BI Desktop kan du koble til Azure Synapse ved hjelp av Azure Synapse Analytics SQL-koblingen. Når du blir bedt om det for serveren, skriver du inn SQL-endepunktet for arbeidsområdet.
Vurderinger for DirectQuery
Det finnes mange brukstilfeller når du bruker DirectQuery-lagringsmodus, som kan løse kravene dine. Bruk av DirectQuery kan imidlertid påvirke ytelsen til Power BI-rapporten negativt. En rapport som bruker en DirectQuery-tilkobling til Dataverse, vil ikke være like rask som en rapport som bruker en importmodell. Vanligvis bør du importere data til Power BI når det er mulig.
Vi anbefaler at du vurderer emnene i denne delen når du arbeider med DirectQuery.
Hvis du vil ha mer informasjon om hvordan du bestemmer når du skal arbeide med DirectQuery-lagringsmodus, kan du se Velg et rammeverk for Power BI-modell.
Bruk dimensjonstabeller for dobbel lagringsmodus
En tabell for dobbel lagringsmodus er satt til å bruke både import- og DirectQuery-lagringsmoduser. På spørringstidspunktet bestemmer Power BI den mest effektive modusen som skal brukes. Når det er mulig, prøver Power BI å oppfylle spørringer ved hjelp av importerte data fordi det er raskere.
Du bør vurdere å sette dimensjonstabeller til dobbel lagringsmodus når det er aktuelt. På den måten vil slicervisualobjekter og filterkortlister – som ofte er basert på dimensjonstabellkolonner – gjengis raskere fordi de blir spurt fra importerte data.
Viktig
Når en dimensjonstabell må arve datavers sikkerhetsmodellen, er det ikke aktuelt å bruke dobbel lagringsmodus.
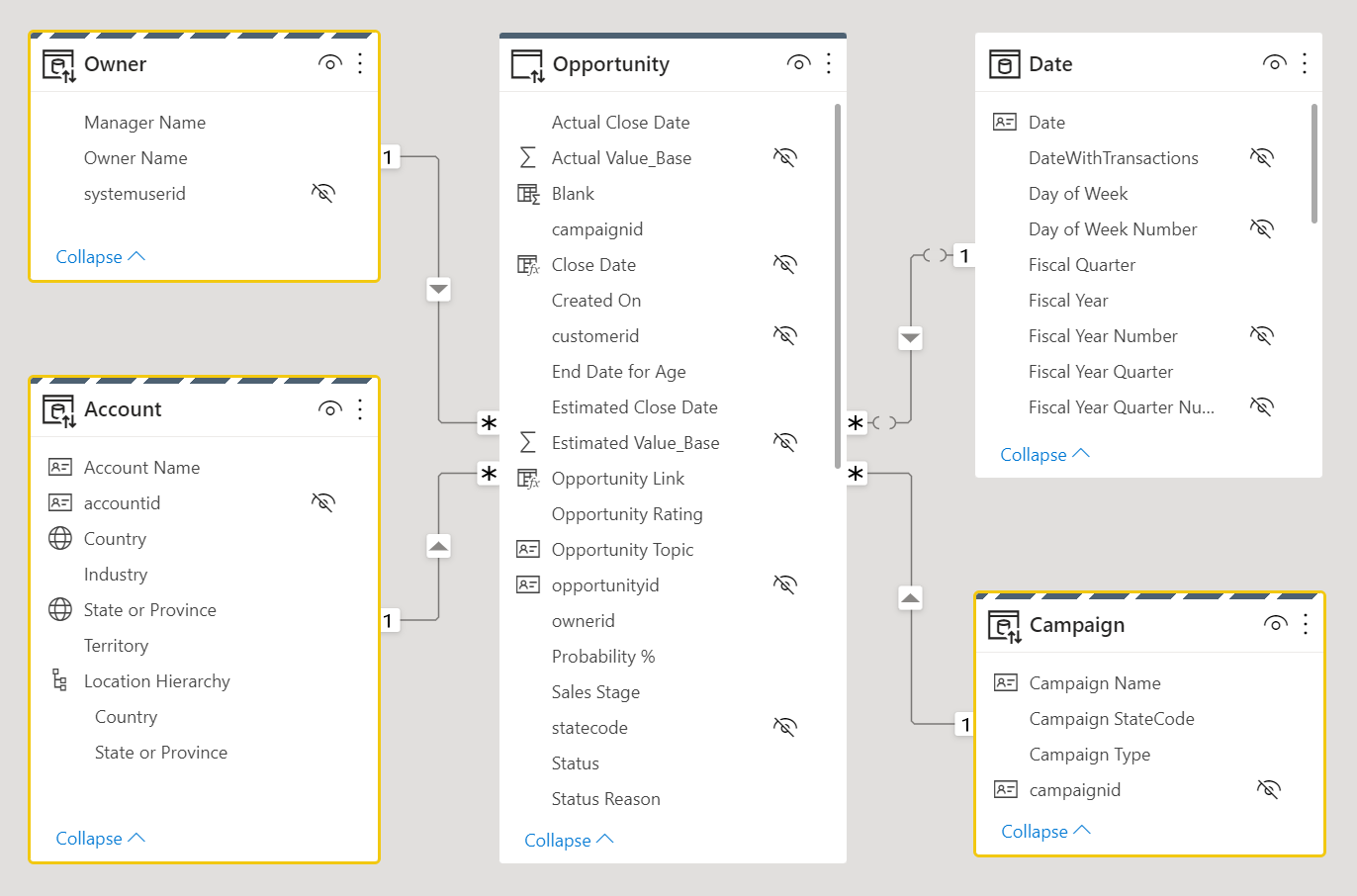
Faktatabeller, som vanligvis lagrer store mengder data, bør forbli som Tabeller for DirectQuery-lagringsmodus. De filtreres etter relaterte dimensjonstabeller for dobbel lagringsmodus, som kan kobles til faktatabellen for å oppnå effektiv filtrering og gruppering.
Vurder følgende utforming av datamodell. Tre dimensjonstabeller, Owner, Accountog Campaign har en stripet øvre kantlinje, noe som betyr at de er satt til dobbel lagringsmodus.
Hvis du vil ha mer informasjon om tabelllagringsmoduser, inkludert dobbel lagringsplass, kan du se Behandle lagringsmodus i Power BI Desktop.
Aktiver enkel pålogging
Når du publiserer en DirectQuery-modell til Power Bi-tjeneste, kan du bruke innstillingene for semantisk modell til å aktivere enkel pålogging (SSO) ved hjelp av Microsoft Entra ID OAuth2 for rapportbrukerne. Du bør aktivere dette alternativet når Dataverse-spørringer må kjøres i sikkerhetskonteksten til rapportbrukeren.
Når SSO-alternativet er aktivert, sender Power BI rapportbrukerens godkjente Microsoft Entra-legitimasjon i spørringene til Dataverse. Dette alternativet gjør det mulig for Power BI å overholde sikkerhetsinnstillingene som er konfigurert i datakilden.
Hvis du vil ha mer informasjon, kan du se Enkel pålogging (SSO) for DirectQuery-kilder.
Replikere «Min»-filtre i Power Query
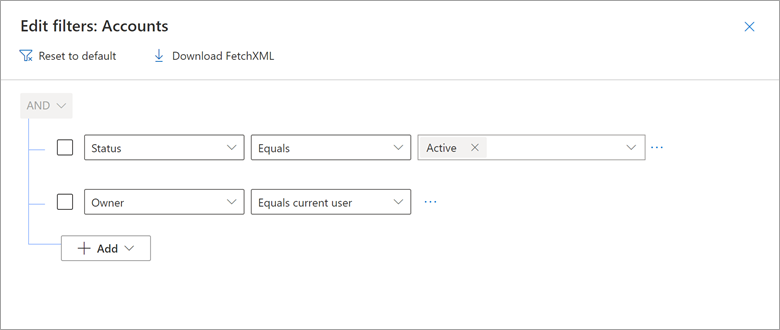
Når du bruker Microsoft Dynamics 365 Customer Engagement (CE) og modelldrevne Power Apps bygget på Dataverse, kan du opprette visninger som bare viser poster der et brukernavnfelt, for eksempel Owner, er lik gjeldende bruker. Du kan for eksempel opprette visninger med navnet «Mine åpne muligheter», «Mine aktive saker» og andre.
Vurder et eksempel på hvordan Visningen Mine aktive kontoer for Dynamics 365 inneholder et filter der eieren er lik gjeldende bruker.
Du kan gjenskape dette resultatet i Power Query ved hjelp av en opprinnelig spørring som bygger inn tokenet CURRENT_USER .
Vurder følgende eksempel som viser en opprinnelig spørring som returnerer kontoene for gjeldende bruker. Legg merke til at ownerid-kolonnen filtreres av CURRENT_USER-tokenet i WHERE-setningsdelen.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Når du publiserer modellen til Power Bi-tjeneste, må du aktivere enkel pålogging (SSO) slik at Power BI sender rapportbrukerens godkjente Microsoft Entra-legitimasjon til Dataverse.
Opprett tilleggsimportmodeller
Du kan opprette en DirectQuery-modell som fremtvinger dataversetillatelser i visshet om at ytelsen vil gå tregt. Deretter kan du supplere denne modellen med importmodeller som retter seg mot bestemte emner eller målgrupper som kan fremtvinge RLS-tillatelser.
En importmodell kan for eksempel gi tilgang til alle dataverse data, men ikke fremtvinge tillatelser. Denne modellen passer til ledere som allerede har tilgang til alle dataverse data.
Som et annet eksempel, når Dataverse håndhever rollebaserte tillatelser etter salgsområde, kan du opprette én importmodell og replikere disse tillatelsene ved hjelp av RLS. Du kan også opprette en modell for hvert salgsområde. Deretter kan du gi lesetillatelse til disse modellene (semantiske modeller) til selgerne i hvert område. Hvis du vil legge til rette for oppretting av disse regionale modellene, kan du bruke parametere og rapportmaler. Hvis du vil ha mer informasjon, kan du se Opprette og bruke rapportmaler i Power BI Desktop.
Relatert innhold
Hvis du vil ha mer informasjon om denne artikkelen, kan du se følgende ressurser.