Konfigurer Arbeidsbelastninger for Power BI Premium-dataflyt
Du kan opprette dataflytarbeidsbelastninger i Power BI Premium-abonnementet. Power BI bruker konseptet med arbeidsbelastninger til å beskrive Premium-innhold. Arbeidsbelastninger inkluderer datasett, paginerte rapporter, dataflyter og kunstig intelligens. Med arbeidsbelastningen for dataflyter kan du bruke selvbetjent dataforberedelse for dataflyter til å innta, transformere, integrere og berike data. Power BI Premium-dataflyter administreres i administrasjonsportalen.
De følgende avsnittene beskriver hvordan du aktiverer dataflyter i organisasjonen, hvordan du begrenser innstillingene i Premium-kapasiteten og veiledning for vanlig bruk.
Aktivere dataflyter i Power BI Premium
Det første kravet for bruk av dataflyter i Power BI Premium-abonnementet er å aktivere oppretting og bruk av dataflyter for organisasjonen. Velg Tenant Innstillinger i administrasjonsportalen, og bytt glidebryteren under Innstillinger for dataflyt til Aktivert, som vist i bildet nedenfor.
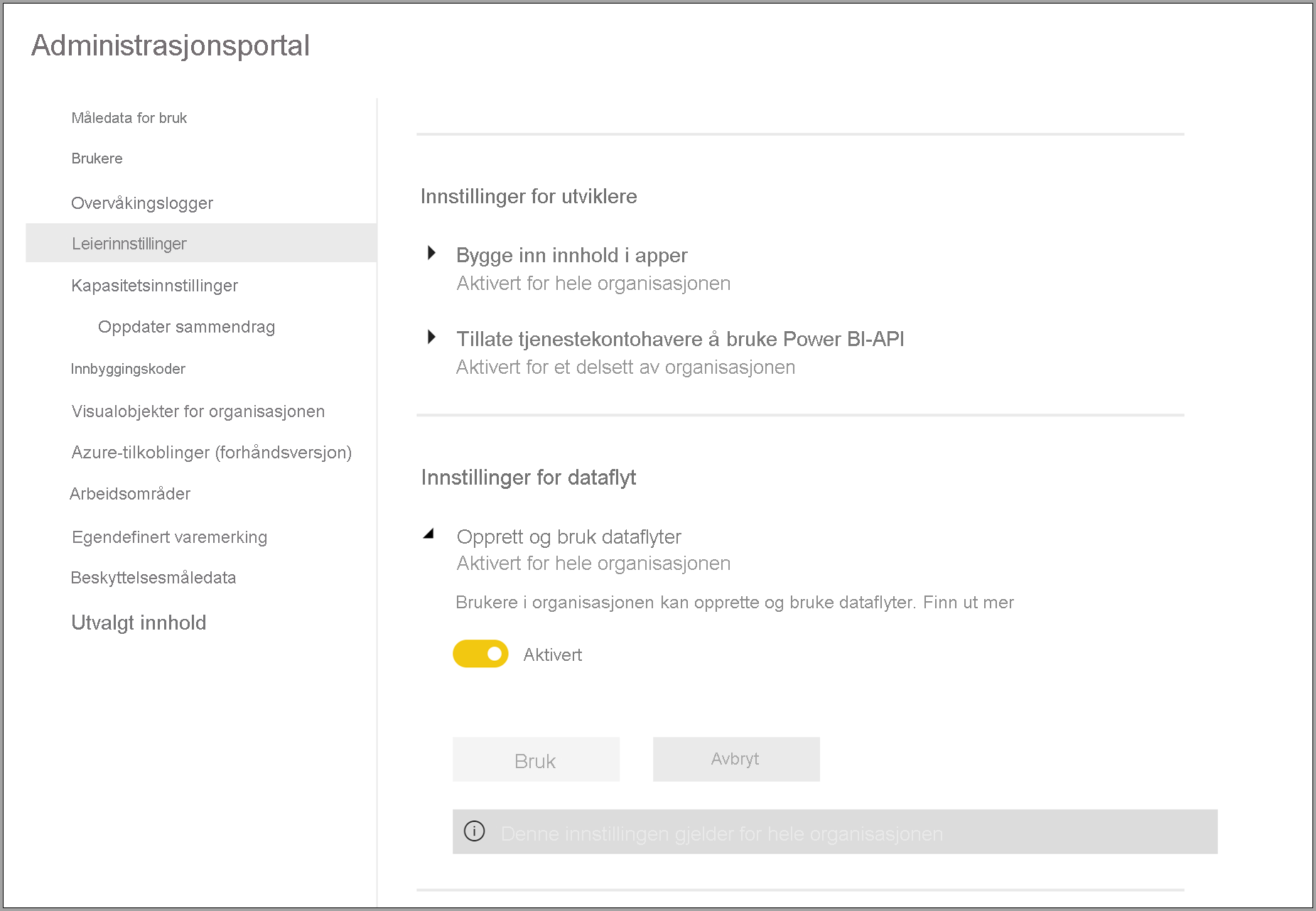
Når du har aktivert arbeidsbelastningen for dataflyter, konfigureres den med standardinnstillinger. Det kan være lurt å justere disse innstillingene slik du ønsker. Deretter beskriver vi hvor disse innstillingene lever, beskriver hver av dem og hjelper deg med å forstå når du kanskje vil endre verdiene for å optimalisere dataflytytelsen.
Presisering av dataflytinnstillinger i Premium
Når dataflyter er aktivert, kan du bruke administrasjonsportalen til å endre, eller begrense, hvordan dataflyter opprettes og hvordan de bruker ressurser i Power BI Premium-abonnementet. Power BI Premium krever ikke at minneinnstillingene endres. Minne i Power BI Premium administreres automatisk av det underliggende systemet. Følgende fremgangsmåte viser hvordan du justerer innstillingene for dataflyten.
Velg Leierinnstillinger i administrasjonsportalen for å vise alle kapasiteter som er opprettet. Velg en kapasitet for å administrere innstillingene.
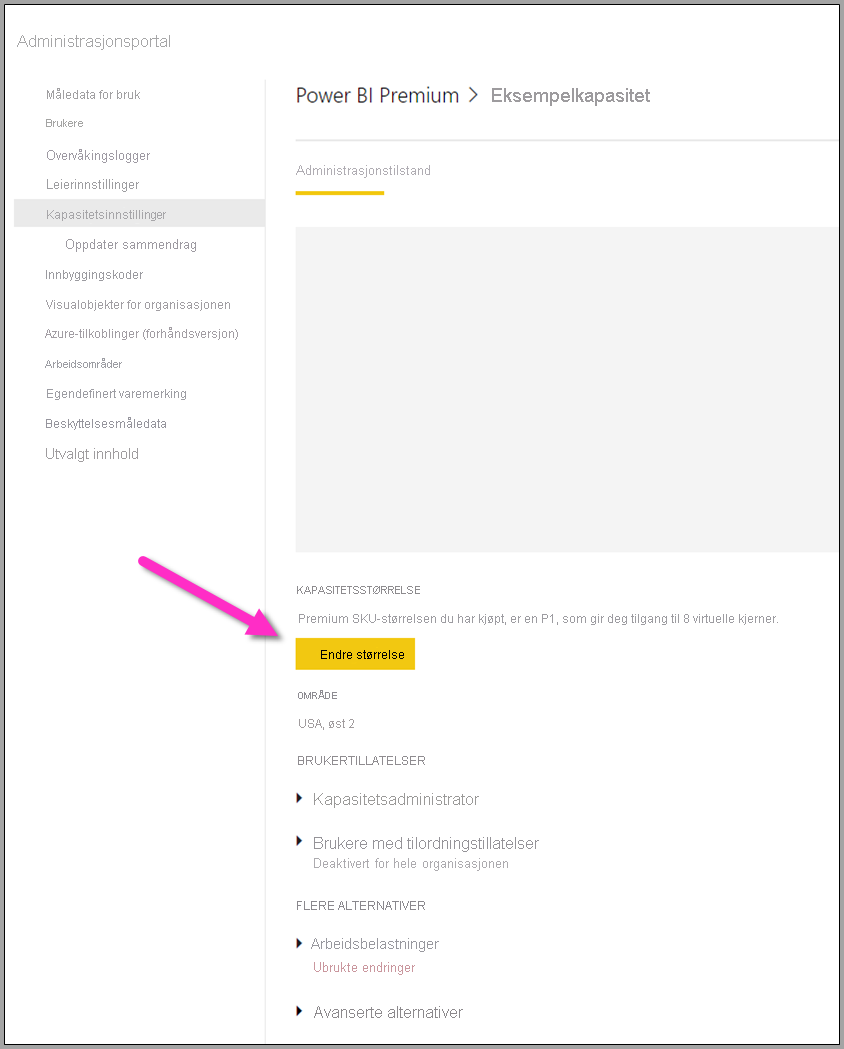
Power BI Premium-kapasiteten gjenspeiler ressursene som er tilgjengelige for dataflytene. Du kan endre størrelsen på kapasiteten ved å velge Endre størrelse-knappen , som vist i bildet nedenfor.
Premium kapasitet SKU-er – skaler opp maskinvaren
Power BI Premium-arbeidsbelastninger bruker v-kjerner til å betjene raske spørringer på tvers av de ulike arbeidsbelastningstypene. Kapasiteter og SKU-er inneholder et diagram som illustrerer gjeldende spesifikasjoner på tvers av hvert av de tilgjengelige arbeidsbelastningstilbudene. Kapasiteter på A3 og større kan dra nytte av databehandlingsmotoren, så når du vil bruke den forbedrede databehandlingsmotoren, starter du der.
Forbedret databehandlingsmotor – en mulighet til å forbedre ytelsen
Den forbedrede databehandlingsmotoren er en motor som kan akselerere spørringene dine. Power BI bruker en databehandlingsmotor til å behandle spørringer og oppdateringsoperasjoner. Den forbedrede databehandlingsmotoren er en forbedring i forhold til standardmotoren, og fungerer ved å laste inn data til en SQL Cache og bruke SQL til å akselerere tabelltransformasjon, oppdatere operasjoner og aktivere DirectQuery-tilkobling. Når den er konfigurert til På eller Optimalisert for beregnede enheter, bruker Power BI SQL til å øke hastigheten på ytelsen hvis forretningslogikken tillater det. Å ha motoren På gir også DirectQuery-tilkobling. Kontroller at dataflytbruken bruker den forbedrede databehandlingsmotoren riktig. Brukere kan konfigurere den forbedrede databehandlingsmotoren til å være på, optimalisert eller deaktivert per dataflyt.
Merk
Den forbedrede databehandlingsmotoren er ennå ikke tilgjengelig i alle områder.
Veiledning for vanlige scenarioer
Denne delen gir veiledning for vanlige scenarioer når du bruker dataflytarbeidsbelastninger med Power BI Premium.
Langsomme oppdateringstider
Langsomme oppdateringstider er vanligvis et problem med parallellitet. Du bør se gjennom følgende alternativer, i rekkefølge:
Et viktig konsept for langsomme oppdateringstider er innholdet i dataforberedelsen. Når du kan optimalisere de langsomme oppdateringstidene ved å dra nytte av datakilden som faktisk gjør klargjøringen og utfører forhåndsspørringslogikk, bør du gjøre det. Når du bruker en relasjonsdatabase, for eksempel SQL som kilde, kan du se om den første spørringen kan kjøres på kilden, og bruke denne kildespørringen for den første uttrekkingsdataflyten for datakilden. Hvis du ikke kan bruke en opprinnelig spørring i kildesystemet, utfører du operasjoner som dataflytmotoren kan brette til datakilden.
Evaluer spredning av oppdateringstider på samme kapasitet. Oppdateringsoperasjoner er en prosess som krever betydelig databehandling. Ved hjelp av vår restaurant analogi, spre ut oppdateringstider er beslektet med å begrense antall gjester i restauranten din. Akkurat som restauranter planlegger gjester og planlegger kapasitet, vil du også vurdere oppdateringsoperasjoner i tider da bruken ikke er på sitt fulle høydepunkt. Dette kan gå langt mot å lindre belastningen på kapasiteten.
Hvis trinnene i denne delen ikke gir ønsket grad av parallellisme, bør du vurdere å oppgradere kapasiteten til en høyere SKU. Følg deretter de forrige trinnene i denne sekvensen på nytt.
Bruke databehandlingsmotoren til å forbedre ytelsen
Gjør følgende for å aktivere arbeidsbelastninger for å utløse databehandlingsmotoren, og forbedre alltid ytelsen:
For beregnede og koblede enheter i samme arbeidsområde:
For inntaksfokus på å få dataene inn i lagringen så raskt som mulig, bruker du filtre bare hvis de reduserer den totale datasettstørrelsen. Det er anbefalt fremgangsmåte å holde transformasjonslogikken atskilt fra dette trinnet, og la motoren fokusere på den første samlingen av ingredienser. Deretter skiller du transformasjonen og forretningslogikken i en egen dataflyt i samme arbeidsområde ved hjelp av koblede eller beregnede enheter. Dette gjør det mulig for motoren å aktivere og akselerere beregningene dine. Logikken må være forberedt separat før den kan dra nytte av databehandlingsmotoren.
Sørg for at du utfører operasjonene som brettes, for eksempel flettinger, sammenføyninger, konvertering og andre.
Bygge dataflyter innenfor publiserte retningslinjer og begrensninger.
Du kan også bruke DirectQuery.
Databehandlingsmotoren er på, men ytelsen er treg
Gjør følgende når du undersøker scenarier der databehandlingsmotoren er på, men du ser tregere ytelse:
Begrens beregnede og koblede enheter som finnes på tvers av arbeidsområdet.
Når du utfører den første oppdateringen med databehandlingsmotoren aktivert, blir dataene skrevet i innsjøen og i hurtigbufferen. Denne dobbeltskrivingen betyr at disse oppdateringene vil bli tregere.
Hvis du har en dataflyt som kobler til flere dataflyter, må du kontrollere at du planlegger oppdateringer av kildedataflytene slik at de ikke alle oppdateres samtidig.
Relatert innhold
Følgende artikler gir mer informasjon om dataflyter og Power BI:
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for