Obs!
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Denne artikkelen viser hvordan du kan bruke kunstig intelligens (AI) med dataflyter. Denne artikkelen beskriver:
- Cognitive Services
- Automatisert maskinlæring
- Azure Machine Learning Integration
Viktig
Oppretting av AutoML-modeller (Power BI Automated Machine Learning) for dataflyter v1 er fjernet, og er ikke lenger tilgjengelig. Kunder oppfordres til å overføre løsningen til AutoML-funksjonen i Microsoft Fabric. Hvis du vil ha mer informasjon, kan du se kunngjøringen om pensjonering.
Cognitive Services i Power BI
Med Cognitive Services i Power BI kan du bruke forskjellige algoritmer fra Azure Cognitive Services til å berike dataene i den selvbetjente dataforberedelsen for dataflyter.
Tjenestene som støttes i dag, er sentimentanalyse, uttrekking av nøkkeluttrykk, språkgjenkjenning og bildemerking. Transformasjonene utføres på Power Bi-tjeneste og krever ikke et Azure Cognitive Services-abonnement. Denne funksjonen krever Power BI Premium.
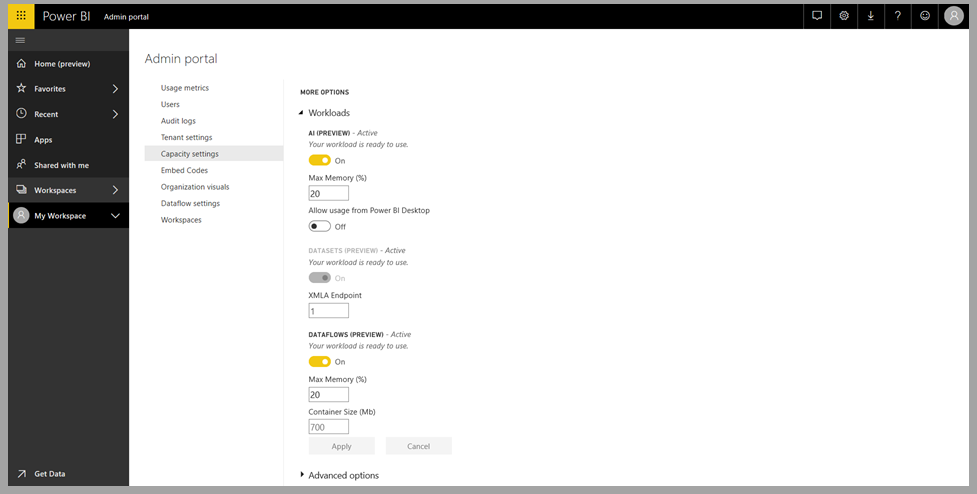
Aktiver AI-funksjoner
Kognitive tjenester støttes for Premium-kapasitetsnoder EM2, A2, P1 eller F64 og andre noder med flere ressurser. Kognitive tjenester er også tilgjengelige med en Premium Per User (PPU)-lisens. En egen AI-arbeidsbelastning på kapasiteten brukes til å kjøre kognitive tjenester. Før du bruker kognitive tjenester i Power BI, må AI-arbeidsbelastningen aktiveres i kapasitetsinnstillingene for administrasjonsportalen. Du kan aktivere AI-arbeidsbelastningen i arbeidsbelastningsdelen.
Komme i gang med Cognitive Services i Power BI
Cognitive Services-transformeringer er en del av selvbetjent dataforberedelse for dataflyter. Hvis du vil berike dataene med Cognitive Services, starter du med å redigere en dataflyt.
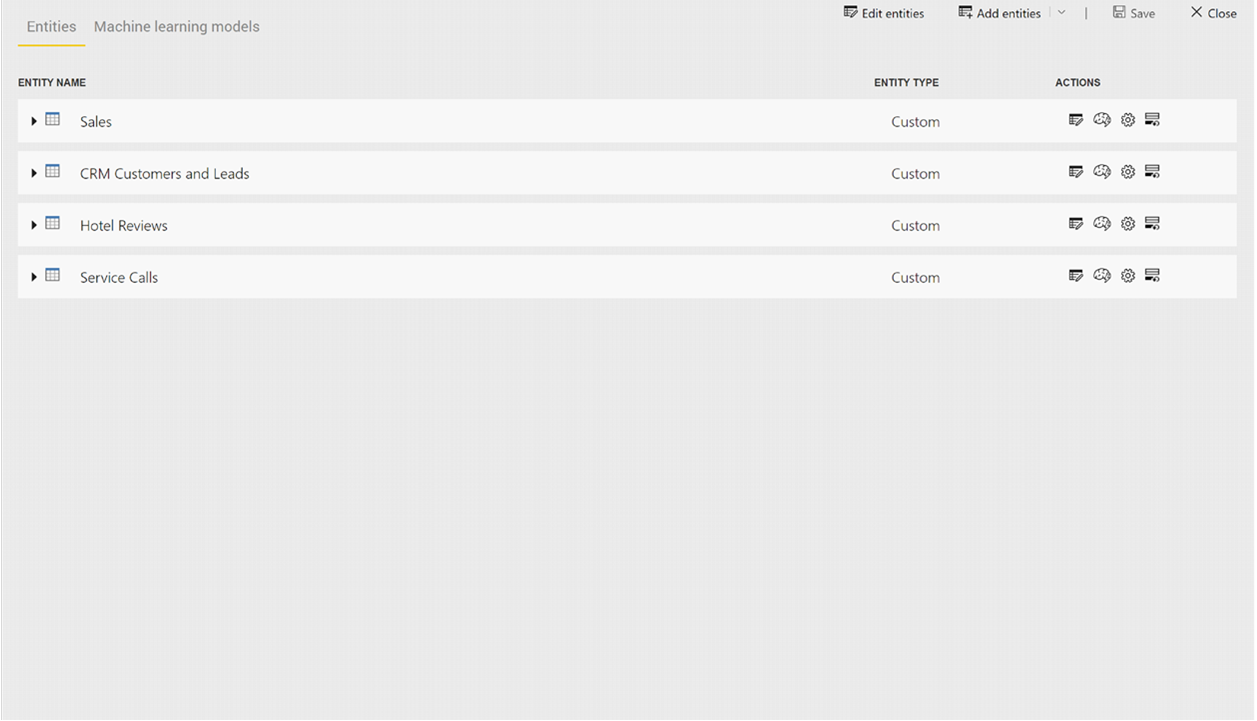
Velg Kunstig intelligens-knappen øverst på Power Query-redigering.
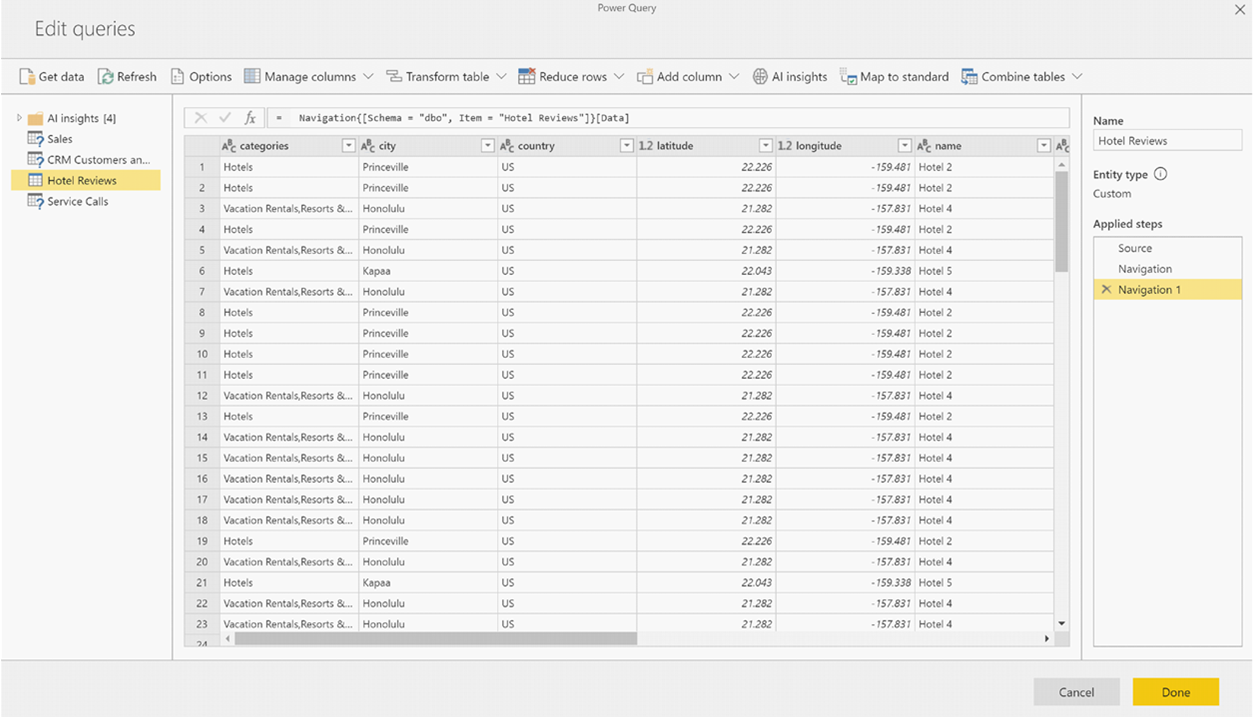
Velg funksjonen du vil bruke i popup-vinduet, og dataene du vil transformere. Dette eksemplet viser sentimentet til en kolonne som inneholder korrekturtekst.
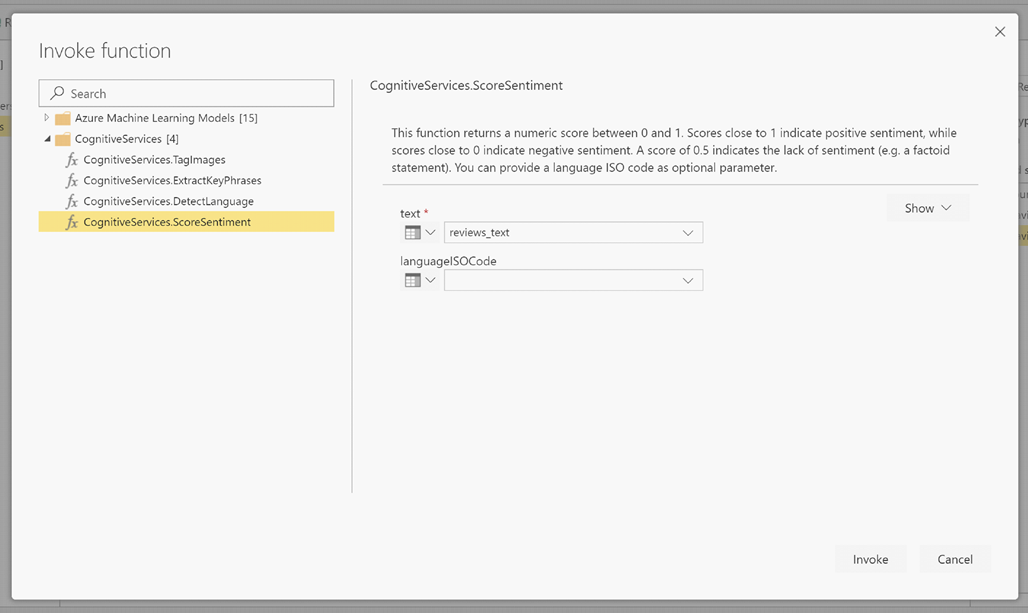
LanguageISOCode er en valgfri inndata for å angi språket for teksten. Denne kolonnen forventer en ISO-kode. Du kan bruke en kolonne som inndata for LanguageISOCode, eller du kan bruke en statisk kolonne. I dette eksemplet er språket angitt som engelsk (en) for hele kolonnen. Hvis du lar denne kolonnen stå tom, oppdager Power BI automatisk språket før du bruker funksjonen. Deretter velger du Aktiver.
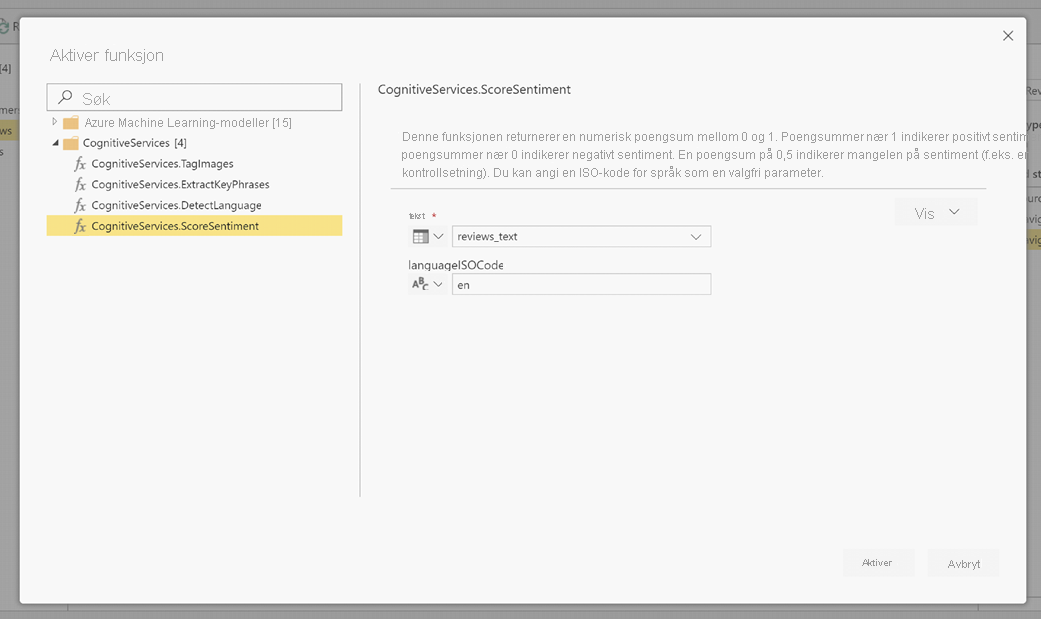
Når du aktiverer funksjonen, legges resultatet til som en ny kolonne i tabellen. Transformasjonen legges også til som et brukt trinn i spørringen.
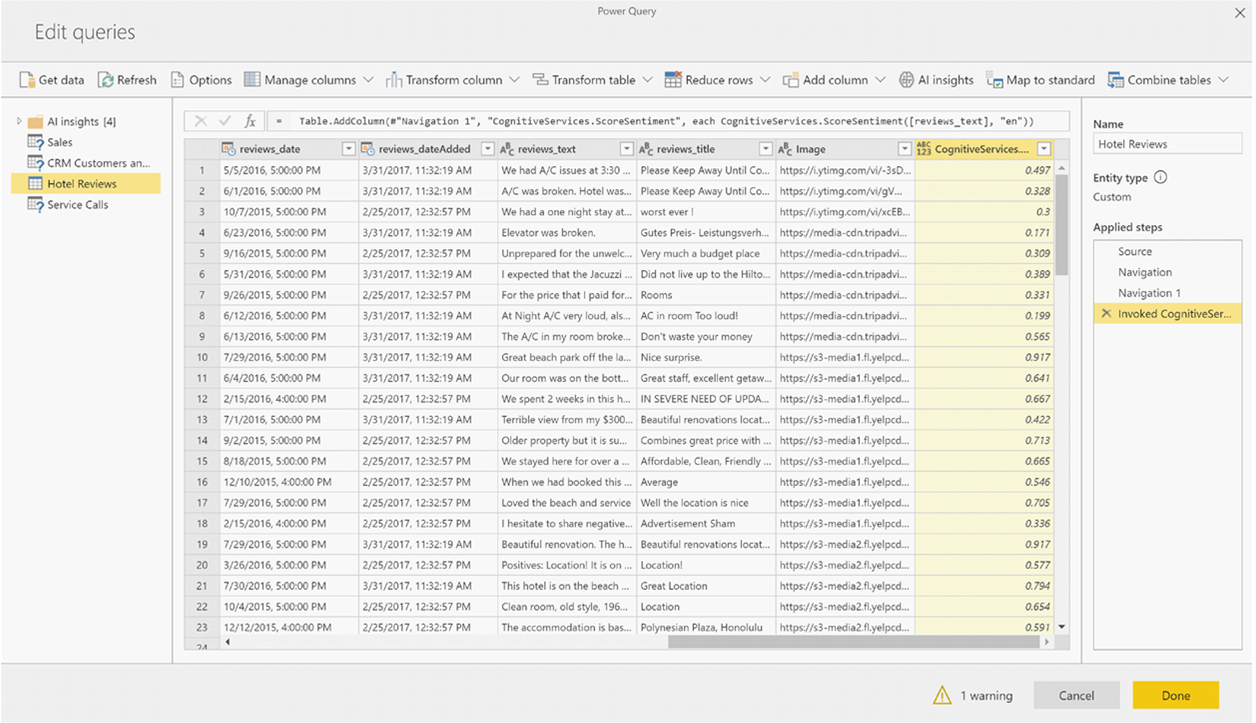
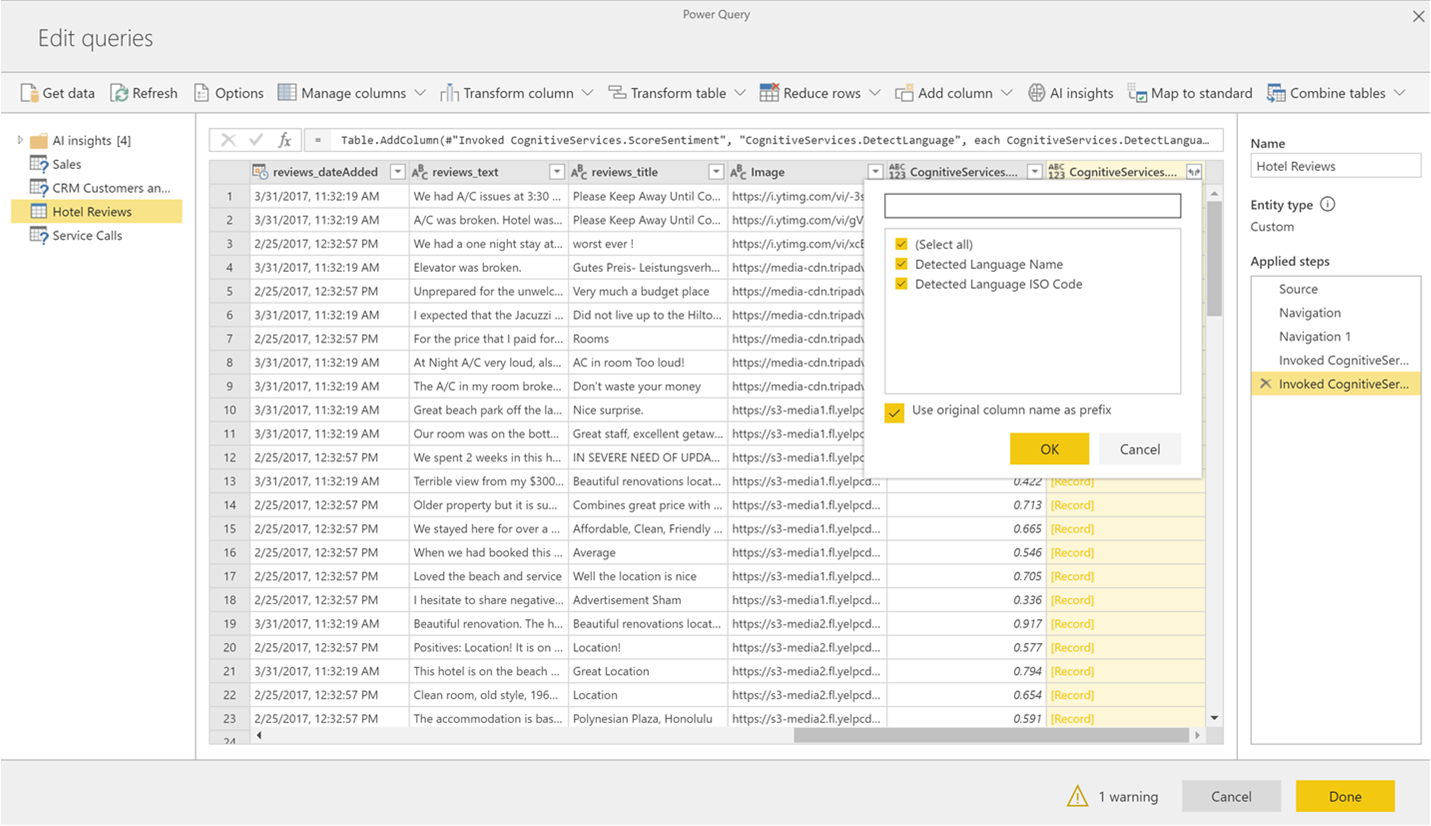
Hvis funksjonen returnerer flere utdatakolonner, legger funksjonen til en ny kolonne med en rad i flere utdatakolonner.
Bruk utvid-alternativet til å legge til én eller begge verdier som kolonner i dataene.
Tilgjengelige funksjoner
Denne delen beskriver de tilgjengelige funksjonene i Cognitive Services i Power BI.
Identifiser språk
Språkgjenkjenningsfunksjonen evaluerer tekstinndata, og returnerer språknavnet og ISO-identifikatoren for hver kolonne. Denne funksjonen er nyttig for datakolonner som samler vilkårlig tekst, der språket er ukjent. Funksjonen forventer data i tekstformat som inndata.
tekstanalyse gjenkjenner opptil 120 språk. Hvis du vil ha mer informasjon, kan du se Hva er språkgjenkjenning i Azure Cognitive Service for language.
Trekk ut nøkkeluttrykk
Funksjonen For uttrekking av nøkkeluttrykk evaluerer ustrukturert tekst, og returnerer en liste over nøkkeluttrykk for hver tekstkolonne. Funksjonen krever en tekstkolonne som inndata og godtar en valgfri inndata for LanguageISOCode. Hvis du vil ha mer informasjon, kan du se Komme i gang.
Uttrekking av nøkkeluttrykk fungerer best når du gir den større deler av teksten å arbeide med, motsatt fra sentimentanalyse. Sentimentanalyse fungerer bedre på mindre tekstblokker. For å få de beste resultatene fra begge operasjonene, bør du vurdere å restrukturere inndataene tilsvarende.
Resultatsentiment
Funksjonen Score sentiment evaluerer tekstinndata og returnerer en sentimentpoengsum for hvert dokument, alt fra 0 (negativ) til 1 (positiv). Denne funksjonen er nyttig for å oppdage positive og negative følelser i sosiale medier, kundeanmeldelser og diskusjonsfora.
tekstanalyse bruker en maskinlæringsklassifiseringsalgoritme til å generere en sentimentpoengsum mellom 0 og 1. Resultater nærmere 1 indikerer positiv sentiment. Resultater nærmere 0 indikerer negativ sentiment. Modellen er forhåndsutdannet med en omfattende teksttekst med sentimenttilknytninger. Det er for øyeblikket ikke mulig å oppgi dine egne opplæringsdata. Modellen bruker en kombinasjon av teknikker under tekstanalyse, inkludert tekstbehandling, del-av-tale-analyse, ordplassering og ordtilknytninger. Hvis du vil ha mer informasjon om algoritmen, kan du se Machine Learning og tekstanalyse.
Sentimentanalyse utføres på hele inndatakolonnen, i motsetning til å trekke ut sentiment for en bestemt tabell i teksten. I praksis er det en tendens til å forbedre poengnøyaktigheten når dokumenter inneholder én eller to setninger i stedet for en stor tekstblokk. I løpet av en objektivitetsvurderingsfase bestemmer modellen om en inndatakolonne som helhet er objektiv eller inneholder sentiment. En inndatakolonne som for det meste er objektiv, går ikke videre til uttrykket for sentimentregistrering, noe som resulterer i en poengsum på 0,50, uten videre behandling. For inndatakolonner som fortsetter i datasamlebåndet, genererer neste fase en poengsum som er større eller mindre enn 0,50, avhengig av graden av sentiment som oppdages i inndatakolonnen.
Sentimentanalyse støtter for øyeblikket engelsk, tysk, spansk og fransk. Andre språk er i forhåndsvisning. Hvis du vil ha mer informasjon, kan du se Hva er språkgjenkjenning i Azure Cognitive Service for language.
Kodebilder
Tag Images-funksjonen returnerer koder basert på mer enn 2000 gjenkjennelige objekter, levende vesener, natur og handlinger. Når koder er tvetydige eller ikke vanlige kunnskaper, gir utdataene hint for å klargjøre betydningen av koden i sammenheng med en kjent innstilling. Merker er ikke organisert som taksonomi, og det finnes ingen arvehierarkier. En samling innholdskoder danner grunnlaget for en bildebeskrivelse som vises som et lesbart språk som er formatert i fullstendige setninger.
Når du har lastet opp et bilde eller angitt en nettadresse for bilder, visuelt innhold utdatakoder for algoritmer basert på objekter, levende vesener og handlinger som er identifisert i bildet. Merking er ikke begrenset til hovedemnet, for eksempel en person i forgrunnen, men inkluderer også innstillingen (innendørs eller utendørs), møbler, verktøy, planter, dyr, tilbehør, gadgets og så videre.
Denne funksjonen krever en URL-adresse for bilde eller abase-64-kolonne som inndata. På dette tidspunktet støtter bildemerking engelsk, spansk, japansk, portugisisk og forenklet kinesisk. Hvis du vil ha mer informasjon, kan du se ComputerVision Interface.
Automatisert maskinlæring i Power BI
Automatisert maskinlæring (AutoML) for dataflyter gjør det mulig for forretningsanalytikere å lære opp, validere og aktivere maskinlæringsmodeller (ML) direkte i Power BI. Det inkluderer en enkel opplevelse for å opprette en ny ML-modell der analytikere kan bruke dataflytene sine til å angi inndata for opplæring av modellen. Tjenesten trekker automatisk ut de mest relevante funksjonene, velger en passende algoritme og justerer og validerer ML-modellen. Når en modell er opplært, genererer Power BI automatisk en ytelsesrapport som inkluderer resultatene av valideringen. Modellen kan deretter aktiveres på eventuelle nye eller oppdaterte data i dataflyten.
Automatisert maskinlæring er bare tilgjengelig for dataflyter som driftes på Power BI Premium- og Embedded-kapasiteter.
Arbeide med AutoML
Maskinlæring og kunstig intelligens ser en enestående økning i popularitet fra bransjer og vitenskapelige forskningsfelt. Bedrifter ser også etter måter å integrere disse nye teknologiene i sin virksomhet på.
Dataflyter tilbyr selvbetjent dataforberedelse for store data. AutoML er integrert i dataflyter og gjør det mulig å bruke dataforberedelsesarbeidet for å bygge maskinlæringsmodeller, direkte i Power BI.
AutoML i Power BI gjør det mulig for dataanalytikere å bruke dataflyter til å bygge maskinlæringsmodeller med en forenklet opplevelse ved å bruke bare Power BI-ferdigheter. Power BI automatiserer det meste av datavitenskapen bak opprettelsen av ML-modellene. Den har rekkverk for å sikre at modellen som produseres har god kvalitet og gir synlighet i prosessen som brukes til å opprette ML-modellen.
AutoML støtter oppretting av binære prognose-, klassifiserings- og regresjonsmodeller for dataflyter. Disse funksjonene er typer maskinlæringsteknikker med tilsyn, noe som betyr at de lærer av de kjente resultatene av tidligere observasjoner for å forutsi resultatene av andre observasjoner. Den semantiske inndatamodellen for opplæring av en AutoML-modell er et sett med rader som er merket med de kjente resultatene.
AutoML i Power BI integrerer automatisert ML fra Azure Machine Learning for å opprette ML-modeller. Du trenger imidlertid ikke et Azure-abonnement for å bruke AutoML i Power BI. Den Power Bi-tjeneste administrerer hele prosessen med opplæring og vert for ML-modellene.
Når en ML-modell er opplært, genererer AutoML automatisk en Power BI-rapport som forklarer den sannsynlige ytelsen til ML-modellen. AutoML understreker forklaringen ved å utheve viktige påvirkere blant inndataene som påvirker prognosene som returneres av modellen. Rapporten inneholder også viktige måledata for modellen.
Andre sider i den genererte rapporten viser statistisk sammendrag av modellen og opplæringsdetaljene. Det statistiske sammendraget er av interesse for brukere som ønsker å se standard mål for datavitenskap for modellytelse. Opplæringsdetaljene oppsummerer alle gjentakelser som ble kjørt for å opprette modellen, med de tilknyttede modelleringsparameterne. Den beskriver også hvordan hver inndata ble brukt til å opprette ML-modellen.
Deretter kan du bruke ML-modellen på dataene for å få poeng. Når dataflyten oppdateres, oppdateres dataene med prognoser fra ML-modellen. Power BI inneholder også en individuell forklaring for hver spesifikke prognose som ML-modellen produserer.
Opprette en maskinlæringsmodell
Denne delen beskriver hvordan du oppretter en AutoML-modell.
Dataforberedelse for å opprette en ML-modell
Hvis du vil opprette en maskinlæringsmodell i Power BI, må du først opprette en dataflyt for dataene som inneholder den historiske resultatinformasjonen, som brukes til opplæring av ML-modellen. Du bør også legge til beregnede kolonner for alle forretningsmål som kan være sterke forutsigelser for resultatet du prøver å forutsi. Hvis du vil ha mer informasjon om hvordan du konfigurerer dataflyten, kan du se Konfigurere og bruke en dataflyt.
AutoML har spesifikke datakrav for opplæring av en maskinlæringsmodell. Disse kravene er beskrevet i avsnittene nedenfor, basert på respektive modelltyper.
Konfigurer ML-modellinndata
Hvis du vil opprette en AutoML-modell, velger du ML-ikonet i Handlinger-kolonnen i dataflyttabellen og velger Legg til en maskinlæringsmodell.
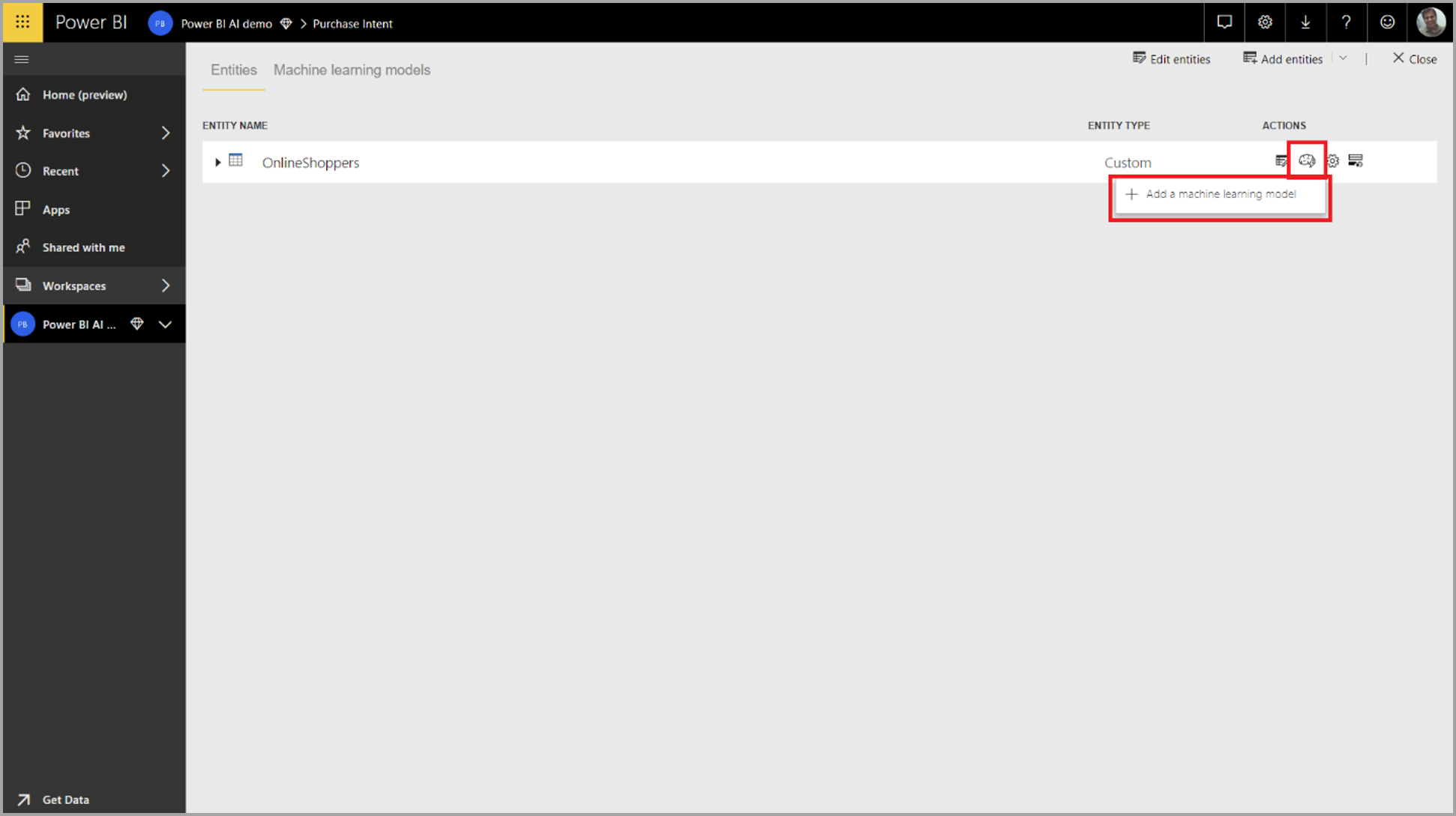
En forenklet opplevelse starter, som består av en veiviser som veileder deg gjennom prosessen med å opprette ML-modellen. Veiviseren inneholder følgende enkle trinn.
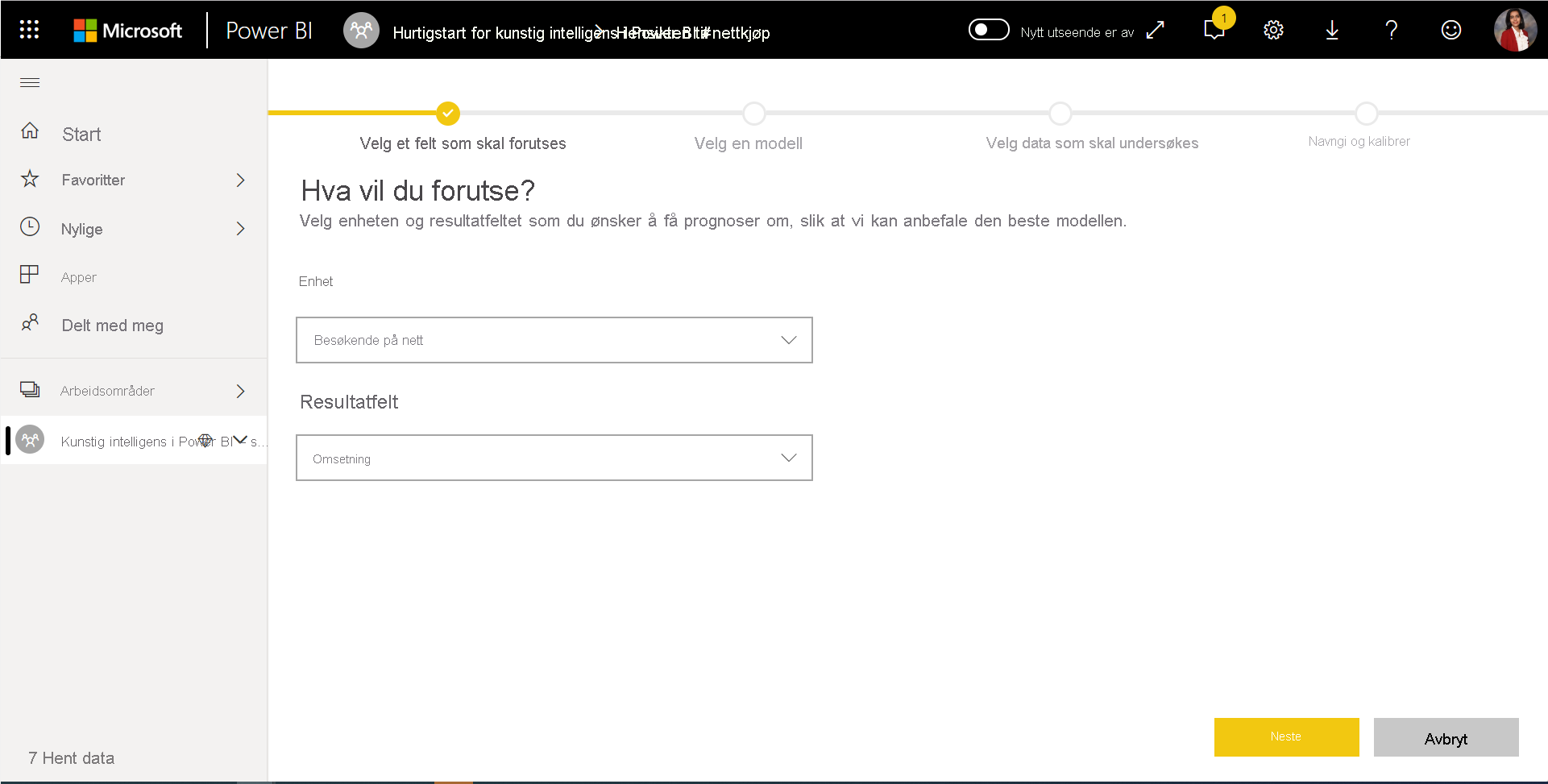
1. Velg tabellen med de historiske dataene, og velg resultatkolonnen du vil finne en prognose for
Resultatkolonnen identifiserer etikettattributtet for opplæring av ML-modellen, som vises på bildet nedenfor.
2. Velg en modelltype
Når du angir resultatkolonnen, analyserer AutoML etikettdataene for å anbefale den mest sannsynlige ML-modelltypen som kan læres opp. Du kan velge en annen modelltype som vist i bildet nedenfor ved å klikke på Velg en modell.
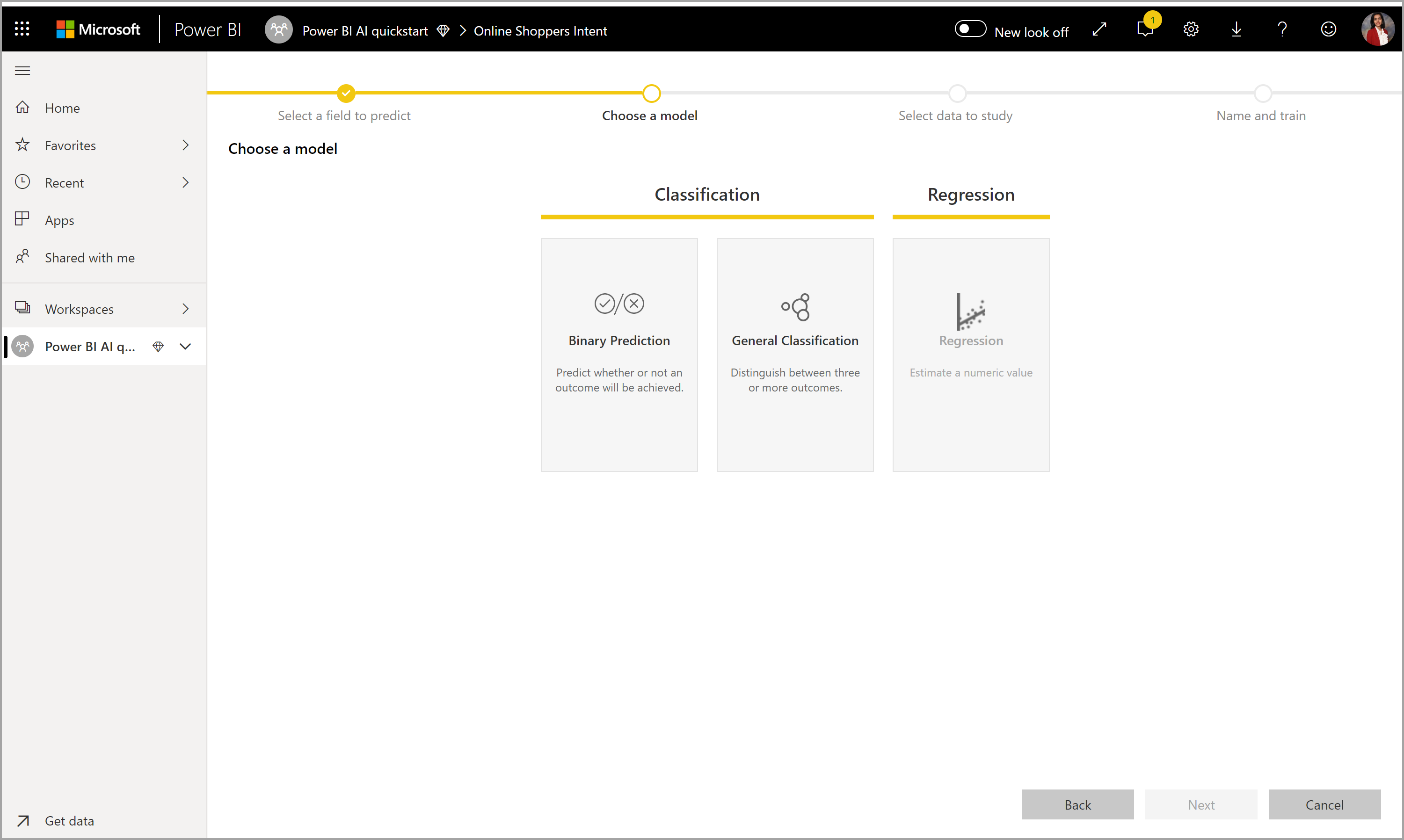
Merk
Enkelte modelltyper støttes kanskje ikke for dataene du har valgt, og derfor deaktiveres den. I det forrige eksemplet deaktiveres Regresjon fordi en tekstkolonne er valgt som resultatkolonne.
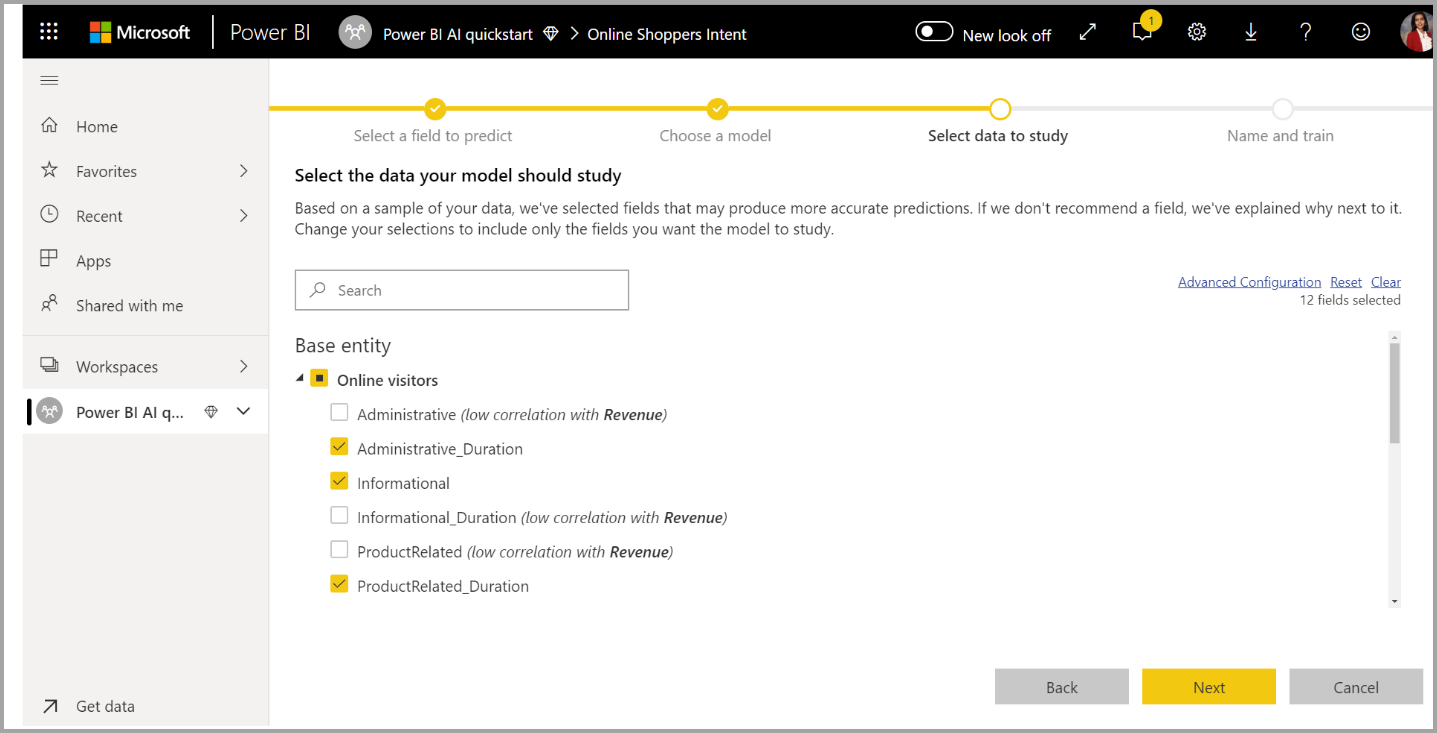
3. Velg inndataene du vil at modellen skal bruke som prediktive signaler
AutoML analyserer et utvalg av den valgte tabellen for å foreslå inndataene som kan brukes til opplæring av ML-modellen. Forklaringer gis ved siden av kolonner som ikke er valgt. Hvis en bestemt kolonne har for mange distinkte verdier eller bare én verdi, eller lav eller høy korrelasjon med utdatakolonnen, anbefales det ikke.
Eventuelle inndata som er avhengige av resultatkolonnen (eller etikettkolonnen), bør ikke brukes til opplæring av ML-modellen, siden de påvirker ytelsen. Slike kolonner er flagget som å ha «mistenkelig høy korrelasjon med utdatakolonne». Innføring av disse kolonnene i opplæringsdataene fører til etikettlekkasje, der modellen fungerer bra på validerings- eller testdataene, men ikke kan samsvare med denne ytelsen når den brukes i produksjon for scoring. Etikettlekkasje kan være en mulig bekymring i AutoML-modeller når ytelsen til opplæringsmodellen er for god til å være sann.
Denne funksjonsanbefalingen er basert på et utvalg av data, så du bør se gjennom inndataene som brukes. Du kan endre valgene til å inkludere bare kolonnene du vil at modellen skal studere. Du kan også merke alle kolonnene ved å merke av for tabellnavnet.
4. Gi modellen et navn, og lagre konfigurasjonen
I det siste trinnet kan du gi modellen et navn, velge Lagre og velge hvilken som begynner å lære opp ML-modellen. Du kan velge å redusere opplæringstiden for å se raske resultater eller øke tiden som brukes i opplæringen for å få den beste modellen.
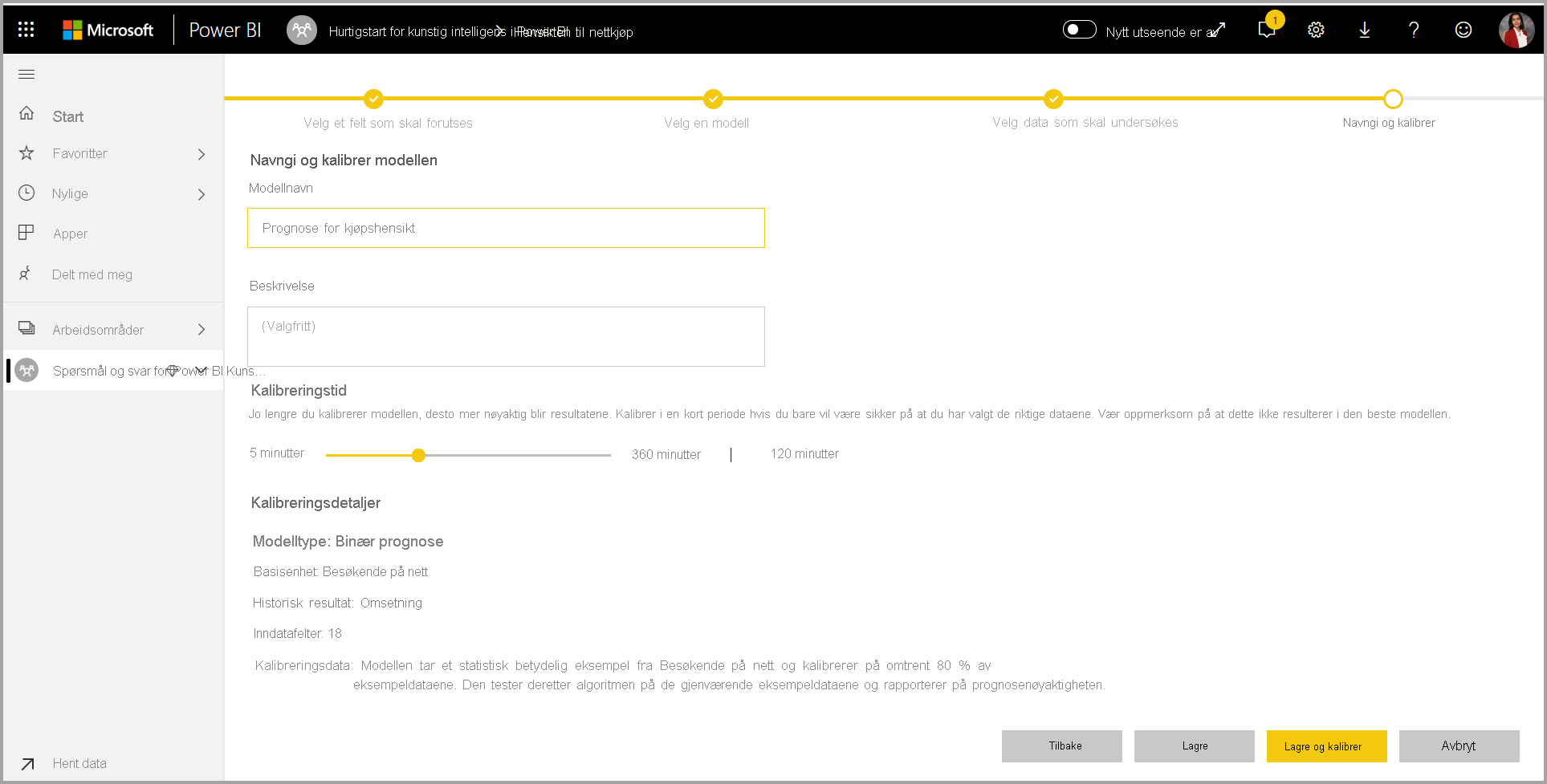
Opplæring for ML-modell
Opplæring av AutoML-modeller er en del av dataflytoppdateringen. AutoML klargjør først dataene for opplæring. AutoML deler de historiske dataene du gir til opplæring og testing av semantiske modeller. Semantisk testmodell er et holdout-sett som brukes til å validere modellytelsen etter opplæring. Disse settene er realisert som opplærings- og testtabeller i dataflyten. AutoML bruker kryssvalidering for modellvalidering.
Deretter analyseres hver inndatakolonne og imputering brukes, noe som erstatter eventuelle manglende verdier med erstattede verdier. Et par ulike imputeringsstrategier brukes av AutoML. For inndataattributter som behandles som numeriske funksjoner, brukes gjennomsnittet for kolonneverdiene til imputering. For inndataattributter som behandles som kategoriske funksjoner, bruker AutoML modusen for kolonneverdiene for imputering. AutoML-rammeverket beregner middelverdien og modusen for verdier som brukes for imputering på den semantiske modellen for subsamplede opplæringer.
Deretter brukes sampling og normalisering på dataene etter behov. For klassifiseringsmodeller kjører AutoML inndata gjennom stratifisert sampling og balanserer klassene for å sikre at radantallene er like for alle.
AutoML bruker flere transformasjoner på hver valgte inndatakolonne basert på datatypen og statistiske egenskaper. AutoML bruker disse transformasjonene til å trekke ut funksjoner for bruk i opplæring av ML-modellen.
Opplæringsprosessen for AutoML-modeller består av opptil 50 gjentakelser med ulike modelleringsalgoritmer og hyperparameterinnstillinger for å finne modellen med best ytelse. Opplæringen kan avsluttes tidlig med mindre gjentakelser hvis AutoML oppdager at det ikke er noen ytelsesforbedring som blir observert. AutoML vurderer ytelsen til hver av disse modellene ved å validere med semantisk modell for holdout-test. I løpet av dette opplæringstrinnet oppretter AutoML flere datasamlebånd for opplæring og validering av disse gjentakelsene. Prosessen med å vurdere ytelsen til modellene kan ta tid, alt fra flere minutter, til et par timer, opp til opplæringstiden som er konfigurert i veiviseren. Tiden det tar, avhenger av størrelsen på den semantiske modellen og kapasitetsressursene som er tilgjengelige.
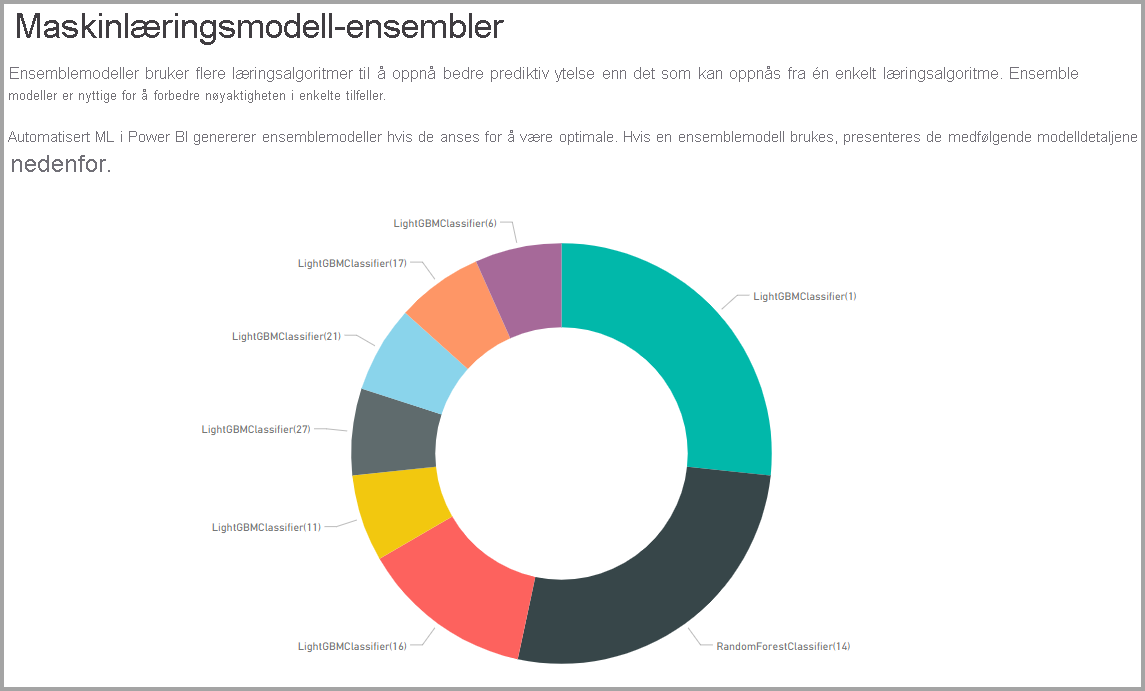
I noen tilfeller kan den endelige modellen som genereres bruke ensemblelæring, der flere modeller brukes til å levere bedre prediktiv ytelse.
AutoML-modell forklarbarhet
Når modellen er opplært, analyserer AutoML relasjonen mellom inndatafunksjonene og modellutdataene. Den vurderer størrelsen på endringen i modellutdataene for semantisk modell for holdout-test for hver inndatafunksjon. Denne relasjonen kalles funksjonens viktighet. Denne analysen skjer som en del av oppdateringen etter at opplæringen er fullført. Derfor kan oppdateringen ta lengre tid enn opplæringstiden som er konfigurert i veiviseren.
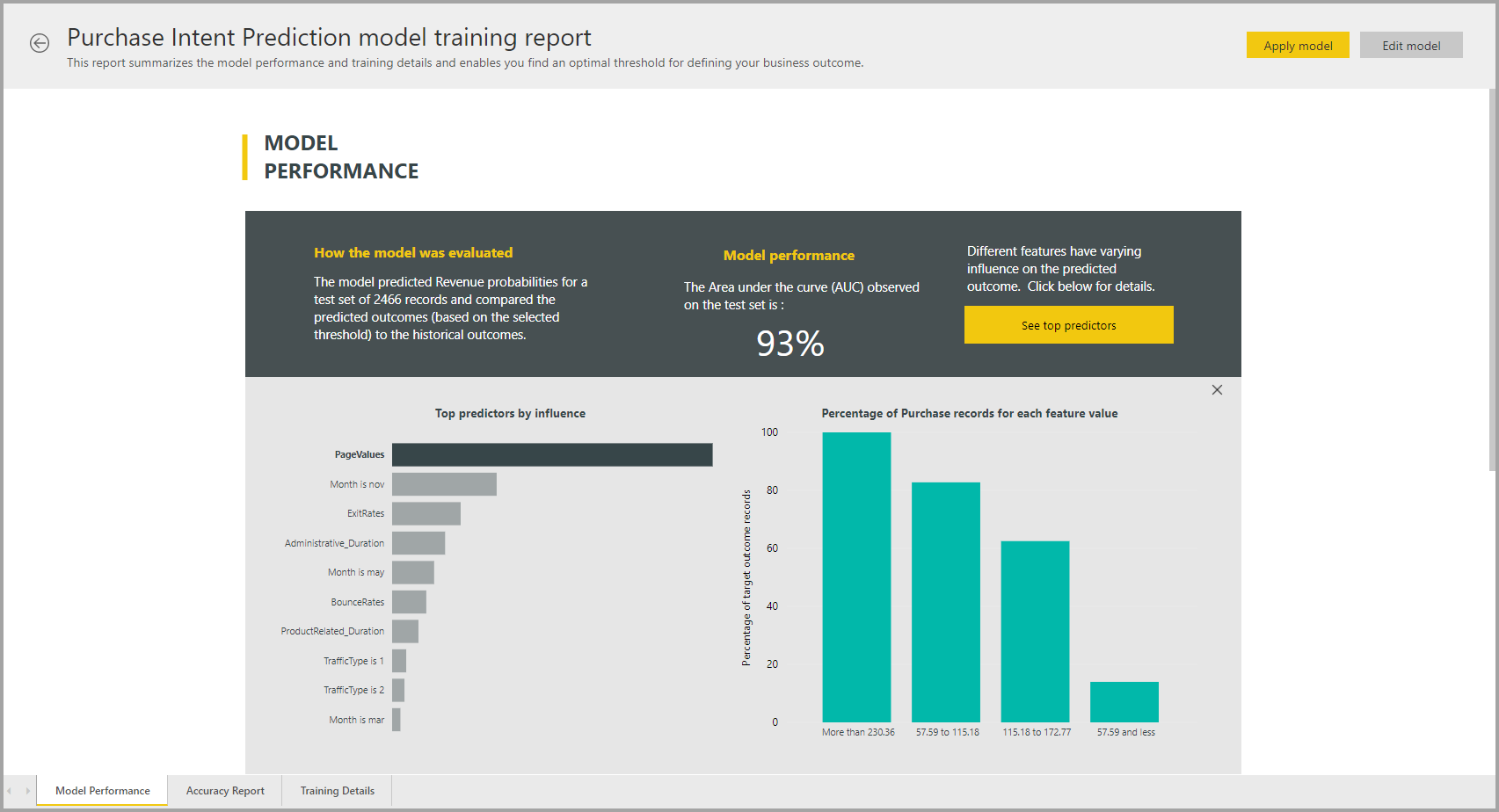
AutoML-modellrapport
AutoML genererer en Power BI-rapport som oppsummerer ytelsen til modellen under validering, sammen med den globale funksjons viktigheten. Denne rapporten kan nås fra maskinlæringsmodeller-fanen etter at dataflytoppdateringen er vellykket. Rapporten oppsummerer resultatene fra å bruke ML-modellen på testdataene for sperring og sammenligning av prognoser med de kjente resultatverdiene.
Du kan se gjennom modellrapporten for å forstå ytelsen. Du kan også bekrefte at de viktigste påvirkerne av modellen samsvarer med forretningsinnsiktene om de kjente resultatene.
Diagrammene og målene som brukes til å beskrive modellytelsen i rapporten, avhenger av modelltypen. Disse ytelsesdiagrammene og målene er beskrevet i avsnittene nedenfor.
Andre sider i rapporten kan beskrive statistiske mål om modellen fra et datavitenskapelig perspektiv. Den binære prognoserapporten inneholder for eksempel et gevinstdiagram og ROC-kurven for modellen.
Rapportene inneholder også en side for opplæringsdetaljer som inneholder en beskrivelse av hvordan modellen ble kalibrert, og et diagram som beskriver modellytelsen over hver av gjentakelsene som kjøres.
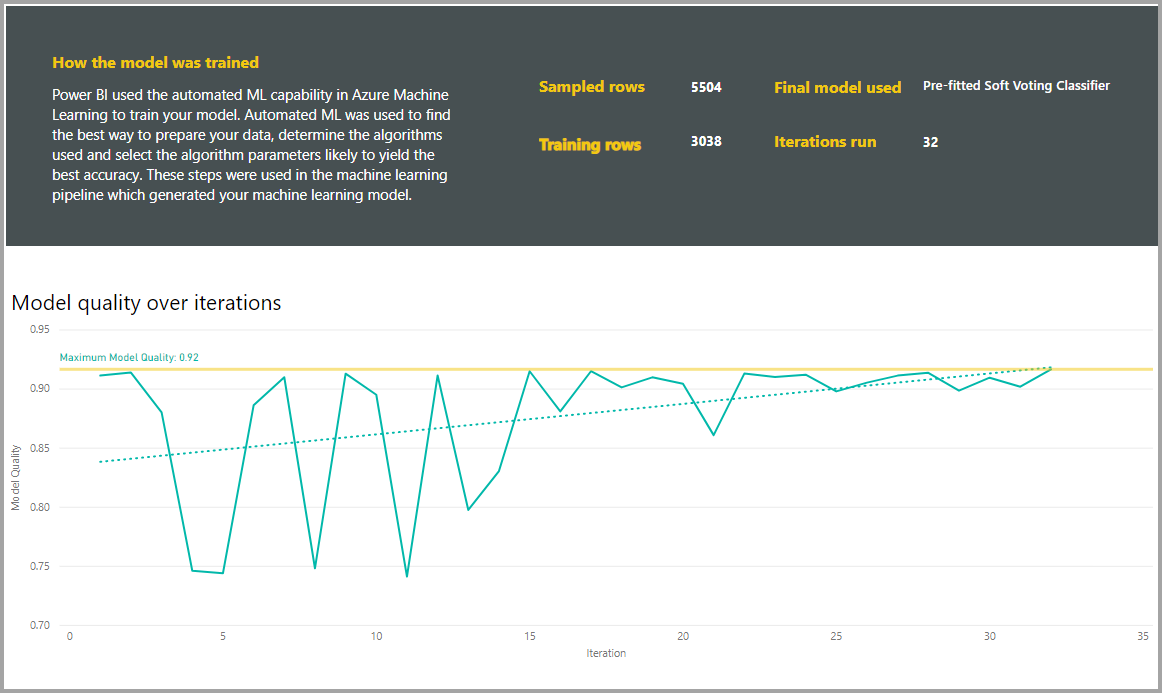
En annen inndeling på denne siden beskriver den oppdagede typen inndatakolonne og imputeringsmetode som brukes til å fylle ut manglende verdier. Den inneholder også parameterne som brukes av den endelige modellen.
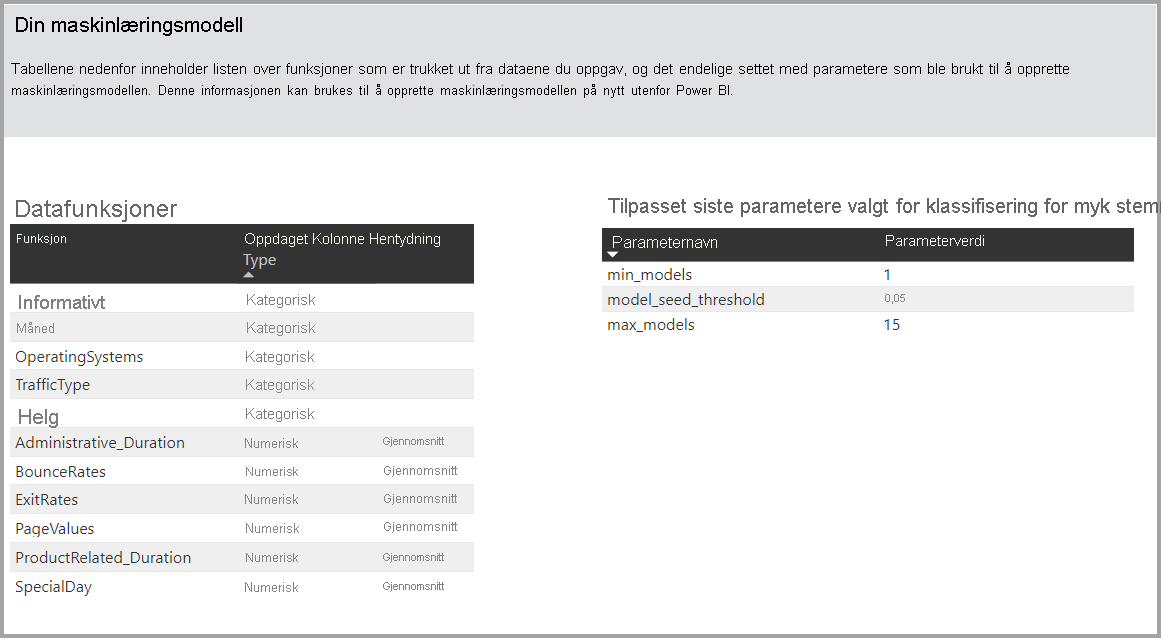
Hvis modellen som produseres bruker ensemblelæring, inneholder opplæringsdetaljer-siden også et diagram som viser vekten til hver konstituerende modell i ensemblet og parameterne.
Bruke AutoML-modellen
Hvis du er fornøyd med ytelsen til ML-modellen som er opprettet, kan du bruke den på nye eller oppdaterte data når dataflyten oppdateres. Velg Bruk-knappen øverst til høyre i modellrapporten, eller Bruk ML-modell under handlinger på fanen Maskinlæringsmodeller .
Hvis du vil bruke ML-modellen, må du angi navnet på tabellen den må brukes på, og et prefiks for kolonnene som skal legges til i denne tabellen for modellutdataene. Standardprefikset for kolonnenavnene er modellnavnet. Bruk-funksjonen kan inneholde flere parametere som er spesifikke for modelltypen.
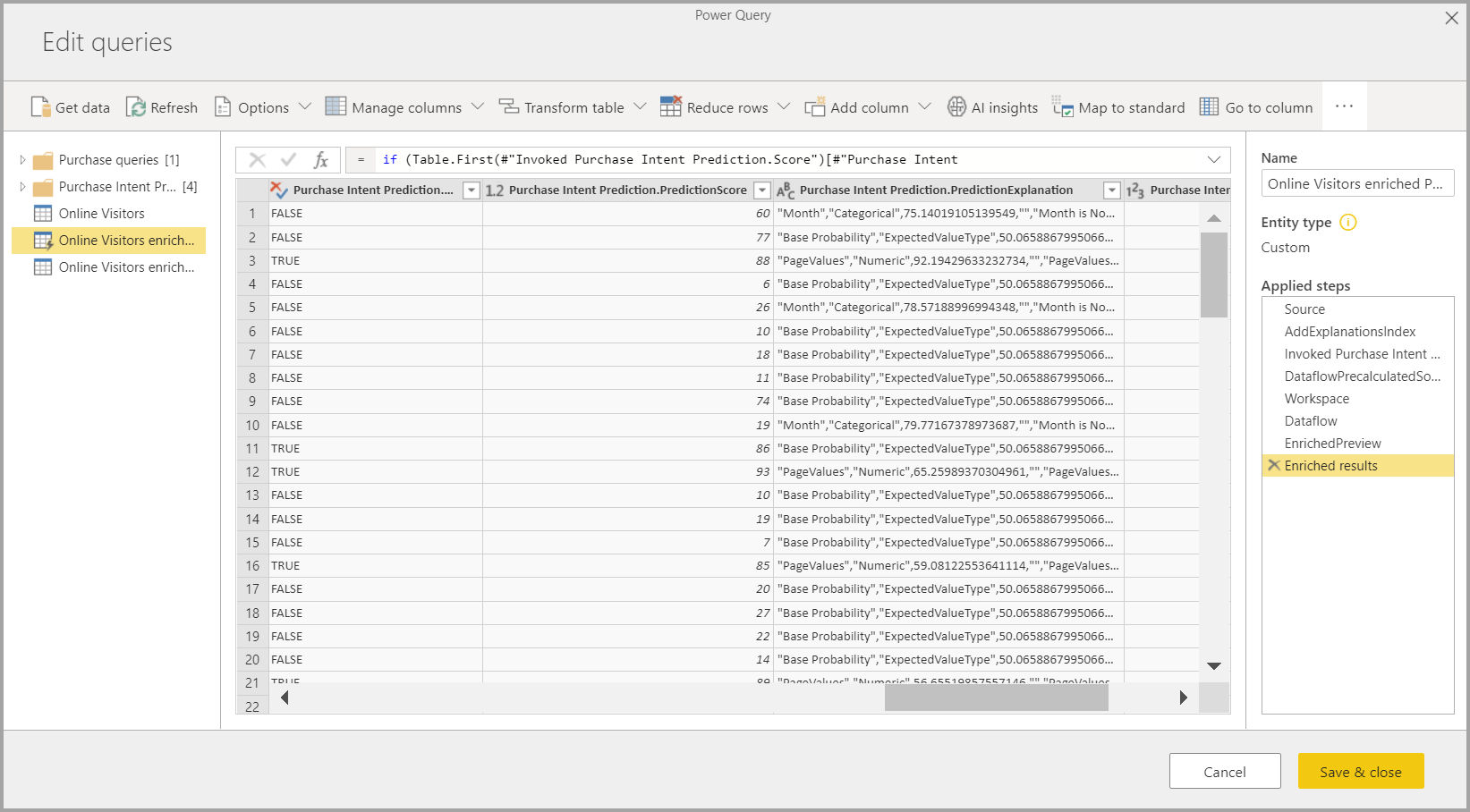
Bruk av ML-modellen oppretter to nye dataflyttabeller som inneholder prognoser og individuelle forklaringer for hver rad den scorer i utdatatabellen. Hvis du for eksempel bruker PurchaseIntent-modellen på OnlineShoppers-tabellen, genererer utdataene tabellene OnlineShoppers berikede PurchaseIntent- og OnlineShoppers-berikede PurchaseIntent-forklaringstabeller. For hver rad i den berikede tabellen deles forklaringene opp i flere rader i tabellen med berikede forklaringer basert på inndatafunksjonen. En ExplanationIndex bidrar til å tilordne radene fra den berikede forklaringstabellen til raden i enriched tabell.
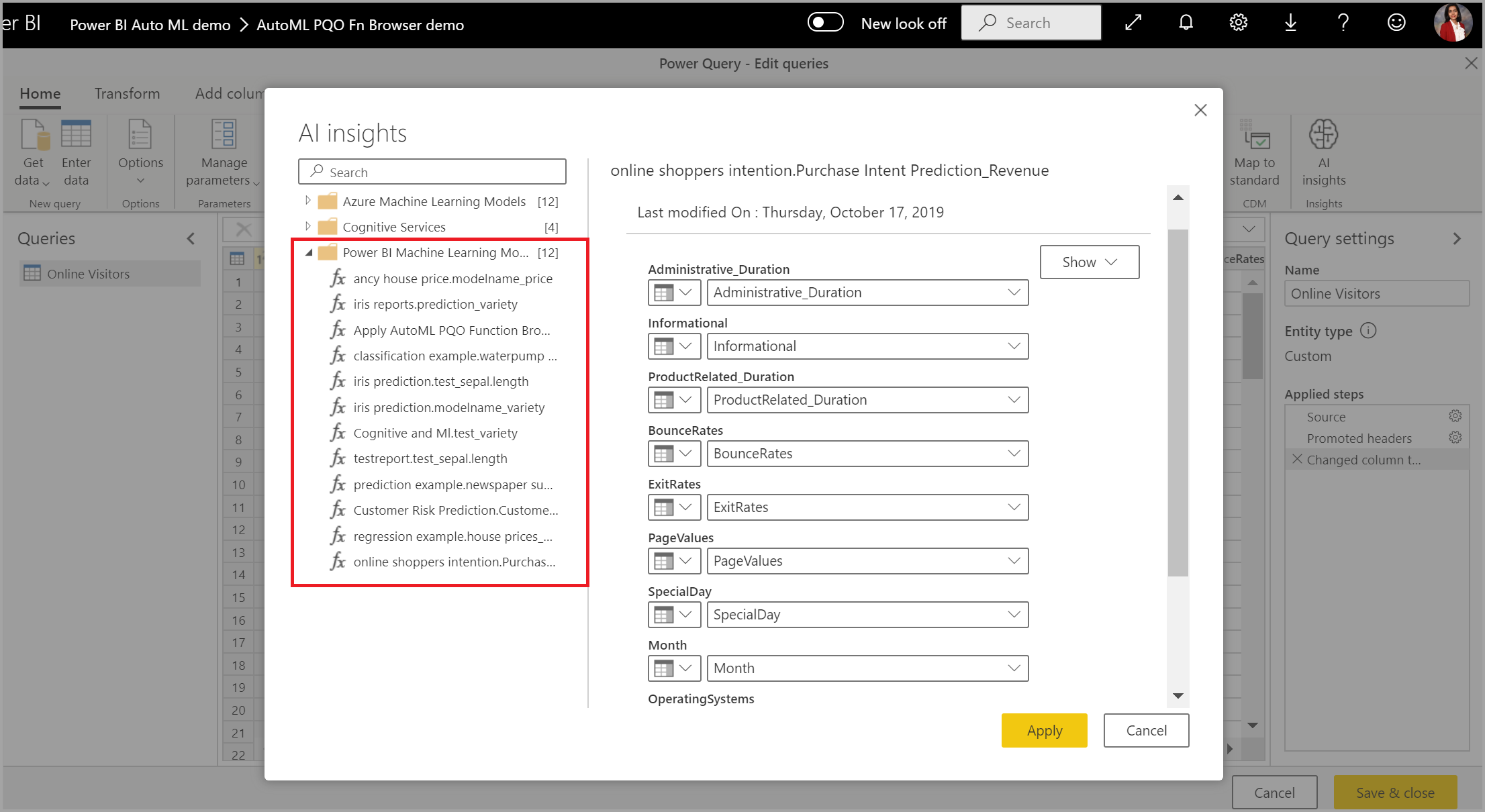
Du kan også bruke en Hvilken som helst Power BI AutoML-modell på tabeller i en hvilken som helst dataflyt i samme arbeidsområde ved hjelp av Kunstig intelligens i PQO-funksjonsnettleseren. På denne måten kan du bruke modeller som er opprettet av andre i samme arbeidsområde, uten nødvendigvis å være eier av dataflyten som har modellen. Power Query oppdager alle Power BI ML-modellene i arbeidsområdet og viser dem som dynamiske Power Query-funksjoner. Du kan aktivere disse funksjonene ved å få tilgang til dem fra båndet i Power Query-redigering eller ved å aktivere M-funksjonen direkte. Denne funksjonaliteten støttes for øyeblikket bare for Power BI-dataflyter og for Power Query Online i Power Bi-tjeneste. Denne prosessen er forskjellig fra å bruke ML-modeller i en dataflyt ved hjelp av AutoML-veiviseren. Det er ingen forklaringstabell som er opprettet ved hjelp av denne metoden. Med mindre du er eieren av dataflyten, får du ikke tilgang til modellopplæringsrapporter eller omskolere modellen. Hvis kildemodellen redigeres ved å legge til eller fjerne inndatakolonner eller at modellen eller kildedataflyten slettes, brytes også denne avhengige dataflyten.
Når du har brukt modellen, holder AutoML alltid prognosene oppdatert når dataflyten oppdateres.
Hvis du vil bruke innsikt og prognoser fra ML-modellen i en Power BI-rapport, kan du koble til utdatatabellen fra Power BI Desktop ved hjelp av dataflytkoblingen.
Binære prognosemodeller
Binære prognosemodeller, mer formelt kjent som binære klassifiseringsmodeller, brukes til å klassifisere en semantisk modell i to grupper. De brukes til å forutsi hendelser som kan ha et binært resultat. For eksempel om en salgsmulighet vil konvertere, om en konto vil frafalle, om en faktura skal betales i tide, om en transaksjon er uredelig og så videre.
Utdataene for en binær forutsigelsesmodell er en sannsynlighetspoengsum, som identifiserer sannsynligheten for at målresultatet oppnås.
Lære opp en binær forutsigelsesmodell
Forutsetninger:
- Minimum 20 rader med historiske data kreves for hver klasse med resultater
Opprettingsprosessen for en binær forutsigelsesmodell følger de samme trinnene som andre AutoML-modeller, beskrevet i forrige del, Konfigurer ML-modellinndata. Den eneste forskjellen er i velg et modelltrinn der du kan velge målresultatverdien du er mest interessert i. Du kan også angi egendefinerte etiketter for resultatene som skal brukes i den automatisk genererte rapporten som oppsummerer resultatene av modellvalideringen.
Binær prognosemodellrapport
Binærprognosemodellen produserer som utdata en sannsynlighet for at en rad oppnår målresultatet. Rapporten inneholder en slicer for sannsynlighetsterskelen, som påvirker hvordan resultatene som er større og mindre enn sannsynlighetsterskelen tolkes.
Rapporten beskriver ytelsen til modellen når det gjelder sanne positiver, falske positiver, sanne negativer og falske negativer. Sanne positiver og sanne negativer er riktig beregnede resultater for de to klassene i resultatdataene. Falske positiver er rader som ble spådd å ha målresultat, men faktisk ikke. Derimot er falske negativer rader som hadde målresultater, men ble spådd som ikke dem.
Mål, for eksempel Presisjon og Tilbakekalling, beskriver effekten av sannsynlighetsterskelen på de forventede resultatene. Du kan bruke sliceren for sannsynlighetsterskel til å velge en terskel som oppnår et balansert kompromiss mellom Presisjon og Tilbakekalling.
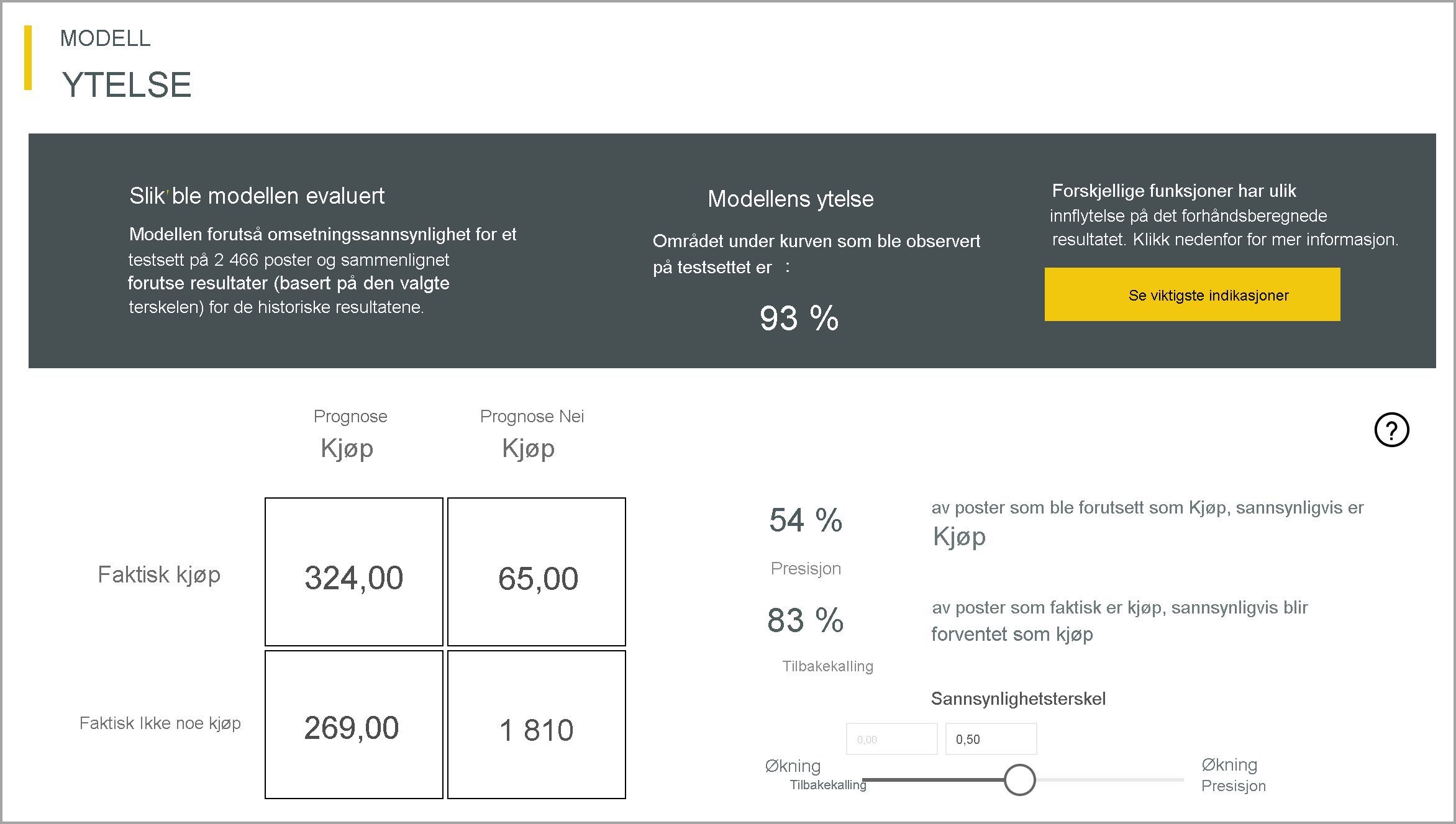
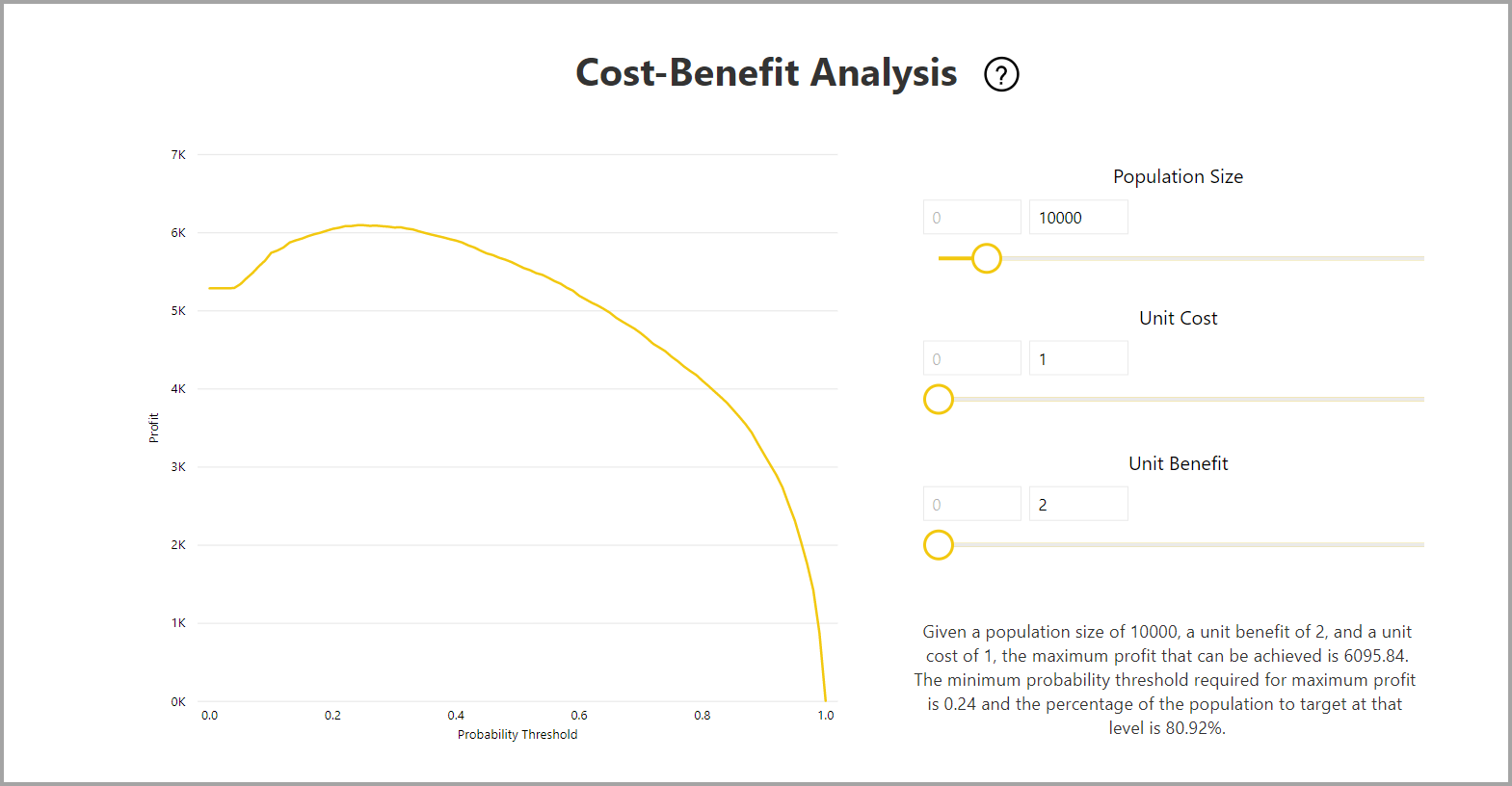
Rapporten inneholder også et analyseverktøy for kost-nytte for å identifisere delsettet av populasjonen som bør være målrettet for å gi høyest fortjeneste. Gitt en estimert enhetskostnad for målretting og en enhetsfordel ved å oppnå et målresultat, forsøker Cost-Benefit-analyse å maksimere fortjenesten. Du kan bruke dette verktøyet til å velge sannsynlighetsterskelen basert på maksimumspunktet i grafen for å maksimere fortjenesten. Du kan også bruke grafen til å beregne fortjeneste eller kostnad for ditt valg av sannsynlighetsterskel.
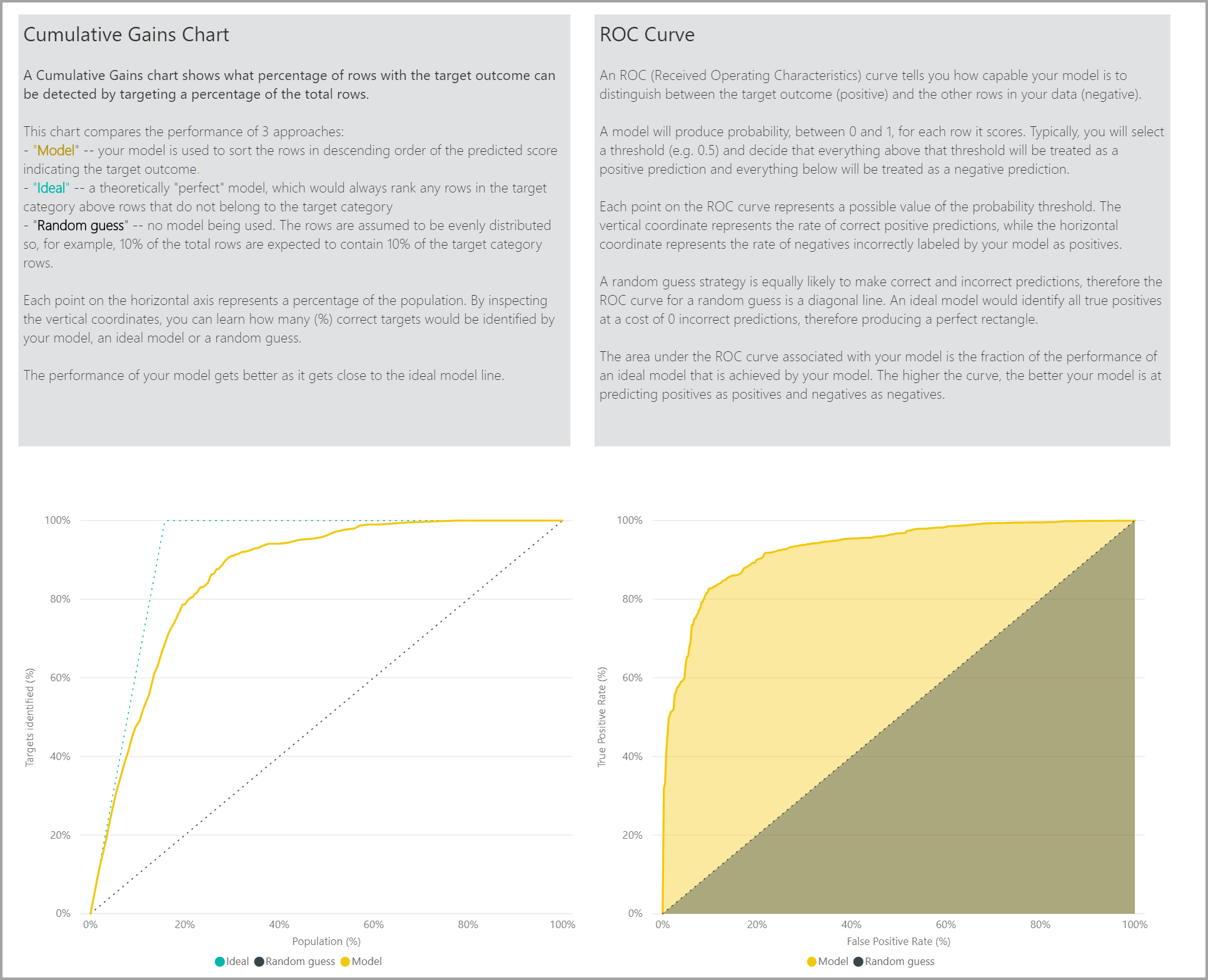
Nøyaktighetsrapportsiden i modellrapporten inkluderer diagrammet Kumulative gevinster og ROC-kurven for modellen. Disse dataene gir statistiske mål for modellytelsen. Rapportene inneholder beskrivelser av diagrammene som vises.
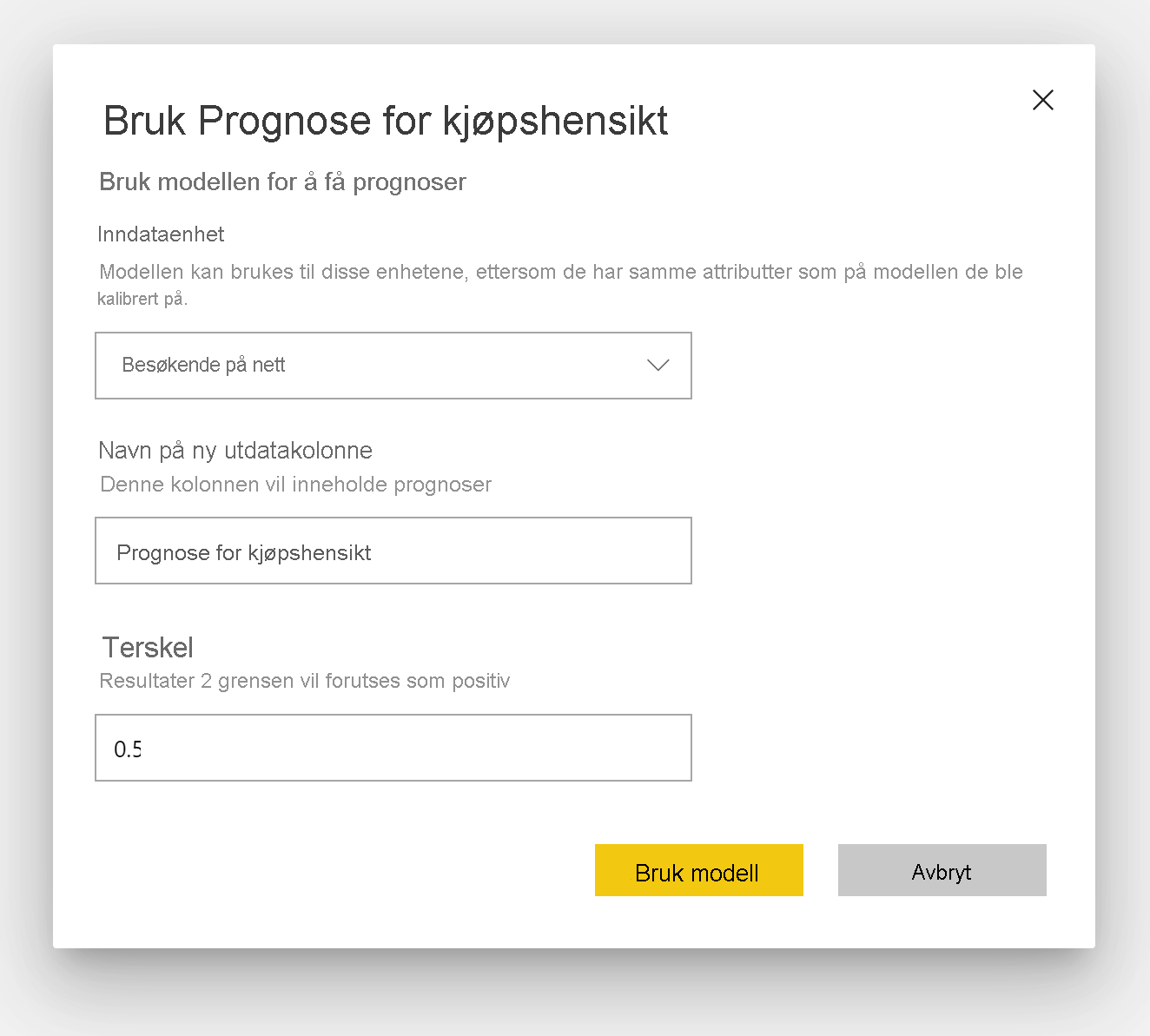
Bruke en binær forutsigelsesmodell
Hvis du vil bruke en binær forutsigelsesmodell, må du angi tabellen med dataene du vil bruke prognoser fra ML-modellen på. Andre parametere inkluderer prefikset for utdatakolonnenavn og sannsynlighetsterskelen for å klassifisere det forventede resultatet.
Når en binær forutsigelsesmodell brukes, legger den til fire utdatakolonner i den berikede utdatatabellen: Resultat, PredictionScore, PredictionExplanation og ExplanationIndex. Kolonnenavnene i tabellen har prefikset angitt når modellen brukes.
PredictionScore er en prosentvis sannsynlighet, som identifiserer sannsynligheten for at målresultatet oppnås.
Resultatkolonnen inneholder den forventede resultatetiketten. Poster med sannsynligheter som overskrider terskelen, forutses som sannsynlige for å oppnå målresultatet og blir merket som Sann. Poster som er mindre enn terskelen, forutses som usannsynlige for å oppnå resultatet og merkes som Usann.
PredictionExplanation-kolonnen inneholder en forklaring med den spesifikke påvirkningen som inndatafunksjonene hadde på PredictionScore.
Klassifiseringsmodeller
Klassifiseringsmodeller brukes til å klassifisere en semantisk modell i flere grupper eller klasser. De brukes til å forutsi hendelser som kan ha ett av de mange mulige resultatene. For eksempel om en kunde sannsynligvis vil ha en høy, middels eller lav levetidsverdi. De kan også forutsi om risikoen for standard er høy, moderat, lav og så videre.
Utdataene for en klassifiseringsmodell er en sannsynlighetspoengsum, som identifiserer sannsynligheten for at en rad oppnår kriteriene for en gitt klasse.
Lære opp en klassifiseringsmodell
Inndatatabellen som inneholder opplæringsdataene for en klassifiseringsmodell, må ha en streng- eller heltallkolonne som resultatkolonne, som identifiserer tidligere kjente resultater.
Forutsetninger:
- Minimum 20 rader med historiske data kreves for hver klasse med resultater
Prosessen med å opprette en klassifiseringsmodell følger de samme trinnene som andre AutoML-modeller, beskrevet i forrige del, Konfigurer ML-modellinndata.
Rapport for klassifiseringsmodell
Power BI oppretter klassifiseringsmodellrapporten ved å bruke ML-modellen på testdataene for sperring. Deretter sammenligner den den forventede klassen for en rad med den faktiske kjente klassen.
Modellrapporten inneholder et diagram som inneholder fordelingen av de korrekte og feil klassifiserte radene for hver kjente klasse.
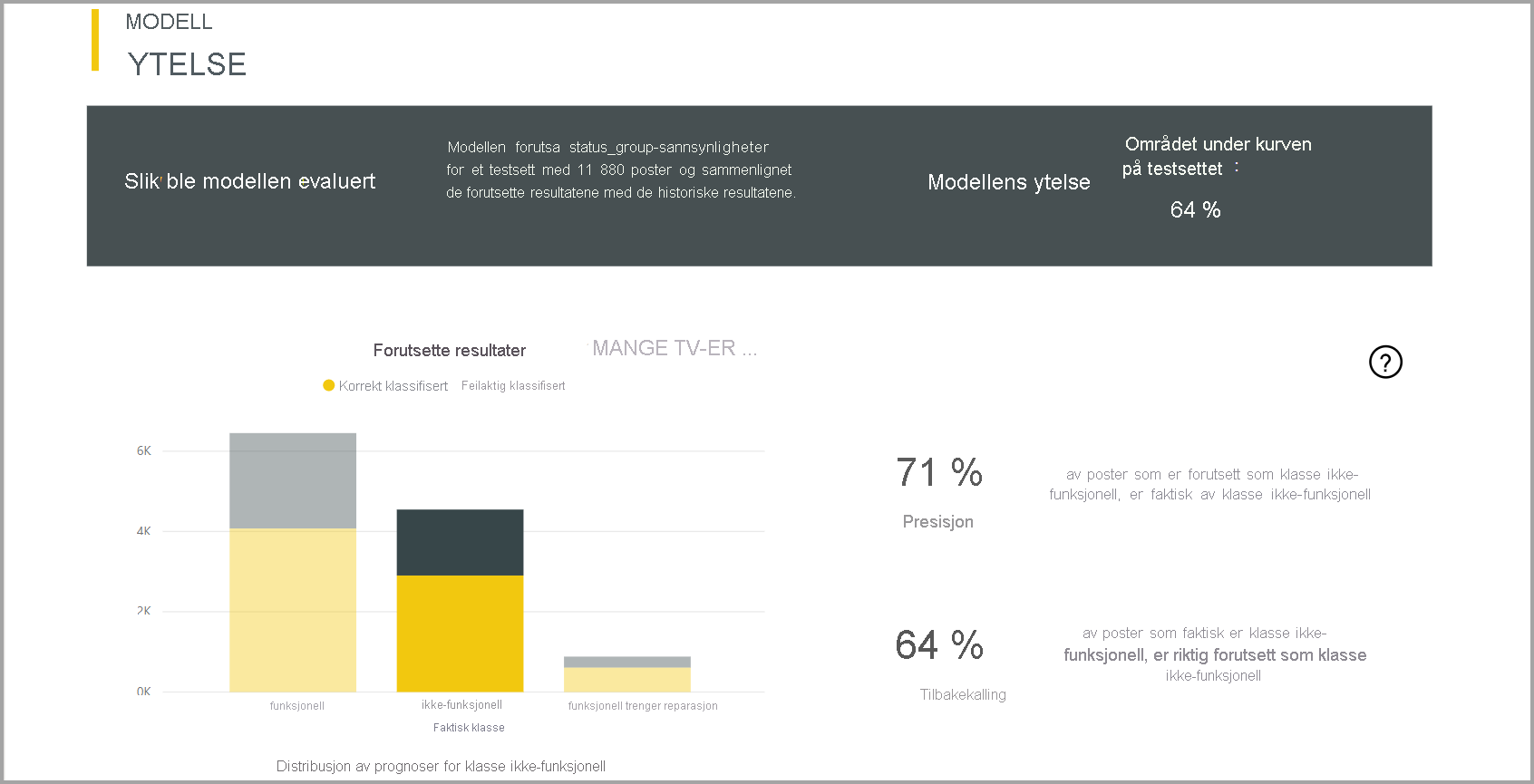
En ytterligere klassespesifikk neddrillingshandling muliggjør en analyse av hvordan prognosene for en kjent klasse distribueres. Denne analysen viser de andre klassene der rader i den kjente klassen sannsynligvis vil bli feilklassifisert.
Modell forklaringen i rapporten inneholder også de beste prediktorene for hver klasse.
Klassifiseringsmodellrapporten inneholder også en side for opplæringsdetaljer som ligner på sidene for andre modelltyper, som beskrevet tidligere, i automl-modellrapporten.
Bruke en klassifiseringsmodell
Hvis du vil bruke en klassifiseringsmodell for ML, må du angi tabellen med inndata og utdatakolonnenavnprefikset.
Når en klassifiseringsmodell brukes, legger den til fem utdatakolonner i den berikede utdatatabellen: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities og ExplanationIndex. Kolonnenavnene i tabellen har prefikset angitt når modellen brukes.
ClassProbabilities-kolonnen inneholder listen over sannsynlighetsresultater for raden for hver mulige klasse.
ClassificationScore er den prosentvise sannsynligheten, som identifiserer sannsynligheten for at en rad vil oppnå kriteriene for en gitt klasse.
ClassificationResult-kolonnen inneholder den mest sannsynlige klassen for raden.
ClassificationExplanation-kolonnen inneholder en forklaring med den spesifikke påvirkningen som inndatafunksjonene hadde på ClassificationScore.
Regresjonsmodeller
Regresjonsmodeller brukes til å forutsi en numerisk verdi og kan brukes i scenarioer som å bestemme:
- Omsetningen vil sannsynligvis bli realisert fra en salgsavtale.
- Levetidsverdien for en konto.
- Beløpet for en faktura som sannsynligvis vil bli betalt
- Datoen en faktura kan betales, og så videre.
Utdataene for en regresjonsmodell er den antatte verdien.
Lære opp en regresjonsmodell
Inndatatabellen som inneholder opplæringsdataene for en regresjonsmodell, må ha en numerisk kolonne som resultatkolonne, som identifiserer de kjente resultatverdiene.
Forutsetninger:
- Minimum 100 rader med historiske data kreves for en regresjonsmodell.
Prosessen med å opprette en regresjonsmodell følger de samme trinnene som andre AutoML-modeller, beskrevet i forrige del, Konfigurer ML-modellinndata.
Regresjonsmodellrapport
I likhet med de andre autoML-modellrapportene er regresjonsrapporten basert på resultatene fra å bruke modellen på testdataene for sperring.
Modellrapporten inneholder et diagram som sammenligner de forventede verdiene med de faktiske verdiene. I dette diagrammet angir avstanden fra diagonalen feilen i prognosen.
Diagrammet for gjenværende feil viser fordelingen av prosentdelen av gjennomsnittsfeilen for ulike verdier i semantisk modell for semantisk holdout-test. Den vannrette aksen representerer gjennomsnittet for den faktiske verdien for gruppen. Størrelsen på boblen viser hyppigheten eller antallet verdier i dette området. Den loddrette aksen er den gjennomsnittlige gjenværende feilen.
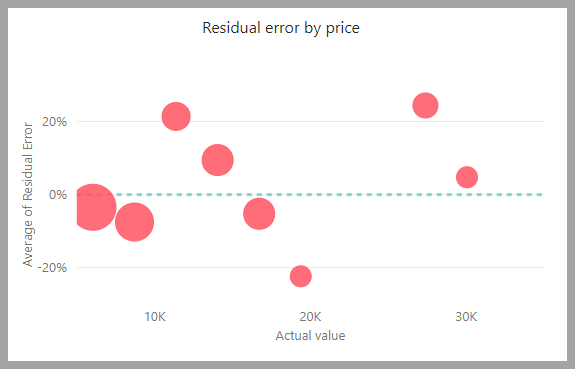
Regresjonsmodellrapporten inneholder også en side med opplæringsdetaljer, for eksempel rapporter for andre modelltyper, som beskrevet i forrige del, AutoML-modellrapport.
Bruke en regresjonsmodell
Hvis du vil bruke en regresjons-ML-modell, må du angi tabellen med inndata og utdatakolonnenavnprefikset.
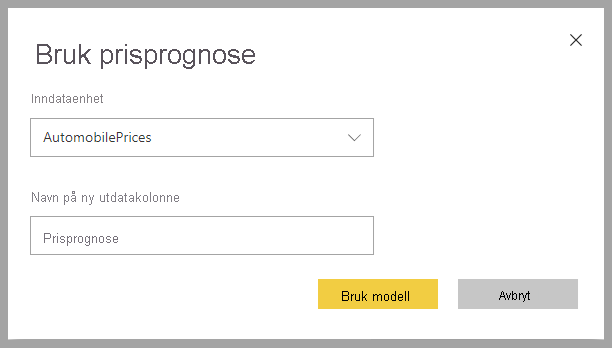
Når en regresjonsmodell brukes, legger den til tre utdatakolonner i den berikede utdatatabellen: RegressionResult, RegressionExplanation og ExplanationIndex. Kolonnenavnene i tabellen har prefikset angitt når modellen brukes.
RegresjonResult-kolonnen inneholder den antatte verdien for raden basert på inndatakolonnene. RegressionExplanation-kolonnen inneholder en forklaring med den spesifikke påvirkningen som inndatafunksjonene hadde på RegressionResult.
Azure Machine Learning-integrering i Power BI
Mange organisasjoner bruker maskinlæringsmodeller for bedre innsikt og prognoser om virksomheten. Du kan bruke maskinlæring med rapporter, instrumentbord og annen analyse for å få denne innsikten. Muligheten til å visualisere og aktivere innsikt fra disse modellene kan bidra til å spre denne innsikten til forretningsbrukerne som trenger det mest. Power BI gjør det nå enkelt å innlemme innsikt fra modeller som driftes på Azure Machine Learning, ved hjelp av enkle pek-og-klikk-bevegelser.
For å bruke denne funksjonen kan en dataforsker gi tilgang til Azure Machine Learning-modellen til BI-analytikeren ved hjelp av Azure-portalen. Deretter oppdager Power Query i begynnelsen av hver økt alle Azure Machine Learning-modellene som brukeren har tilgang til og viser dem som dynamiske Power Query-funksjoner. Brukeren kan deretter aktivere disse funksjonene ved å få tilgang til dem fra båndet i Power Query-redigering, eller ved å aktivere M-funksjonen direkte. Power BI grupperer også automatisk tilgangsforespørslene når du aktiverer Azure Machine Learning-modellen for et sett med rader for å oppnå bedre ytelse.
Denne funksjonaliteten støttes for øyeblikket bare for Power BI-dataflyter og for Power Query på nettet i Power Bi-tjeneste.
Hvis du vil ha mer informasjon om dataflyter, kan du se Innføring i dataflyter og selvbetjent dataforberedelse.
Hvis du vil ha mer informasjon om Azure Machine Learning, kan du se:
- Oversikt: Hva er Azure Machine Learning?
- Hurtigstarter og opplæringer for Azure Machine Learning: Azure Machine Learning Documentation
Gi tilgang til Azure Machine Learning-modellen til en Power BI-bruker
Hvis du vil ha tilgang til en Azure Machine Learning-modell fra Power BI, må brukeren ha lesetilgang til Azure-abonnementet og arbeidsområdet for maskinlæring.
Trinnene i denne artikkelen beskriver hvordan du gir en Power BI-bruker tilgang til en modell som driftes av Azure Machine Learning-tjenesten for å få tilgang til denne modellen som en Power Query-funksjon. Hvis du vil ha mer informasjon, kan du se Tilordne Azure-roller ved hjelp av Azure Portal.
Logg deg på Azure-portalen.
Gå til Abonnementer-siden . Du finner Abonnementer-siden gjennom Alle tjenester-listen i navigasjonsrutemenyen i Azure-portalen.
Velg abonnementet ditt.
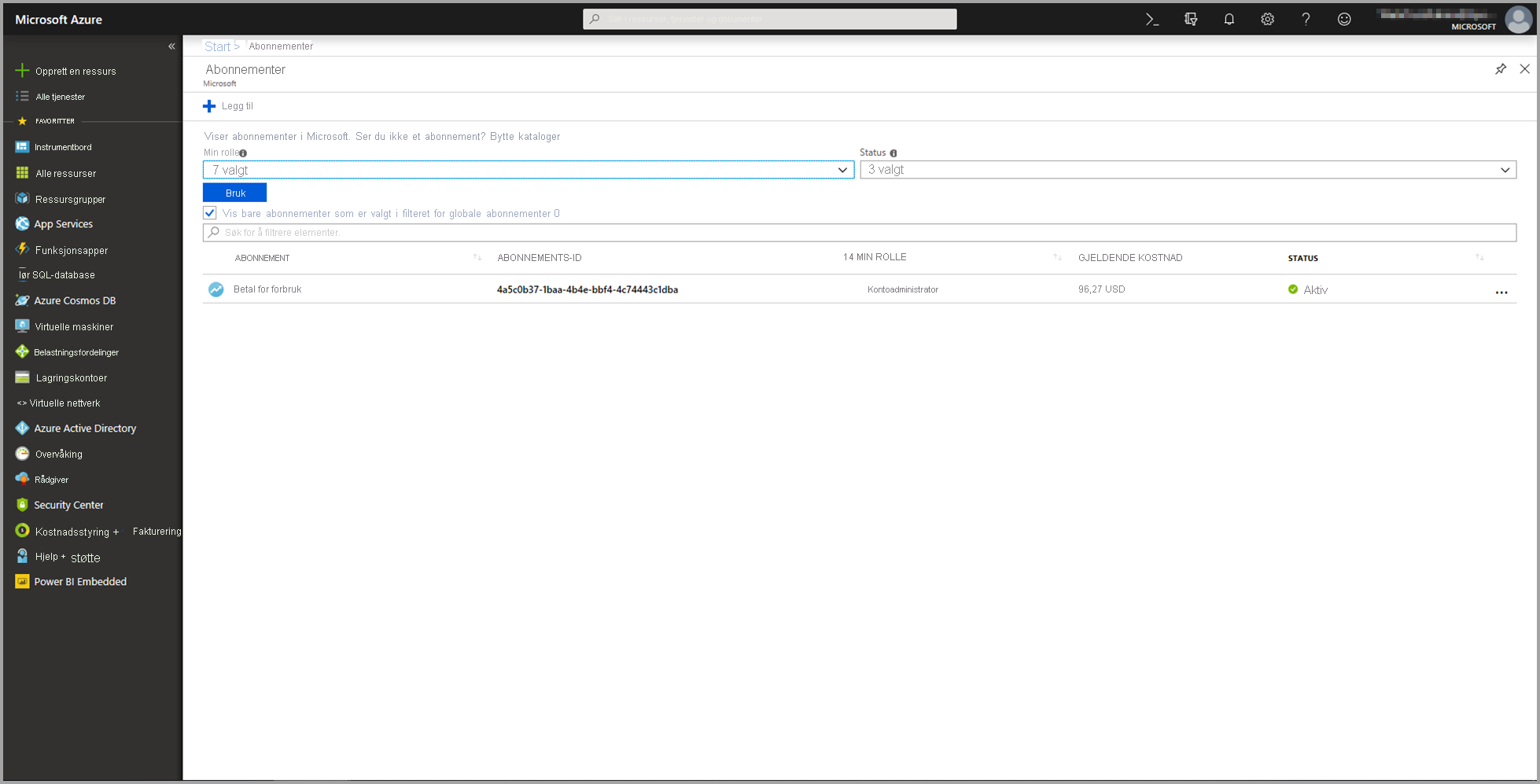
Velg Tilgangskontroll (IAM), og velg deretter Legg til-knappen .
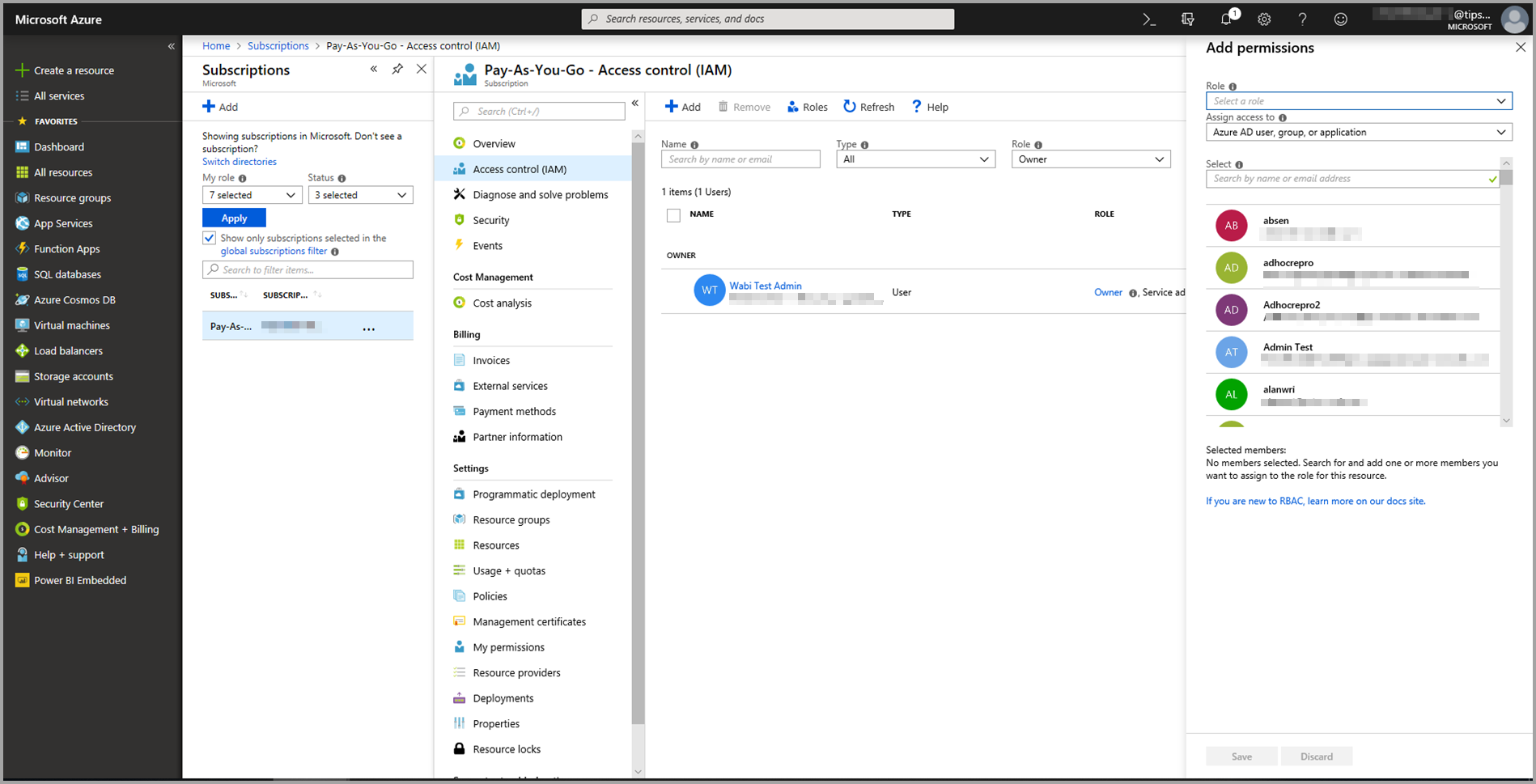
Velg Leser som rolle. Velg deretter Power BI-brukeren du vil gi tilgang til Azure Machine Learning-modellen til.
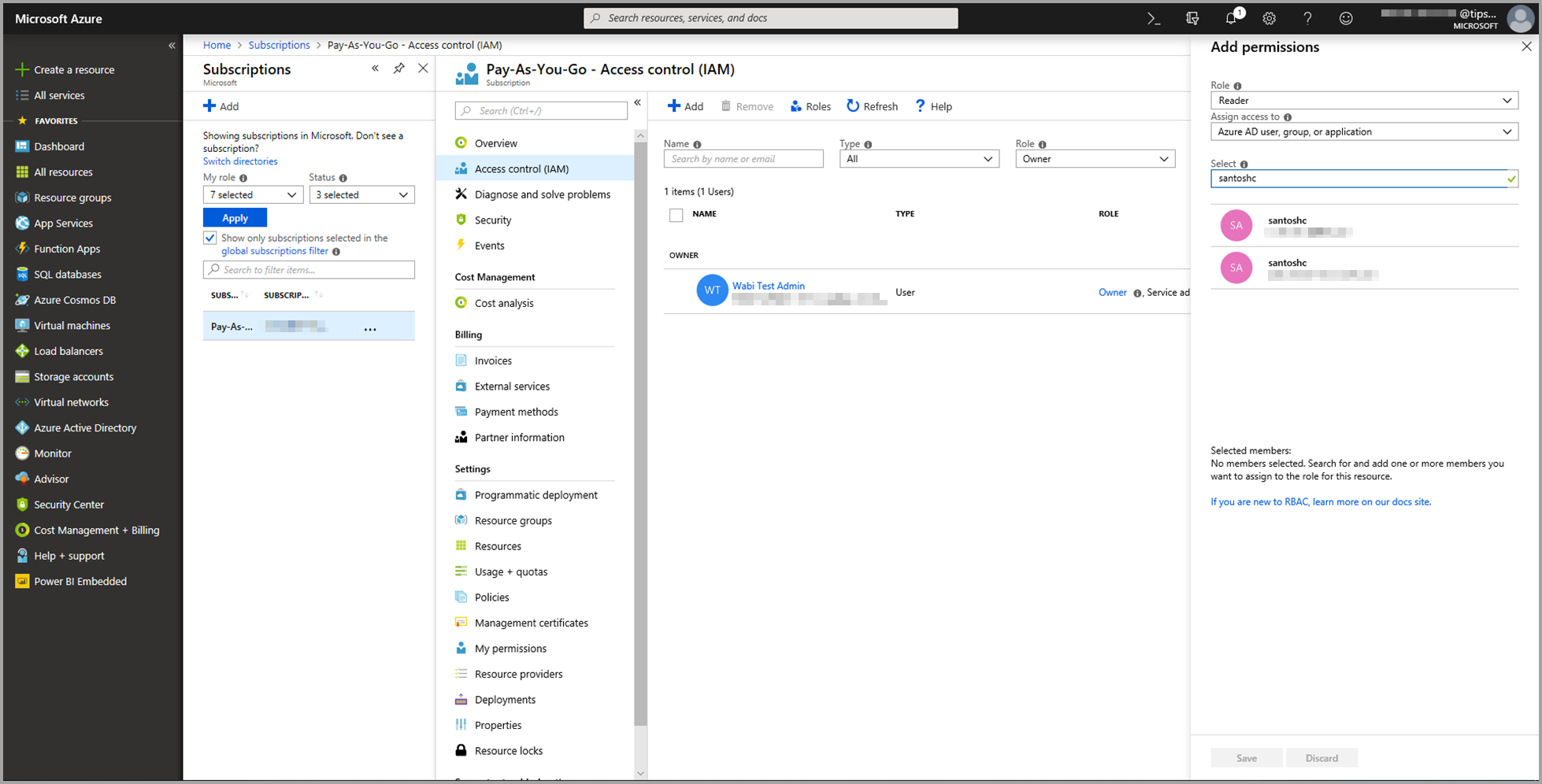
Velg Lagre.
Gjenta trinn tre til seks for å gi Leser tilgang til brukeren for det bestemte arbeidsområdet for maskinlæring som er vert for modellen.




Skjemaoppdagelse for maskinlæringsmodeller
Dataforskere bruker primært Python til å utvikle og til og med distribuere maskinlæringsmodeller for maskinlæring. Dataforskeren må eksplisitt generere skjemafilen ved hjelp av Python.
Denne skjemafilen må være inkludert i den distribuerte nettjenesten for maskinlæringsmodeller. Hvis du vil generere skjemaet for nettjenesten automatisk, må du angi et utvalg av inndata/utdata i oppføringsskriptet for den distribuerte modellen. Hvis du vil ha mer informasjon, kan du se Distribuere og få en maskinlæringsmodell ved hjelp av et nettbasert endepunkt. Koblingen inneholder eksempeloppføringsskriptet med uttrykkene for skjemagenereringen.
Spesielt refererer @input_schema - og @output_schema-funksjonene i oppføringsskriptet til inndata- og utdataeksempelformatene i input_sample og output_sample variabler. Funksjonene bruker disse eksemplene til å generere en OpenAPI-spesifikasjon (Swagger) for nettjenesten under distribusjon.
Disse instruksjonene for skjemagenerering ved å oppdatere oppføringsskriptet må også brukes på modeller som er opprettet ved hjelp av automatiserte maskinlæringseksperimenter med Azure Machine Learning SDK.
Merk
Modeller som er opprettet ved hjelp av azure Machine Learning-visualobjektgrensesnittet, støtter for øyeblikket ikke skjemagenerering, men vil i etterfølgende versjoner.
Aktivere Azure Machine Learning-modellen i Power BI
Du kan aktivere hvilken som helst Azure Machine Learning-modell som du har fått tilgang til, direkte fra Power Query-redigering i dataflyten. Hvis du vil ha tilgang til Azure Machine Learning-modellene, velger du Rediger tabell-knappen for tabellen du vil berike med innsikt fra Azure Machine Learning-modellen, som vist i bildet nedenfor.

Når du velger Rediger tabell-knappen, åpnes Power Query-redigering for tabellene i dataflyten.

Velg Kunstig intelligens-knappen på båndet, og velg deretter mappen Azure Machine Learning Models fra navigasjonsrutemenyen. Alle Azure Machine Learning-modellene du har tilgang til, er oppført her som Power Query-funksjoner. Inndataparameterne for Azure Machine Learning-modellen tilordnes også automatisk som parametere for den tilsvarende Power Query-funksjonen.
Hvis du vil aktivere en Azure Machine Learning-modell, kan du angi en hvilken som helst av kolonnene i den valgte tabellen som inndata fra rullegardinlisten. Du kan også angi en konstant verdi som skal brukes som inndata ved å veksle kolonneikonet til venstre for inndatadialogboksen.

Velg Aktiver for å vise forhåndsvisningen av Azure Machine Learning-modellens utdata som en ny kolonne i tabellen. Modellaktiveringen vises som et brukt trinn for spørringen.

Hvis modellen returnerer flere utdataparametere, grupperes de sammen som en rad i utdatakolonnen. Du kan utvide kolonnen for å produsere individuelle utdataparametere i separate kolonner.

Når du har lagret dataflyten, aktiveres modellen automatisk når dataflyten oppdateres, for eventuelle nye eller oppdaterte rader i tabellen.
Hensyn og begrensninger
- Dataflyter Gen2 integreres for øyeblikket ikke med automatisert maskinlæring.
- AI-innsikt (Cognitive Services og Azure Machine Learning-modeller) støttes ikke på maskiner med konfigurasjon av proxy-godkjenning.
- Azure Machine Learning-modeller støttes ikke for gjestebrukere.
- Det er noen kjente problemer med å bruke Gateway med AutoML og Cognitive Services. Hvis du må bruke en gateway, anbefaler vi at du oppretter en dataflyt som importerer de nødvendige dataene via gatewayen først. Deretter oppretter du en annen dataflyt som refererer til den første dataflyten for å opprette eller bruke disse modellene og AI-funksjonene.
- Hvis AI-en fungerer med dataflyter mislykkes, må du kanskje aktivere Fast Combine når du bruker AI med dataflyter. Når du har importert tabellen og før du begynner å legge til AI-funksjoner, velger du Alternativer fra Hjem-båndet, og i vinduet som vises, merker du av for Tillat å kombinere data fra flere kilder for å aktivere funksjonen, og deretter velger du OK for å lagre det merkede området. Deretter kan du legge til AI-funksjoner i dataflyten.
Relatert innhold
Denne artikkelen ga en oversikt over automatisert maskinlæring for dataflyter i Power Bi-tjeneste. Følgende artikler kan også være nyttige.
Følgende artikler gir mer informasjon om dataflyter og Power BI: