Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Klyngeverdier lager automatisk grupper med lignende verdier ved hjelp av en fuzzy matching-algoritme, og mapper deretter hver kolonnes verdi til den best matchede gruppen. Denne transformasjonen er nyttig når du jobber med data som har mange forskjellige variasjoner av samme verdi, og du må kombinere verdier til konsistente grupper.
Tenk deg en eksempeltabell med en id-kolonne som inneholder et sett med ID-er og en Person-kolonne som inneholder ulike stavede og store bokstaver av navnene Miguel, Mike, William og Bill.
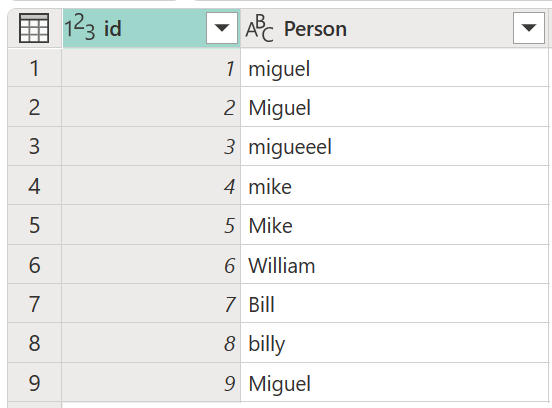
I dette eksempelet er resultatet du ser etter en tabell med en ny kolonne som viser de riktige gruppene av verdier fra Person-kolonnen , og ikke alle de forskjellige variantene av de samme ordene.
Note
Funksjonen Cluster-verdier er kun tilgjengelig for Power Query Online.
Opprett en Klyngekolonne
For å klynge verdier, velg først Person-kolonnen , gå til Legg-til-kolonne-fanen i båndet, og velg deretter Klyngeverdier-alternativet .
![]()
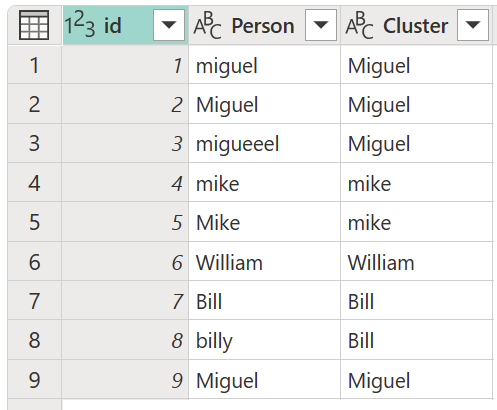
I dialogboksen for Klyngeverdier , bekreft kolonnen du vil bruke for å opprette klyngene fra, og skriv inn det nye navnet på kolonnen. For dette tilfellet, kall denne nye kolonnen Klynge.
Resultatet av denne operasjonen vises i bildet nedenfor.
Note
For hver klynge av verdier velger Power Query den hyppigste instansen fra den valgte kolonnen som den "kanoniske" instansen. Hvis flere tilfeller skjer med samme hyppighet, velger Power Query den første.
Bruk av fuzzy cluster-innstillingene
Følgende alternativer er tilgjengelige for å klynge verdier i en ny kolonne:
- Likhetsterskel (valgfritt): Dette alternativet indikerer hvor like to verdier må være for å grupperes sammen. Minimumsinnstillingen null (0) gjør at alle verdier grupperes sammen. Maksimal innstilling på 1 tillater kun at verdier som matcher nøyaktig kan grupperes sammen. Standard er 0,8.
- Ignorer kasus: Når tekststrenger sammenlignes, ignoreres kasus. Dette alternativet er aktivert som standard.
- Grupper ved å kombinere tekstdeler: Algoritmen prøver å kombinere tekstdeler (for eksempel å kombinere Micro og soft i Microsoft) for å gruppere verdier.
- Vis likhetsscorer: Viser likhetsscore mellom inputverdiene og beregnede representative verdier etter fuzzy clustering.
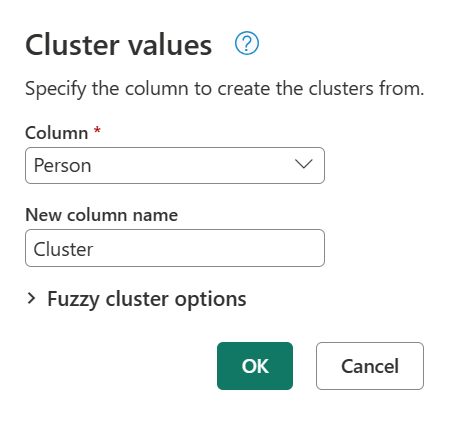
- Transformasjonstabell (valgfritt): Du kan velge en transformasjonstabell som kartlegger verdier (for eksempel mapping MSFT til Microsoft) for å gruppere dem sammen.
For dette eksempelet brukes en ny transformasjonstabell med navnet Min transformasjonstabell for å demonstrere hvordan verdier kan mappes. Denne transformasjonstabellen har to kolonner:
- Fra: Tekststrengen du skal se etter i tabellen din.
- Til: Tekststrengen som skal brukes til å erstatte tekststrengen i From-kolonnen .

Viktig!
Det er viktig at transformasjonstabellen har de samme kolonnene og kolonnenavnene som vist i forrige bilde (de må hete "Fra" og "Til"), ellers vil ikke Power Query gjenkjenne denne tabellen som en transformasjonstabell, og ingen transformasjon vil finne sted.
Ved å bruke den tidligere opprettede spørringen, dobbeltklikk på steget Clustered values, og utnytt deretter Fuzzy cluster-alternativer i dialogboksen Cluster-verdier. Under fuzzy cluster-alternativer, aktiver alternativet Vis likhetsscorer . For transformasjonstabellen (valgfritt), velg spørringen som har transformasjonstabellen.
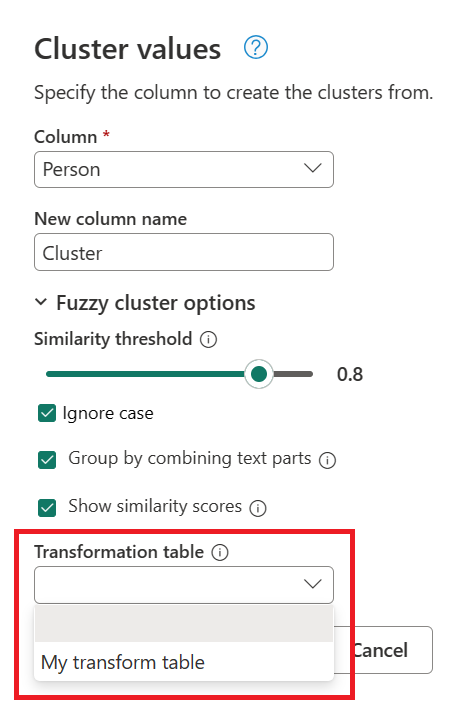
Etter å ha valgt transformasjonstabellen og aktivert Vis likhetsscore-alternativet, velg OK. Resultatet av den operasjonen gir deg en tabell som inneholder samme id- og Person-kolonner som den opprinnelige tabellen, men som også inkluderer to nye kolonner kalt Cluster og Person_Cluster_Similarity. Cluster-kolonnen inneholder de korrekt stavede og store bokstavene av navnene Miguel for versjoner av Miguel og Mike, og William for versjoner av Bill, Billy og William. Kolonnen Person_Cluster_Similarity inneholder likhetspoengene for hvert av navnene.

Transformasjonstabellforskrifter
Du vil kanskje legge merke til at transformasjonstabellen i forrige seksjon så ut til å indikere at forekomster av Mike er endret til Miguel, og forekomster av William er endret til Bill. I den resulterende tabellen ble imidlertid forekomstene av Bill og "billy" i stedet endret til William. I transformasjonstabellen, i stedet for å være en direkte Fra til Til-sti, er transformasjonstabellen symmetrisk under klynging, noe som betyr at "mike" tilsvarer "Miguel" og omvendt. Resultatet av ekvivalentene gitt i transformasjonstabellen avhenger av følgende regler:
- Hvis det er flertall av identiske verdier, har disse verdiene forrang over ikke-identiske verdier.
- Hvis det ikke finnes flertall av verdier, får verdien som vises først forrang.
For eksempel, i den opprinnelige tabellen brukt i denne artikkelen, utgjør versjoner av Miguel (både "miguel" og Miguel) i Person-kolonnen flertallet av forekomstene av navnene Miguel og Mike. I tillegg utgjør navnet Miguel med initialer hovedbokstaver hoveddelen av navnet Miguel. Så ved å assosiere Miguel og dets deriverte og Mike og dets deriverte i transformasjonstabellen brukes navnet Miguel i Cluster-kolonnen .
Men for navnene William, Bill og "billy" finnes det ikke flertall av verdier siden alle tre er unike. Siden William dukker opp først, brukes William i kolonnen Cluster . Hvis "billy" hadde stått først i tabellen, ville "billy" blitt brukt i kolonnen Cluster . Dessuten, fordi det ikke finnes flertall av verdier, brukes kasuset som brukes av de individuelle navnene. Det vil si, hvis William er først, brukes William med stor "W" som resultatverdi; Hvis "Billy" er først, brukes "Billy" med liten "B".