Parquet-indeling in Azure Data Factory en Azure Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Volg dit artikel als u de Parquet-bestanden wilt parseren of de gegevens naar parquet-indeling wilt schrijven.
Parquet-indeling wordt ondersteund voor de volgende connectors:
- Amazon S3
- Amazon S3-compatibele opslag
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Bestandssysteem
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Ga naar het artikel Overzicht van connectors voor een lijst met ondersteunde functies voor alle beschikbare connectors.
Zelf-hostende Integration Runtime gebruiken
Belangrijk
Voor kopie die mogelijk is door zelf-hostende Integration Runtime, bijvoorbeeld tussen on-premises en cloudgegevensarchieven, moet u de 64-bits JRE 8 (Java Runtime Environment) of OpenJDK op uw IR-computer installeren als u parquet-bestanden niet naar behoren kopieert. Controleer de volgende alinea met meer informatie.
Voor kopiëren die wordt uitgevoerd op zelf-hostende IR met Parquet-bestandsserialisatie/deserialisatie, zoekt de service de Java-runtime door eerst het register (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) voor JRE te controleren, indien niet gevonden, ten tweede de systeemvariabele JAVA_HOME voor OpenJDK te controleren.
- Jre gebruiken: voor de 64-bits IR is 64-bits JRE vereist. U vindt het hier.
- OpenJDK gebruiken: dit wordt ondersteund sinds IR versie 3.13. Pak de jvm.dll in met alle andere vereiste assembly's van OpenJDK in een zelf-hostende IR-computer en stel de omgevingsvariabele van het systeem in JAVA_HOME dienovereenkomstig en start vervolgens zelf-hostende IR opnieuw op om onmiddellijk van kracht te worden.
Tip
Als u gegevens kopieert naar/van Parquet-indeling met behulp van zelf-hostende Integration Runtime en de fout 'Er is een fout opgetreden bij het aanroepen van Java, bericht: java.lang.OutOfMemoryError:Java heap space', kunt u een omgevingsvariabele _JAVA_OPTIONS toevoegen op de computer waarop de zelf-hostende IR wordt gehost om de minimale/maximale heapgrootte voor JVM aan te passen om dergelijke kopie mogelijk te maken en de pijplijn opnieuw uit te voeren.
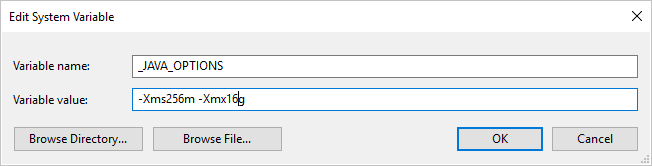
Voorbeeld: variabele _JAVA_OPTIONS instellen met waarde -Xms256m -Xmx16g. De vlag Xms geeft de eerste geheugentoewijzingsgroep voor een Java Virtual Machine (JVM) op, terwijl Xmx de maximale geheugentoewijzingsgroep wordt opgegeven. Dit betekent dat JVM wordt gestart met Xms een hoeveelheid geheugen en een maximale Xmx hoeveelheid geheugen kan gebruiken. De service gebruikt standaard min. 64 MB en maximaal 1G.
Eigenschappen van gegevensset
Zie het artikel Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets . Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Parquet-gegevensset.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op Parquet. | Ja |
| locatie | Locatie-instellingen van de bestanden. Elke op bestanden gebaseerde connector heeft een eigen locatietype en ondersteunde eigenschappen onder location. Zie de details in het connectorartikel -> sectie Eigenschappen van gegevensset. |
Ja |
| compressionCodec | De compressiecodec die moet worden gebruikt bij het schrijven naar Parquet-bestanden. Bij het lezen van Parquet-bestanden bepalen Data Factory's automatisch de compressiecodec op basis van de metagegevens van het bestand. Ondersteunde typen zijn 'none', 'gzip', 'snappy' (standaard) en 'lzo'. Opmerking momenteel Copy-activiteit LZO niet ondersteunt bij het lezen/schrijven van Parquet-bestanden. |
Nr. |
Notitie
Witruimte in kolomnaam wordt niet ondersteund voor Parquet-bestanden.
Hieronder ziet u een voorbeeld van een Parquet-gegevensset in Azure Blob Storage:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Parquet-bron en -sink.
Parquet als bron
De volgende eigenschappen worden ondersteund in de sectie kopieeractiviteit *source* .
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op ParquetSource. | Ja |
| storeSettings | Een groep eigenschappen over het lezen van gegevens uit een gegevensarchief. Elke op bestanden gebaseerde connector heeft zijn eigen ondersteunde leesinstellingen onder storeSettings. Zie de details in het connectorartikel -> sectie Copy-activiteit eigenschappen. |
Nee |
Parquet als sink
De volgende eigenschappen worden ondersteund in de sectie kopieeractiviteit *sink* .
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de sink van de kopieeractiviteit moet worden ingesteld op ParquetSink. | Ja |
| formatSettings | Een groep eigenschappen. Raadpleeg de onderstaande tabel met schrijfinstellingen voor Parquet. | Nee |
| storeSettings | Een groep eigenschappen over het schrijven van gegevens naar een gegevensarchief. Elke op bestanden gebaseerde connector heeft zijn eigen ondersteunde schrijfinstellingen onder storeSettings. Zie de details in het connectorartikel -> sectie Copy-activiteit eigenschappen. |
Nee |
Ondersteunde Parquet-schrijfinstellingen onder formatSettings:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | Het type formatSettings moet worden ingesteld op ParquetWriteSettings. | Ja |
| maxRowsPerFile | Wanneer u gegevens in een map schrijft, kunt u ervoor kiezen om naar meerdere bestanden te schrijven en de maximumrijen per bestand op te geven. | Nee |
| fileNamePrefix | Van toepassing wanneer maxRowsPerFile deze is geconfigureerd.Geef het voorvoegsel voor de bestandsnaam op bij het schrijven van gegevens naar meerdere bestanden, wat resulteert in dit patroon: <fileNamePrefix>_00000.<fileExtension> Als dit niet is opgegeven, wordt het voorvoegsel van de bestandsnaam automatisch gegenereerd. Deze eigenschap is niet van toepassing wanneer de bron een op bestanden gebaseerd archief of gegevensarchief met partitieopties is. |
Nee |
Eigenschappen van toewijzingsgegevensstroom
In toewijzingsgegevensstromen kunt u de parquet-indeling lezen en schrijven in de volgende gegevensarchieven: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 en SFTP, en u kunt de parquet-indeling lezen in Amazon S3.
Broneigenschappen
De onderstaande tabel bevat de eigenschappen die worden ondersteund door een parquet-bron. U kunt deze eigenschappen bewerken op het tabblad Bronopties .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Notatie | Notatie moet zijn parquet |
ja | parquet |
indeling |
| Paden met jokertekens | Alle bestanden die overeenkomen met het jokertekenpad worden verwerkt. Hiermee overschrijft u de map en het bestandspad dat is ingesteld in de gegevensset. | nee | Tekenreeks[] | jokertekenpaden |
| Hoofdpad voor partitie | Voor bestandsgegevens die zijn gepartitioneerd, kunt u een partitiehoofdpad invoeren om gepartitioneerde mappen als kolommen te lezen | nee | String | partitionRootPath |
| Lijst met bestanden | Of uw bron verwijst naar een tekstbestand waarin bestanden worden vermeld die moeten worden verwerkt | nee | true of false |
fileList |
| Kolom voor het opslaan van de bestandsnaam | Een nieuwe kolom maken met de naam en het pad van het bronbestand | nee | String | rowUrlColumn |
| Na voltooiing | Verwijder of verplaats de bestanden na verwerking. Bestandspad begint vanuit de hoofdmap van de container | nee | Verwijderen: true of false Bewegen: [<from>, <to>] |
purgeFiles moveFiles |
| Filteren op laatst gewijzigd | Kiezen om bestanden te filteren op basis van wanneer ze voor het laatst zijn gewijzigd | nee | Tijdstempel | modifiedAfter modifiedBefore |
| Geen bestanden gevonden toestaan | Indien waar, wordt er geen fout gegenereerd als er geen bestanden worden gevonden | nee | true of false |
ignoreNoFilesFound |
Bronvoorbeeld
De onderstaande afbeelding is een voorbeeld van een parquet-bronconfiguratie in toewijzingsgegevensstromen.

Het gekoppelde gegevensstroomscript is:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Sink-eigenschappen
De onderstaande tabel bevat de eigenschappen die worden ondersteund door een parquet-sink. U kunt deze eigenschappen bewerken op het tabblad Instellingen .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Notatie | Notatie moet zijn parquet |
ja | parquet |
indeling |
| Ga naar de map | Als de doelmap is gewist voordat u gaat schrijven | nee | true of false |
truncate |
| Optie voor bestandsnaam | De naamgevingsindeling van de geschreven gegevens. Standaard één bestand per partitie in indeling part-#####-tid-<guid> |
nee | Patroon: Tekenreeks Per partitie: Tekenreeks[] Als gegevens in kolom: Tekenreeks Uitvoer naar één bestand: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Sink-voorbeeld
De onderstaande afbeelding is een voorbeeld van een parquet sink-configuratie in toewijzingsgegevensstromen.

Het gekoppelde gegevensstroomscript is:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Ondersteuning voor gegevenstypen
Parquet-complexe gegevenstypen (bijvoorbeeld MAP, LIST, STRUCT) worden momenteel alleen ondersteund in Gegevensstroom s, niet in kopieeractiviteit. Als u complexe typen in gegevensstromen wilt gebruiken, importeert u het bestandsschema niet in de gegevensset, waardoor het schema leeg blijft in de gegevensset. Importeer vervolgens de projectie in de brontransformatie.