Gegevens kopiëren en transformeren in Azure Data Lake Storage Gen2 met behulp van Azure Data Factory of Azure Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Azure Data Lake Storage Gen2 (ADLS Gen2) is een set mogelijkheden die is toegewezen aan big data-analyses die zijn ingebouwd in Azure Blob Storage. U kunt het gebruiken om interactie met uw gegevens te maken met behulp van paradigma's voor zowel het bestandssysteem als de objectopslag.
In dit artikel wordt beschreven hoe u kopieeractiviteit gebruikt om gegevens van en naar Azure Data Lake Storage Gen2 te kopiëren en Gegevensstroom te gebruiken om gegevens te transformeren in Azure Data Lake Storage Gen2. Lees het inleidende artikel voor Azure Data Factory of Azure Synapse Analytics voor meer informatie.
Tip
Voor data lake- of datawarehouse-migratiescenario's vindt u meer informatie in Gegevens migreren van uw data lake of datawarehouse naar Azure.
Ondersteunde mogelijkheden
Deze Azure Data Lake Storage Gen2-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR | Beheerd privé-eindpunt |
|---|---|---|
| Copy-activiteit (bron/sink) | (1) (2) | ✓ |
| Toewijzingsgegevensstroom (bron/sink) | (1) | ✓ |
| Activiteit Lookup | (1) (2) | ✓ |
| GetMetadata-activiteit | (1) (2) | ✓ |
| Activiteit verwijderen | (1) (2) | ✓ |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Voor Copy-activiteit kunt u met deze connector het volgende doen:
- Kopieer gegevens van/naar Azure Data Lake Storage Gen2 met behulp van accountsleutel, service-principal of beheerde identiteiten voor Verificaties van Azure-resources.
- Kopieer bestanden als zodanig of parseert of genereert bestanden met ondersteunde bestandsindelingen en compressiecodecs.
- Bewaar bestandsmetagegevens tijdens het kopiëren.
- ACL's behouden bij het kopiëren vanuit Azure Data Lake Storage Gen1/Gen2.
Aan de slag
Tip
Zie Gegevens laden in Azure Data Lake Storage Gen2 voor een overzicht van het gebruik van de Data Lake Storage Gen2-connector.
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde Azure Data Lake Storage Gen2-service maken met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde Azure Data Lake Storage Gen2-service te maken in de gebruikersinterface van Azure Portal.
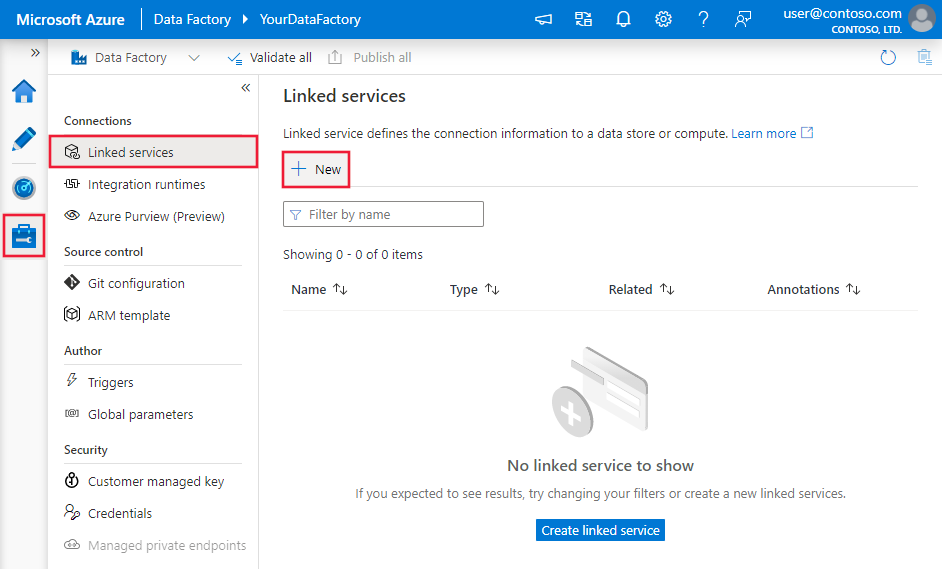
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Azure Data Lake Storage Gen2 en selecteer de Azure Data Lake Storage Gen2-connector.

Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
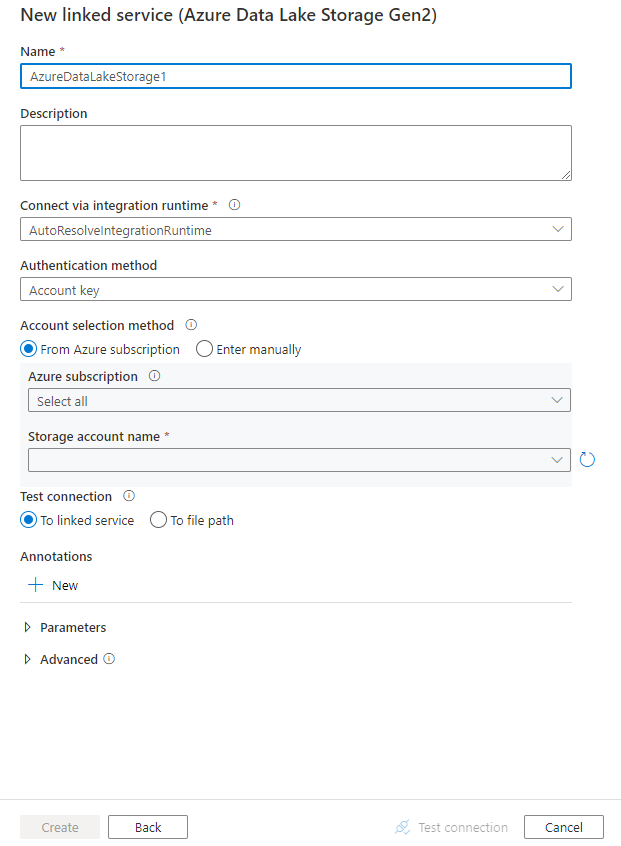
Configuratiedetails van connector
De volgende secties bevatten informatie over eigenschappen die worden gebruikt voor het definiëren van Data Factory- en Synapse-pijplijnentiteiten die specifiek zijn voor Data Lake Storage Gen2.
Eigenschappen van gekoppelde service
De Azure Data Lake Storage Gen2-connector ondersteunt de volgende verificatietypen. Zie de bijbehorende secties voor meer informatie:
- Verificatie van accountsleutels
- Shared Access Signature Authentication
- Verificatie van service-principal
- Door het systeem toegewezen beheerde identiteitverificatie
- Door de gebruiker toegewezen beheerde identiteitverificatie
Notitie
- Als u de openbare Azure Integration Runtime wilt gebruiken om verbinding te maken met Data Lake Storage Gen2 door gebruik te maken van de optie Vertrouwde Microsoft-services toegang geven tot deze optie voor het opslagaccount die is ingeschakeld op de Azure Storage-firewall, moet u verificatie van beheerde identiteiten gebruiken. Zie Azure Storage-firewalls en virtuele netwerken configureren voor meer informatie over de instellingen voor Azure Storage-firewalls.
- Wanneer u de PolyBase- of COPY-instructie gebruikt om gegevens te laden in Azure Synapse Analytics, moet u, als uw bron of fasering Data Lake Storage Gen2 is geconfigureerd met een Azure Virtual Network-eindpunt, beheerde identiteitsverificatie gebruiken zoals vereist door Azure Synapse. Zie de sectie verificatie van beheerde identiteiten met meer configuratievereisten.
Verificatie van accountsleutels
Voor het gebruik van verificatie van opslagaccountsleutels worden de volgende eigenschappen ondersteund:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureBlobFS. | Ja |
| URL | Eindpunt voor Data Lake Storage Gen2 met het patroon .https://<accountname>.dfs.core.windows.net |
Ja |
| accountKey | Accountsleutel voor Data Lake Storage Gen2. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als deze eigenschap niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nr. |
Notitie
Het eindpunt van het secundaire ADLS-bestandssysteem wordt niet ondersteund bij het gebruik van verificatie van accountsleutels. U kunt andere verificatietypen gebruiken.
Voorbeeld:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"accountkey": {
"type": "SecureString",
"value": "<accountkey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Shared Access Signature Authentication
Een SAS (een handtekening voor gedeelde toegang) biedt gedelegeerde toegang tot resources in uw opslagaccount. U kunt een handtekening voor gedeelde toegang gebruiken om een client gedurende een opgegeven tijd beperkte machtigingen te verlenen aan objecten in uw opslagaccount.
U hoeft uw accounttoegangssleutels niet te delen. De handtekening voor gedeelde toegang is een URI die in de queryparameters alle informatie omvat die nodig is voor geverifieerde toegang tot een opslagresource. Voor toegang tot opslagbronnen met de handtekening voor gedeelde toegang hoeft de client alleen de handtekening voor gedeelde toegang door te geven aan de juiste constructor of methode.
Zie Handtekeningen voor gedeelde toegang voor meer informatie over handtekeningen voor gedeelde toegang : Inzicht in het shared access signature-model.
Notitie
- De service ondersteunt nu handtekeningen voor gedeelde toegang en handtekeningen voor gedeelde toegang voor accounts. Zie Beperkte toegang verlenen tot Azure Storage-resources met behulp van handtekeningen voor gedeelde toegang voor meer informatie over handtekeningen voor gedeelde toegang.
- In latere gegevenssetconfiguraties is het mappad het absolute pad dat begint vanaf het containerniveau. U moet er een configureren die is afgestemd op het pad in uw SAS-URI.
De volgende eigenschappen worden ondersteund voor het gebruik van shared access Signature-verificatie:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De type eigenschap moet worden ingesteld op AzureBlobFS (voorgesteld) |
Ja |
| sasUri | Geef de handtekening-URI voor gedeelde toegang op voor de opslagbronnen, zoals blob of container. Markeer dit veld om SecureString het veilig op te slaan. U kunt het SAS-token ook in Azure Key Vault plaatsen om automatisch draaien te gebruiken en het tokengedeelte te verwijderen. Zie de volgende voorbeelden en sla referenties op in Azure Key Vault voor meer informatie. |
Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of de zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een privénetwerk bevindt). Als deze eigenschap niet is opgegeven, gebruikt de service de standaard Azure Integration Runtime. | Nr. |
Notitie
Als u het AzureStorage type gekoppelde service gebruikt, wordt deze nog steeds ondersteund. Maar we raden u aan om het nieuwe AzureDataLakeStorageGen2 gekoppelde servicetype in de toekomst te gebruiken.
Voorbeeld:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld: de accountsleutel opslaan in Azure Key Vault
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Houd rekening met de volgende punten wanneer u een handtekening-URI voor gedeelde toegang maakt:
- Stel de juiste lees-/schrijfmachtigingen in voor objecten op basis van de manier waarop de gekoppelde service (lezen, schrijven, lezen/schrijven) wordt gebruikt.
- Stel de verlooptijd op de juiste wijze in. Zorg ervoor dat de toegang tot Opslagobjecten niet verloopt binnen de actieve periode van de pijplijn.
- De URI moet worden gemaakt in de juiste container of blob op basis van de behoefte. Met een handtekening-URI voor gedeelde toegang voor een blob heeft de data factory of Synapse-pijplijn toegang tot die specifieke blob. Met een handtekening-URI voor gedeelde toegang naar een Blob Storage-container kan de Data Factory- of Synapse-pijplijn doorlopen via blobs in die container. Als u later toegang wilt geven tot meer of minder objecten of als u de handtekening-URI voor gedeelde toegang wilt bijwerken, moet u de gekoppelde service bijwerken met de nieuwe URI.
Verificatie van service-principal
Volg deze stappen om verificatie van de service-principal te gebruiken.
Een toepassing registreren bij het Microsoft-identiteitsplatform. Zie quickstart: Een toepassing registreren bij het Microsoft Identity Platform voor meer informatie. Noteer deze waarden, die u gebruikt om de gekoppelde service te definiëren:
- Toepassings-id
- Toepassingssleutel
- Tenant-id
Verdeel de juiste machtiging voor de service-principal. Bekijk voorbeelden van hoe machtigingen werken in Data Lake Storage Gen2 vanuit toegangsbeheerlijsten voor bestanden en mappen
- Als bron: verleen in Storage Explorer minimaal de machtiging Uitvoeren voor ALLE upstream-mappen en het bestandssysteem, in combinatie met de machtiging Lezen voor de bestanden die u wilt kopiëren. Als alternatief kunt u in Toegangsbeheer (IAM) ook minimaal de rol Storage-blobgegevenslezer verlenen.
- Als sink: verleen in Storage Explorer minimaal de machtiging Uitvoeren voor ALLE upstream-mappen en het bestandssysteem, in combinatie met de machtiging Schrijven voor de sink-map. Als alternatief kunt u in Toegangsbeheer (IAM) ook minimaal de rol Storage-blobgegevensinzender verlenen.
Notitie
Als u de gebruikersinterface gebruikt om te schrijven en de service-principal niet is ingesteld met de rol Storage Blob Data Reader/Inzender in IAM, kiest u bij het testen van de verbinding of bladeren/navigeren in mappen de optie 'Verbinding met bestandspad testen' of 'Bladeren vanaf opgegeven pad' en geeft u een pad op met de machtiging Lezen en Uitvoeren om door te gaan.
Deze eigenschappen worden ondersteund voor de gekoppelde service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureBlobFS. | Ja |
| URL | Eindpunt voor Data Lake Storage Gen2 met het patroon .https://<accountname>.dfs.core.windows.net |
Ja |
| servicePrincipalId | Geef de client-id van de toepassing op. | Ja |
| servicePrincipalCredentialType | Het referentietype dat moet worden gebruikt voor verificatie van de service-principal. Toegestane waarden zijn ServicePrincipalKey en ServicePrincipalCert. | Ja |
| servicePrincipalCredential | De referenties van de service-principal. Wanneer u ServicePrincipalKey als referentietype gebruikt, geeft u de sleutel van de toepassing op. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. Wanneer u ServicePrincipalCert als referentie gebruikt, verwijst u naar een certificaat in Azure Key Vault en zorgt u ervoor dat het certificaatinhoudstype PKCS #12 is. |
Ja |
| servicePrincipalKey | Geef de sleutel van de toepassing op. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. Deze eigenschap wordt nog steeds ondersteund voor servicePrincipalId + servicePrincipalKey. Omdat ADF nieuwe certificaatverificatie voor service-principals toevoegt, is servicePrincipalId + + servicePrincipalCredentialTypeservicePrincipalCredentialhet nieuwe model voor verificatie van de service-principal. |
Nee |
| AD-tenant | Geef de tenantgegevens (domeinnaam of tenant-id) op waaronder uw toepassing zich bevindt. Haal deze op door de muis in de rechterbovenhoek van Azure Portal te bewegen. | Ja |
| azureCloudType | Geef voor service-principalverificatie het type Azure-cloudomgeving op waarnaar uw Microsoft Entra-toepassing is geregistreerd. Toegestane waarden zijn AzurePublic, AzureChina, AzureUsGovernment en AzureGermany. Standaard wordt de cloudomgeving van de data factory of Synapse-pijplijn gebruikt. |
Nee |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld: verificatie van de service-principalsleutel gebruiken
U kunt ook een service-principalsleutel opslaan in Azure Key Vault.
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld: verificatie van service-principalcertificaten gebruiken
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Door het systeem toegewezen beheerde identiteitverificatie
Een data factory of Synapse-werkruimte kan worden gekoppeld aan een door het systeem toegewezen beheerde identiteit. U kunt deze door het systeem toegewezen beheerde identiteit rechtstreeks gebruiken voor Data Lake Storage Gen2-verificatie, vergelijkbaar met het gebruik van uw eigen service-principal. Hiermee kan deze aangewezen factory of werkruimte gegevens openen en kopiëren naar of van uw Data Lake Storage Gen2.
Volg deze stappen om door het systeem toegewezen beheerde identiteitverificatie te gebruiken.
Haal de door het systeem toegewezen beheerde identiteitsgegevens op door de waarde van de object-id van de beheerde identiteit te kopiëren die samen met uw data factory of Synapse-werkruimte is gegenereerd.
Verwijs de door het systeem toegewezen beheerde identiteit de juiste machtiging. Zie voorbeelden van de werking van machtigingen in Data Lake Storage Gen2 vanuit toegangsbeheerlijsten voor bestanden en mappen.
- Als bron: verleen in Storage Explorer minimaal de machtiging Uitvoeren voor ALLE upstream-mappen en het bestandssysteem, in combinatie met de machtiging Lezen voor de bestanden die u wilt kopiëren. Als alternatief kunt u in Toegangsbeheer (IAM) ook minimaal de rol Storage-blobgegevenslezer verlenen.
- Als sink: verleen in Storage Explorer minimaal de machtiging Uitvoeren voor ALLE upstream-mappen en het bestandssysteem, in combinatie met de machtiging Schrijven voor de sink-map. Als alternatief kunt u in Toegangsbeheer (IAM) ook minimaal de rol Storage-blobgegevensinzender verlenen.
Deze eigenschappen worden ondersteund voor de gekoppelde service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureBlobFS. | Ja |
| URL | Eindpunt voor Data Lake Storage Gen2 met het patroon .https://<accountname>.dfs.core.windows.net |
Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Door de gebruiker toegewezen beheerde identiteitverificatie
Een data factory kan worden toegewezen met een of meerdere door de gebruiker toegewezen beheerde identiteiten. U kunt deze door de gebruiker toegewezen beheerde identiteit gebruiken voor Blob Storage-verificatie, waarmee u gegevens kunt openen en kopiëren van of naar Data Lake Storage Gen2. Zie Beheerde identiteiten voor Azure-resources voor meer informatie over beheerde identiteiten voor Azure-resources
Volg deze stappen om door de gebruiker toegewezen beheerde identiteitverificatie te gebruiken:
Maak een of meerdere door de gebruiker toegewezen beheerde identiteiten en verwijs toegang tot Azure Data Lake Storage Gen2. Zie voorbeelden van de werking van machtigingen in Data Lake Storage Gen2 vanuit toegangsbeheerlijsten voor bestanden en mappen.
- Als bron: verleen in Storage Explorer minimaal de machtiging Uitvoeren voor ALLE upstream-mappen en het bestandssysteem, in combinatie met de machtiging Lezen voor de bestanden die u wilt kopiëren. Als alternatief kunt u in Toegangsbeheer (IAM) ook minimaal de rol Storage-blobgegevenslezer verlenen.
- Als sink: verleen in Storage Explorer minimaal de machtiging Uitvoeren voor ALLE upstream-mappen en het bestandssysteem, in combinatie met de machtiging Schrijven voor de sink-map. Als alternatief kunt u in Toegangsbeheer (IAM) ook minimaal de rol Storage-blobgegevensinzender verlenen.
Wijs een of meerdere door de gebruiker toegewezen beheerde identiteiten toe aan uw data factory en maak referenties voor elke door de gebruiker toegewezen beheerde identiteit.
Deze eigenschappen worden ondersteund voor de gekoppelde service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureBlobFS. | Ja |
| URL | Eindpunt voor Data Lake Storage Gen2 met het patroon .https://<accountname>.dfs.core.windows.net |
Ja |
| aanmeldingsgegevens | Geef de door de gebruiker toegewezen beheerde identiteit op als referentieobject. | Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Notitie
Als u de Data Factory-gebruikersinterface gebruikt om te schrijven en de beheerde identiteit niet is ingesteld met de rol Storage Blob Data Reader/Inzender in IAM, kiest u bij het testen van de verbinding of bladeren/navigeren in mappen de optie Verbinding met bestandspad testen of Bladeren vanaf opgegeven pad en geeft u een pad op met de machtiging Lezen en Uitvoeren om door te gaan.
Belangrijk
Als u de PolyBase- of COPY-instructie gebruikt om gegevens uit Data Lake Storage Gen2 te laden in Azure Synapse Analytics, moet u bij het gebruik van beheerde identiteitsverificatie voor Data Lake Storage Gen2 ook stap 1 tot en met 3 in deze richtlijnen volgen. Met deze stappen wordt uw server geregistreerd bij Microsoft Entra ID en wordt de rol Inzender voor opslagblobgegevens toegewezen aan uw server. Data Factory verwerkt de rest. Als u Blob Storage configureert met een Azure Virtual Network-eindpunt, moet u ook vertrouwde Microsoft-services toegang hebben tot dit opslagaccount dat is ingeschakeld onder het menu Firewalls van azure Storage-accounts en instellingen voor virtuele netwerken, zoals vereist door Azure Synapse.
Eigenschappen van gegevensset
Azure Data Factory ondersteunt de volgende bestandsindelingen. Raadpleeg elk artikel voor op indeling gebaseerde instellingen.
- Avro-indeling
- Binaire indeling
- Tekstindeling met scheidingstekens
- Excel-indeling
- JSON-indeling
- ORC-indeling
- Parquet-indeling
- XML-indeling
De volgende eigenschappen worden ondersteund voor Data Lake Storage Gen2 onder location instellingen in de op indeling gebaseerde gegevensset:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap onder location in de gegevensset moet worden ingesteld op AzureBlobFSLocation. |
Ja |
| bestandssysteem | De naam van het Data Lake Storage Gen2-bestandssysteem. | Nee |
| folderPath | Het pad naar een map onder het opgegeven bestandssysteem. Als u een jokerteken wilt gebruiken om mappen te filteren, slaat u deze instelling over en geeft u deze op in de instellingen van de activiteitsbron. | Nee |
| fileName | De bestandsnaam onder het opgegeven bestandssysteem + folderPath. Als u een jokerteken wilt gebruiken om bestanden te filteren, slaat u deze instelling over en geeft u deze op in de instellingen van de activiteitsbron. | Nee |
Voorbeeld:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobFSLocation",
"fileSystem": "filesystemname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie Copy-activiteit configuraties en pijplijnen en activiteiten voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Data Lake Storage Gen2-bron en -sink.
Azure Data Lake Storage Gen2 als brontype
Azure Data Factory ondersteunt de volgende bestandsindelingen. Raadpleeg elk artikel voor op indeling gebaseerde instellingen.
- Avro-indeling
- Binaire indeling
- Tekstindeling met scheidingstekens
- Excel-indeling
- JSON-indeling
- ORC-indeling
- Parquet-indeling
- XML-indeling
U hebt verschillende opties voor het kopiëren van gegevens uit ADLS Gen2:
- Kopieer vanuit het opgegeven pad dat is opgegeven in de gegevensset.
- Jokertekenfilter tegen mappad of bestandsnaam, zie
wildcardFolderPathenwildcardFileName. - Kopieer de bestanden die zijn gedefinieerd in een bepaald tekstbestand als bestandsset.
fileListPath
De volgende eigenschappen worden ondersteund voor Data Lake Storage Gen2 onder storeSettings instellingen in de op indeling gebaseerde kopieerbron:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type onder storeSettings moet worden ingesteld op AzureBlobFSReadSettings. |
Ja |
| Zoek de bestanden die u wilt kopiëren: | ||
| OPTIE 1: statisch pad |
Kopieer vanuit het opgegeven bestandssysteem of map/bestandspad dat is opgegeven in de gegevensset. Als u alle bestanden uit een bestandssysteem/map wilt kopiëren, moet u ook opgeven wildcardFileName als *. |
|
| OPTIE 2: jokerteken - jokertekenFolderPath |
Het pad naar de map met jokertekens onder het opgegeven bestandssysteem dat is geconfigureerd in de gegevensset om bronmappen te filteren. Toegestane jokertekens zijn: * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken); gebruik ^ deze optie om te ontsnappen als de naam van de map een jokerteken heeft of dit escape-teken bevat. Bekijk meer voorbeelden in voorbeelden van mappen en bestandsfilters. |
Nee |
| OPTIE 2: jokerteken - wildcardFileName |
De bestandsnaam met jokertekens onder het opgegeven bestandssysteem + folderPath/wildcardFolderPath om bronbestanden te filteren. Toegestane jokertekens zijn: * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken); gebruik ^ deze optie om te ontsnappen als uw werkelijke bestandsnaam jokertekens of dit escapeteken bevat. Bekijk meer voorbeelden in voorbeelden van mappen en bestandsfilters. |
Ja |
| OPTIE 3: een lijst met bestanden - fileListPath |
Geeft aan om een bepaalde bestandsset te kopiëren. Wijs een tekstbestand aan met een lijst met bestanden die u wilt kopiëren, één bestand per regel. Dit is het relatieve pad naar het pad dat is geconfigureerd in de gegevensset. Wanneer u deze optie gebruikt, geeft u geen bestandsnaam op in de gegevensset. Bekijk meer voorbeelden in voorbeelden van de lijst met bestanden. |
Nee |
| Aanvullende instellingen: | ||
| recursief | Hiermee wordt aangegeven of de gegevens recursief worden gelezen uit de submappen of alleen uit de opgegeven map. Houd er rekening mee dat wanneer recursief is ingesteld op true en de sink een archief op basis van bestanden is, een lege map of submap niet wordt gekopieerd of gemaakt in de sink. Toegestane waarden zijn waar (standaard) en onwaar. Deze eigenschap is niet van toepassing wanneer u configureert fileListPath. |
Nee |
| deleteFilesAfterCompletion | Geeft aan of de binaire bestanden worden verwijderd uit het bronarchief nadat ze naar het doelarchief zijn verplaatst. Het verwijderen van bestanden is per bestand, dus wanneer de kopieeractiviteit mislukt, ziet u dat sommige bestanden al naar het doel zijn gekopieerd en uit de bron zijn verwijderd, terwijl anderen nog steeds in het bronarchief blijven. Deze eigenschap is alleen geldig in het scenario voor het kopiëren van binaire bestanden. De standaardwaarde: false. |
Nee |
| modifiedDatetimeStart | Bestandenfilter op basis van het kenmerk: Laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op utc-tijdzone in de notatie 2018-12-01T05:00:00Z. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde heeft maar modifiedDatetimeEnd NULL is, betekent dit dat de bestanden waarvan het laatst gewijzigde kenmerk groter is dan of gelijk is aan de datum/tijd-waarde worden geselecteerd. Wanneer modifiedDatetimeEnd de datum/tijd-waarde is, maar modifiedDatetimeStart NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd kleiner is dan de datum/tijd-waarde wordt geselecteerd.Deze eigenschap is niet van toepassing wanneer u configureert fileListPath. |
Nee |
| modifiedDatetimeEnd | Hetzelfde als hierboven. | Nee |
| enablePartitionDiscovery | Geef voor bestanden die zijn gepartitioneerd op of de partities van het bestandspad moeten worden geparseerd en als extra bronkolommen moeten worden toegevoegd. Toegestane waarden zijn onwaar (standaard) en waar. |
Nee |
| partitionRootPath | Wanneer partitiedetectie is ingeschakeld, geeft u het absolute hoofdpad op om gepartitioneerde mappen als gegevenskolommen te lezen. Als deze niet is opgegeven, is dit standaard het volgende: - Wanneer u bestandspad gebruikt in de gegevensset of lijst met bestanden op de bron, is het pad naar de partitiehoofdmap dat is geconfigureerd in de gegevensset. - Wanneer u het filter voor jokertekens gebruikt, is partitiehoofdpad het subpad vóór het eerste jokerteken. Stel dat u het pad in de gegevensset configureert als 'root/folder/year=2020/month=08/day=27': - Als u partitiehoofdpad opgeeft als root/folder/year=2020, genereert de kopieeractiviteit twee kolommen month en day met de waarde '08' en '27', naast de kolommen in de bestanden.- Als het hoofdpad van de partitie niet is opgegeven, wordt er geen extra kolom gegenereerd. |
Nee |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
Voorbeeld:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobFSReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Data Lake Storage Gen2 als sinktype
Azure Data Factory ondersteunt de volgende bestandsindelingen. Raadpleeg elk artikel voor op indeling gebaseerde instellingen.
- Avro-indeling
- Binaire indeling
- Tekstindeling met scheidingstekens
- JSON-indeling
- ORC-indeling
- Parquet-indeling
De volgende eigenschappen worden ondersteund voor Data Lake Storage Gen2 onder storeSettings instellingen in de op indeling gebaseerde kopiesink:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type onder storeSettings moet worden ingesteld op AzureBlobFSWriteSettings. |
Ja |
| copyBehavior | Definieert het kopieergedrag wanneer de bron bestanden is uit een gegevensarchief op basis van bestanden. Toegestane waarden zijn: - PreserveHierarchy (standaard): behoudt de bestandshiërarchie in de doelmap. Het relatieve pad van het bronbestand naar de bronmap is identiek aan het relatieve pad van het doelbestand naar de doelmap. - FlattenHierarchy: Alle bestanden uit de bronmap bevinden zich op het eerste niveau van de doelmap. De doelbestanden hebben automatisch gegenereerde namen. - MergeFiles: hiermee worden alle bestanden uit de bronmap samengevoegd tot één bestand. Als de bestandsnaam is opgegeven, is de naam van het samengevoegde bestand de opgegeven naam. Anders is het een automatisch gegenereerde bestandsnaam. |
Nee |
| blockSizeInMB | Geef de blokgrootte op in MB die wordt gebruikt voor het schrijven van gegevens naar ADLS Gen2. Meer informatie over blok-blobs. De toegestane waarde ligt tussen 4 MB en 100 MB. Standaard bepaalt ADF automatisch de blokgrootte op basis van het type bronarchief en gegevens. Voor niet-binaire kopie in ADLS Gen2 is de standaardblokgrootte 100 MB, zodat deze maximaal 4,75 TB aan gegevens past. Het is mogelijk niet optimaal wanneer uw gegevens niet groot zijn, met name wanneer u zelf-hostende Integration Runtime gebruikt met een slecht netwerk, wat resulteert in een time-out of prestatieprobleem voor bewerkingen. U kunt expliciet een blokgrootte opgeven, terwijl blockSizeInMB*50000 groot genoeg is om de gegevens op te slaan, anders mislukt de kopieeractiviteit. |
Nee |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
| metagegevens | Stel aangepaste metagegevens in wanneer u kopieert naar sink. Elk object onder de metadata matrix vertegenwoordigt een extra kolom. De name naam van de metagegevenssleutel wordt gedefinieerd en de value gegevenswaarde van die sleutel wordt aangegeven. Als de kenmerkfunctie behouden wordt gebruikt, worden de opgegeven metagegevens samengevoegd/overschreven met de metagegevens van het bronbestand.Toegestane gegevenswaarden zijn: - $$LASTMODIFIED: een gereserveerde variabele geeft aan dat de laatste wijzigingstijd van de bronbestanden moet worden opgeslagen. Alleen van toepassing op een bron op basis van bestanden met binaire indeling.-Uitdrukking - Statische waarde |
Nee |
Voorbeeld:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobFSWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
Voorbeelden van map- en bestandsfilters
In deze sectie wordt het resulterende gedrag van het mappad en de bestandsnaam met jokertekenfilters beschreven.
| folderPath | fileName | recursief | Structuur van bronmap en filterresultaat (bestanden vetgedrukt worden opgehaald) |
|---|---|---|---|
Folder* |
(Leeg, standaard gebruiken) | false | MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(Leeg, standaard gebruiken) | true | MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Voorbeelden van bestandslijsten
In deze sectie wordt het resulterende gedrag beschreven van het gebruik van bestandslijstpad in bron van kopieeractiviteit.
Ervan uitgaande dat u de volgende bronmapstructuur hebt en de bestanden vetgedrukt wilt kopiëren:
| Voorbeeldbronstructuur | Inhoud in FileListToCopy.txt | ADF-configuratie |
|---|---|---|
| bestandssysteem MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv Metagegevens FileListToCopy.txt |
File1.csv Submap1/File3.csv Submap1/File5.csv |
In gegevensset: -Bestandssysteem: filesystem- Mappad: FolderAIn bron van kopieeractiviteit: - Pad naar bestandslijst: filesystem/Metadata/FileListToCopy.txt Het bestandslijstpad verwijst naar een tekstbestand in hetzelfde gegevensarchief met een lijst met bestanden die u wilt kopiëren, één bestand per regel met het relatieve pad naar het pad dat is geconfigureerd in de gegevensset. |
Enkele recursieve en copyBehavior-voorbeelden
In deze sectie wordt het resulterende gedrag van de kopieerbewerking beschreven voor verschillende combinaties van recursieve en copyBehavior-waarden.
| recursief | copyBehavior | Structuur van bronmap | Resulterend doel |
|---|---|---|---|
| true | preserveHierarchy | Map1 Bestand1 Bestand2 Submap1 Bestand3 Bestand4 Bestand5 |
De doelmap1 wordt gemaakt met dezelfde structuur als de bron: Map1 Bestand1 Bestand2 Submap1 Bestand3 Bestand4 Bestand5 |
| true | flattenHierarchy | Map1 Bestand1 Bestand2 Submap1 Bestand3 Bestand4 Bestand5 |
De doelmap1 wordt gemaakt met de volgende structuur: Map1 automatisch gegenereerde naam voor Bestand1 automatisch gegenereerde naam voor File2 automatisch gegenereerde naam voor File3 automatisch gegenereerde naam voor File4 automatisch gegenereerde naam voor File5 |
| true | mergeFiles | Map1 Bestand1 Bestand2 Submap1 Bestand3 Bestand4 Bestand5 |
De doelmap1 wordt gemaakt met de volgende structuur: Map1 File1 + File2 + File3 + File4 + File5-inhoud worden samengevoegd in één bestand met een automatisch gegenereerde bestandsnaam. |
| false | preserveHierarchy | Map1 Bestand1 Bestand2 Submap1 Bestand3 Bestand4 Bestand5 |
De doelmap1 wordt gemaakt met de volgende structuur: Map1 Bestand1 Bestand2 Submap1 met File3, File4 en File5 wordt niet opgehaald. |
| false | flattenHierarchy | Map1 Bestand1 Bestand2 Submap1 Bestand3 Bestand4 Bestand5 |
De doelmap1 wordt gemaakt met de volgende structuur: Map1 automatisch gegenereerde naam voor Bestand1 automatisch gegenereerde naam voor File2 Submap1 met File3, File4 en File5 wordt niet opgehaald. |
| false | mergeFiles | Map1 Bestand1 Bestand2 Submap1 Bestand3 Bestand4 Bestand5 |
De doelmap1 wordt gemaakt met de volgende structuur: Map1 De inhoud van Bestand1 + File2 wordt samengevoegd in één bestand met een automatisch gegenereerde bestandsnaam. automatisch gegenereerde naam voor Bestand1 Submap1 met File3, File4 en File5 wordt niet opgehaald. |
Metagegevens behouden tijdens het kopiëren
Wanneer u bestanden kopieert van Amazon S3/Azure Blob/Azure Data Lake Storage Gen2 naar Azure Data Lake Storage Gen2/Azure Blob, kunt u ervoor kiezen om de metagegevens van bestanden samen met gegevens te behouden. Meer informatie over metagegevens behouden.
ACL's van Data Lake Storage Gen1/Gen2 behouden
Wanneer u bestanden kopieert van Azure Data Lake Storage Gen1/Gen2 naar Gen2, kunt u ervoor kiezen om de POSIX-toegangsbeheerlijsten (ACL's) samen met gegevens te behouden. Meer informatie over ACL's behouden van Data Lake Storage Gen1/Gen2 naar Gen2.
Tip
Als u gegevens van Azure Data Lake Storage Gen1 in het algemeen naar Gen2 wilt kopiëren, raadpleegt u Gegevens kopiëren van Azure Data Lake Storage Gen1 naar Gen2 voor een overzicht en aanbevolen procedures.
Eigenschappen van toewijzingsgegevensstroom
Wanneer u gegevens transformeert in toewijzingsgegevensstromen, kunt u bestanden lezen en schrijven vanuit Azure Data Lake Storage Gen2 in de volgende indelingen:
Indelingsspecifieke instellingen bevinden zich in de documentatie voor die indeling. Zie Brontransformatie in toewijzingsgegevensstroom en Sink-transformatie in toewijzingsgegevensstroom voor meer informatie.
Brontransformatie
In de brontransformatie kunt u lezen uit een container, map of afzonderlijk bestand in Azure Data Lake Storage Gen2. Op het tabblad Bronopties kunt u beheren hoe de bestanden worden gelezen.
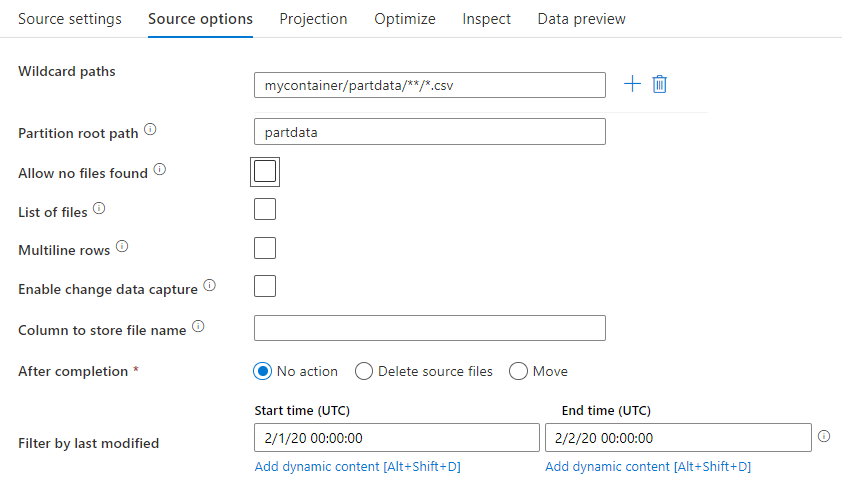
Jokertekenpad: Met behulp van een jokertekenpatroon wordt ADF geïnstrueerd om elke overeenkomende map en elk bestand in één brontransformatie te doorlopen. Dit is een effectieve manier om meerdere bestanden binnen één stroom te verwerken. Voeg meerdere jokertekenpatronen toe met het plusteken dat wordt weergegeven wanneer u de muisaanwijzer boven het bestaande jokertekenpatroon beweegt.
Kies in uw broncontainer een reeks bestanden die overeenkomen met een patroon. Alleen container kan worden opgegeven in de gegevensset. Uw jokertekenpad moet daarom ook uw mappad uit de hoofdmap bevatten.
Voorbeelden van jokertekens:
*Vertegenwoordigt een set tekens**Vertegenwoordigt recursieve directory-nesting?Hiermee wordt één teken vervangen[]Komt overeen met een van de tekens tussen vierkante haken/data/sales/**/*.csvHiermee worden alle CSV-bestanden opgehaald onder /data/sales/data/sales/20??/**/Haalt alle bestanden in de 20e eeuw/data/sales/*/*/*.csvHiermee worden CSV-bestanden twee niveaus opgehaald onder /data/sales/data/sales/2004/*/12/[XY]1?.csvHiermee worden alle CSV-bestanden in 2004 in december opgehaald, beginnend met X of Y, voorafgegaan door een getal van twee cijfers
Hoofdpad partitie: als u mappen in uw bestandsbron hebt gepartitioneerd met een key=value indeling (bijvoorbeeld year=2019), kunt u het hoogste niveau van die partitiemapstructuur toewijzen aan een kolomnaam in uw gegevensstroomgegevensstroom.
Stel eerst een jokerteken in om alle paden op te nemen die de gepartitioneerde mappen zijn plus de leaf-bestanden die u wilt lezen.
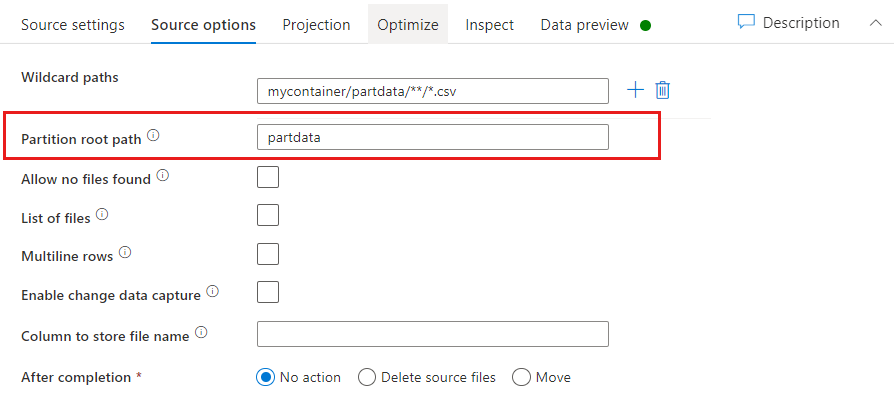
Gebruik de instelling Hoofdpad partitioneren om te definiëren wat het hoogste niveau van de mapstructuur is. Wanneer u de inhoud van uw gegevens bekijkt via een voorbeeld van gegevens, ziet u dat ADF de opgeloste partities toevoegt die in elk van uw mapniveaus zijn gevonden.
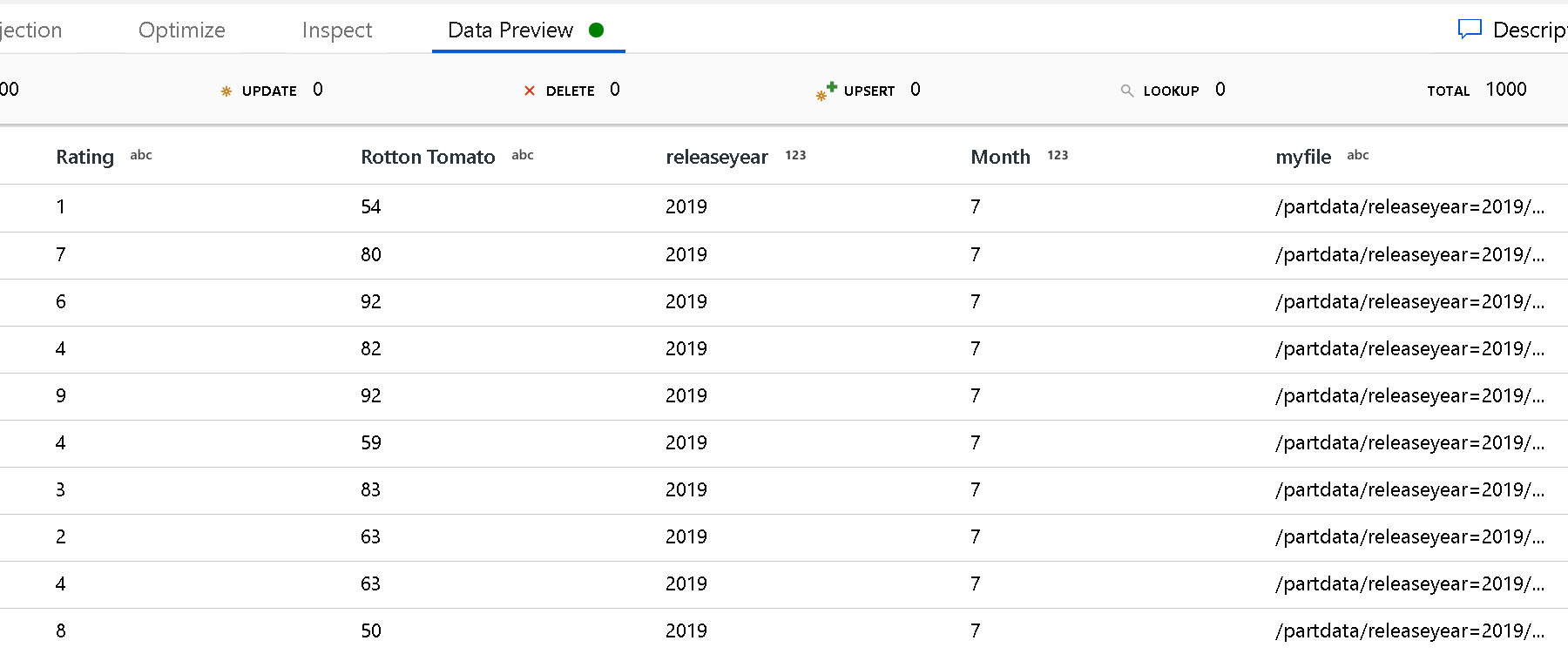
Lijst met bestanden: dit is een bestandsset. Maak een tekstbestand met een lijst met relatieve padbestanden die moeten worden verwerkt. Wijs dit tekstbestand aan.
Kolom voor het opslaan van bestandsnaam: Sla de naam van het bronbestand op in een kolom in uw gegevens. Voer hier een nieuwe kolomnaam in om de bestandsnaamtekenreeks op te slaan.
Na voltooiing: Kies ervoor om niets te doen met het bronbestand nadat de gegevensstroom is uitgevoerd, verwijder het bronbestand of verplaats het bronbestand. De paden voor de verplaatsing zijn relatief.
Als u bronbestanden wilt verplaatsen naar een andere locatie na verwerking, selecteert u eerst Verplaatsen voor bestandsbewerking. Stel vervolgens de map 'from' in. Als u geen jokertekens voor uw pad gebruikt, is de instelling 'van' dezelfde map als uw bronmap.
Als u een bronpad met jokertekens hebt, ziet uw syntaxis er als volgt uit:
/data/sales/20??/**/*.csv
U kunt 'van' opgeven als
/data/sales
En 'aan' als
/backup/priorSales
In dit geval worden alle bestanden die zijn opgehaald onder /data/sales verplaatst naar /backup/priorSales.
Notitie
Bestandsbewerkingen worden alleen uitgevoerd wanneer u de gegevensstroom start vanuit een pijplijnuitvoering (een pijplijnopsporing of uitvoeringsuitvoering) die gebruikmaakt van de uitvoering Gegevensstroom-activiteit uitvoeren in een pijplijn. Bestandsbewerkingen worden niet uitgevoerd in Gegevensstroom foutopsporingsmodus.
Filteren op laatst gewijzigd: u kunt filteren welke bestanden u verwerkt door een datumbereik op te geven van wanneer ze voor het laatst zijn gewijzigd. Alle datums zijn in UTC.
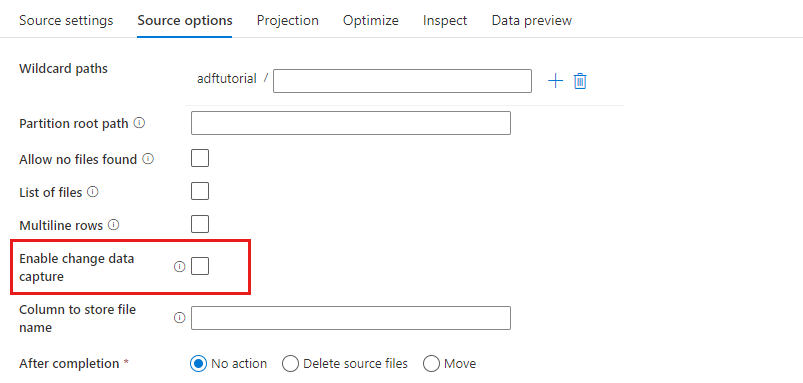
Wijzigingsgegevens vastleggen inschakelen: als waar, krijgt u alleen nieuwe of gewijzigde bestanden van de laatste uitvoering. De eerste belasting van volledige momentopnamegegevens wordt altijd in de eerste uitvoering opgehaald, gevolgd door het vastleggen van nieuwe of gewijzigde bestanden alleen in de volgende uitvoeringen. Zie Gegevens vastleggen wijzigen voor meer informatie.
Sink-eigenschappen
In de sinktransformatie kunt u schrijven naar een container of map in Azure Data Lake Storage Gen2. Op het tabblad Instellingen kunt u beheren hoe de bestanden worden geschreven.
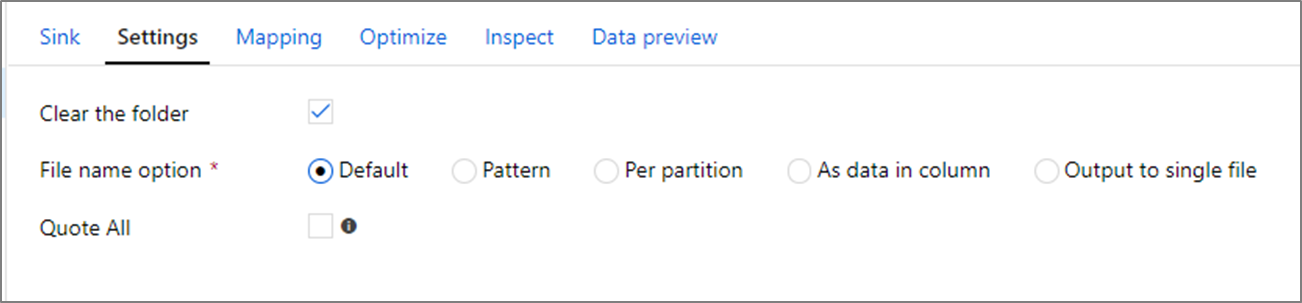
De map wissen: bepaalt of de doelmap al dan niet wordt gewist voordat de gegevens worden geschreven.
Optie Bestandsnaam: bepaalt hoe de doelbestanden worden genoemd in de doelmap. De bestandsnaamopties zijn:
- Standaard: Toestaan dat Spark bestanden een naam geeft op basis van de standaardinstellingen van PART.
- Patroon: Voer een patroon in waarmee uw uitvoerbestanden per partitie worden opgesomd. Leningen[n].csv maken bijvoorbeeld loans1.csv, loans2.csv enzovoort.
- Per partitie: Voer één bestandsnaam per partitie in.
- Als gegevens in kolom: Stel het uitvoerbestand in op de waarde van een kolom. Het pad is relatief ten opzichte van de container van de gegevensset, niet de doelmap. Als u een mappad in uw gegevensset hebt, wordt dit overschreven.
- Uitvoer naar één bestand: combineer de gepartitioneerde uitvoerbestanden in één benoemd bestand. Het pad is relatief ten opzichte van de map gegevensset. Houd er rekening mee dat de samenvoegbewerking mogelijk mislukt op basis van de knooppuntgrootte. Deze optie wordt niet aanbevolen voor grote gegevenssets.
Alle aanhalingstekens: bepaalt of alle waarden tussen aanhalingstekens moeten worden geplaatst
umask
U kunt desgewenst de umask voor bestanden instellen met POSIX-lees-, schrijf-, uitvoervlagken voor eigenaar, gebruiker en groep.
Opdrachten vóór verwerking en naverwerking
U kunt desgewenst Hadoop-bestandssysteemopdrachten uitvoeren voor of na schrijven naar een ADLS Gen2-sink. De volgende opdrachten worden ondersteund:
cpmvrmmkdir
Voorbeelden:
mkdir /folder1mkdir -p folder1mv /folder1/*.* /folder2/cp /folder1/file1.txt /folder2rm -r /folder1
Parameters worden ook ondersteund via de opbouwfunctie voor expressies, bijvoorbeeld:
mkdir -p {$tempPath}/commands/c1/c2
mv {$tempPath}/commands/*.* {$tempPath}/commands/c1/c2
Mappen worden standaard gemaakt als gebruiker/hoofdmap. Raadpleeg de container op het hoogste niveau met '/'.
Eigenschappen van opzoekactiviteit
Als u meer wilt weten over de eigenschappen, controleert u de lookup-activiteit.
Eigenschappen van GetMetadata-activiteit
Als u meer wilt weten over de eigenschappen, controleert u de Activiteit GetMetadata
Activiteitseigenschappen verwijderen
Als u meer wilt weten over de eigenschappen, controleert u De activiteit Verwijderen
Verouderde modellen
Notitie
De volgende modellen worden nog steeds ondersteund voor compatibiliteit met eerdere versies. U wordt aangeraden het nieuwe model te gebruiken dat in de bovenstaande secties wordt genoemd en de ADF-ontwerpgebruikersinterface is overgeschakeld naar het genereren van het nieuwe model.
Verouderd gegevenssetmodel
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op AzureBlobFSFile. | Ja |
| folderPath | Pad naar de map in Data Lake Storage Gen2. Als dit niet is opgegeven, verwijst deze naar de hoofdmap. Jokertekenfilter wordt ondersteund. Toegestane jokertekens zijn * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken). Gebruik ^ deze optie om te ontsnappen als uw werkelijke mapnaam een jokerteken heeft of als dit escape-teken zich binnen bevindt. Voorbeelden: bestandssysteem/map/. Bekijk meer voorbeelden in voorbeelden van mappen en bestandsfilters. |
Nee |
| fileName | Naam of jokertekenfilter voor de bestanden onder het opgegeven mapPath. Als u geen waarde voor deze eigenschap opgeeft, verwijst de gegevensset naar alle bestanden in de map. Voor het filteren zijn * de toegestane jokertekens (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken).- Voorbeeld 1: "fileName": "*.csv"- Voorbeeld 2: "fileName": "???20180427.txt"Gebruik ^ deze optie om te ontsnappen als uw werkelijke bestandsnaam een jokerteken heeft of als dit escape-teken zich binnen bevindt.Wanneer fileName niet is opgegeven voor een uitvoergegevensset en preserveHierarchy niet is opgegeven in de activiteitssink, genereert de kopieeractiviteit automatisch de bestandsnaam met het volgende patroon: 'Data.[ ID-GUID van activiteitsuitvoering]. [GUID als FlattenHierarchy]. [notatie indien geconfigureerd]. [compressie indien geconfigureerd]", bijvoorbeeld 'Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz'. Als u kopieert vanuit een tabellaire bron met behulp van een tabelnaam in plaats van een query, is het naampatroon [tabelnaam].[ format]. [compressie indien geconfigureerd]", bijvoorbeeld 'MyTable.csv'. |
Nee |
| modifiedDatetimeStart | Bestandenfilter op basis van het kenmerk Laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op de UTC-tijdzone in de notatie '2018-12-01T05:00:00Z'. De algehele prestaties van gegevensverplaatsing worden beïnvloed door deze instelling in te schakelen wanneer u een bestandsfilter wilt uitvoeren met grote hoeveelheden bestanden. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde heeft maar modifiedDatetimeEnd NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd groter dan of gelijk aan de datum/tijd-waarde zijn geselecteerd. Wanneer modifiedDatetimeEnd een datum/tijd-waarde heeft, maar modifiedDatetimeStart NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd kleiner is dan de datum/tijd-waarde zijn geselecteerd. |
Nee |
| modifiedDatetimeEnd | Bestandenfilter op basis van het kenmerk Laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op de UTC-tijdzone in de notatie '2018-12-01T05:00:00Z'. De algehele prestaties van gegevensverplaatsing worden beïnvloed door deze instelling in te schakelen wanneer u een bestandsfilter wilt uitvoeren met grote hoeveelheden bestanden. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde heeft maar modifiedDatetimeEnd NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd groter dan of gelijk aan de datum/tijd-waarde zijn geselecteerd. Wanneer modifiedDatetimeEnd een datum/tijd-waarde heeft, maar modifiedDatetimeStart NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd kleiner is dan de datum/tijd-waarde zijn geselecteerd. |
Nee |
| indeling | Als u bestanden wilt kopiëren zoals tussen op bestanden gebaseerde archieven (binaire kopie), slaat u de indelingssectie over in de definities van de invoer- en uitvoergegevensset. Als u bestanden met een specifieke indeling wilt parseren of genereren, worden de volgende bestandstypen ondersteund: TextFormat, JsonFormat, AvroFormat, OrcFormat en ParquetFormat. Stel de typeeigenschap onder opmaak in op een van deze waarden. Zie de secties Tekstindeling, JSON-indeling, Avro-indeling, ORC-indeling en Parquet-indeling voor meer informatie. |
Nee (alleen voor binair kopieerscenario) |
| compressie | Geef het type en het compressieniveau voor de gegevens op. Zie Ondersteunde bestandsindelingen en compressiecodecs voor meer informatie. Ondersteunde typen zijn **GZip**, **Deflate**, **BZip2**, and **ZipDeflate**.Ondersteunde niveaus zijn Optimaal en Snelste. |
Nee |
Tip
Als u alle bestanden onder een map wilt kopiëren, geeft u alleen folderPath op.
Als u één bestand met een bepaalde naam wilt kopiëren, geeft u folderPath op met een maponderdeel en fileName met een bestandsnaam.
Als u een subset van bestanden onder een map wilt kopiëren, geeft u folderPath op met een maponderdeel en fileName met een jokertekenfilter.
Voorbeeld:
{
"name": "ADLSGen2Dataset",
"properties": {
"type": "AzureBlobFSFile",
"linkedServiceName": {
"referenceName": "<Azure Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "myfilesystem/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Bronmodel van verouderde kopieeractiviteit
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op AzureBlobFSSource. | Ja |
| recursief | Hiermee wordt aangegeven of de gegevens recursief worden gelezen uit de submappen of alleen uit de opgegeven map. Wanneer recursief is ingesteld op true en de sink een archief op basis van bestanden is, wordt een lege map of submap niet gekopieerd of gemaakt in de sink. Toegestane waarden zijn waar (standaard) en onwaar. |
Nee |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
Voorbeeld:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen2 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureBlobFSSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Verouderd sinkmodel voor kopieeractiviteit
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de sink van de kopieeractiviteit moet worden ingesteld op AzureBlobFSSink. | Ja |
| copyBehavior | Definieert het kopieergedrag wanneer de bron bestanden is uit een gegevensarchief op basis van bestanden. Toegestane waarden zijn: - PreserveHierarchy (standaard): behoudt de bestandshiërarchie in de doelmap. Het relatieve pad van het bronbestand naar de bronmap is identiek aan het relatieve pad van het doelbestand naar de doelmap. - FlattenHierarchy: Alle bestanden uit de bronmap bevinden zich op het eerste niveau van de doelmap. De doelbestanden hebben automatisch gegenereerde namen. - MergeFiles: hiermee worden alle bestanden uit de bronmap samengevoegd tot één bestand. Als de bestandsnaam is opgegeven, is de naam van het samengevoegde bestand de opgegeven naam. Anders is het een automatisch gegenereerde bestandsnaam. |
Nee |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
Voorbeeld:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen2 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureBlobFSSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Gegevensregistratie wijzigen
Azure Data Factory kan nieuwe of gewijzigde bestanden alleen ophalen uit Azure Data Lake Storage Gen2 door wijzigingsgegevensopname inschakelen in te schakelen in de brontransformatie van de toewijzingsgegevensstroom. Met deze connectoroptie kunt u alleen nieuwe of bijgewerkte bestanden lezen en transformaties toepassen voordat u getransformeerde gegevens laadt in doelgegevenssets van uw keuze.
Zorg ervoor dat u de naam van de pijplijn en activiteit ongewijzigd laat, zodat het controlepunt altijd kan worden vastgelegd vanaf de laatste uitvoering om daar wijzigingen op te halen. Als u de naam van uw pijplijn of activiteit wijzigt, wordt het controlepunt opnieuw ingesteld en begint u vanaf het begin in de volgende uitvoering.
Wanneer u fouten in de pijplijn opssport, werkt het vastleggen van wijzigingsgegevens ook. Houd er rekening mee dat het controlepunt opnieuw wordt ingesteld wanneer u uw browser vernieuwt tijdens de uitvoering van foutopsporing. Nadat u tevreden bent met het resultaat van de foutopsporingsuitvoering, kunt u de pijplijn publiceren en activeren. Het begint altijd vanaf het begin, ongeacht het vorige controlepunt dat is vastgelegd door de foutopsporingsuitvoering.
In de sectie Bewaking hebt u altijd de mogelijkheid om een pijplijn opnieuw uit te voeren. Wanneer u dit doet, worden de wijzigingen altijd opgehaald uit de controlepuntrecord in de geselecteerde pijplijnuitvoering.
Gerelateerde inhoud
Zie Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door de kopieeractiviteit.