Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met aangepaste spraak kunt u de nauwkeurigheid van spraakherkenning voor uw toepassingen en producten evalueren en verbeteren. Een aangepast spraakmodel kan worden gebruikt voor realtime spraak naar tekst, spraakomzetting en batchtranscriptie.
Spraakherkenning maakt gebruik van een Universal Language Model als basismodel dat is getraind met gegevens in eigendom van Microsoft en weerspiegelt veelgebruikte gesproken taal. Het basismodel is vooraf getraind met dialecten en fonetiek die verschillende gemeenschappelijke domeinen vertegenwoordigen. Wanneer u een aanvraag voor spraakherkenning maakt, wordt het meest recente basismodel voor elke ondersteunde taal standaard gebruikt. Het basismodel werkt goed in de meeste scenario's voor spraakherkenning.
Een aangepast model kan worden gebruikt om het basismodel te verbeteren om de herkenning van domeinspecifieke woordenlijsten die specifiek zijn voor de toepassing te verbeteren door tekstgegevens op te geven om het model te trainen. Het kan ook worden gebruikt om herkenning te verbeteren op basis van de specifieke audiovoorwaarden van de toepassing door audiogegevens te voorzien van referentietranscripties.
U kunt ook een model trainen met gestructureerde tekst wanneer de gegevens een patroon volgen, aangepaste uitspraken opgeven en weergavetekstopmaak aanpassen met aangepaste inverse tekstnormalisatie, aangepast herschrijven en filteren op aangepaste scheldwoorden.
Hoe werkt het?
Met aangepaste spraak kunt u uw eigen gegevens uploaden, een aangepast model testen en trainen, de nauwkeurigheid tussen modellen vergelijken en een model implementeren op een aangepast eindpunt.
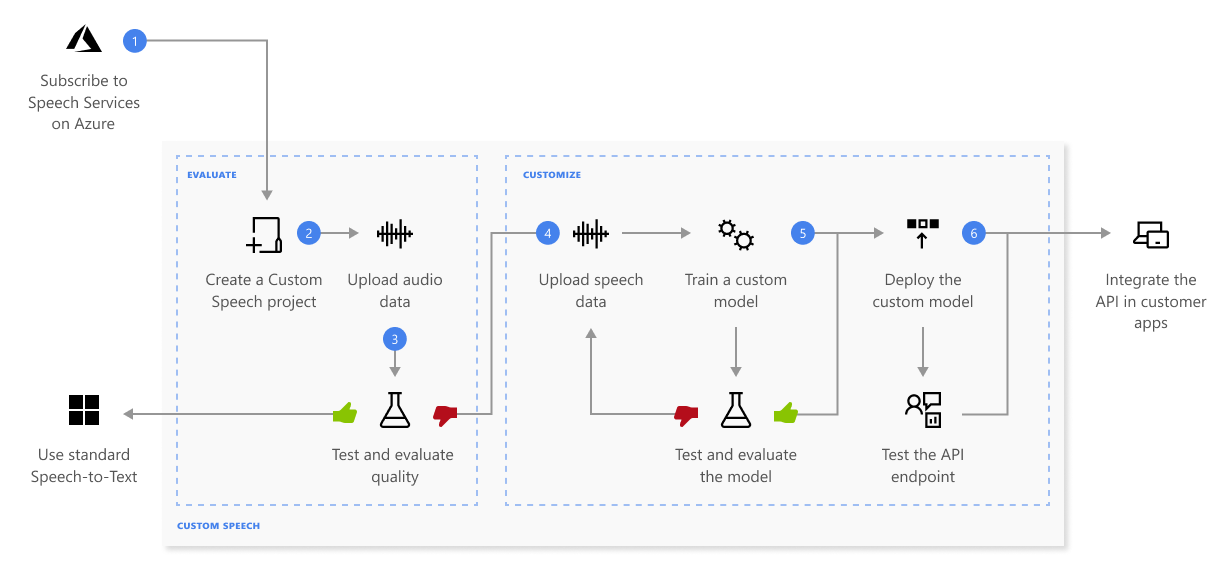
Hier vindt u meer informatie over de reeks stappen die in het vorige diagram worden weergegeven:
Maak een project en kies een model. Gebruik Speech-resource die u in Azure Portal maakt. Als u een aangepast model traint met audiogegevens, selecteert u een serviceresource in een regio met toegewezen hardware voor het trainen van audiogegevens. Zie voetnoten in de tabel Regio's voor meer informatie.
Testgegevens uploaden. Upload testgegevens om de spraak-naar-tekst-aanbieding voor uw toepassingen, hulpprogramma's en producten te evalueren.
Een model trainen. Geef geschreven transcripten en gerelateerde tekst op, samen met de bijbehorende audiogegevens. Het testen van een model voor en na de training is optioneel, maar wordt aanbevolen.
Notitie
U betaalt voor het gebruik van aangepaste spraakmodellen en het hosten van eindpunten. Er worden ook kosten in rekening gebracht voor het trainen van aangepaste spraakmodellen als het basismodel is gemaakt op 1 oktober 2023 en hoger. Er worden geen kosten in rekening gebracht voor training als het basismodel vóór oktober 2023 is gemaakt. Zie de prijzen van Azure AI Speech en de sectie Kosten voor aanpassing in de migratiehandleiding voor spraak naar tekst 3.2 voor meer informatie.
Kwaliteit van testherkenning. Gebruik Speech Studio om geüploade audio af te spelen en de kwaliteit van de spraakherkenning van uw testgegevens te inspecteren.
Test het model kwantitatief. Evalueer en verbeter de nauwkeurigheid van het spraak-naar-tekstmodel. De Speech-service biedt een kwantitatief woordfoutpercentage (WER), dat u kunt gebruiken om te bepalen of er meer training nodig is.
Een model implementeren. Zodra u tevreden bent met de testresultaten, implementeert u het model naar een aangepast eindpunt. Behalve voor batchtranscriptie moet u een aangepast eindpunt implementeren om een aangepast spraakmodel te gebruiken.
Aanbeveling
Een gehost implementatie-eindpunt is niet vereist voor het gebruik van aangepaste spraak met de Batch-transcriptie-API. U kunt resources besparen als het aangepaste spraakmodel alleen wordt gebruikt voor batchtranscriptie. Zie prijzen voor de Speech-service voor meer informatie.
Uw model kiezen
Er zijn enkele benaderingen voor het gebruik van aangepaste spraakmodellen:
- Het basismodel biedt nauwkeurige spraakherkenning in een reeks scenario's. Basismodellen worden periodiek bijgewerkt om de nauwkeurigheid en kwaliteit te verbeteren. Als u basismodellen gebruikt, wordt u aangeraden de meest recente standaardbasismodellen te gebruiken. Als een vereiste aanpassingsmogelijkheid alleen beschikbaar is voor een ouder model, kunt u een ouder basismodel kiezen.
- Met een aangepast model wordt het basismodel uitgebreid met domeinspecifieke vocabulaire die wordt gedeeld in alle gebieden van het aangepaste domein.
- Er kunnen meerdere aangepaste modellen worden gebruikt wanneer het aangepaste domein meerdere gebieden heeft, elk met een specifieke woordenlijst.
Een aanbevolen manier om te zien of het basismodel voldoende is om de transcriptie te analyseren die is geproduceerd op basis van het basismodel en dit te vergelijken met een door mensen gegenereerde transcriptie voor dezelfde audio. U kunt de transcripten vergelijken en een WER-score (Word Error Rate) verkrijgen. Als de WER-score hoog is, wordt het trainen van een aangepast model aanbevolen om de onjuist geïdentificeerde woorden te herkennen.
Er worden meerdere modellen aanbevolen als het vocabulaire varieert tussen de domeingebieden. Olympische commentatoren rapporteren bijvoorbeeld over verschillende gebeurtenissen, elk gekoppeld aan een eigen taal. Omdat elke Vocabulaire olympische gebeurtenis aanzienlijk verschilt van anderen, verhoogt het bouwen van een aangepast model dat specifiek is voor een gebeurtenis de nauwkeurigheid door de uitingsgegevens te beperken ten opzichte van die specifieke gebeurtenis. Als gevolg hiervan hoeft het model niet via niet-gerelateerde gegevens te doorzoeken om een overeenkomst te maken. Hoe dan ook, training vereist nog steeds een behoorlijke verscheidenheid aan trainingsgegevens. Neem audio op van verschillende commentatoren met verschillende accenten, geslacht, leeftijd, enzovoort.
Modelstabiliteit en levenscyclus
Een basismodel of aangepast model dat is geïmplementeerd op een eindpunt met behulp van aangepaste spraak, wordt opgelost totdat u besluit het bij te werken. De nauwkeurigheid en kwaliteit van spraakherkenning blijven consistent, zelfs wanneer er een nieuw basismodel wordt vrijgegeven. Hiermee kunt u het gedrag van een specifiek model vergrendelen totdat u besluit een nieuwer model te gebruiken.
Of u nu uw eigen model traint of een momentopname van een basismodel gebruikt, u kunt het model gedurende een beperkte tijd gebruiken. Zie model- en eindpuntlevenscyclus voor meer informatie.
Verantwoorde AI
Een AI-systeem omvat niet alleen de technologie, maar ook de mensen die het gebruiken, de mensen die worden beïnvloed door het systeem en de omgeving waarin het wordt geïmplementeerd. Lees de transparantienotities voor meer informatie over verantwoord AI-gebruik en -implementatie in uw systemen.
- Transparantienotitie en gebruiksvoorbeelden
- Kenmerken en beperkingen
- Integratie en verantwoordelijk gebruik
- Gegevens, privacy en beveiliging