Meta Llama 3.1-modellen implementeren met Azure AI Studio
Belangrijk
Sommige van de functies die in dit artikel worden beschreven, zijn mogelijk alleen beschikbaar in de preview-versie. Deze preview wordt aangeboden zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
In dit artikel leert u meer over de Meta Llama-modelfamilie. U leert ook hoe u Azure AI Studio gebruikt om modellen uit deze set te implementeren op serverloze API's met betalen per gebruik facturering of beheerde berekening.
Belangrijk
Lees meer over de aankondiging van Meta Llama 3.1 405B Instruct and other Llama 3.1 models available now on Azure AI Model Catalog: Microsoft Tech Community Blog and from Meta Announcement Blog.
Nu beschikbaar in Azure AI Models-as-a-Service:
Meta-Llama-3.1-405B-InstructMeta-Llama-3.1-70B-InstructMeta-Llama-3.1-8B-Instruct
De Meta Llama 3.1-familie van meertalige grote taalmodellen (LLM's) is een verzameling vooraf getrainde en instructiegestemde modellen in 8B-, 70B- en 405B-grootten (tekst in/tekst uit). Alle modellen ondersteunen lange contextlengte (128k) en zijn geoptimaliseerd voor deductie met ondersteuning voor gegroepeerde query-aandacht (GQA). De Llama 3.1-instructie alleen modellen (8B, 70B, 405B) zijn geoptimaliseerd voor meertalige gebruiksscenario's voor dialoog en presteren veel van de beschikbare opensource-chatmodellen op algemene benchmarks voor de industrie.
Bekijk de volgende GitHub-voorbeelden om integraties te verkennen met LangChain, LiteLLM, OpenAI en de Azure-API.
Meta Llama 3.1 405B implementeren als een serverloze API
Meta Llama 3.1-modellen , zoals Meta Llama 3.1 405B Instruct - kunnen worden geïmplementeerd als een serverloze API met betalen per gebruik. Dit biedt een manier om ze als API te gebruiken zonder ze te hosten in uw abonnement, terwijl organisaties voor bedrijfsbeveiliging en naleving nodig hebben. Voor deze implementatieoptie is geen quotum van uw abonnement vereist. Meta Llama 3.1-modellen worden geïmplementeerd als een serverloze API met betalen per gebruik-facturering via Microsoft Azure Marketplace, en ze kunnen meer gebruiksvoorwaarden en prijzen toevoegen.
Azure Marketplace-modelaanbiedingen
De volgende modellen zijn beschikbaar in Azure Marketplace voor Llama 3.1 en Llama 3 wanneer ze worden geïmplementeerd als een service met betalen per gebruik:
Als u een ander model wilt implementeren, implementeert u het in plaats daarvan in beheerde berekeningen .
Vereisten
Een Azure-abonnement met een geldige betalingswijze. Gratis of proefversie van Azure-abonnementen werkt niet. Als u geen Azure-abonnement hebt, maakt u eerst een betaald Azure-account .
Een AI Studio-hub. De serverloze API-modelimplementatie voor Meta Llama 3.1 en Llama 3 is alleen beschikbaar met hubs die in deze regio's zijn gemaakt:
- VS - oost
- VS - oost 2
- VS - noord-centraal
- VS - zuid-centraal
- VS - west
- US - west 3
- Zweden - centraal
Zie Regio-beschikbaarheid voor modellen in serverloze API-eindpunten voor een lijst met regio's die beschikbaar zijn voor elk van de modellen die ondersteuning bieden voor serverloze API-eindpuntimplementaties.
Een AI Studio-project in Azure AI Studio.
Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) wordt gebruikt om toegang te verlenen tot bewerkingen in Azure AI Studio. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de rol eigenaar of inzender voor het Azure-abonnement zijn toegewezen. U kunt ook een aangepaste rol aan uw account toewijzen met de volgende machtigingen:
In het Azure-abonnement: als u het AI Studio-project wilt abonneren op het Azure Marketplace-aanbod, één keer voor elk project, per aanbieding:
Microsoft.MarketplaceOrdering/agreements/offers/plans/readMicrosoft.MarketplaceOrdering/agreements/offers/plans/sign/actionMicrosoft.MarketplaceOrdering/offerTypes/publishers/offers/plans/agreements/readMicrosoft.Marketplace/offerTypes/publishers/offers/plans/agreements/readMicrosoft.SaaS/register/action
In de resourcegroep—om de SaaS-resource te maken en te gebruiken:
Microsoft.SaaS/resources/readMicrosoft.SaaS/resources/write
In het AI Studio-project: als u eindpunten wilt implementeren (de Azure AI Developer-rol bevat deze machtigingen al):
Microsoft.MachineLearningServices/workspaces/marketplaceModelSubscriptions/*Microsoft.MachineLearningServices/workspaces/serverlessEndpoints/*
Zie Op rollen gebaseerd toegangsbeheer in Azure AI Studio voor meer informatie over machtigingen.
Een nieuwe implementatie maken
Een implementatie maken:
Meld u aan bij Azure AI Studio.
Kies
Meta-Llama-3.1-405B-Instructimplementeren in de Azure AI Studio-modelcatalogus.U kunt ook de implementatie starten door te beginnen met uw project in AI Studio. Selecteer een project en selecteer vervolgens Deployments>+ Create.
Selecteer op de pagina Details voor
Meta-Llama-3.1-405B-InstructImplementeren en selecteer vervolgens Serverloze API met Azure AI Content Safety.Selecteer het project waarin u uw modellen wilt implementeren. Als u het implementatieaanbod voor betalen per gebruik-model wilt gebruiken, moet uw werkruimte deel uitmaken van de regio VS - oost 2 of Zweden - centraal .
Selecteer in de implementatiewizard de koppeling naar azure Marketplace-voorwaarden voor meer informatie over de gebruiksvoorwaarden. U kunt ook het tabblad Details van marketplace-aanbiedingen selecteren voor meer informatie over prijzen voor het geselecteerde model.
Als dit de eerste keer is dat u het model in het project implementeert, moet u zich abonneren op uw project voor de specifieke aanbieding (bijvoorbeeld
Meta-Llama-3.1-405B-Instruct) van Azure Marketplace. Voor deze stap is vereist dat uw account beschikt over de machtigingen voor het Azure-abonnement en de resourcegroepmachtigingen die worden vermeld in de vereisten. Elk project heeft een eigen abonnement op de specifieke Azure Marketplace-aanbieding, waarmee u uitgaven kunt beheren en bewaken. Selecteer Abonneren en implementeren.Notitie
Als u een project abonneert op een bepaalde Azure Marketplace-aanbieding (in dit geval Meta-Llama-3-70B), moet uw account toegang hebben tot inzender of eigenaar op abonnementsniveau waar het project wordt gemaakt. U kunt ook een aangepaste rol toewijzen aan uw gebruikersaccount met de machtigingen voor het Azure-abonnement en de resourcegroepmachtigingen die worden vermeld in de vereisten.
Nadat u zich hebt geregistreerd voor het project voor de specifieke Azure Marketplace-aanbieding, hoeven volgende implementaties van hetzelfde aanbod in hetzelfde project niet opnieuw te worden geabonneerd. Daarom hoeft u niet over de machtigingen op abonnementsniveau te beschikken voor volgende implementaties. Als dit scenario van toepassing is op u, selecteert u Doorgaan om te implementeren.
Geef de implementatie een naam. Deze naam maakt deel uit van de URL van de implementatie-API. Deze URL moet uniek zijn in elke Azure-regio.
Selecteer Implementeren. Wacht totdat de implementatie gereed is en u wordt omgeleid naar de pagina Implementaties.
Selecteer Openen in speeltuin om te beginnen met interactie met het model.
U kunt terugkeren naar de pagina Implementaties, de implementatie selecteren en de doel-URL van het eindpunt en de geheime sleutel noteren, die u kunt gebruiken om de implementatie aan te roepen en voltooiingen te genereren.
U kunt altijd de details, URL en toegangssleutels van het eindpunt vinden door naar de projectpagina te navigeren en implementaties te selecteren in het linkermenu.
Voor meer informatie over facturering voor Meta Llama-modellen die zijn geïmplementeerd met betalen per gebruik, raadpleegt u Kosten- en quotumoverwegingen voor Llama 3-modellen die als een service zijn geïmplementeerd.




Meta Llama-modellen als een service gebruiken
Modellen die als een service zijn geïmplementeerd, kunnen worden gebruikt met behulp van de chat- of voltooiings-API, afhankelijk van het type model dat u hebt geïmplementeerd.
Selecteer uw project of hub en selecteer vervolgens Implementaties in het linkermenu.
Zoek en selecteer de
Meta-Llama-3.1-405B-Instructimplementatie die u hebt gemaakt.Selecteer Openen in speeltuin.
Selecteer Code weergeven en kopieer de eindpunt-URL en de sleutelwaarde.
Maak een API-aanvraag op basis van het type model dat u hebt geïmplementeerd.
- Voor voltooiingsmodellen, zoals
Meta-Llama-3-8B, gebruikt u de/completionsAPI. - Voor chatmodellen, zoals
Meta-Llama-3.1-405B-Instruct, gebruikt u de/chat/completionsAPI.
Zie de naslagsectie voor meer informatie over het gebruik van de API's.
- Voor voltooiingsmodellen, zoals
Naslaginformatie voor Meta Llama 3.1-modellen die zijn geïmplementeerd als een service
Llama-modellen accepteren zowel de Azure AI-modeldeductie-API op de route /chat/completions of een Llama Chat-API op /v1/chat/completions. Op dezelfde manier kunnen tekstvoltooiingen worden gegenereerd met behulp van de Azure AI-modeldeductie-API op de route /completions of een Llama-voltooiings-API op /v1/completions
Het API-schema voor Azure AI-modeldeductie vindt u in de naslagwerken voor chatvoltooiingen en er kan een OpenAPI-specificatie worden verkregen van het eindpunt zelf.
Voltooiings-API
Gebruik de methode POST om de aanvraag naar de /v1/completions route te verzenden:
Aanvragen
POST /v1/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Aanvraagschema
Payload is een tekenreeks met JSON-indeling die de volgende parameters bevat:
| Sleutel | Type | Default | Beschrijving |
|---|---|---|---|
prompt |
string |
Geen standaardwaarde. Deze waarde moet worden opgegeven. | De prompt om naar het model te verzenden. |
stream |
boolean |
False |
Met streaming kunnen de gegenereerde tokens worden verzonden als gebeurtenissen die alleen door de server worden verzonden wanneer ze beschikbaar zijn. |
max_tokens |
integer |
16 |
Het maximum aantal tokens dat moet worden gegenereerd tijdens de voltooiing. Het tokenaantal van uw prompt plus max_tokens kan de contextlengte van het model niet overschrijden. |
top_p |
float |
1 |
Een alternatief voor steekproeven met temperatuur, zogenaamde kernsampling, waarbij het model rekening houdt met de resultaten van de tokens met top_p waarschijnlijkheidsmassa. 0,1 betekent dus dat alleen de tokens die de top 10% kansdichtheid omvatten, worden beschouwd. Over het algemeen raden we aan om te top_p wijzigen of temperature, maar niet beide. |
temperature |
float |
1 |
De te gebruiken steekproeftemperatuur tussen 0 en 2. Hogere waarden betekenen de modelvoorbeelden breder de distributie van tokens. Nul betekent hebzuchtige steekproeven. We raden u aan dit te wijzigen of top_p, maar niet beide. |
n |
integer |
1 |
Hoeveel voltooiingen moeten worden gegenereerd voor elke prompt. Opmerking: Omdat deze parameter veel voltooiingen genereert, kan deze snel uw tokenquotum gebruiken. |
stop |
array |
null |
Tekenreeks of een lijst met tekenreeksen die het woord bevatten waarin de API stopt met het genereren van verdere tokens. De geretourneerde tekst bevat de stopvolgorde niet. |
best_of |
integer |
1 |
Genereert best_of voltooiingen aan de serverzijde en retourneert de 'beste' (de waarde met de laagste logboekkans per token). Resultaten kunnen niet worden gestreamd. Wanneer gebruikt met n, best_of bepaalt u het aantal voltooiingen van de kandidaat en n geeft u op hoeveel te retourneren–best_of moet groter zijn dan n. Opmerking: Omdat deze parameter veel voltooiingen genereert, kan deze snel uw tokenquotum gebruiken. |
logprobs |
integer |
null |
Een getal dat aangeeft dat de logboekkans op de logprobs meest waarschijnlijke tokens en de gekozen tokens moet worden opgenomen. Als dit bijvoorbeeld logprobs 10 is, retourneert de API een lijst met de 10 meest waarschijnlijke tokens. de API retourneert altijd de logprob van het voorbeeldtoken, dus er kunnen maximaal logprobs+1 elementen in het antwoord zijn. |
presence_penalty |
float |
null |
Getal tussen -2.0 en 2.0. Positieve waarden bestraffen nieuwe tokens op basis van of ze tot nu toe worden weergegeven in de tekst, waardoor de kans op het model groter wordt om over nieuwe onderwerpen te praten. |
ignore_eos |
boolean |
True |
Of u het EOS-token moet negeren en tokens wilt blijven genereren nadat het EOS-token is gegenereerd. |
use_beam_search |
boolean |
False |
Hiermee wordt aangegeven of de zoekfunctie in plaats van steekproeven moet worden gebruikt. In dat geval best_of moet dit groter zijn dan 1 en temperature moet het zijn 0. |
stop_token_ids |
array |
null |
Lijst met id's voor tokens die, wanneer ze worden gegenereerd, verdere tokengeneratie stoppen. De geretourneerde uitvoer bevat de stoptokens, tenzij de stoptokens speciale tokens zijn. |
skip_special_tokens |
boolean |
null |
Of speciale tokens in de uitvoer moeten worden overgeslagen. |
Opmerking
Tekst
{
"prompt": "What's the distance to the moon?",
"temperature": 0.8,
"max_tokens": 512
}
Antwoordschema
De nettolading van het antwoord is een woordenlijst met de volgende velden.
| Sleutel | Type | Description |
|---|---|---|
id |
string |
Een unieke id voor de voltooiing. |
choices |
array |
De lijst met voltooiingskeuzen die het model heeft gegenereerd voor de invoerprompt. |
created |
integer |
De Unix-tijdstempel (in seconden) van het moment waarop de voltooiing is gemaakt. |
model |
string |
De model_id gebruikt voor voltooiing. |
object |
string |
Het objecttype, dat altijd text_completionis. |
usage |
object |
Gebruiksstatistieken voor de voltooiingsaanvraag. |
Tip
In de streamingmodus is voor elk deel van het antwoord finish_reason altijd null, behalve van de laatste die wordt beëindigd door een nettolading [DONE].
Het choices object is een woordenlijst met de volgende velden.
| Sleutel | Type | Description |
|---|---|---|
index |
integer |
Keuzeindex. Wanneer best_of> 1, is de index in deze matrix mogelijk niet in orde en is deze mogelijk niet 0 tot n-1. |
text |
string |
Voltooiingsresultaat. |
finish_reason |
string |
De reden waarom het model geen tokens meer genereert: - stop: het model raakt een natuurlijk stoppunt of een opgegeven stopreeks. - length: als het maximum aantal tokens is bereikt. - content_filter: Wanneer RAI moderatie en CMP dwingt. - content_filter_error: een fout tijdens het toezicht en kon geen beslissing nemen over het antwoord. - null: API-antwoord wordt nog steeds uitgevoerd of onvolledig. |
logprobs |
object |
De logboekkans van de gegenereerde tokens in de uitvoertekst. |
Het usage object is een woordenlijst met de volgende velden.
| Sleutel | Type | Weergegeven als |
|---|---|---|
prompt_tokens |
integer |
Aantal tokens in de prompt. |
completion_tokens |
integer |
Het aantal tokens dat is gegenereerd tijdens de voltooiing. |
total_tokens |
integer |
Totaal aantal tokens. |
Het logprobs object is een woordenlijst met de volgende velden:
| Sleutel | Type | Weergegeven als |
|---|---|---|
text_offsets |
array van integers |
De positie of index van elk token in de voltooiingsuitvoer. |
token_logprobs |
array van float |
Geselecteerd logprobs uit woordenlijst in top_logprobs matrix. |
tokens |
array van string |
Geselecteerde tokens. |
top_logprobs |
array van dictionary |
Matrix van woordenlijst. In elke woordenlijst is de sleutel het token en de waarde is de prob. |
Opmerking
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "text_completion",
"created": 217877,
"choices": [
{
"index": 0,
"text": "The Moon is an average of 238,855 miles away from Earth, which is about 30 Earths away.",
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 7,
"total_tokens": 23,
"completion_tokens": 16
}
}
Chat-API
Gebruik de methode POST om de aanvraag naar de /v1/chat/completions route te verzenden:
Aanvragen
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Aanvraagschema
Payload is een tekenreeks met JSON-indeling die de volgende parameters bevat:
| Sleutel | Type | Default | Beschrijving |
|---|---|---|---|
messages |
string |
Geen standaardwaarde. Deze waarde moet worden opgegeven. | Het bericht of de geschiedenis van berichten die moeten worden gebruikt om het model te vragen. |
stream |
boolean |
False |
Met streaming kunnen de gegenereerde tokens worden verzonden als gebeurtenissen die alleen door de server worden verzonden wanneer ze beschikbaar zijn. |
max_tokens |
integer |
16 |
Het maximum aantal tokens dat moet worden gegenereerd tijdens de voltooiing. Het tokenaantal van uw prompt plus max_tokens kan de contextlengte van het model niet overschrijden. |
top_p |
float |
1 |
Een alternatief voor steekproeven met temperatuur, zogenaamde kernsampling, waarbij het model rekening houdt met de resultaten van de tokens met top_p waarschijnlijkheidsmassa. 0,1 betekent dus dat alleen de tokens die de top 10% kansdichtheid omvatten, worden beschouwd. Over het algemeen raden we aan om te top_p wijzigen of temperature, maar niet beide. |
temperature |
float |
1 |
De te gebruiken steekproeftemperatuur tussen 0 en 2. Hogere waarden betekenen de modelvoorbeelden breder de distributie van tokens. Nul betekent hebzuchtige steekproeven. We raden u aan dit te wijzigen of top_p, maar niet beide. |
n |
integer |
1 |
Hoeveel voltooiingen moeten worden gegenereerd voor elke prompt. Opmerking: Omdat deze parameter veel voltooiingen genereert, kan deze snel uw tokenquotum gebruiken. |
stop |
array |
null |
Tekenreeks of een lijst met tekenreeksen die het woord bevatten waarin de API stopt met het genereren van verdere tokens. De geretourneerde tekst bevat de stopvolgorde niet. |
best_of |
integer |
1 |
Genereert best_of voltooiingen aan de serverzijde en retourneert de 'beste' (de waarde met de laagste logboekkans per token). Resultaten kunnen niet worden gestreamd. Wanneer gebruikt, nbest_of bepaalt u het aantal voltooiingen van de kandidaat en n geeft u op hoeveel te retourneren,best_of moet groter zijn dan n. Opmerking: Omdat deze parameter veel voltooiingen genereert, kan deze snel uw tokenquotum gebruiken. |
logprobs |
integer |
null |
Een getal dat aangeeft dat de logboekkans op de logprobs meest waarschijnlijke tokens en de gekozen tokens moet worden opgenomen. Als dit bijvoorbeeld logprobs 10 is, retourneert de API een lijst met de 10 meest waarschijnlijke tokens. de API retourneert altijd de logprob van het voorbeeldtoken, dus er kunnen maximaal logprobs+1 elementen in het antwoord zijn. |
presence_penalty |
float |
null |
Getal tussen -2.0 en 2.0. Positieve waarden bestraffen nieuwe tokens op basis van of ze tot nu toe worden weergegeven in de tekst, waardoor de kans op het model groter wordt om over nieuwe onderwerpen te praten. |
ignore_eos |
boolean |
True |
Of u het EOS-token moet negeren en tokens wilt blijven genereren nadat het EOS-token is gegenereerd. |
use_beam_search |
boolean |
False |
Hiermee wordt aangegeven of de zoekfunctie in plaats van steekproeven moet worden gebruikt. In dat geval best_of moet dit groter zijn dan 1 en temperature moet het zijn 0. |
stop_token_ids |
array |
null |
Lijst met id's voor tokens die, wanneer ze worden gegenereerd, verdere tokengeneratie stoppen. De geretourneerde uitvoer bevat de stoptokens, tenzij de stoptokens speciale tokens zijn. |
skip_special_tokens |
boolean |
null |
Of speciale tokens in de uitvoer moeten worden overgeslagen. |
Het messages object heeft de volgende velden:
| Sleutel | Type | Weergegeven als |
|---|---|---|
content |
string |
De inhoud van het bericht. Inhoud is vereist voor alle berichten. |
role |
string |
De rol van de auteur van het bericht. Een van system, userof assistant. |
Opmerking
Tekst
{
"messages":
[
{
"role": "system",
"content": "You are a helpful assistant that translates English to Italian."},
{
"role": "user",
"content": "Translate the following sentence from English to Italian: I love programming."
}
],
"temperature": 0.8,
"max_tokens": 512,
}
Antwoordschema
De nettolading van het antwoord is een woordenlijst met de volgende velden.
| Sleutel | Type | Description |
|---|---|---|
id |
string |
Een unieke id voor de voltooiing. |
choices |
array |
De lijst met voltooiingskeuzen die het model heeft gegenereerd voor de invoerberichten. |
created |
integer |
De Unix-tijdstempel (in seconden) van het moment waarop de voltooiing is gemaakt. |
model |
string |
De model_id gebruikt voor voltooiing. |
object |
string |
Het objecttype, dat altijd chat.completionis. |
usage |
object |
Gebruiksstatistieken voor de voltooiingsaanvraag. |
Tip
In de streamingmodus is voor elk deel van het antwoord finish_reason altijd null, behalve van de laatste die wordt beëindigd door een nettolading [DONE]. In elk choices object wordt de sleutel voor messages gewijzigd door delta.
Het choices object is een woordenlijst met de volgende velden.
| Sleutel | Type | Description |
|---|---|---|
index |
integer |
Keuzeindex. Wanneer best_of> 1, is de index in deze matrix mogelijk niet in orde en is dit 0 mogelijk niet.n-1 |
messages of delta |
string |
Voltooiing van chat resulteert in messages object. Wanneer de streamingmodus wordt gebruikt, delta wordt de sleutel gebruikt. |
finish_reason |
string |
De reden waarom het model geen tokens meer genereert: - stop: het model raakt een natuurlijk stoppunt of een meegeleverde stopreeks. - length: als het maximum aantal tokens is bereikt. - content_filter: Wanneer RAI moderatie en CMP dwingt - content_filter_error: een fout tijdens het toezicht en kon geen beslissing nemen over het antwoord - null: API-antwoord wordt nog steeds uitgevoerd of onvolledig. |
logprobs |
object |
De logboekkans van de gegenereerde tokens in de uitvoertekst. |
Het usage object is een woordenlijst met de volgende velden.
| Sleutel | Type | Weergegeven als |
|---|---|---|
prompt_tokens |
integer |
Aantal tokens in de prompt. |
completion_tokens |
integer |
Het aantal tokens dat is gegenereerd tijdens de voltooiing. |
total_tokens |
integer |
Totaal aantal tokens. |
Het logprobs object is een woordenlijst met de volgende velden:
| Sleutel | Type | Weergegeven als |
|---|---|---|
text_offsets |
array van integers |
De positie of index van elk token in de voltooiingsuitvoer. |
token_logprobs |
array van float |
Geselecteerd logprobs uit woordenlijst in top_logprobs matrix. |
tokens |
array van string |
Geselecteerde tokens. |
top_logprobs |
array van dictionary |
Matrix van woordenlijst. In elke woordenlijst is de sleutel het token en de waarde is de prob. |
Opmerking
Hier volgt een voorbeeld van een respons:
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "chat.completion",
"created": 2012359,
"model": "",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Sure, I\'d be happy to help! The translation of ""I love programming"" from English to Italian is:\n\n""Amo la programmazione.""\n\nHere\'s a breakdown of the translation:\n\n* ""I love"" in English becomes ""Amo"" in Italian.\n* ""programming"" in English becomes ""la programmazione"" in Italian.\n\nI hope that helps! Let me know if you have any other sentences you\'d like me to translate."
}
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 40,
"completion_tokens": 30
}
}
Meta Llama-modellen implementeren voor beheerde compute
Naast de implementatie met de beheerde service betalen per gebruik, kunt u ook Meta Llama 3.1-modellen implementeren voor beheerde berekeningen in AI Studio. Wanneer deze is geïmplementeerd voor beheerde compute, kunt u alle details selecteren over de infrastructuur waarop het model wordt uitgevoerd, inclusief de virtuele machines die moeten worden gebruikt en het aantal instanties dat moet worden verwerkt voor de belasting die u verwacht. Modellen die zijn geïmplementeerd voor beheerde berekeningen verbruiken quotum van uw abonnement. De volgende modellen uit de releasegolf 3.1 zijn beschikbaar op beheerde compute:
Meta-Llama-3.1-8B-Instruct(FT ondersteund)Meta-Llama-3.1-70B-Instruct(FT ondersteund)Meta-Llama-3.1-8B(FT ondersteund)Meta-Llama-3.1-70B(FT ondersteund)Llama Guard 3 8BPrompt Guard
Volg deze stappen om een model te implementeren, zoals Meta-Llama-3.1-70B-Instruct een beheerd rekenproces in Azure AI Studio.
Kies het model dat u wilt implementeren vanuit de Azure AI Studio-modelcatalogus.
U kunt ook de implementatie starten door te beginnen met uw project in AI Studio. Selecteer uw project en selecteer vervolgens Deployments>+ Create.
Selecteer Implementeren naast de knop Licentie weergeven op de pagina Details van het model.
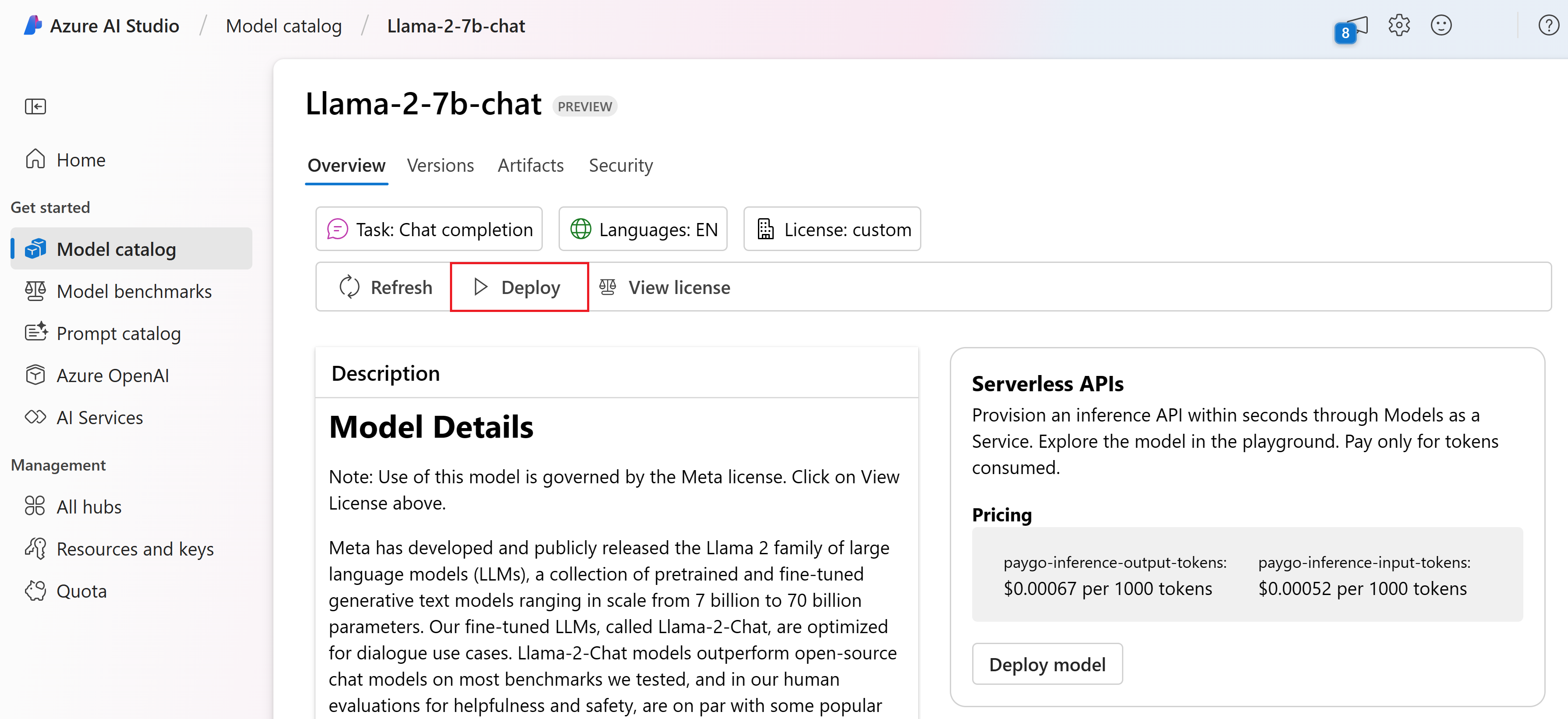
Selecteer op de pagina Implementeren met Azure AI Content Safety (preview) de optie Overslaan van Azure AI-inhoudsveiligheid , zodat u het model kunt blijven implementeren met behulp van de gebruikersinterface.
Tip
Over het algemeen wordt u aangeraden Azure AI Content Safety inschakelen (aanbevolen) te selecteren voor de implementatie van het Llama-model. Deze implementatieoptie wordt momenteel alleen ondersteund met behulp van de Python SDK en vindt plaats in een notebook.
Selecteer Doorgaan.
Selecteer het project waar u een implementatie wilt maken.
Tip
Als u onvoldoende quotum beschikbaar hebt in het geselecteerde project, kunt u de optie gebruiken die ik wil gebruiken voor gedeeld quotum en ik bevestig dat dit eindpunt over 168 uur wordt verwijderd.
Selecteer de virtuele machine en het aantal exemplaren dat u wilt toewijzen aan de implementatie.
Selecteer of u deze implementatie wilt maken als onderdeel van een nieuw eindpunt of een bestaand eindpunt. Eindpunten kunnen meerdere implementaties hosten terwijl resourceconfiguratie exclusief blijft voor elk van deze implementaties. Implementaties onder hetzelfde eindpunt delen de eindpunt-URI en de bijbehorende toegangssleutels.
Geef aan of u het verzamelen van gegevens deductie wilt inschakelen (preview).
Selecteer Implementeren. Na enkele ogenblikpen wordt de pagina Details van het eindpunt geopend.
Wacht tot het maken en implementeren van het eindpunt is voltooid. Deze stap kan enkele minuten duren.
Selecteer het tabblad Verbruik van de implementatie om codevoorbeelden te verkrijgen die kunnen worden gebruikt om het geïmplementeerde model in uw toepassing te gebruiken.

Llama 2-modellen gebruiken die zijn geïmplementeerd voor beheerde rekenkracht
Zie de kaart van het model in de Azure AI Studio-modelcatalogus voor naslaginformatie over het aanroepen van Llama-modellen die zijn geïmplementeerd voor beheerde berekeningen. De kaart van elk model heeft een overzichtspagina met een beschrijving van het model, voorbeelden voor op code gebaseerde deductie, afstemming en modelevaluatie.
Meer deductievoorbeelden
| Pak | Sample notebook |
|---|---|
| CLI met behulp van CURL- en Python-webaanvragen | webrequests.ipynb |
| OpenAI SDK (experimenteel) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| LiteLLM SDK | litellm.ipynb |
Kosten en quota
Kosten- en quotumoverwegingen voor Meta Llama 3.1-modellen die zijn geïmplementeerd als een service
Meta Llama 3.1-modellen die als een service zijn geïmplementeerd, worden aangeboden door Meta via Azure Marketplace en geïntegreerd met Azure AI Studio voor gebruik. U vindt de prijzen van Azure Marketplace bij het implementeren of verfijnen van de modellen.
Telkens wanneer een project zich abonneert op een bepaalde aanbieding vanuit Azure Marketplace, wordt er een nieuwe resource gemaakt om de kosten te traceren die zijn gekoppeld aan het verbruik. Dezelfde resource wordt gebruikt om de kosten te traceren die zijn gekoppeld aan deductie en verfijning; er zijn echter meerdere meters beschikbaar om elk scenario onafhankelijk te traceren.
Zie Monitoring van kosten voor modellen die worden aangeboden in de Azure Marketplace voor meer informatie over het traceren van kosten.

Het quotum wordt beheerd per implementatie. Elke implementatie heeft een frequentielimiet van 400.000 tokens per minuut en 1000 API-aanvragen per minuut. Momenteel beperken we echter tot één implementatie per model per project. Neem contact op met de ondersteuning voor Microsoft Azure als de huidige frequentielimieten niet voldoende zijn voor uw scenario's.
Overwegingen voor kosten en quota voor Meta Llama 3.1-modellen die zijn geïmplementeerd als beheerde rekenkracht
Voor implementatie en deductie van Meta Llama 3.1-modellen met beheerde rekenkracht gebruikt u het kernquotum voor virtuele machines (VM) dat per regio aan uw abonnement is toegewezen. Wanneer u zich registreert voor Azure AI Studio, ontvangt u een standaard-VM-quotum voor verschillende VM-families die beschikbaar zijn in de regio. U kunt implementaties blijven maken totdat u de quotumlimiet bereikt. Zodra u deze limiet hebt bereikt, kunt u een quotumverhoging aanvragen.
Inhoud filteren
Modellen die zijn geïmplementeerd als een serverloze API met betalen per gebruik, worden beveiligd door Azure AI Content Safety. Wanneer deze optie is geïmplementeerd voor beheerde berekeningen, kunt u zich afmelden voor deze mogelijkheid. Als de veiligheid van Azure AI-inhoud is ingeschakeld, passeren zowel de prompt als de voltooiing een ensemble van classificatiemodellen die zijn gericht op het detecteren en voorkomen van de uitvoer van schadelijke inhoud. Het inhoudsfiltersysteem detecteert en onderneemt actie op specifieke categorieën van mogelijk schadelijke inhoud in zowel invoerprompts als uitvoervoltooiingen. Meer informatie over Azure AI Content Safety.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor