Aangepaste modellen voor Document Intelligence
Belangrijk
- Openbare preview-versies van Document Intelligence bieden vroegtijdige toegang tot functies die actief zijn in ontwikkeling.
- Functies, benaderingen en processen kunnen veranderen, vóór algemene beschikbaarheid (GA), op basis van feedback van gebruikers.
- De openbare preview-versie van Document Intelligence-clientbibliotheken is standaard ingesteld op REST API-versie 2024-02-29-preview.
- Openbare preview-versie 2024-02-29-preview is momenteel alleen beschikbaar in de volgende Azure-regio's:
- VS - oost
- VS - west 2
- Europa -west
Deze inhoud is van toepassing op:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Deze inhoud is van toepassing op:![]() v3.1 (GA) | Nieuwste versie:
v3.1 (GA) | Nieuwste versie:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.0
v3.0![]() v2.1
v2.1
Deze inhoud is van toepassing op:![]() v3.0 (GA) | Nieuwste versies:
v3.0 (GA) | Nieuwste versies:![]() v4.0 (preview)
v4.0 (preview)![]() v3.1 | Vorige versie:
v3.1 | Vorige versie:![]() v2.1
v2.1
Deze inhoud is van toepassing op:![]() v2.1 | Nieuwste versie:
v2.1 | Nieuwste versie:![]() v4.0 (preview)
v4.0 (preview)
Document Intelligence maakt gebruik van geavanceerde machine learning-technologie voor het identificeren van documenten, het detecteren en extraheren van informatie uit formulieren en documenten en het retourneren van de geëxtraheerde gegevens in een gestructureerde JSON-uitvoer. Met Document Intelligence kunt u documentanalysemodellen gebruiken, vooraf gebouwd/vooraf getraind of uw getrainde, zelfstandige aangepaste modellen.
Aangepaste modellen bevatten nu aangepaste classificatiemodellen voor scenario's waarin u het documenttype moet identificeren voordat u het extractiemodel aanroept. Classificatiemodellen zijn beschikbaar vanaf de 2023-07-31 (GA) API. Een classificatiemodel kan worden gekoppeld aan een aangepast extractiemodel om velden te analyseren en te extraheren uit formulieren en documenten die specifiek zijn voor uw bedrijf om een oplossing voor documentverwerking te maken. Zelfstandige aangepaste extractiemodellen kunnen worden gecombineerd om samengestelde modellen te maken.
Aangepaste documentmodeltypen
Aangepaste documentmodellen kunnen een van de twee typen zijn, een aangepaste sjabloon of aangepast formulier en aangepaste neurale of aangepaste documentmodellen. Het label- en trainingsproces voor beide modellen is identiek, maar de modellen verschillen als volgt:
Aangepaste extractiemodellen
Als u een aangepast extractiemodel wilt maken, labelt u een gegevensset met documenten met de waarden die u wilt ophalen en traint u het model op de gelabelde gegevensset. U hebt slechts vijf voorbeelden van hetzelfde formulier of documenttype nodig om aan de slag te gaan.
Aangepast neuraal model
Belangrijk
Vanaf versie 4.0 — 2024-02-29-preview-API ondersteunen aangepaste neurale modellen nu overlappende velden en tabellen, rij- en celniveauvertrouwen.
Het aangepaste neurale model (aangepast document) maakt gebruik van Deep Learning-modellen en basismodel dat is getraind op een grote verzameling documenten. Dit model wordt vervolgens nauwkeurig afgestemd of aangepast aan uw gegevens wanneer u het model traint met een gelabelde gegevensset. Aangepaste neurale modellen ondersteunen gestructureerde, semi-gestructureerde en ongestructureerde documenten om velden te extraheren. Aangepaste neurale modellen ondersteunen momenteel Engelstalige documenten. Wanneer u kiest tussen de twee modeltypen, begint u met een neuraal model om te bepalen of het voldoet aan uw functionele behoeften. Zie neurale modellen voor meer informatie over aangepaste documentmodellen.
Aangepast sjabloonmodel
De aangepaste sjabloon of het aangepaste formuliermodel is afhankelijk van een consistente visuele sjabloon om de gelabelde gegevens te extraheren. Afwijkingen in de visuele structuur van uw documenten zijn van invloed op de nauwkeurigheid van uw model. Gestructureerde formulieren, zoals vragenlijsten of toepassingen, zijn voorbeelden van consistente visuele sjablonen.
Uw trainingsset bestaat uit gestructureerde documenten waarbij de opmaak en indeling statisch en constant zijn van het ene documentexemplaren naar het volgende. Aangepaste sjabloonmodellen ondersteunen sleutel-waardeparen, selectiemarkeringen, tabellen, handtekeningvelden en regio's. Sjabloonmodellen en kunnen worden getraind op documenten in een van de ondersteunde talen. Zieaangepaste sjabloonmodellen voor meer informatie.
Als de taal van uw documenten en extractiescenario's aangepaste neurale modellen ondersteunt, raden we u aan aangepaste neurale modellen te gebruiken voor sjabloonmodellen voor een hogere nauwkeurigheid.
Tip
Als u wilt controleren of uw trainingsdocumenten een consistente visuele sjabloon bevatten, verwijdert u alle door de gebruiker ingevoerde gegevens uit elk formulier in de set. Als de lege formulieren identiek zijn in uiterlijk, vertegenwoordigen ze een consistente visuele sjabloon.
ZieDe nauwkeurigheid en betrouwbaarheid van aangepaste modellen interpreteren en verbeteren voor meer informatie.
Vereisten voor invoer
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen:
Model PDF Afbeelding:
jpeg/jpg, png, bmp, tiff, heifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Read ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview en hoger) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ ✱ Microsoft Office-bestanden worden momenteel niet ondersteund voor andere modellen of versies.
Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een gratis abonnement worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en 4 MB gratis (F0).
De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer
8-punttekst op 150 punten per inch.Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en 1G-MB voor het neurale model.
Voor het trainen van aangepast classificatiemodel is
1GBde totale grootte van trainingsgegevens maximaal 10.000 pagina's.
Buildmodus
Met de bewerking Aangepast model bouwen wordt ondersteuning toegevoegd voor de sjabloon en neurale aangepaste modellen. Vorige versies van de REST API en clientbibliotheken ondersteunden slechts één buildmodus die nu de sjabloonmodus wordt genoemd.
Sjabloonmodellen accepteren alleen documenten met dezelfde basispaginastructuur( een uniform uiterlijk) of dezelfde relatieve positie van elementen in het document.
Neurale modellen ondersteunen documenten met dezelfde informatie, maar verschillende paginastructuren. Voorbeelden van deze documenten zijn Verenigde Staten W2-formulieren, die dezelfde informatie delen, maar verschillen in uiterlijk tussen bedrijven. Neurale modellen ondersteunen momenteel alleen Engelse tekst.
Deze tabel bevat koppelingen naar de SDK-verwijzingen en codevoorbeelden voor de programmeertaal voor de buildmodus op GitHub:
| Programmeertaal | SDK-naslaginformatie | Voorbeeld van code |
|---|---|---|
| C#/.NET | DocumentBuildMode Struct | Sample_BuildCustomModelAsync.cs |
| Java | Klasse DocumentBuildMode | BuildModel.java |
| JavaScript | Type DocumentBuildMode | buildModel.js |
| Python | DocumentBuildMode Enum | sample_build_model.py |
Modelfuncties vergelijken
In de volgende tabel worden aangepaste sjabloon- en aangepaste neurale functies vergeleken:
| Functie | Aangepaste sjabloon (formulier) | Aangepast neuraal (document) |
|---|---|---|
| Documentstructuur | Sjabloon, formulier en gestructureerd | Gestructureerd, semi-gestructureerd en ongestructureerd |
| Trainingstijd | 1 tot 5 minuten | 20 minuten tot 1 uur |
| Gegevensextractie | Sleutel-waardeparen, tabellen, selectiemarkeringen, coördinaten en handtekeningen | Sleutel-waardeparen, selectiemarkeringen en tabellen |
| Overlappende velden | Niet ondersteund | Ondersteund |
| Documentvariaties | Vereist een model per variatie | Maakt gebruik van één model voor alle variaties |
| Taalondersteuning | Ondersteuning voor meerdere talen | Engels, met preview-ondersteuning voor Ondersteuning voor Spaans, Frans, Duits, Italiaans en Nederlands |
Aangepast classificatiemodel
Documentclassificatie is een nieuw scenario dat wordt ondersteund door Document Intelligence met de 2023-07-31 (v3.1 GA) API. De API voor documentclassificatie ondersteunt classificatie- en splitsingsscenario's. Train een classificatiemodel om de verschillende typen documenten te identificeren die uw toepassing ondersteunt. Het invoerbestand voor het classificatiemodel kan meerdere documenten bevatten en elk document in een gekoppeld paginabereik classificeren. Zieaangepaste classificatiemodellen voor meer informatie.
Notitie
Vanaf de 2024-02-29-preview API-versie wordt documentclassificatie nu ondersteund voor Office-documenttypen voor classificatie. Deze API-versie introduceert ook incrementele training voor het classificatiemodel.
Aangepaste modelhulpprogramma's
Document Intelligence v3.1- en hogermodellen ondersteunen de volgende hulpprogramma's, toepassingen en bibliotheken, programma's en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| Aangepast model | • Document Intelligence Studio • REST API • C# SDK • Python SDK |
custom-model-id |
Document Intelligence v2.1 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
Notitie
Aangepaste modeltypen aangepaste neurale en aangepaste sjablonen zijn beschikbaar met Document Intelligence versie v3.1 en v3.0 API's.
| Functie | Resources |
|---|---|
| Aangepast model | • Hulpprogramma voor documentinformatielabels• REST API • Clientbibliotheek SDK • Document Intelligence Docker-container |
Een aangepast model bouwen
Gegevens extraheren uit uw specifieke of unieke documenten met behulp van aangepaste modellen. U hebt de volgende resources nodig:
Een Azure-abonnement. U kunt er gratis een maken.
Een Document Intelligence-exemplaar in Azure Portal. U kunt de gratis prijscategorie (
F0) gebruiken om de service te proberen. Nadat uw resource is geïmplementeerd, selecteert u Ga naar de resource om uw sleutel en eindpunt op te halen.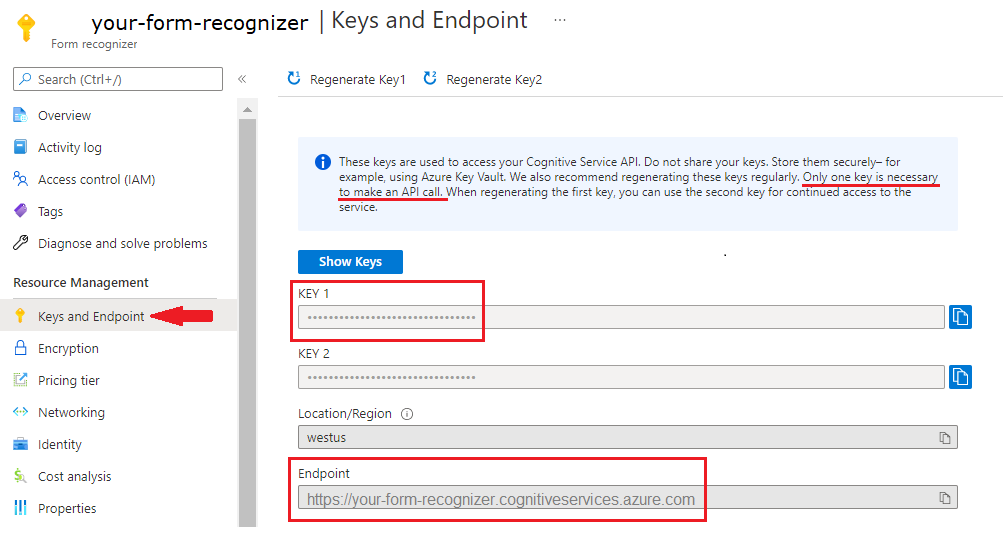
Voorbeeldhulpprogramma voor labelen
Tip
- Voor een verbeterde ervaring en geavanceerde modelkwaliteit kunt u Document Intelligence v3.0 Studio gebruiken.
- V3.0 Studio ondersteunt elk model dat is getraind met v2.1 gelabelde gegevens.
- Raadpleeg de API-migratiehandleiding voor gedetailleerde informatie over het migreren van v2.1 naar v3.0.
- Bekijk onze quickstarts voor REST API of C#, Java, JavaScript of Python SDK om aan de slag te gaan met de versie v3.0.
Het hulpprogramma Document Intelligence Sample Labeling is een opensource-hulpprogramma waarmee u de nieuwste functies van OCR-functies (Document Intelligence en Optical Character Recognition) kunt testen.
Probeer de quickstart voor het voorbeeldhulpprogramma voor labelen om aan de slag te gaan met het bouwen en gebruiken van een aangepast model.
Document Intelligence Studio
Notitie
Document Intelligence Studio is beschikbaar met v3.1- en v3.0-API's.
Selecteer aangepaste extractiemodellen op de startpagina van Document Intelligence Studio.
Selecteer onder Mijn projecten de optie Een project maken.
Vul de velden met projectdetails in.
Configureer de serviceresource door uw Opslagaccount en Blob-container toe te voegen aan Verbinding maken uw trainingsgegevensbron.
Controleer en maak uw project.
Voeg uw voorbeelddocumenten toe om uw aangepaste model te labelen, te bouwen en te testen.
Zie Een aangepast extractiemodel maken voor een gedetailleerd overzicht van het maken van uw eerste aangepaste extractiemodel.
Samenvatting van aangepaste modelextractie
In deze tabel worden de ondersteunde gebieden voor gegevensextractie vergeleken:
| Model | Formuliervelden | Selectiemarkeringen | Gestructureerde velden (tabellen) | Handtekening | Regiolabels | Overlappende velden |
|---|---|---|---|---|---|---|
| Sjabloon Aangepast | ✔ | ✔ | ✔ | ✔ | ✔ | N/a |
| Aangepaste neurale | ✔ | ✔ | ✔ | N/a | * | ✔ (2024-02-29-preview) |
Tabelsymbolen:
✔ — Ondersteund
**n/a— Momenteel niet beschikbaar;
*-Gedraagt zich anders, afhankelijk van het model. Met sjabloonmodellen worden synthetische gegevens gegenereerd tijdens de training. Bij neurale modellen wordt het afsluiten van tekst die in de regio wordt herkend, geselecteerd.
Tip
Wanneer u kiest tussen de twee modeltypen, begint u met een aangepast neuraal model als deze voldoet aan uw functionele behoeften. Zie aangepaste neurale gegevens voor meer informatie over aangepaste neurale modellen.
Opties voor het ontwikkelen van aangepaste modellen
In de volgende tabel worden de functies beschreven die beschikbaar zijn met de bijbehorende hulpprogramma's en clientbibliotheken. Als best practice moet u ervoor zorgen dat u de compatibele hulpprogramma's gebruikt die hier worden vermeld.
| Documenttype | REST-API | SDK | Modellen labelen en testen |
|---|---|---|---|
| Aangepaste sjabloon v 4.0 v3.1 v3.0 | Document Intelligence 3.1 | Document Intelligence SDK | Document Intelligence Studio |
| Aangepaste neurale v4.0 v3.1 v3.0 | Document Intelligence 3.1 | Document Intelligence SDK | Document Intelligence Studio |
| Aangepast formulier v2.1 | Document Intelligence 2.1 GA API | Document Intelligence SDK | Voorbeeldhulpprogramma voor labelen |
Notitie
Aangepaste sjabloonmodellen die zijn getraind met de 3.0-API, hebben enkele verbeteringen ten opzichte van de 2.1-API die afkomstig zijn van verbeteringen in de OCR-engine. Gegevenssets die worden gebruikt om een aangepast sjabloonmodel te trainen met behulp van de 2.1-API, kunnen nog steeds worden gebruikt om een nieuw model te trainen met behulp van de 3.0-API.
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen zijn JPEG/JPG, PNG, BMP, TIFF en PDF (ingesloten of gescand). PDF-bestanden met ingesloten tekst hebben de voorkeur omdat hier geen fouten optreden met locatie en extractie van tekens.
Voor PDF- en TIFF-bestanden kunnen maximaal 2000 pagina's worden verwerkt. Met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt.
De bestandsgrootte moet kleiner zijn dan 500 MB voor betaalde laag (S0) en 4 MB gratis (F0).
De afmetingen van afbeeldingen moeten tussen 50 x 50 en 10.000 x 10.000 pixels liggen.
PDF-afmetingen zijn maximaal 17 x 17 inch, overeenkomend met Legal of A3 papierformaat of kleiner.
De totale grootte van de trainingsgegevens is 500 pagina's of minder.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
Tip
Trainingsgegevens:
- Gebruik indien mogelijk PDF-documenten op basis van tekst in plaats van op afbeeldingen gebaseerde documenten. Gescande PDF-bestanden worden verwerkt als afbeeldingen.
- Geef slechts één exemplaar van het formulier per document op.
- Gebruik voor ingevulde formulieren voorbeelden waarin al hun velden zijn ingevuld.
- Gebruik in formulieren met in elk veld verschillende waarden.
- Als uw formulierafbeeldingen van lagere kwaliteit zijn, gebruikt u een grotere gegevensset. Gebruik bijvoorbeeld 10 tot 15 afbeeldingen.
Ondersteunde talen en landinstellingen
Zie onze pagina Taalondersteuning: aangepaste modellen voor een volledige lijst met ondersteunde talen.
Volgende stappen
Probeer uw eigen formulieren en documenten te verwerken met het hulpprogramma Document Intelligence Sample Labeling.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.
Probeer uw eigen formulieren en documenten te verwerken met Document Intelligence Studio.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.