Een aangepast extractiemodel bouwen en trainen
Deze inhoud is van toepassing op:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1
v2.1
Document Intelligence-modellen vereisen slechts vijf trainingsdocumenten om aan de slag te gaan. Als u ten minste vijf documenten hebt, kunt u aan de slag met het trainen van een aangepast model. U kunt een aangepast sjabloonmodel (aangepast formulier) of een aangepast neuraal model (aangepast document) trainen. Het trainingsproces is identiek voor beide modellen en dit document begeleidt u bij het trainen van beide modellen.
Vereisten voor aangepaste modelinvoer
Zorg er eerst voor dat uw trainingsgegevensset voldoet aan de invoervereisten voor Document Intelligence.
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen:
Model PDF Afbeelding:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) en HTMLRead ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ (2024-02-29-preview) Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en 4 MB gratis (F0).
De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer
8-punttekst op 150 punten per inch (DPI).Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en 1G-MB voor het neurale model.
Voor het trainen van aangepast classificatiemodel is
1GBde totale grootte van trainingsgegevens maximaal 10.000 pagina's.
Tips voor trainingsgegevens
Volg deze tips om uw gegevensset verder te optimaliseren voor training:
- Gebruik pdf-documenten op basis van tekst in plaats van op afbeeldingen gebaseerde documenten. Gescande PDF-bestanden worden verwerkt als afbeeldingen.
- Gebruik voorbeelden met alle velden die zijn ingevuld voor formulieren met invoervelden.
- Gebruik in formulieren met in elk veld verschillende waarden.
- Gebruik een grotere gegevensset (10-15 afbeeldingen) als uw formulierafbeeldingen van lagere kwaliteit zijn.
Uw trainingsgegevens uploaden
Zodra u een set formulieren of documenten voor training hebt verzameld, moet u deze uploaden naar een Azure Blob Storage-container. Als u niet weet hoe u een Azure-opslagaccount maakt met een container, volgt u de quickstart voor Azure Storage voor Azure Portal. U kunt de gratis prijscategorie (F0) gebruiken om de service uit te proberen en later upgraden naar een betaalde laag voor productie.
Video: Uw aangepaste model trainen
- Zodra u uw trainingsgegevensset hebt verzameld en geüpload, bent u klaar om uw aangepaste model te trainen. In de volgende video maken we een project en verkennen we enkele basisprincipes voor het labelen en trainen van een model.
Een project maken in Document Intelligence Studio
Document Intelligence Studio biedt en organiseert alle API-aanroepen die nodig zijn om uw gegevensset te voltooien en uw model te trainen.
Ga eerst naar Document Intelligence Studio. De eerste keer dat u Studio gebruikt, moet u uw abonnement, resourcegroep en resource initialiseren. Volg vervolgens de vereisten voor aangepaste projecten om de Studio te configureren voor toegang tot uw trainingsgegevensset.
Selecteer in Studio de tegel Aangepaste modellen , op de pagina aangepaste modellen en selecteer de knop Een project maken.

Geef in het dialoogvenster Project maken een naam op voor uw project, eventueel een beschrijving en selecteer Doorgaan.
Kies of maak in de volgende stap in de werkstroom een Document Intelligence-resource voordat u doorgaan selecteert.
Belangrijk
Aangepaste neurale modellen zijn slechts in een paar regio's beschikbaar. Als u van plan bent een neuraal model te trainen, selecteert of maakt u een resource in een van deze ondersteunde regio's.
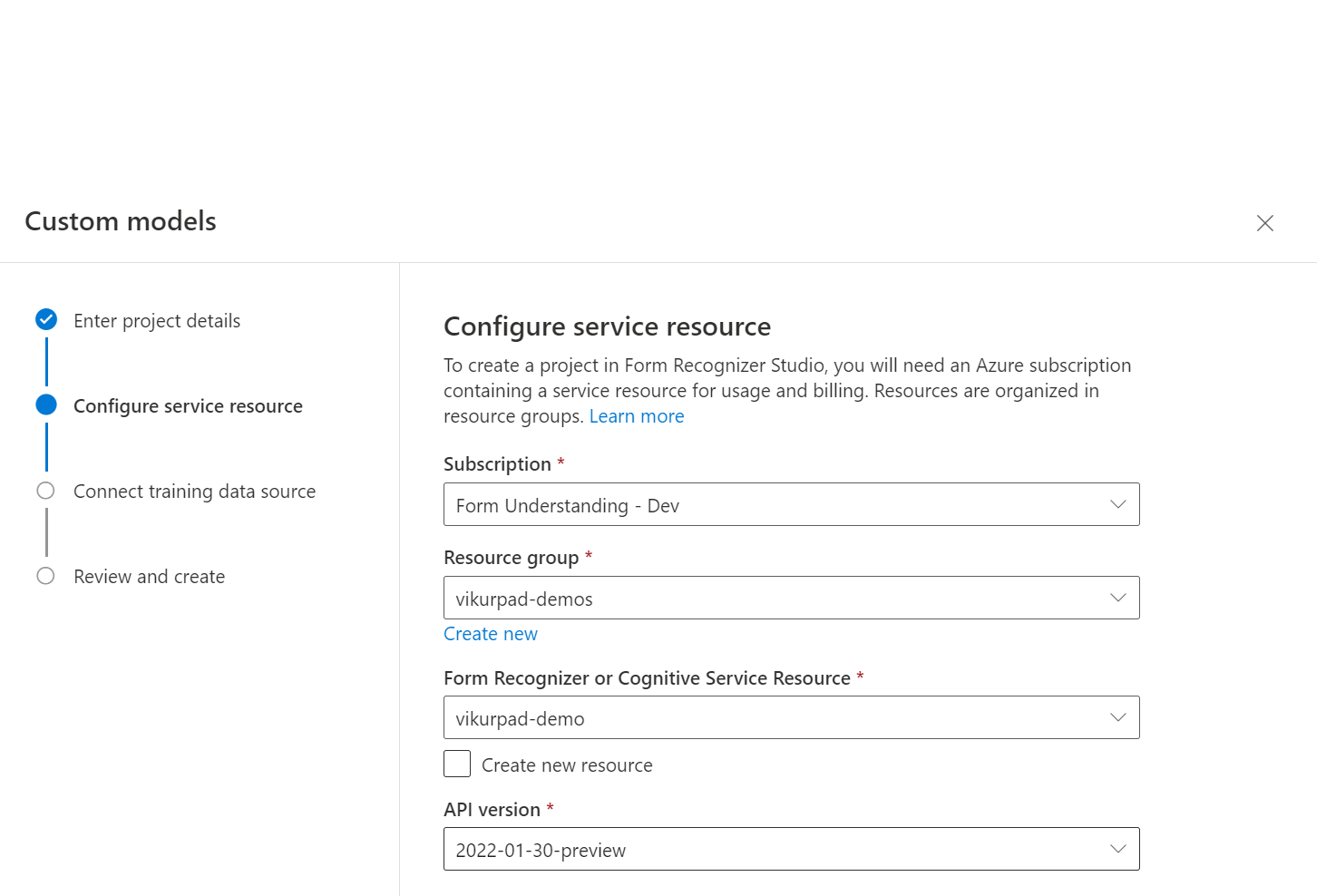
Selecteer vervolgens het opslagaccount dat u hebt gebruikt om uw aangepaste modeltrainingsgegevensset te uploaden. Het pad Map moet leeg zijn als uw trainingsdocumenten zich in de hoofdmap van de container bevinden. Als uw documenten zich in een submap bevinden, voert u het relatieve pad uit de hoofdmap van de container in het padveld Map in. Zodra uw opslagaccount is geconfigureerd, selecteert u Doorgaan.
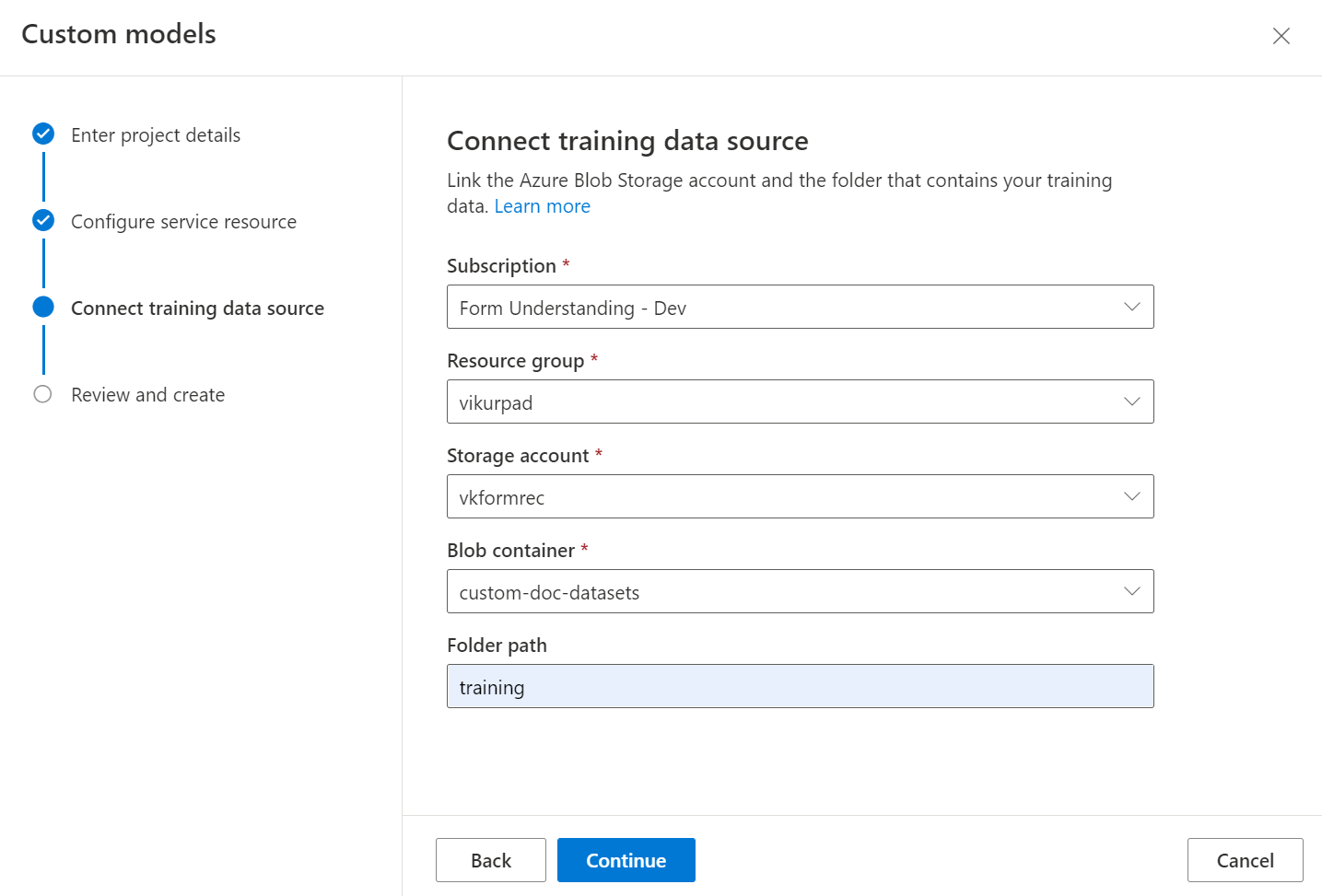
Controleer ten slotte de projectinstellingen en selecteer Project maken om een nieuw project te maken. U moet nu in het labelvenster staan en de bestanden in de lijst met gegevenssets zien.
Uw gegevens labelen
In uw project is uw eerste taak het labelen van uw gegevensset met de velden die u wilt extraheren.
De bestanden die u naar de opslag hebt geüpload, worden links van het scherm weergegeven, met het eerste bestand dat klaar is om te worden gelabeld.
Begin met het labelen van uw gegevensset en het maken van uw eerste veld door de plusknop (➕) in de rechterbovenhoek van het scherm te selecteren.
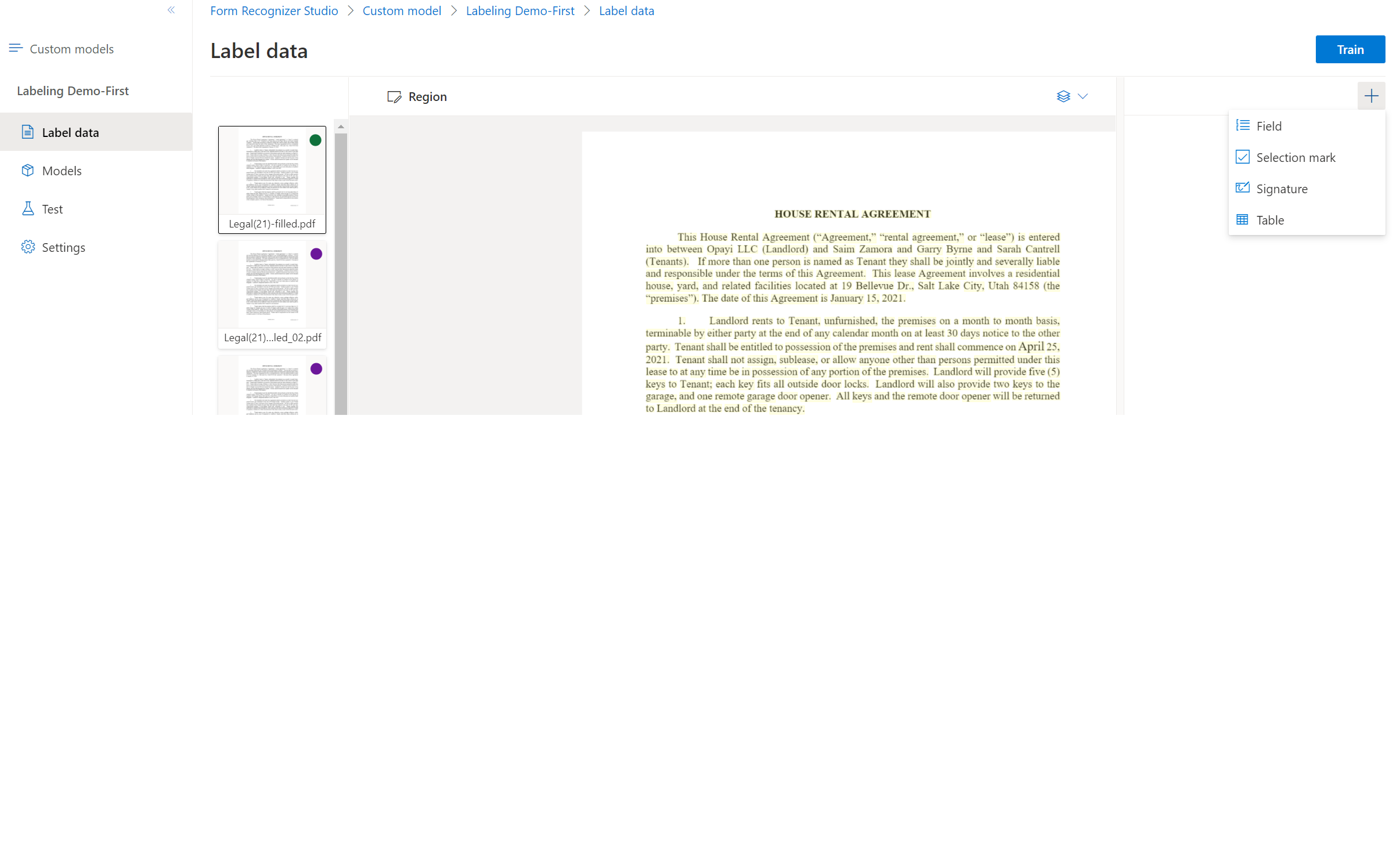
Voer een naam in voor het veld.
Wijs een waarde toe aan het veld door een woord of woorden in het document te kiezen. Selecteer het veld in de vervolgkeuzelijst of de lijst met velden op de rechternavigatiebalk. De gelabelde waarde bevindt zich onder de veldnaam in de lijst met velden.
Herhaal het proces voor alle velden die u wilt labelen voor uw gegevensset.
Label de resterende documenten in uw gegevensset door elk document te selecteren en de tekst te selecteren die moet worden gelabeld.
U hebt nu alle documenten in uw gegevensset gelabeld. De .labels.json - en .ocr.json-bestanden komen overeen met elk document in uw trainingsgegevensset en een nieuw fields.json-bestand. Deze trainingsgegevensset wordt verzonden om het model te trainen.
Uw model trainen
Nu uw gegevensset is gelabeld, kunt u uw model trainen. Selecteer de knop Trainen in de rechterbovenhoek.
Geef in het dialoogvenster trainmodel een unieke model-id en eventueel een beschrijving op. De model-id accepteert een gegevenstype tekenreeks.
Selecteer voor de buildmodus het type model dat u wilt trainen. Meer informatie over de modeltypen en mogelijkheden.
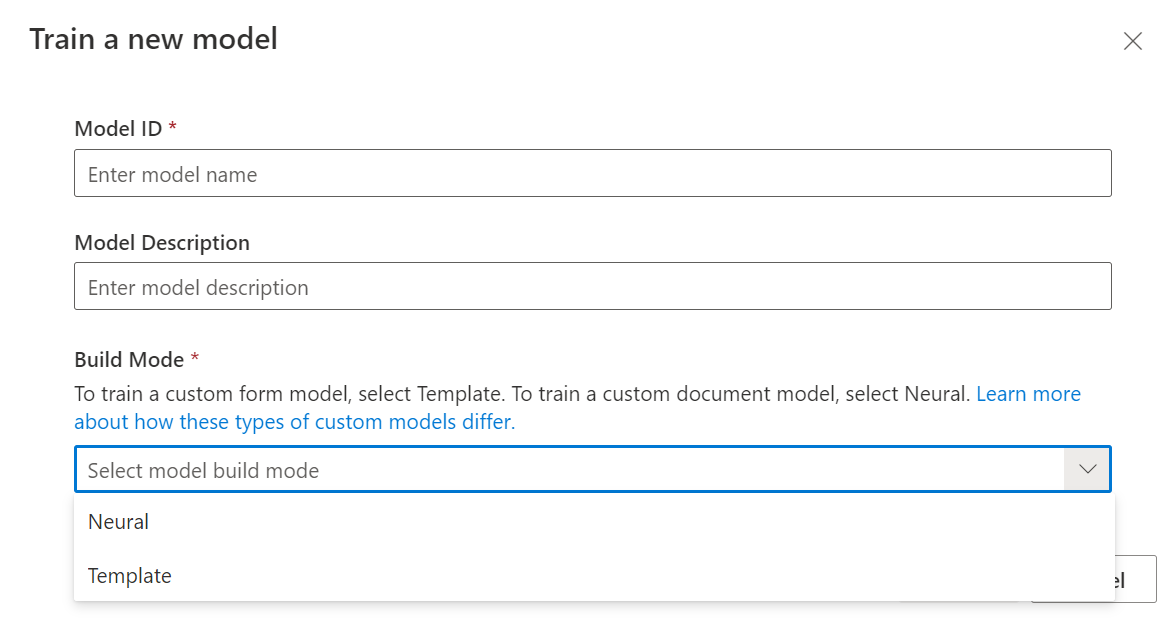
Selecteer Trainen om het trainingsproces te starten.
Sjabloonmodellen trainen over een paar minuten. Het kan tot 30 minuten duren voordat neurale modellen zijn getraind.
Navigeer naar het menu Modellen om de status van de treinbewerking weer te geven.
Het model testen
Zodra de modeltraining is voltooid, kunt u uw model testen door het model te selecteren op de pagina met de modellenlijst.
Selecteer het model en selecteer op de knop Testen .
Selecteer de
+ Addknop om een bestand te selecteren om het model te testen.Als een bestand is geselecteerd, kiest u de knop Analyseren om het model te testen.
De modelresultaten worden weergegeven in het hoofdvenster en de geëxtraheerde velden worden weergegeven in de rechternavigatiebalk.
Valideer uw model door de resultaten voor elk veld te evalueren.
De rechternavigatiebalk bevat ook de voorbeeldcode om uw model aan te roepen en de JSON-resultaten van de API.
Gefeliciteerd met het trainen van een aangepast model in Document Intelligence Studio. Uw model is klaar voor gebruik met de REST API of de SDK om documenten te analyseren.
Van toepassing op:![]() v2.1. Andere versies:v3.0
v2.1. Andere versies:v3.0
Wanneer u het aangepaste Document Intelligence-model gebruikt, geeft u uw eigen trainingsgegevens op voor de bewerking Aangepast model trainen, zodat het model kan trainen naar uw branchespecifieke formulieren. Volg deze handleiding om te leren hoe u gegevens verzamelt en voorbereidt om het model effectief te trainen.
U hebt ten minste vijf ingevulde formulieren van hetzelfde type nodig.
Als u handmatig gelabelde trainingsgegevens wilt gebruiken, moet u beginnen met ten minste vijf ingevulde formulieren van hetzelfde type. U kunt nog steeds niet-gelabelde formulieren gebruiken naast de vereiste gegevensset.
Vereisten voor aangepaste modelinvoer
Zorg er eerst voor dat uw trainingsgegevensset voldoet aan de invoervereisten voor Document Intelligence.
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen:
Model PDF Afbeelding:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) en HTMLRead ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ (2024-02-29-preview) Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en 4 MB gratis (F0).
De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer
8-punttekst op 150 punten per inch (DPI).Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en 1G-MB voor het neurale model.
Voor het trainen van aangepast classificatiemodel is
1GBde totale grootte van trainingsgegevens maximaal 10.000 pagina's.
Tips voor trainingsgegevens
Volg deze tips om uw gegevensset verder te optimaliseren voor training.
- Gebruik pdf-documenten op basis van tekst in plaats van op afbeeldingen gebaseerde documenten. Gescande PDF-bestanden worden verwerkt als afbeeldingen.
- Gebruik voorbeelden waarin alle velden zijn ingevuld voor ingevulde formulieren.
- Gebruik in formulieren met in elk veld verschillende waarden.
- Gebruik een grotere gegevensset (10-15 afbeeldingen) voor ingevulde formulieren.
Uw trainingsgegevens uploaden
Zodra u de set documenten voor training hebt verzameld, moet u deze uploaden naar een Azure Blob Storage-container. Als u niet weet hoe u een Azure-opslagaccount met een container maakt, volgt u de quickstart voor Azure Storage voor Azure Portal. Gebruik de standard-prestatielaag.
Als u handmatig gelabelde gegevens wilt gebruiken, uploadt u de .labels.json en .ocr.json bestanden die overeenkomen met uw trainingsdocumenten. U kunt het hulpprogramma Voorbeeldlabeling (of uw eigen gebruikersinterface) gebruiken om deze bestanden te genereren.
Uw gegevens ordenen in submappen (optioneel)
Standaard gebruikt de API Aangepast model trainen alleen documenten die zich in de hoofdmap van uw opslagcontainer bevinden. U kunt echter trainen met gegevens in submappen als u deze opgeeft in de API-aanroep. Normaal gesproken heeft de hoofdtekst van de aanroep Aangepast model trainen de volgende indeling. Dit <SAS URL> is de SHARED Access Signature-URL van uw container:
{
"source":"<SAS URL>"
}
Als u de volgende inhoud toevoegt aan de aanvraagbody, traint de API met documenten in submappen. Het "prefix" veld is optioneel en beperkt de trainingsgegevens die zijn ingesteld op bestanden waarvan de paden beginnen met de opgegeven tekenreeks. Een waarde van "Test"bijvoorbeeld zorgt ervoor dat de API alleen de bestanden of mappen bekijkt die beginnen met het woord Testen.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Volgende stappen
Nu u hebt geleerd hoe u een set met trainingsgegevens maakt, volgt u een quickstart om een aangepast Document Intelligence-model te trainen en te gaan gebruiken in uw formulieren.