Wat is er nieuw in Azure AI Document Intelligence?
Deze inhoud is van toepassing op:![]() v4.0 (preview)
v4.0 (preview)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
De Document Intelligence-service wordt doorlopend bijgewerkt. Maak een bladwijzer voor deze pagina om op de hoogte te blijven van releaseopmerkingen, functieverbeteringen en onze nieuwste documentatie.
Belangrijk
Preview-API-versies worden buiten gebruik gesteld zodra de GA-API is uitgebracht. De API-versie 2023-02-28-preview wordt buiten gebruik gesteld als u nog steeds de preview-API of de bijbehorende SDK-versies gebruikt. Werk uw code bij om de nieuwste API-versie 2023-07-31 (GA) te gebruiken.
Februari 2024
De REST API Document Intelligence 2024-02-29-preview is nu beschikbaar. Deze preview-API introduceert nieuwe en bijgewerkte mogelijkheden:
Openbare preview-versie 2024-02-29-preview is momenteel alleen beschikbaar in de volgende Azure-regio's:
- VS - oost
- VS - west 2
- Europa -west
Indelingsmodel ondersteunt nu afbeeldingsdetectie en hiërarchische documentstructuuranalyse (secties en subsecties). De AI-kwaliteit van leesvolgorde en de detectie van logische rollen wordt ook verbeterd.
-
- Aangepaste extractiemodellen ondersteunen nu betrouwbaarheidsscores op cel-, rij- en tabelniveau. Meer informatie over betrouwbaarheid van tabellen, rijen en cellen.
- Aangepaste extractiemodellen hebben AI-kwaliteitsverbeteringen voor veldextractie.
- Aangepast sjabloonextractiemodel ondersteunt nu het extraheren van overlappende velden. Meer informatie over overlappende velden en hoe u deze gebruikt.
-
- Aangepast classificatiemodel biedt nu ondersteuning voor incrementele training voor scenario's waarin u het classificatiemodel moet bijwerken met aanvullende voorbeelden of extra klassen. Meer informatie over incrementele training.
- Aangepast classificatiemodel voegt ondersteuning toe voor Office-documenttypen (.docx, .pptx en .xls). Meer informatie over uitgebreide ondersteuning voor documenttypen.
-
- Ondersteuning voor nieuwe landinstellingen:
Landinstelling Code Arabisch ( ar)Bulgaars ( bg)Grieks ( el)Hebreeuws ( he)Macedonische ( mk)Russisch ( ru)Servisch Cyrillisch ( sr-cyrl)Oekraïens ( uk)Thai ( th)Turks ( tr)Vietnamees ( vi)- Ondersteuning voor nieuwe valutacodes:
Valuta Landinstelling Code BAM Bosnische converteerbare mark ( ba)BGN Bulgaarse Lev ( bg)ILS Israëlische nieuwe shekel ( il)MKD Macedonisch Denar ( mk)RUB Russische roebel ( ru)THB Thaise baht ( th)TRY Turkse lira ( tr)UAH Oekraïense Hryvnia ( ua)VND Vietnamese Dong ( vn)- Belastingartikelen ondersteunen uitbreiding voor Duitsland (), Spanje (
dees),Portugal (pt), Engels Canadaen-CA.
-
- Uitgebreide veldondersteuning voor id's en rijbewijs van de Europese Unie.
-
- Informatie extraheren uit de aanvraag voor een uniforme woonlening (formulier 1003).
- Gegevens extraheren uit Uniform Underwriting en Transmittal Summary of Form 1008.
- Informatie extraheren uit de openbaarmaking van hypotheekafsluiting.
-
- Gegevens extraheren uit bankkaarten.
-
- Nieuwe vooraf samengestelde gegevens uit huwelijkscertificaten extraheren.
December 2023
De Document Intelligence-clientbibliotheken gericht op REST API 2023-10-31-preview zijn nu beschikbaar voor gebruik.
November 2023
De REST API Document Intelligence 2023-10-31-preview is nu beschikbaar. Deze preview-API introduceert nieuwe en bijgewerkte mogelijkheden:
Openbare preview-versie 2023-10-31-preview is momenteel alleen beschikbaar in de volgende Azure-regio's:
- VS - oost
- VS - west 2
- Europa -west
-
- Taaluitbreiding voor handschrift: Russisch(
ru), Arabisch(ar), Thai(th). - Naleving van Cyber Executive Order (EO).
- Taaluitbreiding voor handschrift: Russisch(
-
- Ondersteuning voor Office- en HTML-bestanden.
- Ondersteuning voor Markdown-uitvoer.
- Verbeteringen in tabelextractie, leesvolgorde en sectiekopdetectie.
- Met documentinformatie 2023-10-31-preview wordt het algemene documentmodel (vooraf samengesteld-document) afgeschaft. Als u in de toekomst sleutel-waardeparen uit documenten wilt extraheren, gebruikt u het
prebuilt-layoutmodel waarvoor de optionele querytekenreeksparameterfeatures=keyValuePairsis ingeschakeld.
-
- Extraheert nu valuta voor alle prijsgerelateerde velden.
Model van de zorgverzekeringskaart
- Nieuwe veldondersteuning voor Medicare en Medicaid informatie.
Amerikaanse belastingdocumentmodellen
- Nieuw belastingmodel 1099. Ondersteunt de basisvorm 1099 en de volgende variaties: A, B, C, CAP, DIV, G, H, INT, K, LS, LS, LTC, MISC, NEC, OID, PATR, Q, QA, R, S, SA, SB.
-
- Ondersteuning voor
KVKveld. - Ondersteuning voor
BPAYveld. - Talrijke veldverfijningen.
- Ondersteuning voor
-
- Ondersteuning voor documenten in meerdere talen.
- Opties voor het splitsen van nieuwe pagina's: automatisch splitsen, altijd splitsen op pagina, geen splitsing.
Mogelijkheden voor invoegtoepassingen
- Queryvelden zijn beschikbaar in de
2023-10-31-previewrelease. - Mogelijkheden voor invoegtoepassingen zijn beschikbaar in alle modellen, met uitzondering van het leesmodel.
- Queryvelden zijn beschikbaar in de
Notitie
Met de release van 2022-08-31 API voor algemene beschikbaarheid (GA) worden de bijbehorende preview-API's afgeschaft. Als u de 2021-09-30-preview gebruikt, werkt u de API-versies 2022-01-30-preview of 2022-06-30-preview-API-versies bij om uw toepassingen te richten op de API-versie 2022-08-31. Er zijn enkele kleine wijzigingen betrokken. Zie de migratiehandleiding voor meer informatie.
Juli 2023
Notitie
Form Recognizer is nu Azure AI Document Intelligence.
- Documenteer, Azure AI-services omvatten alle eerder bekende cognitive services en Azure-app lied AI Services.
- Er zijn geen wijzigingen in prijzen.
- De namen Cognitive Services en Azure-app lied AI blijven worden gebruikt in Azure-facturering, kostenanalyse, prijslijst en prijs-API's.
- Er zijn geen belangrijke wijzigingen in API's (Application Programming Interfaces) of clientbibliotheken.
- Sommige platforms wachten nog steeds op de hernoemingsupdate. Alle vermeldingen van Form Recognizer of Document Intelligence in onze documentatie verwijzen naar dezelfde Azure-service.
Document Intelligence v3.1 (GA)
De Document Intelligence versie 3.1 API is nu algemeen beschikbaar (GA)! De API-versie komt overeen met 2023-07-31.
De v3.1-API introduceert nieuwe en bijgewerkte mogelijkheden:
- Document Intelligence-API's zijn nu modulairer en bieden ondersteuning voor optionele functies. U kunt nu de uitvoer aanpassen zodat deze specifiek de functies bevat die u nodig hebt. Meer informatie over de optionele parameters.
- Api voor documentclassificatie voor het splitsen van één bestand in afzonderlijke documenten. Meer informatie over documentclassificatie.
- Vooraf samengesteld contractmodel.
- Vooraf samengesteld amerikaans belastingformulier 1098-model.
- Ondersteuning voor Office-bestandstypen met read-API.
- Streepjescodeherkenning in documenten.
- Mogelijkheid voor invoegtoepassing voor formuleherkenning.
- Mogelijkheid voor invoegtoepassing voor lettertypeherkenning.
- Ondersteuning voor documenten met hoge resolutie.
- Aangepaste neurale modellen vereisen nu één gelabeld voorbeeld om te trainen.
- Taaluitbreiding voor aangepaste neurale modellen. Train een neuraal model voor documenten in 30 talen. Zie taalondersteuning voor de volledige lijst met ondersteunde talen.
- 🆕 Vooraf samengesteld model voor de zorgverzekering.
- Vooraf gedefinieerde uitbreiding van landinstellingen voor het factuurmodel.
- Vooraf samengestelde bonmodeltaal en uitbreiding van landinstellingen met meer dan 100 ondersteunde talen.
- Vooraf samengesteld id-model ondersteunt nu Europese id's.
UX-updates voor Document Intelligence Studio
✔️ Opties voor analyseren
Document Intelligence biedt nu ondersteuning voor geavanceerdere analysemogelijkheden en de Studio maakt het mogelijk om eenvoudig één toegangspunt (knop Opties analyseren) te configureren voor het configureren van de mogelijkheden van de invoegtoepassing.
Afhankelijk van het scenario voor documentextractie configureert u het analysebereik, documentpaginabereik, optionele detectie- en premiumdetectiefuncties.

Notitie
Lettertypeextractie wordt niet gevisualiseerd in Document Intelligence Studio. U kunt echter de stijlensectie van de JSON-uitvoer controleren op de resultaten van de detectie van lettertypen.
✔️ Documenten automatisch labelen met vooraf gedefinieerde modellen of een van uw eigen modellen
Op de pagina voor labelen van aangepaste extractiemodellen kunt u uw documenten nu automatisch labelen met behulp van een vooraf samengestelde Document Intelligent Service-modellen of -modellen die u eerder hebt getraind.

Voor sommige documenten kunnen er dubbele labels zijn nadat automatisch label is uitgevoerd. Zorg ervoor dat u de labels wijzigt zodat er daarna geen dubbele labels op de labelpagina staan.

✔️ Tabellen automatisch labelen
Op de pagina voor labelen van aangepast extractiemodel kunt u de tabellen in het document nu automatisch labelen zonder dat u de tabellen handmatig hoeft te labelen.

✔️ Testbestanden rechtstreeks toevoegen aan uw trainingsgegevensset
Zodra u een aangepast extractiemodel hebt getraind, gebruikt u de testpagina om de kwaliteit van uw model te verbeteren door indien nodig testdocumenten naar de trainingsgegevensset te uploaden.
Als een lage betrouwbaarheidsscore wordt geretourneerd voor sommige labels, controleert u of deze juist zijn gelabeld. Zo niet, voeg ze toe aan de trainingsgegevensset en label deze opnieuw om de kwaliteit van het model te verbeteren.

✔️ Gebruik maken van de documentlijstopties en filters in aangepaste projecten
Gebruik de pagina voor het labelen van aangepaste extractiemodellen. U kunt nu eenvoudig door uw trainingsdocumenten navigeren door gebruik te maken van de functie zoeken, filteren en sorteren op.
Gebruik de rasterweergave om een voorbeeld van documenten te bekijken of gebruik de lijstweergave om gemakkelijker door de documenten te bladeren.

✔️ Project delen
- Deel eenvoudig aangepaste extractieprojecten. Zie Project delen met aangepaste modellen voor meer informatie.
mei 2023
Introductie van vernieuwde documentatie voor Build 2023
🆕 Document Intelligence Overview verbeterde navigatie, gestructureerde toegangspunten en verrijkte afbeeldingen.
🆕 Kies een Document Intelligence-model met richtlijnen voor het kiezen van de beste Document Intelligence-oplossing voor uw projecten en werkstromen.
April 2023
Aankondiging van de nieuwste openbare preview-versie van de Document Intelligence-clientbibliotheek
Document Intelligence REST API versie 2023-02-28-preview ondersteunt de openbare preview-releaseclientbibliotheken . Deze release bevat de volgende nieuwe functies en mogelijkheden die beschikbaar zijn voor .NET/C# (4.1.0-beta-1), Java (4.1.0-beta-1), JavaScript (4.1.0-beta-1) en Python-clientbibliotheken (3.3.0b.1):
Zie de releaseopmerkingen voor Document Intelligence SDK (openbare preview) en maart 2023 voor meer informatie
Maart 2023
Belangrijk
2023-02-28-preview de mogelijkheden zijn momenteel alleen beschikbaar in de volgende regio's:
- Europa -west
- VS - west 2
- VS - oost
- Aangepast classificatiemodel is een nieuwe mogelijkheid binnen Document Intelligence die begint met de
2023-02-28-previewAPI. Probeer de functie voor documentclassificatie met behulp van Document Intelligence Studio of de REST API. - Queryvelden die zijn toegevoegd aan het model Algemeen document, gebruiken Azure OpenAI-modellen om specifieke velden uit documenten te extraheren. Probeer de functie Algemene documenten met queryvelden met behulp van Document Intelligence Studio. Queryvelden zijn momenteel alleen actief voor resources in de
East USregio. - Mogelijkheden voor invoegtoepassingen:
- Lettertypeextractie wordt nu herkend met de
2023-02-28-previewAPI. - Formuleextractie wordt nu herkend met de
2023-02-28-previewAPI. - Extractie van hoge resolutie wordt nu herkend met de
2023-02-28-previewAPI.
- Lettertypeextractie wordt nu herkend met de
- Updates voor aangepast extractiemodel:
- Aangepast neuraal model ondersteunt nu toegevoegde talen voor training en analyse. Train neurale modellen voor Nederlands, Frans, Duits, Italiaans en Spaans.
- Aangepast sjabloonmodel heeft nu een verbeterde mogelijkheid voor handtekeningdetectie.
- Updates voor Document Intelligence Studio :
- Naast ondersteuning voor alle nieuwe functies, zoals classificatie- en queryvelden, maakt Studio nu het delen van projecten voor aangepaste modelprojecten mogelijk.
- Nieuwe model toevoegingen in gated preview: Vaccinatiekaarten, Contracten, US Tax 1098, US Tax 1098-E en US Tax 1098-T. Als u toegang tot beperkte preview-modellen wilt aanvragen, moet u het aanvraagformulier documentinformatie voor persoonlijke preview invullen en verzenden.
- Updates voor ontvangstmodel:
- Het ontvangstbewijsmodel voegt ondersteuning toe voor thermische ontvangstbewijzen.
- Ontvangstbewijsmodel voegt nu taalondersteuning toe voor 18 talen en drie regionale talen (Engels, Frans, Portugees).
- Het ontvangstmodel ondersteunt
TaxDetailsnu extractie.
- Het indelingsmodel verbetert nu de tabelherkenning.
- Leesmodel voegt nu verbetering toe voor herkenning van tekens met één cijfer.
2023 februari
Selecteer Document Intelligence-containers voor v3.0 zijn nu beschikbaar voor gebruik.
Momenteel zijn Read v3.0 - en Layout v3.0-containers beschikbaar.
ZieDocument Intelligence-containers installeren en uitvoeren voor meer informatie.
Januari 2023
Vooraf samengesteld ontvangstbewijsmodel- ondersteunde talen toegevoegd. Het ontvangstbewijsmodel ondersteunt nu deze toegevoegde talen en landinstellingen
- Japans - Japan (ja-JP)
- Frans - Canada (fr-CA)
- Nederlands - Nederland (nl-NL)
- Engels - Verenigde Arabische Emiraten (en-AE)
- Portugees - Brazilië (pt-BR)
Vooraf samengesteld factuurmodel- ondersteunde talen toegevoegd. Het factuurmodel ondersteunt nu deze toegevoegde talen en landinstellingen
- Engels - Verenigde Staten (en-US), Australië (en-AU), Canada (en-CA), Verenigd Koninkrijk (en-UK), India (en-IN)
- Spaans - Spanje (es-ES)
- Frans - Frankrijk (fr-FR)
- Italiaans - Italië (it-IT)
- Portugees - Portugal (pt-PT)
- Nederlands - Nederland (nl-NL)
Vooraf samengesteld factuurmodel- toegevoegde velden die worden herkend. Het factuurmodel herkent nu deze toegevoegde velden
- Valutacode
- Betalingsopties
- Totale korting
- Belastingartikelen (alleen en-IN)
Vooraf samengesteld id-model- documenttypen toegevoegd die worden ondersteund. Het id-model ondersteunt nu deze toegevoegde documenttypen
- Amerikaanse militaire id
Tip
Alle updates van januari 2023 zijn beschikbaar met REST API-versie 2022-08-31 (GA).
Vooraf samengesteld ontvangstbewijsmodel: aanvullende taalondersteuning:
Het vooraf samengestelde ontvangstbewijsmodel voegt ondersteuning toe voor de volgende talen:
- Engels - Verenigde Arabische Emiraten (en-AE)
- Nederlands - Nederland (nl-NL)
- Frans - Canada (fr-CA)
- Duits - (de-DE)
- Italiaans - (it-IT)
- Japans - Japan (ja-JP)
- Portugees - Brazilië (pt-BR)
Vooraf samengesteld factuurmodel: aanvullende taalondersteuning en veldextractie
Het vooraf samengestelde factuurmodel voegt ondersteuning toe voor de volgende talen:
- Engels - Australië (en-AU), Canada (en-CA), Verenigd Koninkrijk (en-UK), India (en-IN)
- Portugees - Brazilië (pt-BR)
Het vooraf samengestelde factuurmodel voegt nu ondersteuning toe voor de volgende veldextracties:
- Valutacode
- Betalingsopties
- Totale korting
- Belastingartikelen (alleen en-IN)
Vooraf samengesteld id-documentmodel: aanvullende ondersteuning voor documenttypen
Het vooraf gemaakte id-documentmodel voegt nu ondersteuning toe voor de volgende documenttypen:
- Uitbreiding van rijbewijs met ondersteuning voor India, Canada, Verenigd Koninkrijk en Australië
- Amerikaanse militaire id-kaarten en documenten
- India-id-kaarten en -documenten (PAN en Aadhaar)
- Australië-id-kaarten en -documenten (fotokaart, sleutelpas-id)
- Canada-id-kaarten en -documenten (identificatiekaart, Maple-kaart)
- Id-kaarten en documenten van het Verenigd Koninkrijk (nationale/regionale identiteitskaart)
December 2022
Updates voor Document Intelligence Studio
De release van Document Intelligence Studio van december bevat de nieuwste updates voor Document Intelligence Studio. Er zijn aanzienlijke verbeteringen in de gebruikerservaring, met name met ondersteuning voor aangepaste modellabels.
Paginabereik. De Studio ondersteunt nu het analyseren van opgegeven pagina's uit een document.
Aangepaste modellabels:
Voer de Layout-API automatisch uit. U kunt ervoor kiezen om de Indelings-API automatisch uit te voeren voor alle documenten in uw blobopslag tijdens het installatieproces voor een aangepast model.
Zoeken. De Studio bevat nu zoekfunctionaliteit om woorden in een document te zoeken. Dankzij deze verbetering kunt u eenvoudiger navigeren tijdens het labelen.
Navigatie. U kunt labels selecteren om gelabelde woorden in een document te richten.
Automatisch tabellabels. Nadat u het tabelpictogram in een document hebt geselecteerd, kunt u ervoor kiezen om de geëxtraheerde tabel in de labelweergave automatisch te labelen.
Labelsubtypen en subtypen op het tweede niveau The Studio ondersteunt nu subtypen voor tabelkolommen, tabelrijen en subtypen op het tweede niveau voor typen zoals datums en getallen.
Het bouwen van aangepaste neurale modellen wordt nu ondersteund in de regio US Gov Virginia.
Preview-API-versies
2022-01-30-previewen2021-09-30-previewwordt buiten gebruik gesteld op 31 januari 2023. Werk bij naar de2022-08-31API-versie om serviceonderbrekingen te voorkomen.
november 2022
- Aankondiging van de nieuwste stabiele release van Azure AI Document Intelligence-bibliotheken
- Deze release bevat belangrijke wijzigingen en updates voor .NET-, Java-, JavaScript- en Python-clientbibliotheken. ZieAzure SDK DevBlog voor meer informatie.
- De belangrijkste verbeteringen zijn de introductie van twee nieuwe clients, de
DocumentAnalysisClienten deDocumentModelAdministrationClient.
Oktober 2022
Inhoud met versiebeheer van documentinformatie
Document Intelligence-documentatie wordt bijgewerkt om een versie-ervaring te presenteren. Nu kunt u ervoor kiezen om inhoud weer te geven die is gericht op de
v3.0 GAervaring of dev2.1 GAervaring. De v3.0-ervaring is de standaardinstelling.
Document Intelligence Studio-voorbeeldcode
- Voorbeeldcode voor de labelervaring van Document Intelligence Studio is nu beschikbaar op GitHub. Klanten kunnen Document Intelligence ontwikkelen en integreren in hun eigen UX of hun eigen nieuwe UX bouwen met behulp van de Voorbeeldcode van Document Intelligence Studio.
Taaluitbreiding
- Met de nieuwste preview-versie ondersteunen Document Intelligence's Read (OCR), Layout en Custom template modellen 134 nieuwe talen. Deze taaltoevoegingen zijn Grieks, Lets, Servisch, Thai, Oekraïens en Vietnamees, samen met verschillende Latijnse en Cyrillische talen. Document Intelligence heeft nu in totaal 299 ondersteunde talen in de meest recente ALGEMENE en nieuwe preview-versies. Raadpleeg de pagina ondersteunde talen om alle ondersteunde talen weer te geven.
- Gebruik de PARAMETER REST API
api-version=2022-06-30-previewwanneer u de API of de bijbehorende SDK gebruikt om de nieuwe talen in uw toepassingen te ondersteunen.
Nieuw vooraf samengesteld contractmodel
- Een nieuwe vooraf samengestelde functie waarmee informatie wordt geëxtraheerd uit contracten zoals partijen, titel, contract-id, uitvoeringsdatum en meer. het contractenmodel is momenteel in preview en vraagt hier toegang aan.
Regio-uitbreiding voor het trainen van aangepaste neurale modellen
- Aangepaste neurale modellen trainen die nu worden ondersteund in toegevoegde regio's.
- VS - oost
- VS - oost 2
- US Gov - Arizona
- Aangepaste neurale modellen trainen die nu worden ondersteund in toegevoegde regio's.
September 2022
Notitie
Vanaf versie 4.0.0 is een nieuwe set clients geïntroduceerd om gebruik te maken van de nieuwste functies van de Document Intelligence-service.
De ALGEMENE release van SDK-versie 4.0.0 bevat de volgende updates:
- Versie 4.0.0 GA (2022-09-08)
- Ondersteunt REST API v3.0- en v2.0-clients
Regio-uitbreiding voor het trainen van aangepaste neurale modellen wordt nu ondersteund in zes nieuwe regio's
- Australië - oost
- Central US
- Azië - oost
- Frankrijk - centraal
- Verenigd Koninkrijk Zuid
- VS - west 2
Zie aangepaste neurale modellen voor een volledige lijst met regio's waarin training wordt ondersteund.
Release van document Intelligence SDK-versie
4.0.0 GA:- Document Intelligence-clientbibliotheken versie 4.0.0 (.NET/C#, Java, JavaScript) en versie 3.2.0 (Python) zijn algemeen beschikbaar en klaar voor gebruik in productietoepassingen!.
- Zie het SDK-overzicht voor meer informatie over Document Intelligence-clientbibliotheken.
- Werk uw toepassingen bij met behulp van de migratiehandleiding voor uw programmeertaal.
Augustus 2022
De release van de Document Intelligence SDK bètaversie van augustus 2022 bevat de volgende updates:
Versie 4.0.0-beta.5 (2022-08-09)
Document Intelligence v3.0 algemeen beschikbaar
- Document Intelligence REST API v3.0 is nu algemeen beschikbaar en klaar voor gebruik in productietoepassingen. Werk uw toepassingen bij met REST API-versie 2022-08-31.
Updates voor Document Intelligence Studio
- Volgende stappen. Op elke modelpagina heeft Studio nu een sectie met de volgende stappen. Gebruikers kunnen snel verwijzen naar voorbeeldcode, richtlijnen voor probleemoplossing en prijsinformatie.
- Aangepaste modellen. De Studio bevat nu de mogelijkheid om labels in aangepaste modelprojecten opnieuw te ordenen om de efficiëntie van labels te verbeteren.
- Aangepaste modellen kopiëren kan worden gekopieerd naar Document Intelligence-services vanuit Studio. Met deze bewerking kunt u een getraind model promoveren naar andere omgevingen en regio's.
- Documenten verwijderen. De Studio ondersteunt nu het verwijderen van documenten uit gelabelde gegevensset in aangepaste projecten.
Updates voor Document Intelligence-service
- vooraf gedefinieerde leesbewerkingen. Ocr-model lezen is nu ook beschikbaar in Document Intelligence met alinea's en taaldetectie als de twee nieuwe functies. Document Intelligence Read is gericht op geavanceerde documentscenario's die zijn afgestemd op de bredere mogelijkheden voor documentinformatie in Document intelligence.
- vooraf gedefinieerde indeling. Met het indelingsmodel worden alinea's geëxtraheerd en wordt aangegeven of de geëxtraheerde tekst een alinea, titel, sectiekop, voetnoot, paginakoptekst, paginavoettekst of paginanummer is.
- vooraf samengestelde factuur. De velden TotalVAT en Regel/BTW worden nu omgezet in respectievelijk de bestaande velden TotalTax en Regel/Belasting.
- vooraf samengesteld-idDocument. Ondersteuning voor gegevensextractie voor amerikaanse staats-id's, sociale zekerheid en groene kaarten. Ondersteuning voor paspoortvisuminformatie.
- vooraf gemaakte ontvangstbewijs. Uitgebreide landinstellingenondersteuning voor Frans (fr-FR), Spaans (es-ES), Portugees (pt-PT), Italiaans (it-IT) en Duits (de-DE).
- vooraf samengestelde businessCard. Adresparse-ondersteuning voor het extraheren van subvelden voor adresonderdelen zoals adres, plaats, provincie, land/regio en postcode.
Verbeteringen in AI-kwaliteit
- vooraf gedefinieerde leesbewerkingen. Verbeterde ondersteuning voor enkele tekens, handgeschreven datums, bedragen, namen, andere belangrijke gegevens die vaak worden gevonden in ontvangstbewijzen en facturen en verbeterde verwerking van digitale PDF-documenten.
- vooraf gedefinieerde indeling. Ondersteuning voor een betere detectie van bijgesneden tabellen, randloze tabellen en verbeterde herkenning van langlopende cellen.
- vooraf samengesteld document. Verbeterde waarde- en selectievakjedetectie.
- custom-neurale. Verbeterde nauwkeurigheid voor tabeldetectie en -extractie.
Juni 2022
- De release van de Document Intelligence SDK-bètaversie van juni 2022 bevat de volgende updates:
Versie 4.0.0-beta.4 (2022-06-08)
De release van Document Intelligence Studio juni is de meest recente update van Document Intelligence Studio. Deze update bevat aanzienlijke gebruikerservaring en toegankelijkheidsverbeteringen:
- Codevoorbeeld voor JavaScript en C#. Op het tabblad Code van Studio worden nu naast de bestaande Python-codevoorbeelden JavaScript en C#-code toegevoegd.
- Nieuwe gebruikersinterface voor het uploaden van documenten. Studio biedt nu ondersteuning voor het uploaden van een document met slepen en neerzetten naar de nieuwe gebruikersinterface voor uploaden.
- Nieuwe functie voor aangepaste projecten. Aangepaste projecten bieden nu ondersteuning voor het maken van opslagaccounts en blobs bij het configureren van het project. Daarnaast biedt een aangepast project nu ondersteuning voor het uploaden van trainingsbestanden rechtstreeks in studio en het kopiëren van het bestaande aangepaste model.
Document Intelligence v3.0 2022-06-30-preview-release biedt uitgebreide updates voor de functie-API's:
- Indeling breidt structuurextractie uit. Indeling bevat nu toegevoegde structuurelementen, waaronder secties, sectiekoppen en alinea's. Met deze update worden gedetailleerdere scenario's voor documentsegmentatie mogelijk. Zie verbeterde structuur voor een volledige lijst met geïdentificeerde structuurelementen.
- Ondersteuning voor aangepaste tabellaire velden voor neurale modellen. Aangepaste documentmodellen ondersteunen nu tabellaire velden. Tabellaire velden zijn standaard ook meerdere pagina's. Zietabellaire velden voor meer informatie over tabellaire velden in aangepaste neurale modellen.
- Ondersteuning voor tabellaire velden voor aangepast sjabloonmodel voor tabellen op meerdere pagina's. Aangepaste formuliermodellen ondersteunen nu tabellaire velden op meerdere pagina's. Zietabellaire velden voor meer informatie over tabellaire velden in aangepaste sjabloonmodellen.
- Uitvoer van factuurmodel bevat nu algemene sleutel-waardeparen voor documenten. Wanneer facturen vereiste velden bevatten buiten de velden die zijn opgenomen in het vooraf gedefinieerde model, vormt het algemene documentmodel een aanvulling op de uitvoer met sleutel-waardeparen. Ziesleutel-waardeparen.
- Uitbreiding van factuurtaal. Het factuurmodel bevat uitgebreide taalondersteuning. Zieondersteunde talen.
- Vooraf samengesteld visitekaartje bevat nu japanse taalondersteuning. Zieondersteunde talen.
- Vooraf samengesteld id-documentmodel. Het id-documentmodel extraheert nu DateOfIssue, Height, Weight, EyeColor, HairColor en DocumentDiscriminator uit de amerikaanse rijbewijslicenties. Zieveldextractie.
- Leesmodel ondersteunt nu veelgebruikte Microsoft Office-documenttypen. Documenttypen zoals Word (docx), Excel (xlsx) en PowerPoint (pptx) worden nu ondersteund met de Read-API. Zie Gegevensextractie lezen.
Februari 2022
Versie 4.0.0-beta.3 (2022-02-10)
In de preview-versie van Document Intelligence v3.0 worden verschillende nieuwe functies, mogelijkheden en verbeteringen geïntroduceerd:
- Aangepast neuraal model of aangepast documentmodel is een nieuw aangepast model voor het extraheren van tekst- en selectiemarkeringen uit gestructureerde formulieren, semi-gestructureerde en ongestructureerde documenten.
- Vooraf samengesteld W-2-model is een nieuw vooraf samengesteld model voor het extraheren van velden uit W-2-formulieren voor belastingrapportage- en inkomensverificatiescenario's.
- Lees-API extraheert gedrukte tekstregels, woorden, tekstlocaties, gedetecteerde talen en handgeschreven tekst, indien gedetecteerd.
- Het vooraf getrainde algemene documentmodel wordt nu bijgewerkt ter ondersteuning van selectiemarkeringen naast API-tekst, tabellen, structuur en sleutel-waardeparen uit formulieren en documenten.
- Het vooraf samengestelde factuurmodel voor de Factuur-API breidt de ondersteuning uit naar Spaanse facturen.
- Document Intelligence Studio voegt nieuwe demo's toe voor lees-, W2-, hotelbevestigingsvoorbeelden en ondersteuning voor het trainen van de nieuwe aangepaste neurale modellen.
- Taaluitbreiding documentinformatie lezen, indeling en aangepast formulier voegen ondersteuning toe voor 42 nieuwe talen, waaronder Arabisch, Hindi en andere talen die Arabische en Devanagari-scripts gebruiken om de dekking uit te breiden naar 164 talen. Handgeschreven taalondersteuning wordt uitgebreid naar Japans en Koreaans.
Aan de slag met de nieuwe REST API, Python of .NET SDK voor de v3.0 preview-API.
Gegevensextractie van documentinformatiemodel:
Model Tekstextractie Sleutel-waardeparen Selectiemarkeringen Tabellen Handtekeningen Read ✓ Algemeen document ✓ ✓ ✓ ✓ Indeling ✓ ✓ ✓ Factuur ✓ ✓ ✓ ✓ Ontvangstbewijs ✓ ✓ ✓ Id-document ✓ ✓ Visitekaartje ✓ ✓ Sjabloon Aangepast ✓ ✓ ✓ ✓ ✓ Aangepaste neurale ✓ ✓ ✓ ✓ De bètaversie van document Intelligence SDK bevat de volgende updates:
Aangepaste documentmodellen en -modi:
- Aangepaste sjabloon (voorheen aangepast formulier).
- Aangepast neuraal.
- Aangepast model: buildmodus.
Vooraf samengesteld W-2-model (prebuilt-tax.us.w2).
Vooraf samengesteld model lezen (vooraf gedefinieerd).
Vooraf samengesteld model voor facturen (Spaans) (vooraf samengestelde factuur).
November 2021
Versie 4.0.0-beta.2 (2021-11-09)
| Naslagdocumentatie voor pakket (NuGet) | Changelog/Release History API |
- Document Intelligence v3.0 preview SDK-release-update (bèta.2) bevat bugfixes en kleine functie-updates.
Oktober 2021
Document Intelligence v3.0 preview-versie 4.0.0-beta.1 (2021-10-07)introduceert verschillende nieuwe functies en mogelijkheden:
Algemeen documentmodel is een nieuwe API die gebruikmaakt van een vooraf getraind model voor het extraheren van tekst, tabellen, structuur en sleutel-waardeparen uit formulieren en documenten.
Het ontvangstbewijsmodel van het hotel is toegevoegd aan de vooraf samengestelde ontvangstbevestigingsverwerking.
Uitgebreide velden voor id-document het ID-model ondersteunen goedkeuringen, beperkingen en extractie van voertuigclassificaties uit amerikaanse rijbewijs's.
Handtekeningveld is een nieuw veldtype in aangepaste formulieren om de aanwezigheid van een handtekening in een formulierveld te detecteren.
Taaluitbreidingsondersteuning voor 122 talen (afdrukken) en 7 talen (handgeschreven). Document Intelligence-indeling en aangepast formulier breiden ondersteunde talen uit naar 122 met de nieuwste preview. Het voorbeeld bevat tekstextractie voor afdruktekst in 49 nieuwe talen, waaronder Russisch, Bulgaars en andere Cyrillische en meer Latijnse talen. Daarnaast ondersteunt extractie van handgeschreven tekst nu zeven talen met Engels en nieuwe previews van vereenvoudigd Chinees, Frans, Duits, Italiaans, Portugees en Spaans.
Verbeteringen in tabel- en tekstextractie Indeling bieden nu ondersteuning voor het extraheren van tabellen met één rij, ook wel sleutel-waardetabellen genoemd. Verbeteringen in tekstextractie omvatten een betere verwerking van digitale PDF's en MRZ-tekst (Machine Readable Zone) in identiteitsdocumenten, samen met algemene prestaties.
Document Intelligence Studio Om het gebruik van de service te vereenvoudigen, hebt u nu toegang tot Document Intelligence Studio om de verschillende vooraf samengestelde modellen of labels te testen en een aangepast model te trainen.
Aan de slag met de nieuwe REST API, Python of .NET SDK voor de v3.0 preview-API.
Gegevensextractie van documentinformatiemodel
Model Tekstextractie Sleutel-waardeparen Selectiemarkeringen Tabellen Algemeen document ✓ ✓ ✓ ✓ Indeling ✓ ✓ ✓ Factuur ✓ ✓ ✓ ✓ Ontvangstbewijs ✓ ✓ Id-document ✓ ✓ Visitekaartje ✓ ✓ Aangepast telefoonnummer ✓ ✓ ✓ ✓
September 2021
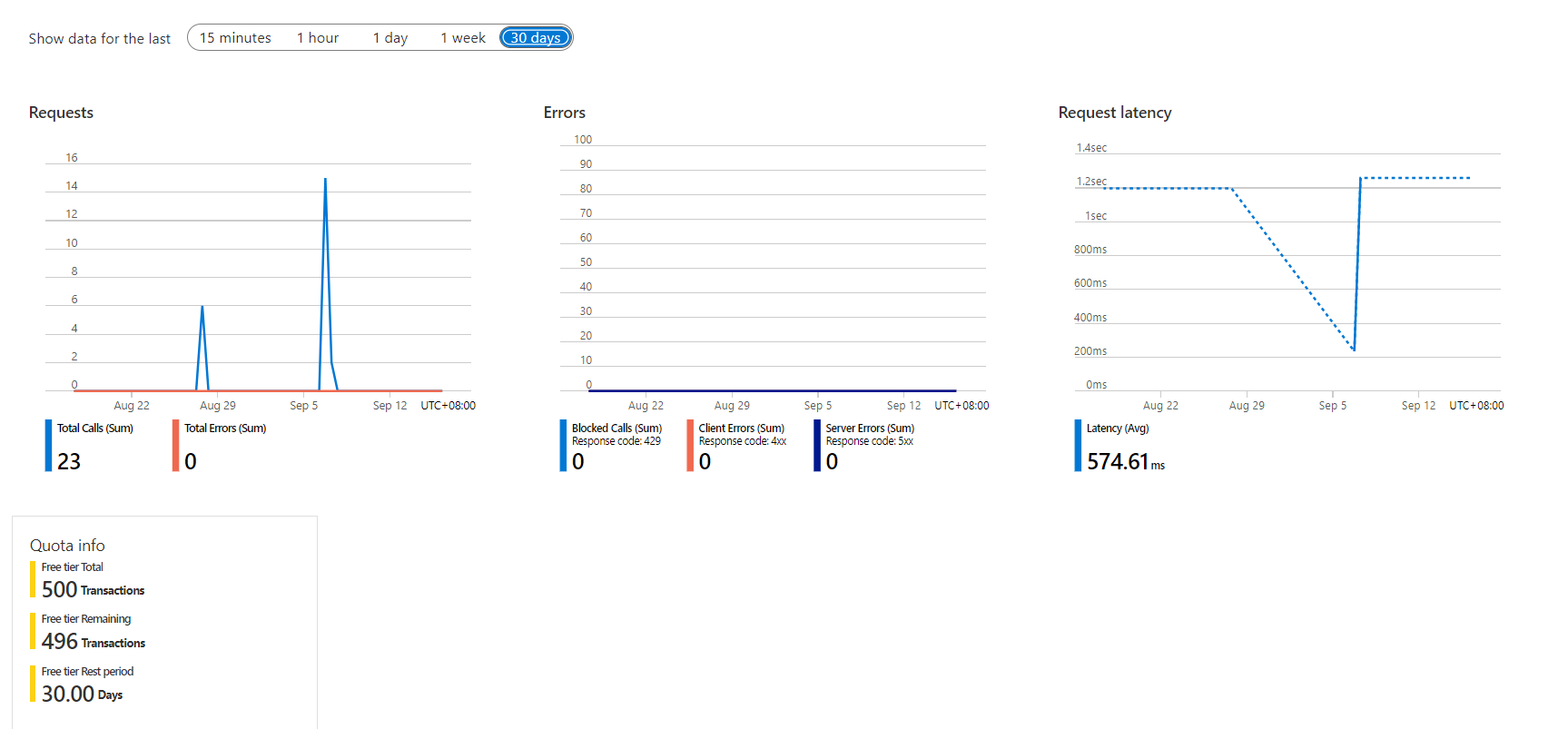
Geavanceerde functies van Azure Metrics Explorer zijn beschikbaar op de overzichtspagina van uw Document Intelligence-resource in Azure Portal.
Bewakingsmenu:
Diagrammen:
Update van id-documentmodel : opgegeven namen, waaronder een achtervoegsel, met of zonder punt (volledige stop), proces geslaagd:
Invoertekst Resultaat met update William Isaac Kirby Jr. FirstName: William Isaac
LastName: Kirby Jr.Henry Caleb Ross Sr Voornaam: Henry Caleb
LastName: Ross Sr.
Juli 2021
- Ondersteuning voor door het systeem toegewezen beheerde identiteit: u kunt nu een door het systeem toegewezen beheerde identiteit inschakelen om Document Intelligence beperkte toegang te verlenen tot privéopslagaccounts, waaronder accounts die zijn beveiligd door een virtueel netwerk, firewall of BYOS (Bring Your Own Storage). ZieBeheerde identiteit voor uw Document Intelligence-resource maken en gebruiken voor meer informatie.
Juni 2021
Document Intelligence-containers v2.1 die zijn uitgebracht in beperkte preview en worden nu ondersteund door zes functiecontainers: indeling, visitekaartje, id-document, ontvangstbewijs, factuur en aangepast. Als u deze wilt gebruiken, moet u een onlineaanvraag indienen en goedkeuring ontvangen.
Document Intelligence-connector die is uitgebracht in preview: De Document Intelligence-connector kan worden geïntegreerd met Azure Logic Apps, Microsoft Power Automate en Microsoft Power Apps. De connector ondersteunt werkstroomacties en triggers voor het extraheren en analyseren van documentgegevens en -structuur uit aangepaste en vooraf samengestelde formulieren, facturen, ontvangstbewijzen, visitekaartjes en id-documenten.
Document Intelligence SDK v3.1.0 is gepatcht naar v3.1.1 voor C#, Java en Python. De patchadressen facturen waarvoor geen subregelitemvelden zijn gedetecteerd, zoals een
FormFieldmetTextmaar geen ofPageinformatieBoundingBox.
Mei 2021
- Versie 3.1.0 (2021-05-26)
Documentatie voor NuGet-pakket versie 3.0.1 voor Changelog/Release History Reference| | |
Document Intelligence 2.1 is algemeen beschikbaar. De GA-release markeert de stabiliteit van de wijzigingen die zijn geïntroduceerd in eerdere 2.1 preview-pakketversies. Met deze release kunt u informatie en gegevens uit de volgende documenttypen detecteren en extraheren:
Als u aan de slag wilt gaan, probeert u het voorbeeldprogramma documentinformatie en volgt u de quickstart.
Met de bijgewerkte functie indelings-API-tabel voegt u kopherkenning toe met kolomkoppen die meerdere rijen kunnen omvatten. Elke tabelcel heeft een kenmerk dat aangeeft of deze deel uitmaakt van een koptekst of niet. Deze update kan worden gebruikt om te bepalen welke rijen de tabelkop vormen.
April 2021
NuGet-pakket versie 3.1.0-beta.4
Nieuwe methoden voor het analyseren van gegevens uit identiteitsdocumenten:
StartRecognizeIdDocumentsFromUriAsync
StartRecognizeIdDocumentsAsync
Zie Velden die zijn geëxtraheerd in onze documentinformatiedocumentatie voor een lijst met veldwaarden.
Breid de set documenttalen uit die kunnen worden geleverd aan de methode StartRecognizeContent.
Nieuwe eigenschap
Pagesdie wordt ondersteund door de volgende klassen:RecognizeBusinessCardsOptions
RecognizeCustomFormsOptions
RecognizeInvoicesOptions
RecognizeReceiptsOptionsMet de
Pageseigenschap kunt u afzonderlijke of een reeks pagina's selecteren voor PDF- en TIFF-documenten met meerdere pagina's. Voer voor afzonderlijke pagina's het paginanummer in, bijvoorbeeld3. Voor een reeks pagina's (zoals pagina 2 en pagina 5-7) voert u de p-leeftijdsnummers en bereiken in, gescheiden door komma's:2, 5-7.Nieuwe eigenschap
ReadingOrderdie wordt ondersteund voor de volgende klasse:De
ReadingOrdereigenschap is een optionele parameter waarmee u kunt opgeven welk algoritme voor leesvolgorde(basicofnatural) moet worden toegepast om de extractie van tekstelementen te orden. Als dit niet is opgegeven, isbasicde standaardwaarde .
- SDK-preview-updates voor API-versie
2.1-preview.3introduceert functie-updates en -verbeteringen.
Maart 2021
Document Intelligence v2.1 openbare preview v2.1-preview.3 is uitgebracht en bevat de volgende functies:
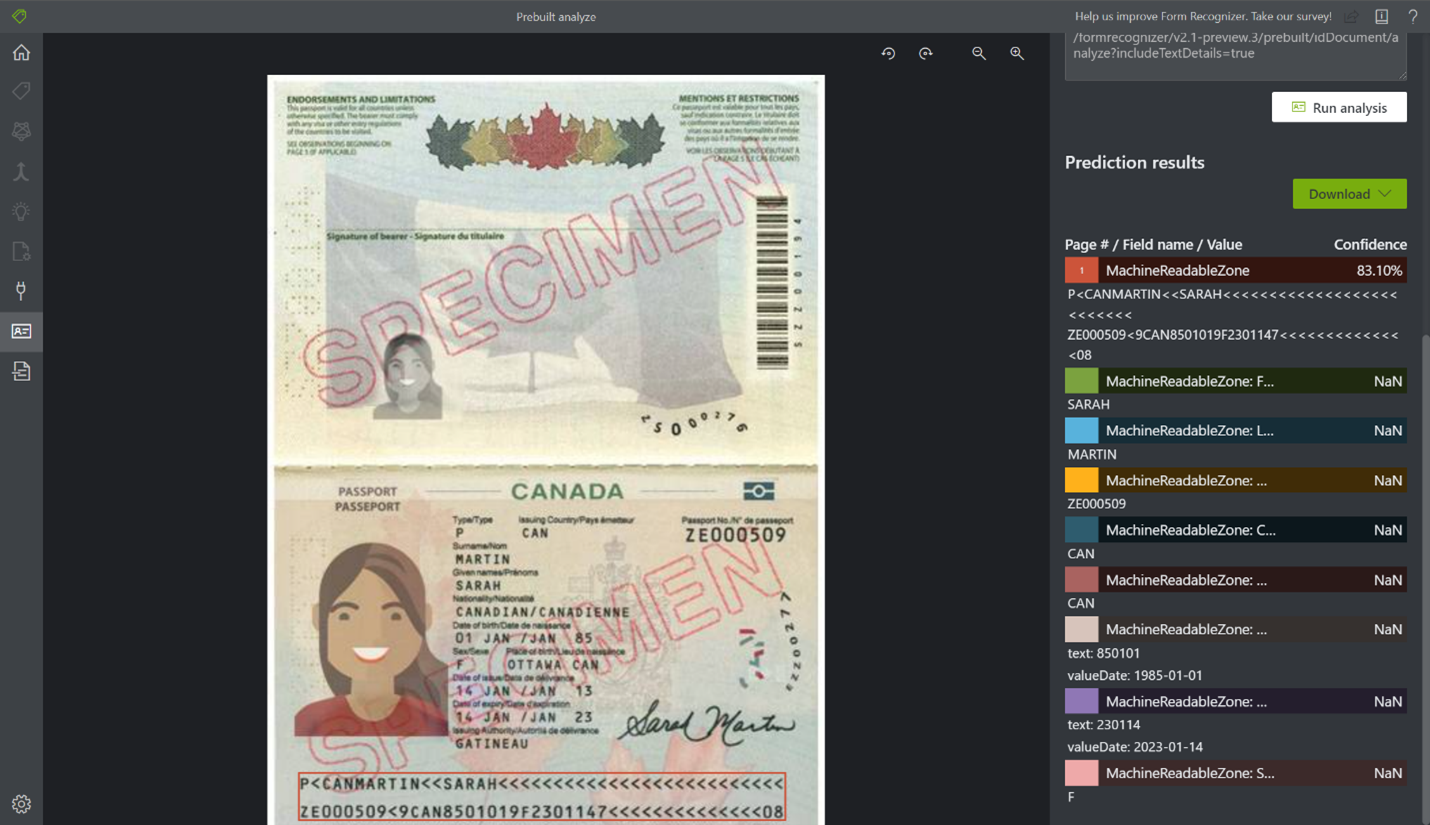
Nieuw vooraf samengesteld id-model Het nieuwe vooraf samengestelde ID-model stelt klanten in staat om id's te nemen en gestructureerde gegevens te retourneren om de verwerking te automatiseren. Het combineert onze krachtige OCR-mogelijkheden (Optical Character Recognition) met ID understanding-modellen om belangrijke informatie te extraheren uit paspoorten en Amerikaanse rijbewijs' s.
Meer informatie over het vooraf samengestelde id-model
Extractie van regelitems voor factuurmodel - Vooraf samengesteld factuurmodel biedt nu ondersteuning voor het extraheren van regelitems; het extraheert nu volledige items en hun onderdelen- beschrijving, hoeveelheid, hoeveelheid, product-id, datum en meer. Met een eenvoudige API/SDK-aanroep kunt u nuttige gegevens extraheren uit uw facturen: tekst, tabel, sleutel-waardeparen en regelitems.
Labelen en trainen van tabellen onder supervisie, labelen met lege waarden: naast de geavanceerde deep learning-mogelijkheden voor deep learning voor automatische tabelextractie van Document Intelligence kunnen klanten nu tabellen labelen en trainen. Deze nieuwe release bevat de mogelijkheid om regelitems/tabellen (dynamisch en vast) te labelen en te trainen en een aangepast model te trainen om sleutel-waardeparen en regelitems te extraheren. Zodra een model is getraind, extraheert het model regelitems als onderdeel van de JSON-uitvoer in de sectie documentResults.

Naast het labelen van tabellen kunt u nu lege waarden en regio's labelen. Als sommige documenten in uw trainingsset geen waarden hebben voor bepaalde velden, kunt u ze labelen zodat uw model weet dat waarden correct moeten worden geëxtraheerd uit geanalyseerde documenten.
Ondersteuning voor 66 nieuwe talen : de indelings-API en aangepaste modellen voor Document Intelligence ondersteunen nu 73 talen.
Meer informatie over de taalondersteuning van Document Intelligence.
Natuurlijke leesvolgorde, handschriftclassificatie en paginaselectie : met deze update kunt u ervoor kiezen om de tekstregeluitvoer in de natuurlijke leesrichting op te halen in plaats van de standaardvolgorde van links naar rechts en van boven naar beneden. Gebruik de nieuwe queryparameter readingOrder en stel deze in op 'natuurlijke' waarde voor een meer mensenvriendelijke uitvoer van de leesvolgorde. Daarnaast classificeert Document Intelligence voor Latijnse talen tekstregels als handgeschreven stijl of niet en geeft een betrouwbaarheidsscore.
Verbeteringen in de kwaliteit van het vooraf samengestelde ontvangstmodel. Deze update bevat veel kwaliteitsverbeteringen voor het vooraf samengestelde ontvangstbewijsmodel, met name rond het extraheren van lijnitems.


November 2020
Document Intelligence v2.1-preview.2 is uitgebracht en bevat de volgende functies:
Nieuw vooraf samengesteld factuurmodel : het nieuwe vooraf samengestelde factuurmodel stelt klanten in staat facturen in verschillende indelingen te nemen en gestructureerde gegevens te retourneren om de factuurverwerking te automatiseren. Het combineert onze krachtige OCR-mogelijkheden (Optical Character Recognition) met deep learning-modellen voor het begrijpen van facturen om belangrijke informatie uit facturen in het Engels te extraheren. Hiermee worden belangrijke tekst, tabellen en informatie geëxtraheerd, zoals klant, leverancier, factuur-id, factuurdatum, totaal, verschuldigd bedrag, belastingbedrag, verzenden naar en factureren aan.

Verbeterde tabelextractie - Document Intelligence biedt nu verbeterde tabelextractie , waarin onze krachtige OCR-mogelijkheden (Optical Character Recognition) worden gecombineerd met een deep learning-model voor tabelextractie. Met Document Intelligence kunnen gegevens worden geëxtraheerd uit tabellen, waaronder complexe tabellen met samengevoegde kolommen, rijen, geen randen en meer.

Update van clientbibliotheek : de nieuwste versies van de clientbibliotheken voor .NET, Python, Java en JavaScript ondersteunen de Document Intelligence 2.1 API.
Nieuwe taal die wordt ondersteund: Japans - De volgende nieuwe talen worden nu ondersteund: voor
AnalyzeLayoutenAnalyzeCustomForm: Japans (ja). Taalondersteuning.Tekstregelstijlindicatie (handgeschreven/andere) (alleen Latijnse talen) - Document Intelligence voert nu een
appearanceobject uit waarbij wordt geclassificeerd of elke tekstregel handgeschreven stijl is of niet, samen met een betrouwbaarheidsscore. Deze functie wordt alleen ondersteund voor Latijnse talen.Kwaliteitsverbeteringen - Verbeteringen voor extractie, waaronder verbeteringen voor extractie met één cijfer.
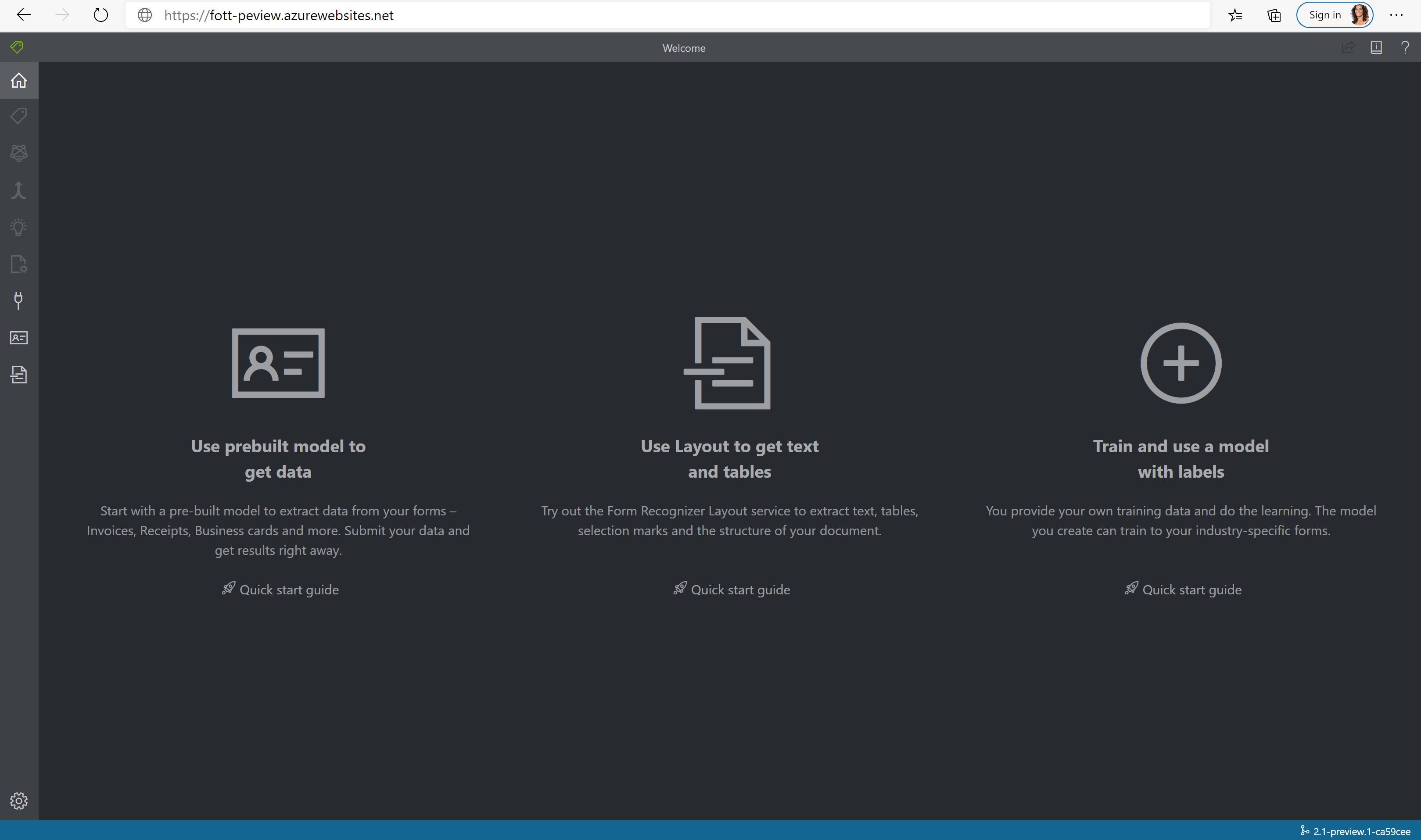
Nieuwe try-it-outfunctie in het document intelligence-voorbeeld- en labelprogramma: mogelijkheid om vooraf samengestelde factuur-, ontvangst- en visitekaartjesmodellen en de indelings-API uit te proberen met behulp van het hulpprogramma Document Intelligence-voorbeeldlabels. Bekijk hoe uw gegevens worden geëxtraheerd zonder code te schrijven.
Het hulpprogramma Document Intelligence-voorbeeldlabels proberen
- Feedbacklus : wanneer u bestanden analyseert via het hulpprogramma Voorbeeldlabels, kunt u deze nu ook toevoegen aan de trainingsset en de labels zo nodig aanpassen en trainen om het model te verbeteren.
- Documenten automatisch labelen: automatisch labels toegevoegd documenten op basis van eerdere gelabelde documenten in het project.


Augustus 2020
**Document intelligence
v2.1-preview.1bevat de volgende functies:- REST API-verwijzing is beschikbaar - Bekijk de
v2.1-preview.1 reference. - Naast Engels worden de volgende talen ondersteund: voor
LayoutenTrain Custom Model: Engels (en), Chinees (vereenvoudigd), Nederlands (zh-Hans), Fransnl(fr), Duits (de), Italiaans (), Portugees (itpt) en Spaans (es). - Selectievakje/Selectiemarkeringsdetectie – Document Intelligence ondersteunt detectie en extractie van selectiemarkeringen, zoals selectievakjes en keuzerondjes. Selectiemarkeringen worden geëxtraheerd
Layouten u kunt nu ook labelen en trainen inTrain Custom Model- Trainen met labels om sleutel-waardeparen voor selectiemarkeringen te extraheren. - Model opstellen : hiermee kunnen meerdere modellen worden samengesteld en aangeroepen met één model-id. Wanneer u een document verzendt dat moet worden geanalyseerd met een samengestelde model-id, wordt eerst een classificatiestap uitgevoerd om het naar het juiste aangepaste model te routeren. Model opstellen is beschikbaar voor
Train Custom Model- Trainen met labels. - Modelnaam : voeg een beschrijvende naam toe aan uw aangepaste modellen voor eenvoudiger beheer en tracering.
- Nieuw vooraf samengesteld model voor visitekaartjes voor het extraheren van algemene velden in het Engels, taal visitekaartjes.
- Nieuwe landinstellingen voor vooraf samengestelde ontvangstbewijzen naast EN-US, ondersteuning is nu beschikbaar voor EN-AU, EN-CA, EN-GB, EN-IN.
- Kwaliteitsverbeteringen voor
Layout,Train Custom Model- Trainen zonder labels en Trainen met labels.
- REST API-verwijzing is beschikbaar - Bekijk de
v2.0 bevat de volgende update:
- De clientbibliotheken voor NET, Python, Java en JavaScript zijn algemeen beschikbaar.
Er zijn nieuwe voorbeelden beschikbaar op GitHub.
- Het Recepten voor kennisextractie - Forms Playbook verzamelt best practices van echte Document Intelligence-klantafspraken en biedt bruikbare codevoorbeelden, controlelijsten en voorbeeldpijplijnen die worden gebruikt bij het ontwikkelen van deze projecten.
- Het hulpprogramma Voorbeeldlabeling wordt bijgewerkt ter ondersteuning van de nieuwe v2.1-functionaliteit. Zie deze quickstart om aan de slag te gaan met het hulpprogramma.
- Het intelligent kioskdocument intelligence-voorbeeld laat zien hoe u integreert en
Train Custom Model- traintAnalyze Receiptzonder labels.
Juli 2020
- Document Intelligence v2.0-verwijzing beschikbaar: bekijk de naslaginformatie over de v2.0-API en de bijgewerkte clientbibliotheken voor .NET, Python, Java en JavaScript.
Verbeteringen aan tabellen en verbeteringen van extractie: bevat verbeteringen in nauwkeurigheid en verbeteringen in tabelextracties, met name de mogelijkheid om tabelkoppen en -structuren te leren in aangepaste trein zonder labels.
Valutaondersteuning : detectie en extractie van globale valutasymbolen.
Azure Gov - Document Intelligence is nu ook beschikbaar in Azure Gov.
Verbeterde beveiligingsfuncties:
- Bring Your Own Key - Document Intelligence versleutelt uw gegevens automatisch wanneer deze in de cloud worden bewaard om deze te beveiligen en om u te helpen te voldoen aan de beveiligings- en nalevingsverplichtingen van uw organisatie. Uw abonnement maakt standaard gebruik van door Microsoft beheerde versleutelingssleutels. U kunt uw abonnement nu ook beheren met uw eigen versleutelingssleutels. Door de klant beheerde sleutels, ook wel bring your own key (BYOK) genoemd, bieden meer flexibiliteit om toegangsbeheer te maken, draaien, uitschakelen en intrekken. U kunt ook de versleutelingssleutels controleren die worden gebruikt voor het beveiligen van uw gegevens.
- Privé-eindpunten : hiermee kunt u op een virtueel netwerk veilig toegang krijgen tot gegevens via een Private Link.
Juni 2020
- CopyModel-API toegevoegd aan clientbibliotheken : u kunt nu de clientbibliotheken gebruiken om modellen van het ene abonnement naar het andere te kopiëren. Zie Back-ups maken en modellen herstellen voor algemene informatie over deze functie.
- Azure Active Directory-integratie : u kunt nu uw Azure AD-referenties gebruiken om uw Document Intelligence-clientobjecten in de clientbibliotheken te verifiëren.
- SDK-specifieke wijzigingen : deze wijziging omvat zowel kleine functietoevoegingen als belangrijke wijzigingen. Zie de SDK-wijzigingenlogboeken voor meer informatie.
April 2020
- SDK-ondersteuning voor document intelligence-API v2.0 openbare preview : deze maand hebben we onze serviceondersteuning uitgebreid met een preview-SDK voor Document Intelligence v2.0-release. Gebruik deze koppelingen om aan de slag te gaan met uw gewenste taal:
- .NET SDK
- Java SDK
- Python SDK
- JavaScript SDK
De nieuwe SDK ondersteunt alle functies van de v2.0 REST API voor Document Intelligence. U kunt uw feedback over de clientbibliotheken delen via het SDK-feedbackformulier.
Aangepast model kopiëren U kunt nu modellen kopiëren tussen regio's en abonnementen met behulp van de nieuwe functie Aangepast model kopiëren. Voordat u de COPY Custom Model-API aanroept, moet u eerst autorisatie verkrijgen om naar de doelresource te kopiëren. Deze autorisatie wordt beveiligd door de kopieerautorisatiebewerking aan te roepen voor het doelresource-eindpunt.
Beveiligingsverbeteringen.
Door de klant beheerde sleutels zijn nu beschikbaar voor FormRecognizer. Zie Data Encryption-at-rest voor Document Intelligence voor meer informatie.
Beheerde identiteiten gebruiken voor toegang tot Azure-resources met Azure Active Directory. Zie Toegang tot beheerde identiteiten autoriseren voor meer informatie.
Maart 2020
- Waardetypen voor labelen U kunt nu de typen waarden opgeven die u labelt met het hulpprogramma Document Intelligence-voorbeeldlabels. De volgende waardetypen en variaties worden momenteel ondersteund:
string- standaard,
no-whitespaces,alphanumeric
- standaard,
number- standaard,
currency
- standaard,
date- standaard,
dmy,mdy,ymd
- standaard,
timeinteger
Zie de handleiding voorbeeldhulpprogramma voor labelen voor meer informatie over het gebruik van deze functie.
Tabelvisualisatie Het hulpprogramma Voorbeeldlabeling geeft nu tabellen weer die in het document zijn herkend. Met deze functie kunt u herkende en geëxtraheerde tabellen uit het document bekijken voordat u labelt en analyseert. Deze functie kan worden in-/uitgeschakeld met behulp van de optie Lagen.
De volgende afbeelding is een voorbeeld van hoe tabellen worden herkend en geëxtraheerd:
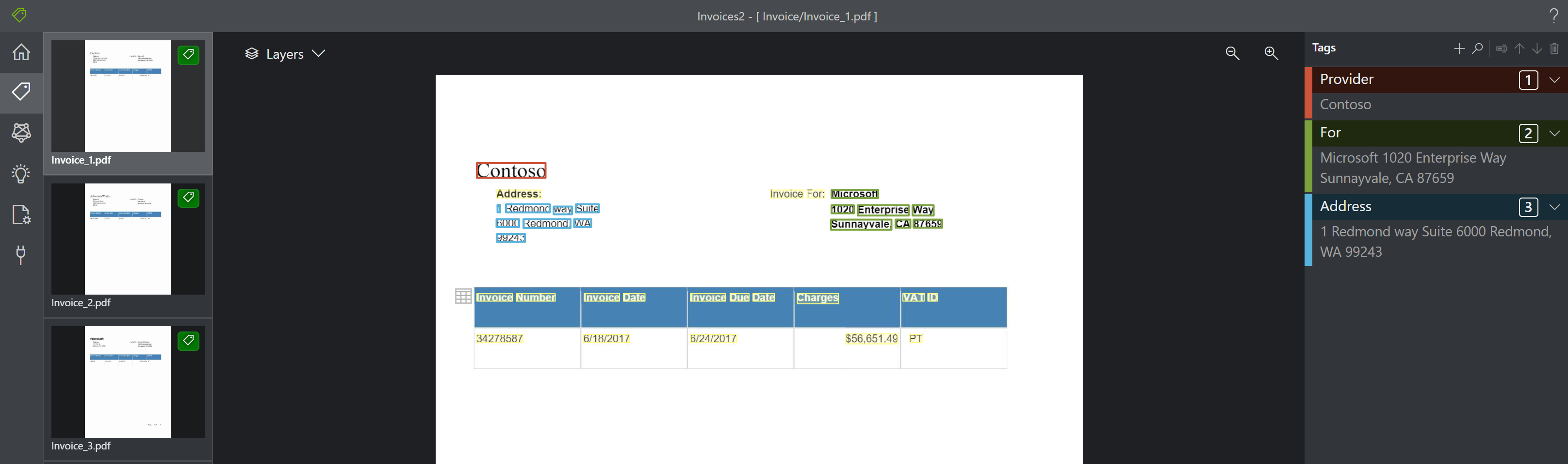
De geëxtraheerde tabellen zijn beschikbaar in de JSON-uitvoer onder
"pageResults".Belangrijk
Labelen van tabellen wordt niet ondersteund. Als tabellen niet automatisch worden herkend en geëxtraheerd, kunt u ze alleen labelen als sleutel-/waardeparen. Wanneer u tabellen labelt als sleutel-waardeparen, labelt u elke cel als een unieke waarde.
Verbeteringen in extractie.
Deze release bevat extractieverbeteringen en nauwkeurigheidsverbeteringen, met name de mogelijkheid om meerdere sleutel-/waardeparen in dezelfde tekstregel te labelen en te extraheren.
Voorbeeldhulpprogramma voor labelen is nu opensource.
Het hulpprogramma Document Intelligence-voorbeeldlabels is nu beschikbaar als een opensource-project. U kunt deze integreren in uw oplossingen en klantspecifieke wijzigingen aanbrengen om aan uw behoeften te voldoen.
Raadpleeg de documentatie die beschikbaar is op GitHub voor meer informatie over het hulpprogramma Document Intelligence-voorbeeldlabels.
TLS1.2 handhaving.TLS1.2 wordt nu afgedwongen voor alle HTTP-aanvragen voor deze service. Zie Beveiliging van Azure AI-services voor meer informatie.
Januari 2020
In deze release wordt documentinformatie 2.0 geïntroduceerd. In de volgende secties vindt u meer informatie over nieuwe functies, verbeteringen en wijzigingen.
Nieuwe functies
Aangepast model
- Trainen met labels U kunt nu een aangepast model trainen met handmatig gelabelde gegevens. Deze methode resulteert in beter presterende modellen en kan modellen produceren die werken met complexe formulieren of formulieren die waarden zonder sleutels bevatten.
- Asynchrone API U kunt asynchrone API-aanroepen gebruiken om grote gegevenssets en bestanden te trainen en te analyseren.
- TIFF-bestandsondersteuning U kunt nu trainen met en gegevens extraheren uit TIFF-documenten.
- Nauwkeurigheidsverbeteringen voor extractie.
Vooraf samengesteld ontvangstbewijsmodel
- Tipbedragen U kunt nu tipbedragen en andere handgeschreven waarden extraheren.
- Regelitemextractie U kunt regelitemwaarden extraheren uit ontvangstbevestigingen.
- Betrouwbaarheidswaarden U kunt het vertrouwen van het model voor elke geëxtraheerde waarde bekijken.
- Nauwkeurigheidsverbeteringen voor extractie.
- Indelingextractie U kunt nu de Layout-API gebruiken om tekstgegevens en tabelgegevens uit uw formulieren te extraheren.
Wijzigingen in aangepaste model-API
Alle API's voor het trainen en gebruiken van aangepaste modellen worden hernoemd en sommige synchrone methoden zijn nu asynchroon. Hier volgen belangrijke wijzigingen:
- Het proces van het trainen van een model is nu asynchroon. U start de training via de API-aanroep /custom/models . Deze aanroep retourneert een bewerkings-id, die u kunt doorgeven aan aangepaste/modellen/{modelID} om de trainingsresultaten te retourneren.
- Sleutel-/waardeextractie wordt nu gestart door de API-aanroep /custom/models/{modelID}/analyze . Deze aanroep retourneert een bewerkings-id, die u kunt doorgeven aan aangepaste/modellen/{modelID}/analyzeResults/{resultID} om de extractieresultaten te retourneren.
- Bewerkings-id's voor de trainbewerking vindt u nu in de locatieheader van HTTP-antwoorden, niet in de header Operation-Location .
Wijzigingen in de ontvangst-API
De API's voor het lezen van verkoopbevestigingen worden hernoemd.
Extractie van ontvangstgegevens wordt nu gestart door de API-aanroep /prebuilt/receipt/analyze . Deze aanroep retourneert een bewerkings-id, die u kunt doorgeven aan /prebuilt/receipt/analyzeResults/{resultID} om de extractieresultaten te retourneren.
Wijzigingen in uitvoerindeling
- De JSON-antwoorden voor alle API-aanroepen hebben nieuwe indelingen. Sommige sleutels en waarden worden toegevoegd, verwijderd of hernoemd. Zie de quickstarts voor voorbeelden van de huidige JSON-indelingen.
Volgende stappen
Probeer uw eigen formulieren en documenten te verwerken met Document Intelligence Studio.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.
Probeer uw eigen formulieren en documenten te verwerken met het hulpprogramma Document Intelligence Sample Labeling.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.