Antipatroon Intensieve I/O
Het cumulatieve effect van een groot aantal I/O-aanvragen kan aanzienlijke gevolgen hebben voor de prestaties en reactiesnelheid.
Beschrijving van het probleem
Netwerkaanroepen en andere I/O-bewerkingen zijn inherent traag in vergelijking met rekentaken. Elke I/O-aanvraag heeft meestal een aanzienlijke overhead en het cumulatieve effect van talrijke I/O-bewerkingen kan het systeem vertragen. Hier volgen enkele veelvoorkomende oorzaken van intensieve I/O.
Lezen en schrijven van afzonderlijke records naar een database als afzonderlijke aanvragen
In het volgende voorbeeld worden gegevens gelezen uit een database met producten. Er zijn drie tabellen: Product, ProductSubcategory en ProductPriceListHistory. Met de code worden alle producten in een subcategorie opgehaald, samen met de prijsinformatie, door een reeks query's uit te voeren:
- Een query uitvoeren op de subcategorie van de tabel
ProductSubcategory. - Alle producten in die subcategorie vinden door een query uit te voeren op de tabel
Product. - Voor elk product de prijsinformatie opvragen via een query op de tabel
ProductPriceListHistory.
De toepassing gebruikt Entity Framework om de database te bevragen. U vindt het complete voorbeeld hier.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
Dit voorbeeld toont het probleem expliciet aan, maar soms kan het probleem worden gemaskeerd door een O/RM en worden onderliggende records één voor één impliciet opgehaald. Dit staat bekend als het 'N+1-probleem'.
Eén logische bewerking implementeren als een reeks HTTP-aanvragen
Dit gebeurt vaak als ontwikkelaars proberen een objectgeoriënteerd paradigma te volgen en externe objecten behandelen alsof het lokale objecten in het geheugen zijn. Dit kan resulteren in te veel 'round trips' in het netwerk. Met de volgende web-API worden bijvoorbeeld de individuele eigenschappen van User-objecten beschikbaar gemaakt via afzonderlijke HTTP GET-methoden.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
Hoewel er technisch niets mis is met deze aanpak, zullen de meeste clients waarschijnlijk verschillende eigenschappen moeten ophalen voor elke User, wat resulteert in clientcode zoals deze.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Lezen en schrijven naar een bestand op schijf
Bestands-I/O omvat het openen van een bestand en het opzoeken van het juiste punt voordat gegevens kunnen worden gelezen of geschreven. Wanneer de bewerking is voltooid, kan het bestand worden gesloten om resources van het besturingssysteem te besparen. Een toepassing die voortdurend kleine hoeveelheden gegevens leest en schrijft naar een bestand zal nog steeds een aanzienlijke I/O-overhead genereren. Kleine schrijfaanvragen kunnen ook leiden tot bestandsfragmentatie, waardoor volgende I/O-bewerkingen nog verder worden vertraagd.
In het volgende voorbeeld wordt een FileStream gebruikt om een Customer-object weg te schrijven naar een bestand. Het bestand wordt geopend door het maken van het FileStream-object en het wordt weer gesloten zodra het object is verwijderd. (Met de using instructie wordt het FileStream object automatisch verwijderd.) Als de toepassing deze methode herhaaldelijk aanroept wanneer nieuwe klanten worden toegevoegd, kan de I/O-overhead snel oplopen.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
Het probleem oplossen
Verminder het aantal I/O-aanvragen door de gegevens te verpakken in grotere, en dus minder, aanvragen.
Gebruik één query om gegevens op te halen uit een database in plaats van meerdere kleinere query's. Hier volgt een aangepaste versie van de code voor het ophalen van productinformatie.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Hanteer de REST-ontwerpprincipes voor web-API's. Hieronder ziet u een bijgewerkte versie van de web-API uit het eerdere voorbeeld. In plaats van afzonderlijke GET-methoden te gebruiken voor elke eigenschap, wordt er één GET-methode gebruikt die de User retourneert. Dit resulteert in een grotere antwoordtekst per aanvraag, maar elke client zal waarschijnlijk minder API-aanroepen nodig hebben.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
Voor bestands-I/O kunt u overwegen om gegevens te bufferen in het geheugen en vervolgens de gebufferde gegevens in één bewerking weg te schrijven naar een bestand. Deze aanpak vermindert de overhead die het gevolg is van het herhaaldelijk openen en sluiten van het bestand, en vermindert ook de fragmentatie van het bestand op schijf.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Overwegingen
De eerste twee voorbeelden resulteren in minder I/O-aanroepen, maar met elk voorbeeld wordt meer informatie opgehaald. U moet een afweging maken tussen deze twee factoren. Het juiste antwoord wordt bepaald door de werkelijke gebruikspatronen. In het voorbeeld met de web API kan het zo zijn dat clients vaak alleen de gebruikersnaam nodig hebben. In dat geval kan het zinvol zijn om deze beschikbaar te maken als een afzonderlijke API-aanroep. Zie voor meer informatie het antipatroon Ophalen van overbodige gegevens.
Bij het lezen van gegevens is het belangrijk dat u de I/O-aanvragen niet te groot maakt. Een toepassing moet alleen de gegevens ophalen die waarschijnlijk zullen worden gebruikt.
Soms helpt het om de gegevens voor een object op te splitsen in twee categorieën: veelgebruikte gegevens, die nodig zijn voor de meeste aanvragen, en minder vaak gebruikte gegevens, die bijna nooit worden gebruikt. Vaak vormen de meestgebruikte gegevens maar een relatief klein deel van de totale gegevens voor een object, zodat er aanzienlijk kan worden bespaard op de I/O-overhead door alleen dat deel te retourneren.
Bij het wegschrijven van gegevens is het belangrijk om resources niet langer te vergrendelen dan nodig is om zo de kans op conflicten tijdens een langdurige bewerking te verminderen. Als een schrijfbewerking meerdere gegevensarchieven, bestanden of services omvat, kiest u voor een uiteindelijk consistent benadering. Zie deze richtlijnen voor gegevensconsistentie (Engelstalig) voor meer informatie.
Als u gegevens in het geheugen buffert voordat deze worden weggeschreven, zijn de gegevens kwetsbaar als het proces vastloopt. Als de gegevensstroom wordt gekenmerkt door bursts met gegevens of juist verspreide gegevens, kan het veiliger zijn om de gegevens te bufferen in een externe, duurzame wachtrij zoals Event Hubs.
Het kan een optie zijn om gegevens die u ophaalt uit een service of database te cachen. Op deze manier kan de hoeveelheid I/O worden verlaagd door herhaalde verzoeken voor dezelfde gegevens te vermijden. Zie voor meer informatie de aanbevolen procedures voor caching.
Het probleem vaststellen
Symptomen van intensieve I/O zijn hoge latentie en lage doorvoer. Eindgebruikers zullen waarschijnlijk lange reactietijden melden of fouten die worden veroorzaakt door de time-out van services, dit alles als gevolg van conflicten om I/O-resources.
U kunt de volgende stappen uitvoeren om de oorzaken van een probleem vast te stellen:
- Monitor de processen van het productiesysteem om bewerkingen met slechte responstijden te identificeren.
- Voer belastingstests uit van de bewerkingen die zijn geïdentificeerd in de vorige stap.
- Verzamel tijdens de tests telemetriegegevens van de aanvragen voor gegevenstoegang door elke bewerking.
- Verzamel gedetailleerde statistieken voor elke aanvraag die naar een gegevensarchief wordt verzonden.
- Profileer de toepassing in de testomgeving om te bepalen waar mogelijke I/O-knelpunten kunnen bestaan.
Kijk of er sprake is van deze symptomen:
- Een groot aantal kleine I/O-aanvragen voor hetzelfde bestand.
- Een groot aantal kleine netwerkaanvragen van een exemplaar van een toepassing naar dezelfde service.
- Een groot aantal kleine aanvragen van een exemplaar van een toepassing naar hetzelfde gegevensarchief.
- Toepassingen en services die afhankelijk zijn van I/O.
Voorbeeld van diagnose
In de volgende secties worden deze stappen toegepast op het eerdere voorbeeld over het bevragen van een database.
De belasting van de toepassing testen
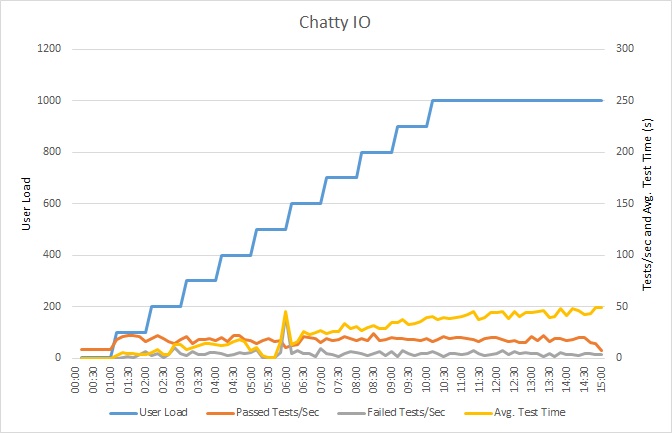
Deze grafiek toont de resultaten van de belastingstests. De gemiddelde reactietijd wordt gemeten in tienden van een seconde per aanvraag. De grafiek toont een zeer hoge latentie. Bij een belasting van 1000 gebruikers moet een gebruiker misschien wel een minuut wachten om de resultaten van een query te zien.
Notitie
De toepassing is met behulp van Azure SQL Database geïmplementeerd als een web-app van Azure App Service. Tijdens de test is een stapsgewijs opgevoerde werkbelasting gesimuleerd van maximaal 1000 gelijktijdige gebruikers. De database is geconfigureerd met een verbindingsgroep die ondersteuning biedt voor maximaal 1000 gelijktijdige verbindingen, om het risico van beïnvloeding van de resultaten door conflicten over verbindingen te beperken.
Monitoren van de toepassing
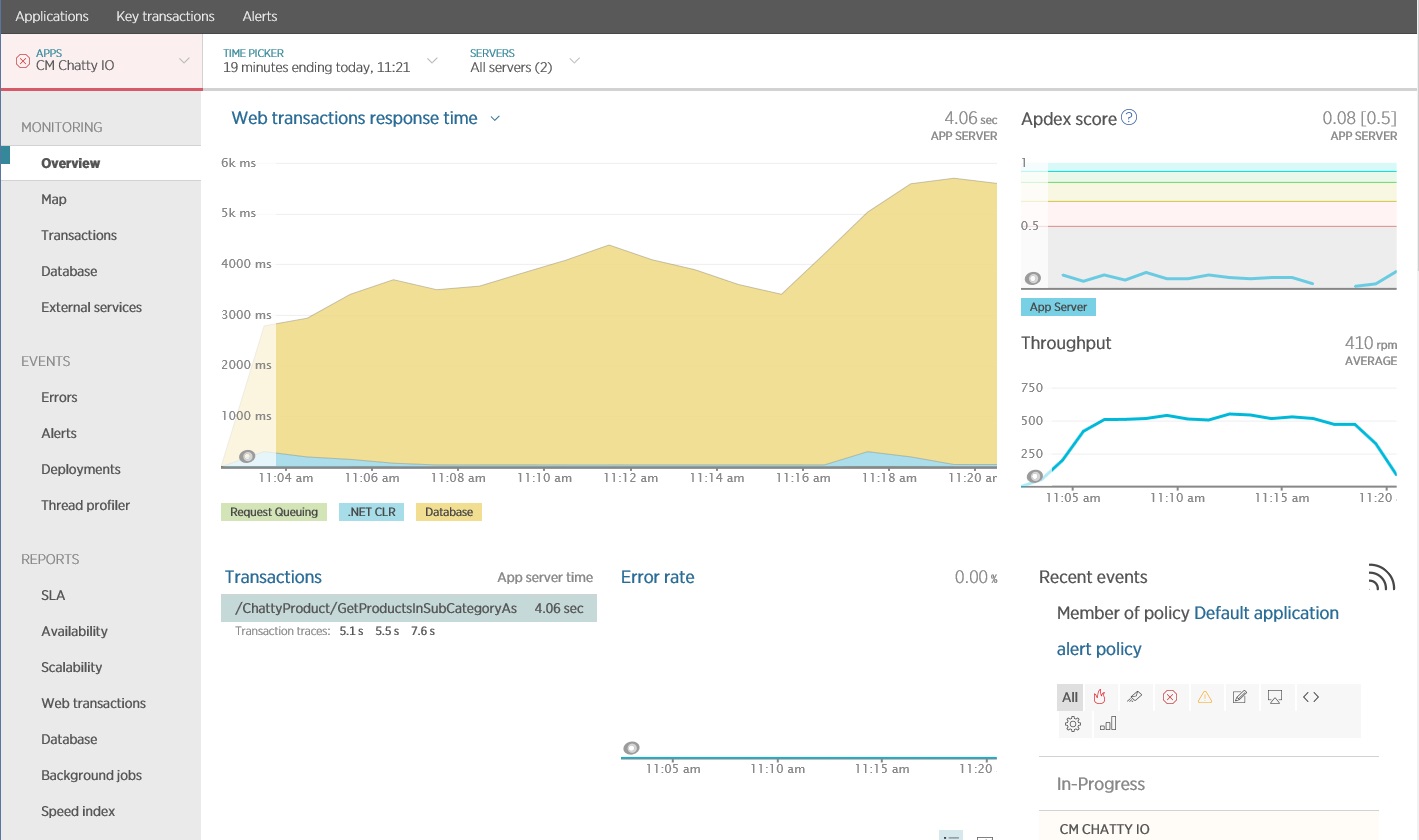
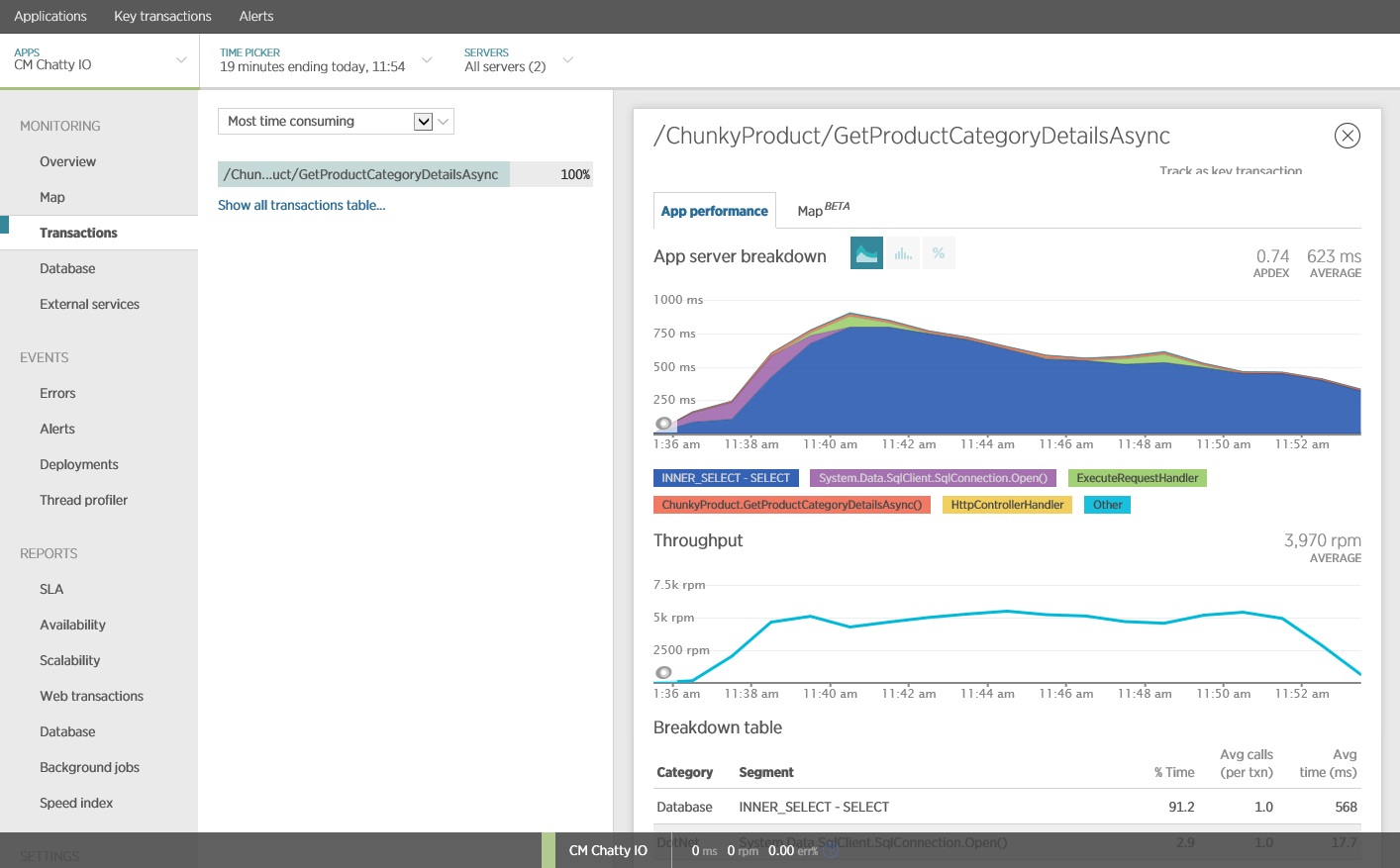
U kunt een APM-pakket (Application Performance Monitoring) gebruiken om de belangrijkste metrische gegevens vast te leggen en te analyseren die intensieve I/O kunnen identificeren. De I/O-werkbelasting bepaalt welke metrische gegevens belangrijk zijn. Voor dit voorbeeld zijn de interessante I/O-aanvragen de databasequery's.
In de volgende afbeelding ziet u de resultaten die zijn gegenereerd met New Relic APM. De langste reactietijd van de gemiddelde database was ongeveer 5,6 seconden per aanvraag tijdens de maximale werkbelasting. Het systeem was in staat om een gemiddelde van 410 aanvragen per minuut te verwerken gedurende de test.
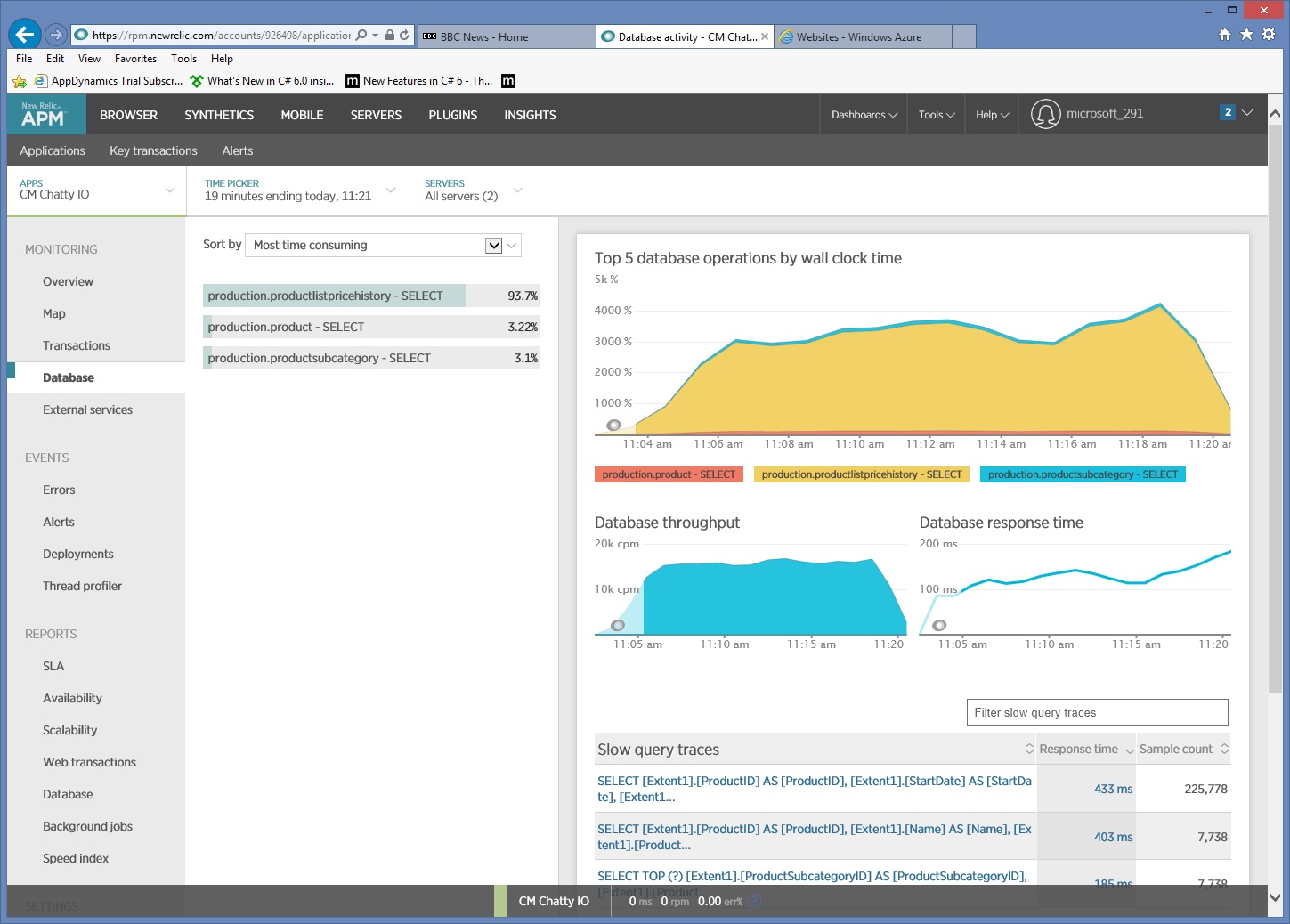
Gedetailleerde informatie over gegevenstoegang verzamelen
Als we de gegevens nader bestuderen, zien we dat de toepassing drie verschillende SQL SELECT-instructies uitvoert. Deze komen overeen met de aanvragen die worden gegenereerd door de Entity Framework voor het ophalen van gegevens uit de tabellen ProductListPriceHistory, Product en ProductSubcategory. Daarnaast wordt duidelijk dat de query waarmee gegevens worden opgehaald uit de tabel ProductListPriceHistory, met een factor 30 de meest uitgevoerde SELECT-instructie is.
Het blijkt dat met de methode GetProductsInSubCategoryAsync, zie hierboven, 45 SELECT-query's worden uitgevoerd. Elke query heeft tot gevolg dat de toepassing een nieuwe SQL-verbinding opent.
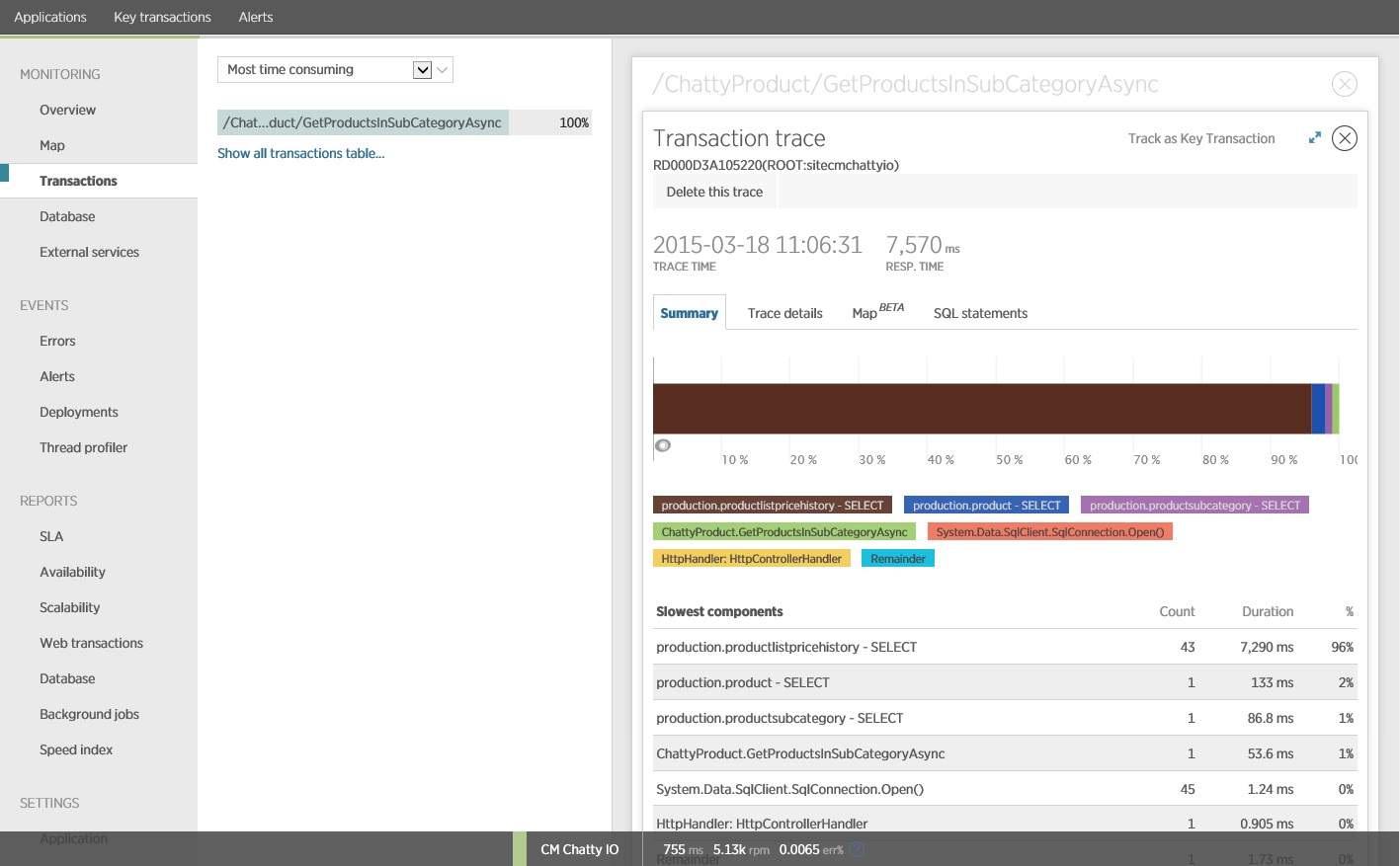
Notitie
Deze afbeelding toont traceringsgegevens voor de langzaamste uitvoering van de bewerking GetProductsInSubCategoryAsync in de belastingstest. In een productieomgeving is het handig om traceringen van de traagste exemplaren te onderzoeken, om te zien of er een patroon is dat een mogelijk probleem aangeeft. Als u alleen naar de gemiddelde waarden kijkt, kunt u problemen over het hoofd zien die aanzienlijk verslechteren naarmate de belasting toeneemt.
De volgende afbeelding toont de SQL-instructies die zijn gegeven. De query voor het ophalen van de prijsgegevens wordt uitgevoerd voor elk afzonderlijk product in de subcategorie met producten. Met behulp van een join kan het aantal databaseaanroepen aanzienlijk worden gereduceerd.
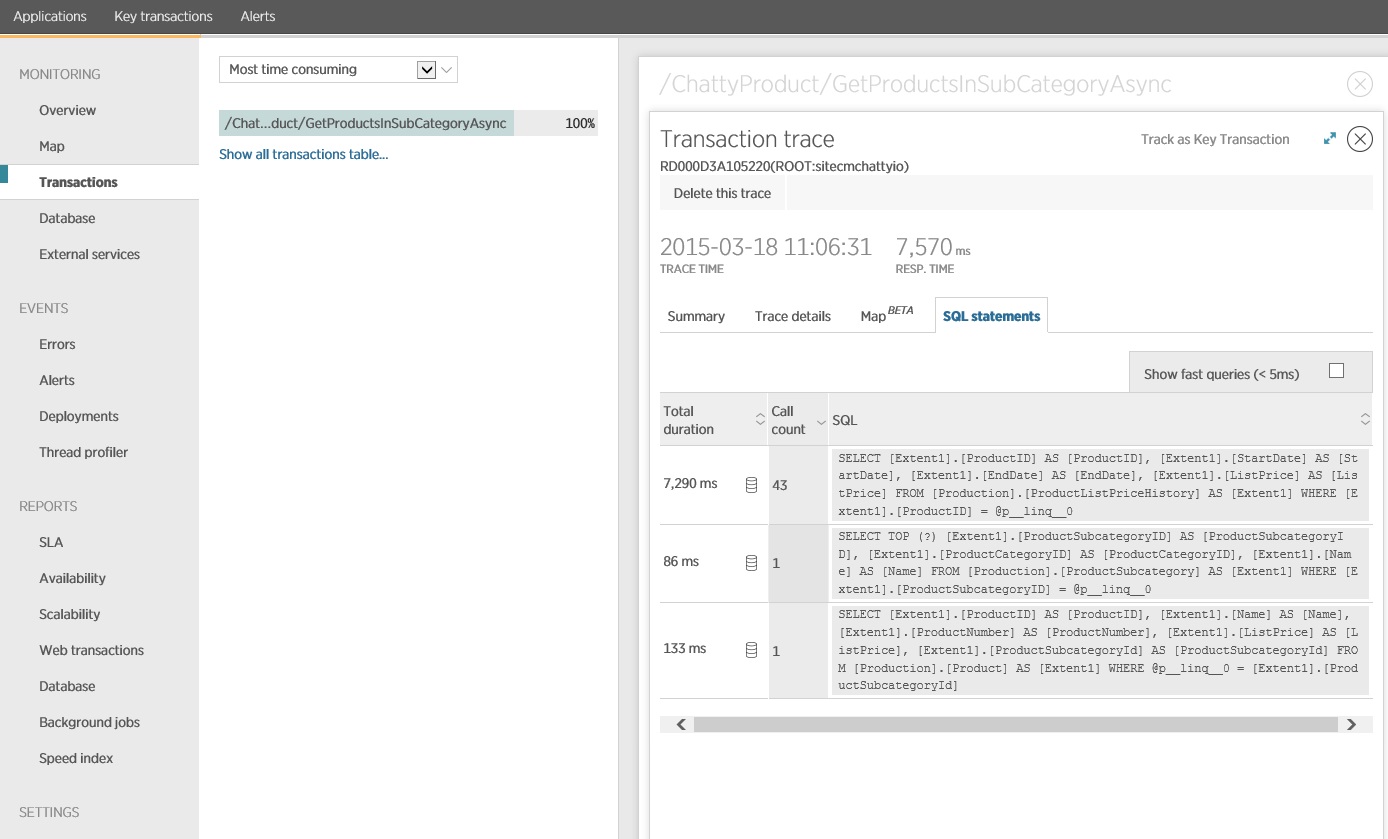
Als u een O/RM, zoals Entity Framework, kan het traceren van de SQL-query's inzicht bieden in de manier waarop O/RM programmatische aanroepen omzet in SQL-instructies om gebieden te herkennen waar de gegevenstoegang kan worden geoptimaliseerd.
De oplossing implementeren en het resultaat controleren
Het herschrijven van de aanroep van Entity Framework levert de volgende resultaten op.
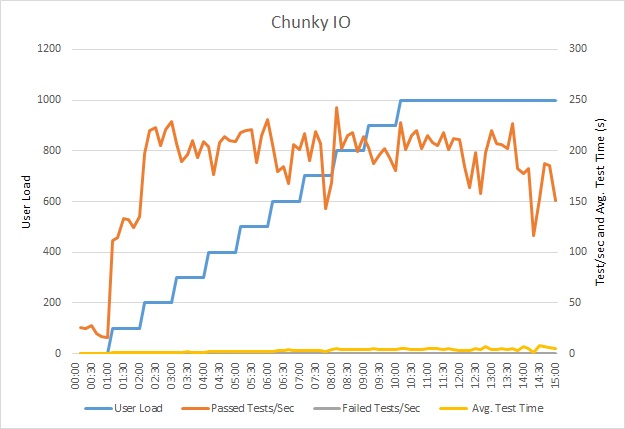
Deze belastingstest is uitgevoerd op dezelfde implementatie, met hetzelfde belastingsprofiel. Deze keer toont de grafiek een veel lagere latentie. De gemiddelde aanvraagtijd op 1000 gebruikers ligt tussen de vijf en zes seconden, in vergelijking met bijna een minuut in het eerdere scenario.
Deze keer ondersteunt het systeem een gemiddelde van 3.970 aanvragen per minuut, wordt vergeleken met 410 voor de eerdere test.
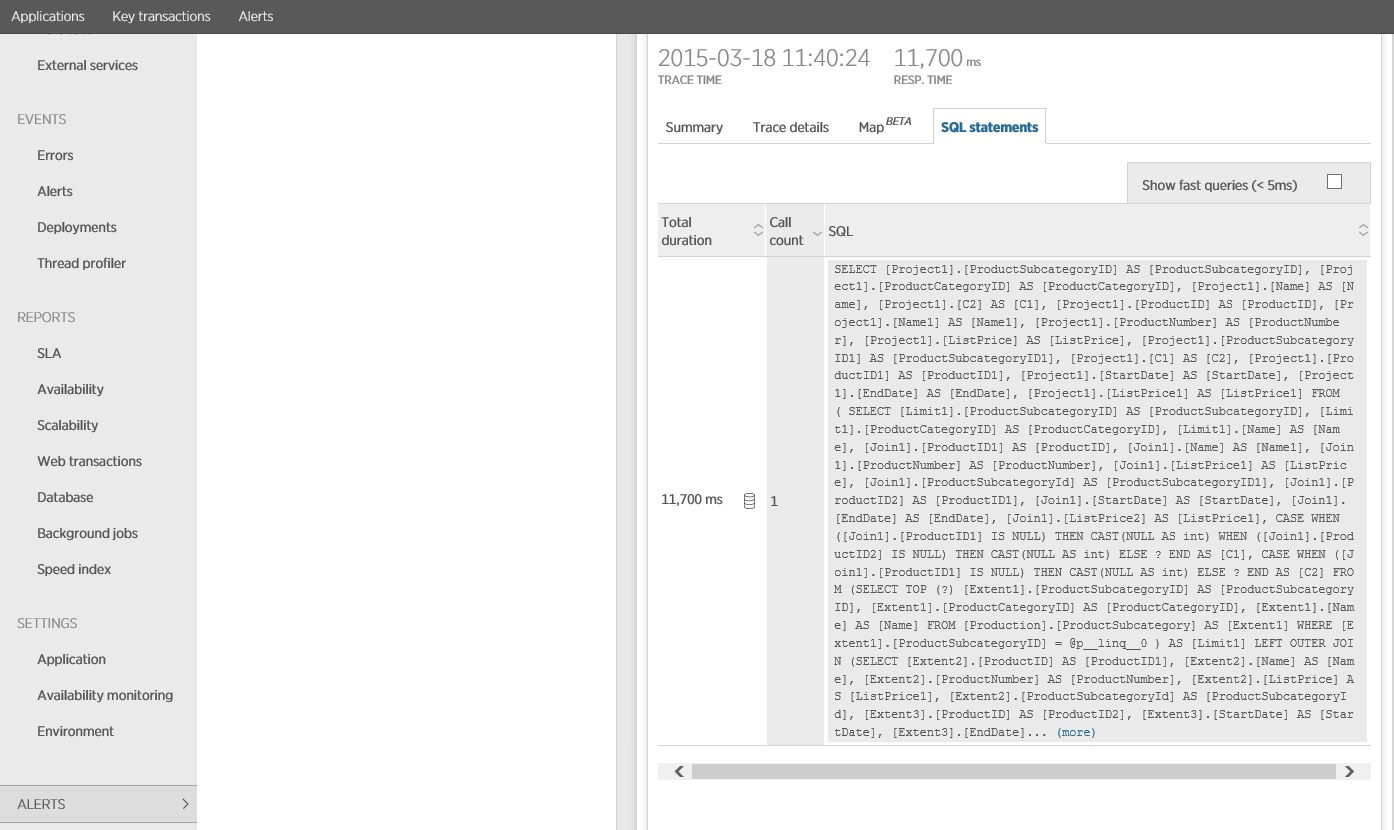
Tracering van de SQL-instructie toont aan dat alle gegevens in één SELECT-instructie worden opgehaald. Hoewel deze query aanzienlijk complexer is, wordt deze maar één keer per bewerking uitgevoerd. En hoewel de kosten van complexe joins kunnen oplopen, zijn relationele databasesystemen geoptimaliseerd voor dit type query.
Verwante resources
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor