Antipatroon monolithische persistentie
Als alle gegevens van een toepassing in één gegevensarchief worden geplaatst, kan dit de prestaties nadelig beïnvloeden, omdat het leidt tot bronconflicten of omdat het gegevensarchief niet geschikt is voor een deel van de gegevens.
Beschrijving van het probleem
In het verleden werd vaak één gegevensarchief gebruikt voor toepassingen, ongeacht de verschillende typen gegevens die de toepassing mogelijk moet opslaan. Dit werd doorgaans gedaan om het toepassingsontwerp te vereenvoudigen of om het ontwerp aan te passen aan de bestaande vaardigheden van het ontwikkelteam.
Moderne systemen in de cloud hebben vaak aanvullende functionele en niet-functionele vereisten en moeten veel heterogene soorten gegevens opslaan, zoals documenten, afbeeldingen, gegevens in de cache, berichten in de wachtrij, toepassingslogboeken en telemetrie. Als u de traditionele aanpak volgt en al deze gegevens in hetzelfde gegevensarchief plaatst, kan dit de prestaties schaden. Dit heeft twee belangrijke redenen:
- Het opslaan en ophalen van grote hoeveelheden niet-gerelateerde gegevens in hetzelfde gegevensarchief kan leiden tot conflicten, die op hun beurt leiden tot trage reactietijden en verbindingsfouten.
- Ongeacht het type gegevensarchief dat is gekozen, is het mogelijk niet de beste keuze voor alle verschillende soorten gegevens, of kan het mogelijk niet worden geoptimaliseerd voor de bewerkingen die de toepassing uitvoert.
Het volgende voorbeeld geeft een ASP.NET Web API-controller weer die een nieuwe record toevoegt aan een database en het resultaat registreert in een logboek. Het logboek is ondergebracht in dezelfde database als de zakelijke gegevens. U vindt het complete voorbeeld hier.
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}
De snelheid waarmee de logboekrecords worden gegenereerd, heeft waarschijnlijk invloed op de prestaties van de bedrijfsactiviteiten. En als een ander onderdeel, zoals een monitor van het toepassingsproces, de logboekgegevens regelmatig leest en verwerkt, kunnen de bedrijfsprocessen ook worden beïnvloed.
Het probleem oplossen
Scheid gegevens op basis van het gebruik. Selecteer een gegevensarchief voor elke gegevensset die het meest geschikt is voor hoe u deze gegevensset gebruikt. In het vorige voorbeeld moet de toepassing logboeken registreren in een archief dat losstaat van de database met de zakelijke gegevens:
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}
Overwegingen
Scheid gegevens op basis van de manier waarop deze worden gebruikt en hoe deze worden geopend. Sla logboekinformatie en zakelijke gegevens bijvoorbeeld niet op in hetzelfde gegevensarchief. Deze typen gegevens hebben aanzienlijk verschillende vereisten en toegangspatronen. Logboekrecords zijn inherent sequentieel, terwijl bedrijfsgegevens waarschijnlijk willekeurige toegang vereisen en vaak relationeel zijn.
Houd rekening met het toegangspatroon voor elk type gegevens. Sla bijvoorbeeld opgemaakte rapporten en documenten op in een documentdatabase zoals Azure Cosmos DB, maar gebruik Azure Cache voor Redis om tijdelijke gegevens in de cache op te slaan.
Als u deze richtlijnen volgt, maar de limieten van de database nog steeds bereikt, moet u de database wellicht omhoog schalen. U kunt ook horizontaal schalen en de belasting partitioneren op databaseservers. Voor partitionering moet u de toepassing echter mogelijk opnieuw ontwerpen. Raadpleeg voor meer informatie Gegevens partitioneren.
Het probleem vaststellen
Het systeem wordt waarschijnlijk aanzienlijk vertraagd en geeft uiteindelijk foutmeldingen wanneer het niet meer genoeg bronnen heeft, zoals databaseverbindingen.
U kunt de volgende stappen uitvoeren om het probleem te identificeren.
- Laat het systeem belangrijke prestatiestatistieken vastleggen. Leg tijdgegevens vast voor elke bewerking, evenals de momenten waarop de toepassing gegevens leest en schrijft.
- Bewaak het systeem indien mogelijk een paar dagen terwijl het is ingeschakeld in een productieomgeving om een goed idee te krijgen van hoe het systeem wordt gebruikt. Als dit niet mogelijk is, kunt u geprogrammeerde belastingtests uitvoeren met een realistisch aantal virtuele gebruikers dat een typische reeks bewerkingen uitvoert.
- Gebruik de telemetriegegevens om perioden met slechte prestaties te identificeren.
- Achterhaal welke gegevensarchieven tijdens deze perioden zijn geopend.
- Identificeer gegevensrchiefbronnen waarin mogelijk conflicten optreden.
Voorbeeld van diagnose
In de volgende secties worden deze stappen toegepast op de voorbeeldtoepassing die eerder is beschreven.
Instrumenteer en bewaak het systeem
In het volgende diagram ziet u de resultaten van een belastingstest van de voorbeeldtoepassing die we eerder hebben beschreven. De test gebruikt een stapsgewijze belasting van maximaal 1000 gelijktijdige gebruikers.
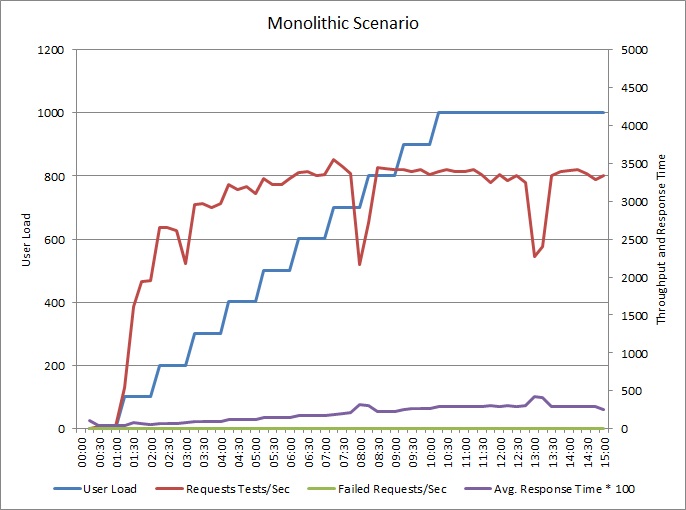
Wanneer de belasting tot 700 gebruikers toeneemt, geldt dat ook voor de doorvoer. Maar op dat moment stijgt de doorvoer niet meer en lijkt het systeem op de maximale capaciteit te worden uitgevoerd. De gemiddelde reactietijd stijgt geleidelijk, naarmate de gebruikersbelasting toeneemt. Het is te zien het systeem de vraag niet kan bijbenen.
Identificeer perioden waarin de prestaties slecht zijn
Als u het productiesysteem bewaakt, ziet u mogelijk patronen. De reactietijden worden bijvoorbeeld mogelijk elke dag op hetzelfde moment erg lang. Dit kan worden veroorzaakt door een reguliere werkbelasting of geplande batchverwerking, of gewoon doordat het systeem meer gebruikers heeft op bepaalde tijden. U moet u richten op de telemetriegegevens voor deze gebeurtenissen.
Zoek naar correlaties tussen verhoogde reactietijden en verhoogde activiteit in de database of I/O-bewerkingen naar gedeelde bronnen. Als u correlaties vindt, betekent dit dat de database mogelijk een knelpunt is.
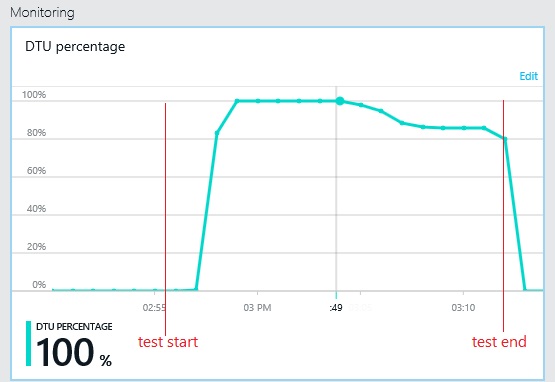
Achterhaal welke gegevensarchieven tijdens deze perioden zijn geopend
Het volgende diagram toont het gebruik van de doorvoereenheden van de database (DTU) tijdens de belastingtest. (Een DTU is een meting van de beschikbare capaciteit en is een combinatie van CPU-gebruik, geheugentoewijzing, I/O-snelheid.) Het gebruik van DTU's bereikt snel 100%. Dit is ongeveer het punt waarop de doorvoer een piek vertoonde in de vorige grafiek. Het databasegebruik bleef zeer hoog tot het einde van de test. Er is een lichte afname te zien aan het einde van de test. Dit kan worden veroorzaakt door een beperking, concurrentie voor databaseverbindingen of andere factoren.
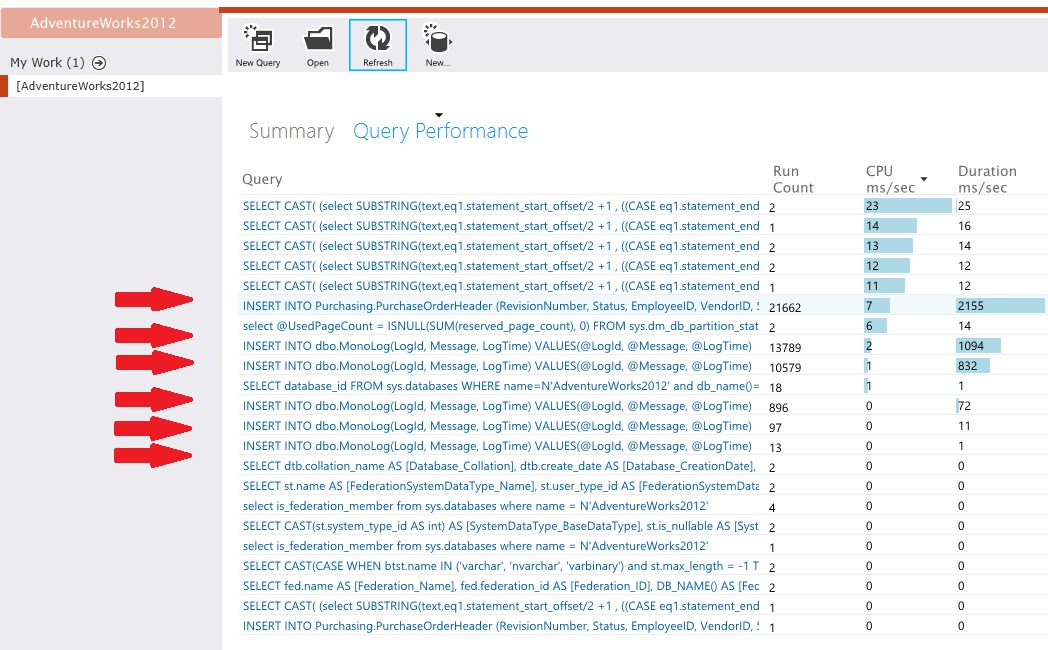
Bekijk de telemetrie voor de gegevensarchieven
Laat de gegevensarchieven de details op laag niveau van de activiteit vastleggen. In de voorbeeldtoepassing blijkt uit de statistieken voor gegevenstoegang dat een groot aantal invoerbewerkingen werd uitgevoerd op zowel de PurchaseOrderHeader-tabel als de MonoLog-tabel.
Identificeer bronconflicten
Op dit moment kunt u de broncode bekijken. Focus op de punten waarop de toepassing de conflicterende bronnen gebruikt. Zoek naar situaties zoals:
- Gegevens die logisch zijn gescheiden, maar naar hetzelfde archief worden geschreven. Gegevens, zoals logboeken, rapporten en berichten in de wachtrij moeten niet worden ondergebracht in dezelfde database als bedrijfsgegevens.
- Een discrepantie tussen de keuze van gegevensarchief en het type gegevens, zoals grote blobs of XML-documenten in een relationele database.
- Gegevens met aanmerkelijk verschillende gebruikspatronen die dezelfde opslag gebruiken, zoals gegevens met veel schrijfbewerkingen en weinig leesbewerkingen die worden opgeslagen met gegevens met weinig schrijfbewerkingen en veel leesbewerkingen.
De oplossing implementeren en het resultaat controleren
De toepassing is gewijzigd zodat logboeken naar een afzonderlijk gegevensarchief worden geschreven. Hier volgen de resultaten van de belastingtest:
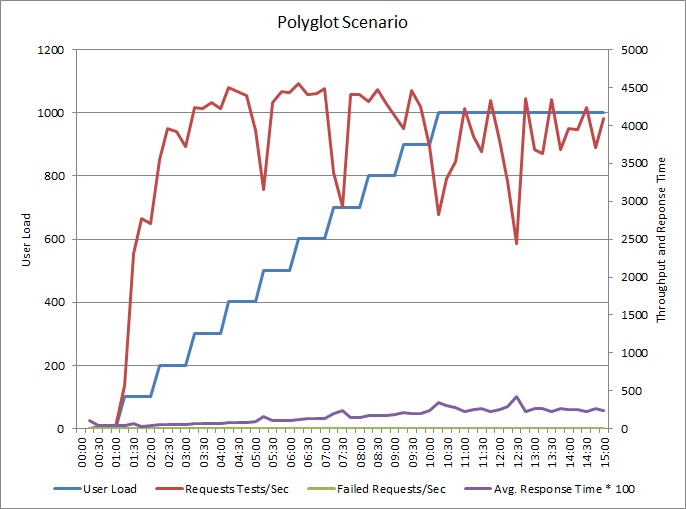
Het doorvoerpatroon is vergelijkbaar met de vorige grafiek, maar het punt waarop pieken in de prestaties optreden, ligt ongeveer 500 aanvragen per seconde hoger. De gemiddelde reactietijd is nu veel lager. Deze statistieken laten echter niet het volledige verhaal zien. Uit telemetrie voor de zakelijke database business blijkt dat er een piek optreedt in het DTU-gebruik rond ongeveer 75% in plaats van 100%.
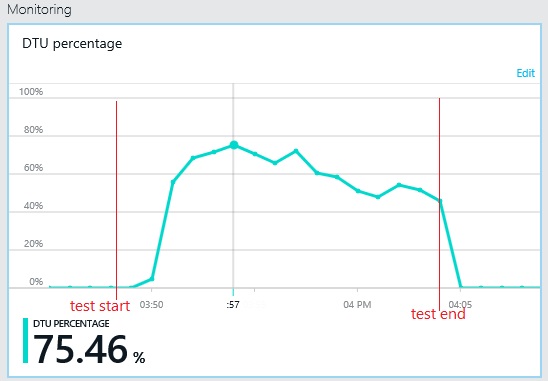
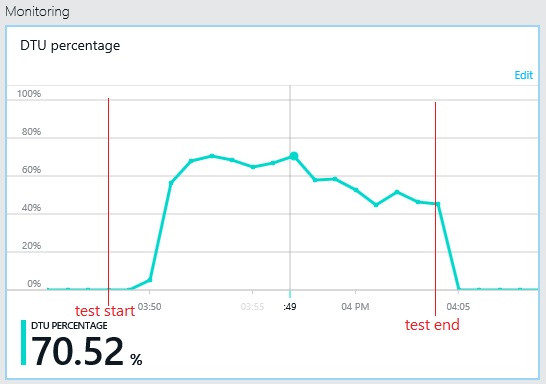
Het maximale DTU-gebruik van de logboekdatabase bereikt eveneens slechts 70%. De databases zijn niet langer de beperkende factor voor de prestaties van het systeem.
Verwante resources
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor