Knooppunt- en podstatus onderzoeken
Dit artikel maakt deel uit van een serie. Begin met het overzicht.
Als het cluster controleert dat u in de vorige stap hebt uitgevoerd, controleert u de status van de AKS-werkknooppunten (Azure Kubernetes Service). Volg de zes stappen in dit artikel om de status van knooppunten te controleren, de reden voor een beschadigd knooppunt te bepalen en het probleem op te lossen.
Stap 1: De status van werkknooppunten controleren
Verschillende factoren kunnen bijdragen aan beschadigde knooppunten in een AKS-cluster. Een veelvoorkomende reden is de uitsplitsing van de communicatie tussen het besturingsvlak en de knooppunten. Deze miscommunicatie wordt vaak veroorzaakt door onjuiste configuraties in routerings- en firewallregels.
Wanneer u uw AKS-cluster configureert voor door de gebruiker gedefinieerde routering, moet u uitgaande paden configureren via een virtueel netwerkapparaat (NVA) of een firewall, zoals een Azure-firewall. Als u een probleem met onjuiste configuratie wilt oplossen, raden we u aan de firewall zo te configureren dat de benodigde poorten en FQDN's (Fully Qualified Domain Names) zijn toegestaan in overeenstemming met de richtlijnen voor uitgaand verkeer van AKS.
Een andere reden voor beschadigde knooppunten is mogelijk onvoldoende reken-, geheugen- of opslagresources die kubelet-druk maken. In dergelijke gevallen kan het opschalen van de resources het probleem effectief oplossen.
In een privé-AKS-cluster kunnen DNS-omzettingsproblemen (Domain Name System) communicatieproblemen veroorzaken tussen het besturingsvlak en de knooppunten. U moet controleren of de DNS-naam van de Kubernetes-API-server wordt omgezet in het privé-IP-adres van de API-server. Onjuiste configuratie van een aangepaste DNS-server is een veelvoorkomende oorzaak van DNS-omzettingsfouten. Als u aangepaste DNS-servers gebruikt, moet u ervoor zorgen dat u deze correct opgeeft als DNS-servers in het virtuele netwerk waar knooppunten worden ingericht. Controleer ook of de privé-API-server van AKS kan worden omgezet via de aangepaste DNS-server.
Nadat u deze potentiële problemen met betrekking tot communicatie tussen besturingsvlakken en DNS-omzetting hebt opgelost, kunt u problemen met de knooppuntstatus in uw AKS-cluster effectief aanpakken en oplossen.
U kunt de status van uw knooppunten evalueren met behulp van een van de volgende methoden.
Statusweergave van Azure Monitor-containers
Volg deze stappen om de status van knooppunten, gebruikerspods en systeempods in uw AKS-cluster weer te geven:
- Ga in Azure Portal naar Azure Monitor.
- Selecteer Containers in de sectie Inzichten van het navigatiedeelvenster.
- Selecteer Bewaakte clusters voor een lijst met de AKS-clusters die worden bewaakt.
- Kies een AKS-cluster in de lijst om de status van de knooppunten, gebruikerspods en systeempods weer te geven.

Weergave AKS-knooppunten
Volg deze stappen om ervoor te zorgen dat alle knooppunten in uw AKS-cluster de status Gereed hebben:
- Ga in Azure Portal naar uw AKS-cluster.
- Selecteer Knooppuntgroepen in het Instellingen gedeelte van het navigatiedeelvenster.
- Selecteer Knooppunten.
- Controleer of alle knooppunten de status Gereed hebben.

Bewaking in clusters met Prometheus en Grafana
Als u Prometheus en Grafana in uw AKS-cluster hebt geïmplementeerd, kunt u het K8 Cluster Detail Dashboard gebruiken om inzichten te verkrijgen. Dit dashboard toont metrische gegevens van Prometheus-clusters en bevat essentiële informatie, zoals CPU-gebruik, geheugengebruik, netwerkactiviteit en bestandssysteemgebruik. Er worden ook gedetailleerde statistieken weergegeven voor afzonderlijke pods, containers en systeemservices .
Selecteer in het dashboard Knooppuntvoorwaarden om metrische gegevens te bekijken over de status en prestaties van uw cluster. U kunt knooppunten bijhouden die problemen kunnen hebben, zoals problemen met hun planning, het netwerk, schijfdruk, geheugendruk, proportionele integraal afgeleide druk (PID) of schijfruimte. Bewaak deze metrische gegevens, zodat u proactief potentiële problemen kunt identificeren en oplossen die van invloed zijn op de beschikbaarheid en prestaties van uw AKS-cluster.

Beheerde service bewaken voor Prometheus en Azure Managed Grafana
U kunt vooraf gemaakte dashboards gebruiken om metrische gegevens van Prometheus te visualiseren en analyseren. Hiervoor moet u uw AKS-cluster instellen voor het verzamelen van metrische Prometheus-gegevens in de beheerde Service voor Prometheus en uw Monitor-werkruimte verbinden met een Azure Managed Grafana-werkruimte . Deze dashboards bieden een uitgebreide weergave van de prestaties en status van uw Kubernetes-cluster.
De dashboards worden ingericht in het opgegeven Azure Managed Grafana-exemplaar in de map Managed Prometheus . Enkele dashboards zijn:
- Kubernetes/Rekenresources/Cluster
- Kubernetes/Compute-resources/naamruimte (pods)
- Kubernetes/Rekenresources/knooppunt (pods)
- Kubernetes/Rekenresources/Pod
- Kubernetes/Rekenresources/Naamruimte (workloads)
- Kubernetes/rekenresources/workload
- Kubernetes/Kubelet
- Knooppuntexporteur/USE-methode/knooppunt
- Knooppuntexporteur/knooppunten
- Kubernetes/Rekenresources/Cluster (Windows)
- Kubernetes/Rekenresources/Naamruimte (Windows)
- Kubernetes/Rekenresources/Pod (Windows)
- Kubernetes/USE-methode/cluster (Windows)
- Kubernetes/USE Method/Node (Windows)
Deze ingebouwde dashboards worden veel gebruikt in de opensource-community voor het bewaken van Kubernetes-clusters met Prometheus en Grafana. Gebruik deze dashboards om metrische gegevens weer te geven, zoals resourcegebruik, podstatus en netwerkactiviteit. U kunt ook aangepaste dashboards maken die zijn afgestemd op uw bewakingsbehoeften. Dashboards helpen u bij het effectief bewaken en analyseren van metrische Prometheus-gegevens in uw AKS-cluster, waarmee u de prestaties kunt optimaliseren, problemen kunt oplossen en de werking van uw Kubernetes-workloads soepel kunt laten verlopen.
U kunt het kubernetes-/rekenresources-/knooppuntdashboard (pods) gebruiken om metrische gegevens voor uw Linux-agentknooppunten te bekijken. U kunt het CPU-gebruik, het CPU-quotum, het geheugengebruik en het geheugenquotum voor elke pod visualiseren.

Als uw cluster Windows-agentknooppunten bevat, kunt u het Kubernetes-/USE Method/Node-dashboard (Windows) gebruiken om de metrische Prometheus-gegevens te visualiseren die van deze knooppunten worden verzameld. Dit dashboard biedt een uitgebreide weergave van het resourceverbruik en de prestaties voor Windows-knooppunten in uw cluster.
Profiteer van deze toegewezen dashboards, zodat u belangrijke metrische gegevens met betrekking tot CPU, geheugen en andere resources in zowel Linux- als Windows-agentknooppunten eenvoudig kunt bewaken en analyseren. Met deze zichtbaarheid kunt u potentiële knelpunten identificeren, resourcetoewijzing optimaliseren en een efficiënte werking garanderen in uw AKS-cluster.
Stap 2: De connectiviteit van het besturingsvlak en werkknooppunt controleren
Als werkknooppunten in orde zijn, moet u de connectiviteit tussen het beheerde AKS-besturingsvlak en de clusterwerkknooppunten onderzoeken. AKS maakt communicatie mogelijk tussen de Kubernetes API-server en afzonderlijke knooppunt-kubelets via een beveiligde tunnelcommunicatiemethode. Deze onderdelen kunnen zelfs communiceren als ze zich op verschillende virtuele netwerken bevinden. De tunnel wordt beveiligd met MTLS-versleuteling (Mutual Transport Layer Security). De primaire tunnel die AKS gebruikt, heet Konnectivity (voorheen bekend als apiserver-network-proxy). Zorg ervoor dat alle netwerkregels en FQDN's voldoen aan de vereiste Azure-netwerkregels.
Als u de connectiviteit tussen het beheerde AKS-besturingsvlak en de clusterwerkknooppunten van een AKS-cluster wilt controleren, kunt u het opdrachtregelprogramma kubectl gebruiken.
Voer de volgende opdracht uit om ervoor te zorgen dat de Konnectivity-agentpods goed werken:
kubectl get deploy konnectivity-agent -n kube-system
Zorg ervoor dat de pods de status Gereed hebben.
Als er een probleem is met de connectiviteit tussen het besturingsvlak en de werkknooppunten, moet u de connectiviteit tot stand brengen nadat u ervoor hebt gezorgd dat de vereiste AKS-verkeersregels voor uitgaand verkeer zijn toegestaan.
Voer de volgende opdracht uit om de konnectivity-agent pods opnieuw op te starten:
kubectl rollout restart deploy konnectivity-agent -n kube-system
Als het opnieuw opstarten van de pods de verbinding niet oplost, controleert u de logboeken op afwijkingen. Voer de volgende opdracht uit om de logboeken van de konnectivity-agent pods weer te geven:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
In de logboeken moet de volgende uitvoer worden weergegeven:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Notitie
Wanneer een AKS-cluster is ingesteld met integratie van een virtueel netwerk van een API-server en een Azure-containernetwerkinterface (CNI) of een Azure CNI met dynamische IP-toewijzing van pods, is het niet nodig om Konnectivity-agents te implementeren. De geïntegreerde API-serverpods kunnen directe communicatie tot stand brengen met de clusterwerkknooppunten via privénetwerken.
Wanneer u echter virtuele netwerkintegratie van API-servers met Azure CNI Overlay gebruikt of uw eigen CNI (BYOCNI) gebruikt, wordt Konnectivity geïmplementeerd om communicatie tussen de API-servers en POD-IP's mogelijk te maken. De communicatie tussen de API-servers en de werkknooppunten blijft direct.
U kunt ook zoeken in de containerlogboeken in de logboekregistratie- en bewakingsservice om de logboeken op te halen. Zie Querylogboeken van containerinzichten voor een voorbeeld dat zoekt naar connectiviteitsfouten met aks-link.
Voer de volgende query uit om de logboeken op te halen:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Voer de volgende query uit om containerlogboeken te doorzoeken op een mislukte pod in een specifieke naamruimte:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Als u de logboeken niet kunt ophalen met behulp van query's of het kubectl-hulpprogramma, gebruikt u SSH-verificatie (Secure Shell). In dit voorbeeld wordt de tunnelfront-pod gevonden nadat u via SSH verbinding hebt gemaakt met het knooppunt.
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Stap 3: DNS-omzetting valideren bij het beperken van uitgaand verkeer
DNS-resolutie is een cruciaal aspect van uw AKS-cluster. Als DE DNS-resolutie niet goed werkt, kan dit leiden tot fouten in het besturingsvlak of pull-fouten met containerinstallatiekopieën. Voer de volgende stappen uit om ervoor te zorgen dat de DNS-omzetting naar de Kubernetes-API-server correct functioneert:
Voer de opdracht kubectl exec uit om een opdrachtshell te openen in de container die in de pod wordt uitgevoerd.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashControleer of de hulpprogramma's nslookup of graafprogramma's zijn geïnstalleerd in de container.
Als geen van beide hulpprogramma's in de pod is geïnstalleerd, voert u de volgende opdracht uit om een hulpprogrammapod in dezelfde naamruimte te maken.
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shU kunt het API-serveradres ophalen op de overzichtspagina van uw AKS-cluster in Azure Portal of u kunt de volgende opdracht uitvoeren.
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvVoer de volgende opdracht uit om de AKS-API-server op te lossen. Zie Problemen met DNS-omzetting oplossen vanuit de pod, maar niet vanuit het werkknooppunt voor meer informatie.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioControleer de upstream-DNS-server van de pod om te bepalen of de DNS-omzetting correct werkt. Voer bijvoorbeeld de
nslookupopdracht uit voor Azure DNS.nslookup microsoft.com 168.63.129.16Als de vorige stappen geen inzichten bieden, maakt u verbinding met een van de werkknooppunten en probeert u dns-omzetting vanaf het knooppunt. Met deze stap kunt u vaststellen of het probleem is gerelateerd aan AKS of de netwerkconfiguratie.
Als de DNS-omzetting is geslaagd vanaf het knooppunt, maar niet van de pod, kan het probleem te maken hebben met Kubernetes DNS. Zie Problemen met DNS-omzetting oplossen voor stappen voor het opsporen van fouten in DNS-omzetting vanuit de pod.
Als de DNS-omzetting van het knooppunt mislukt, controleert u de netwerkinstallatie om ervoor te zorgen dat de juiste routeringspaden en poorten zijn geopend om DNS-omzetting te vergemakkelijken.
Stap 4: Controleren op kubelet-fouten
Controleer de voorwaarde van het kubelet-proces dat wordt uitgevoerd op elk werkknooppunt en zorg ervoor dat het niet onder druk staat. Mogelijke druk kan betrekking hebben op CPU, geheugen of opslag. Als u de status van afzonderlijke knooppunt-kubelets wilt controleren, kunt u een van de volgende methoden gebruiken.
AKS-kubelet-werkmap
Voer de volgende stappen uit om ervoor te zorgen dat kubelets voor agentknooppunten goed werken:
Ga naar uw AKS-cluster in Azure Portal.
Selecteer Werkmappen in de sectie Bewaking van het navigatiedeelvenster.
Selecteer de Kubelet-werkmap .
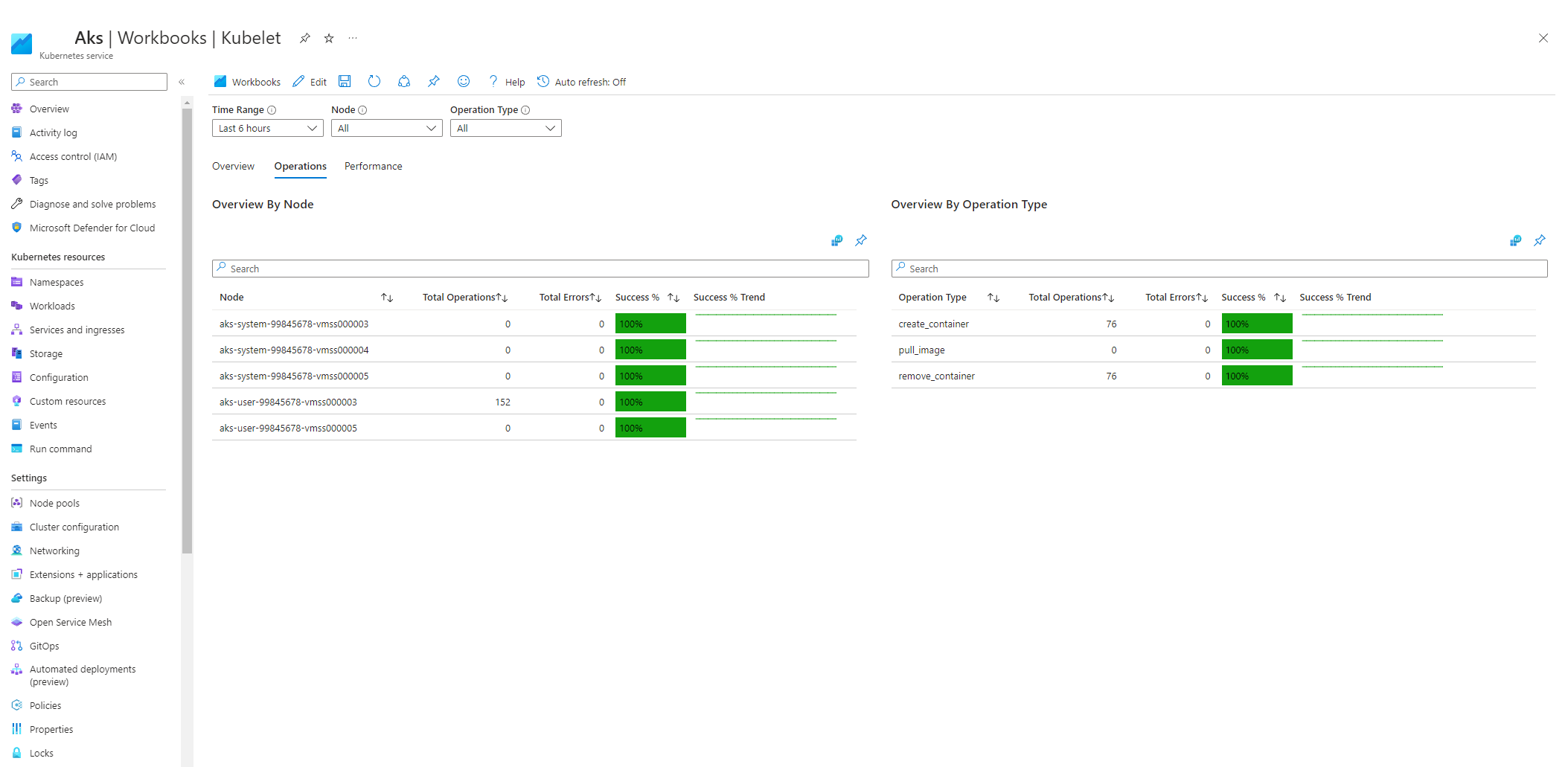
Selecteer Bewerkingen en zorg ervoor dat de bewerkingen voor alle werkknooppunten zijn voltooid.


Bewaking in clusters met Prometheus en Grafana
Als u Prometheus en Grafana in uw AKS-cluster hebt geïmplementeerd, kunt u het Kubernetes-/Kubelet-dashboard gebruiken om inzicht te krijgen in de status en prestaties van kubelets voor afzonderlijke knooppunten.

Beheerde service bewaken voor Prometheus en Azure Managed Grafana
U kunt het vooraf samengestelde Kubernetes/Kubelet-dashboard gebruiken om de prometheus-metrische gegevens voor de kubelets voor het werkknooppunt te visualiseren en te analyseren. Hiervoor moet u uw AKS-cluster instellen voor het verzamelen van metrische Prometheus-gegevens in de beheerde Service voor Prometheus en uw Monitor-werkruimte verbinden met een Azure Managed Grafana-werkruimte .

De druk neemt toe wanneer een kubelet opnieuw wordt opgestart en sporadisch, onvoorspelbaar gedrag veroorzaakt. Zorg ervoor dat het aantal fouten niet continu groeit. Een incidentele fout is acceptabel, maar een constante groei geeft een onderliggend probleem aan dat u moet onderzoeken en oplossen.
Stap 5: Gebruik het hulpprogramma NPD (Node Problem Detector) om de status van het knooppunt te controleren
NPD is een Kubernetes-hulpprogramma dat u kunt gebruiken om problemen met betrekking tot knooppunten te identificeren en te rapporteren. Het werkt als een systeemservice op elk knooppunt in het cluster. Het verzamelt metrische gegevens en systeemgegevens, zoals CPU-gebruik, schijfgebruik en netwerkconnectiviteitsstatus. Wanneer er een probleem wordt gedetecteerd, genereert het HULPPROGRAMMA NPD een rapport over de gebeurtenissen en de knooppuntvoorwaarde. In AKS wordt het HULPPROGRAMMA NPD gebruikt voor het bewaken en beheren van knooppunten in een Kubernetes-cluster dat wordt gehost in de Azure-cloud. Zie NPD in AKS-knooppunten voor meer informatie.
Stap 6: I/O-bewerkingen per seconde (IOPS) controleren op beperking
U kunt een van de volgende methoden gebruiken om ervoor te zorgen dat IOPS niet wordt beperkt en van invloed is op services en workloads in uw AKS-cluster.
I/O-werkmap voor AKS-knooppuntschijf
Als u de schijf-I/O-gerelateerde metrische gegevens van de werkknooppunten in uw AKS-cluster wilt bewaken, kunt u de I/O-werkmap van de knooppuntschijf gebruiken. Volg deze stappen om toegang te krijgen tot de werkmap:
Ga naar uw AKS-cluster in Azure Portal.
Selecteer Werkmappen in de sectie Bewaking van het navigatiedeelvenster.
Selecteer de knooppuntschijf-IO-werkmap .
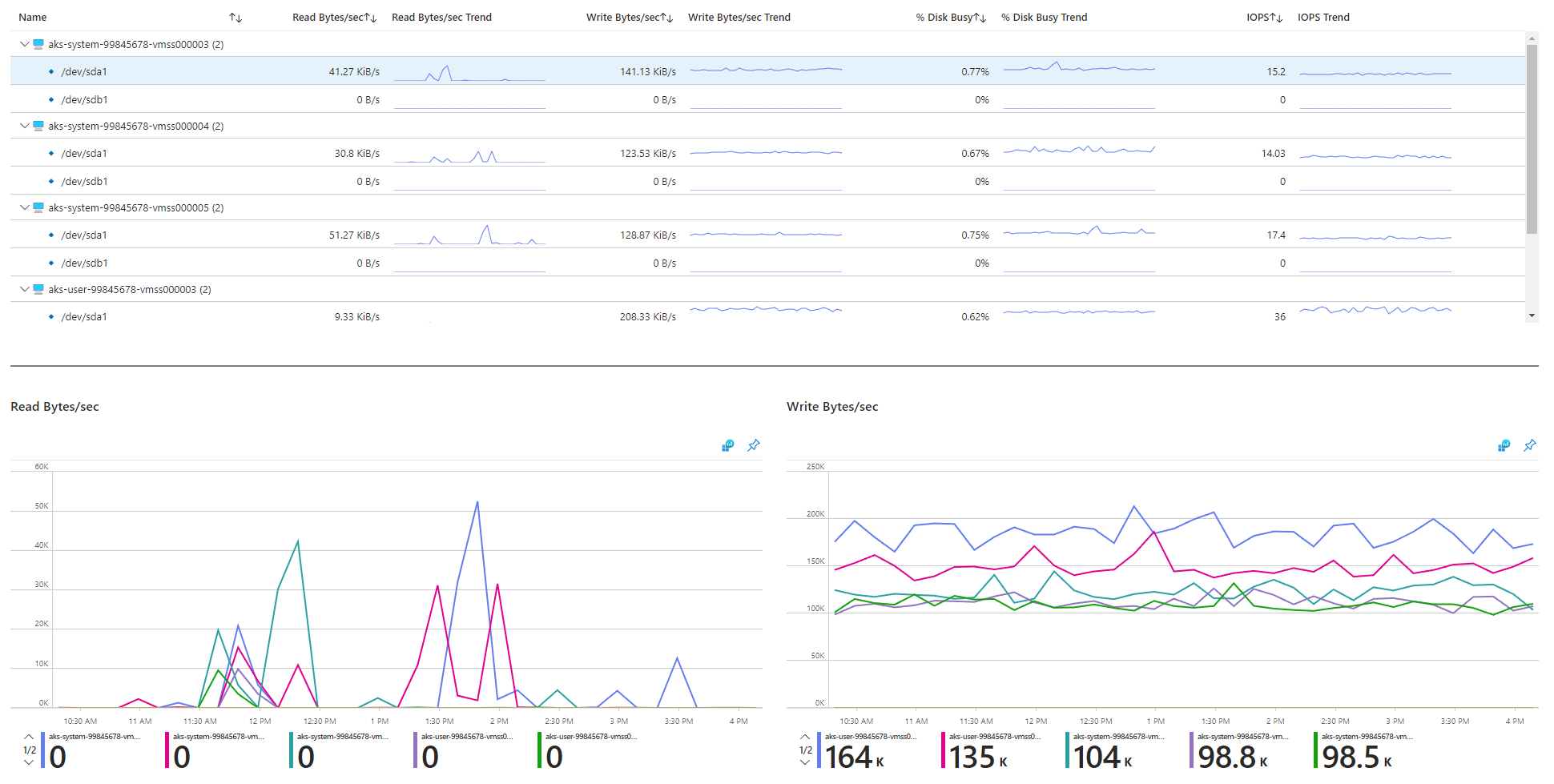
Bekijk de I/O-gerelateerde metrische gegevens.


Bewaking in clusters met Prometheus en Grafana
Als u Prometheus en Grafana in uw AKS-cluster hebt geïmplementeerd, kunt u het dashboard USE Method/Node gebruiken om inzicht te krijgen in de schijf-I/O voor de clusterwerkknooppunten.

Beheerde service bewaken voor Prometheus en Azure Managed Grafana
U kunt het vooraf samengestelde dashboard Knooppuntexporteur/knooppunten gebruiken om I/O-gerelateerde schijfgegevens van de werkknooppunten te visualiseren en te analyseren. Hiervoor moet u uw AKS-cluster instellen voor het verzamelen van metrische Prometheus-gegevens in de beheerde Service voor Prometheus en uw Monitor-werkruimte verbinden met een Azure Managed Grafana-werkruimte .

IOPS- en Azure-schijven
Fysieke opslagapparaten hebben inherente beperkingen in termen van bandbreedte en het maximum aantal bestandsbewerkingen dat ze kunnen verwerken. Azure-schijven worden gebruikt voor het opslaan van het besturingssysteem dat wordt uitgevoerd op AKS-knooppunten. De schijven zijn onderworpen aan dezelfde fysieke opslagbeperkingen als het besturingssysteem.
Houd rekening met het concept van doorvoer. U kunt de gemiddelde I/O-grootte vermenigvuldigen met de IOPS om de doorvoer in megabytes per seconde (MBps) te bepalen. Grotere I/O-grootten worden omgezet in lagere IOPS vanwege de vaste doorvoer van de schijf.
Wanneer een workload de maximale IOPS-servicelimieten overschrijdt die zijn toegewezen aan de Azure-schijven, reageert het cluster mogelijk niet meer en voert u een I/O-wachtstatus in. In Linux-systemen worden veel onderdelen behandeld als bestanden, zoals netwerksockets, CNI, Docker en andere services die afhankelijk zijn van netwerk-I/O. Als de schijf dus niet kan worden gelezen, wordt de fout uitgebreid naar al deze bestanden.
Verschillende gebeurtenissen en scenario's kunnen IOPS-beperking activeren, waaronder:
Een aanzienlijk aantal containers die worden uitgevoerd op knooppunten, omdat Docker I/O de besturingssysteemschijf deelt.
Aangepaste of externe hulpprogramma's die worden gebruikt voor beveiliging, bewaking en logboekregistratie, waardoor extra I/O-bewerkingen op de besturingssysteemschijf kunnen worden gegenereerd.
Failover-gebeurtenissen en periodieke taken van knooppunten die de workload versterken of het aantal pods schalen. Hierdoor wordt de kans groter dat er sprake is van beperking, waardoor alle knooppunten worden overgestapt naar een niet-gereede status totdat de I/O-bewerkingen zijn afgesloten.
Bijdragers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- Paulo Salvatori | Principal Customer Engineer
- Francis Simy Azure | Senior Technisch Specialist
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
Verwante resources
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor