Overwegingen voor toepassingsplatforms voor bedrijfskritieke workloads
Een belangrijk ontwerpgebied van een bedrijfskritieke architectuur is het toepassingsplatform. Platform verwijst naar de infrastructuuronderdelen en Azure-services die moeten worden ingericht ter ondersteuning van de toepassing. Hier volgen enkele overkoepelende aanbevelingen.
Ontwerpen in lagen. Kies de juiste set services, hun configuratie en de toepassingsspecifieke afhankelijkheden. Deze gelaagde benadering helpt bij het maken van logische en fysieke segmentatie. Het is handig bij het definiëren van rollen en functies en het toewijzen van de juiste bevoegdheden en implementatiestrategieën. Deze aanpak verhoogt uiteindelijk de betrouwbaarheid van het systeem.
Een bedrijfskritieke toepassing moet zeer betrouwbaar en bestand zijn tegen datacentrum- en regionale storingen. Het bouwen van zonegebonden en regionale redundantie in een actief-actief-configuratie is de belangrijkste strategie. Wanneer u Azure-services kiest voor het platform van uw toepassing, kunt u de Beschikbaarheidszones ondersteuning en implementatie en operationele patronen overwegen om meerdere Azure-regio's te gebruiken.
Gebruik een architectuur op basis van schaaleenheden om verhoogde belasting te verwerken. Met schaaleenheden kunt u resources logisch groeperen en een eenheid kan onafhankelijk van andere eenheden of services in de architectuur worden geschaald. Gebruik uw capaciteitsmodel en verwachte prestaties om de grenzen van, het aantal en de basislijnschaal van elke eenheid te definiëren.
In deze architectuur bestaat het toepassingsplatform uit wereldwijde, implementatiestempels en regionale resources. De regionale resources worden ingericht als onderdeel van een implementatiestempel. Elke stempel is gelijk aan een schaaleenheid en kan, als deze beschadigd raakt, volledig worden vervangen.
De resources in elke laag hebben verschillende kenmerken. Zie het architectuurpatroon van een typische bedrijfskritieke workload voor meer informatie.
| Kenmerken | Overwegingen |
|---|---|
| Levenslang | Wat is de verwachte levensduur van resources ten opzichte van andere resources in de oplossing? Moet de resource de levensduur van het hele systeem of de hele regio uitleven of delen, of moet deze tijdelijk zijn? |
| Provincie | Welke invloed heeft de persistente status op deze laag op betrouwbaarheid of beheerbaarheid? |
| Reach | Is de resource vereist om wereldwijd te worden gedistribueerd? Kan de resource communiceren met andere resources, wereldwijd of in regio's? |
| Afhankelijkheden | Wat is de afhankelijkheid van andere resources, globaal of in andere regio's? |
| Schaallimieten | Wat is de verwachte doorvoer voor die resource op die laag? Hoeveel schaal wordt door de resource geleverd om aan die vraag te voldoen? |
| Beschikbaarheid/herstel na noodgevallen | Wat is de impact op beschikbaarheid of noodgeval op deze laag? Zou dit leiden tot een systeemstoring of alleen gelokaliseerde capaciteit of beschikbaarheidsprobleem? |
Globale resources
Bepaalde resources in deze architectuur worden gedeeld door resources die zijn geïmplementeerd in regio's. In deze architectuur worden ze gebruikt om verkeer over meerdere regio's te distribueren, permanente status voor de hele toepassing op te slaan en globale statische gegevens in de cache op te slaan.
| Kenmerken | Overwegingen voor lagen |
|---|---|
| Levenslang | Deze resources zullen naar verwachting lang leven. Hun levensduur beslaat de levensduur van het systeem of langer. Vaak worden de resources beheerd met in-place gegevens- en besturingsvlakupdates, ervan uitgaande dat ze updatebewerkingen zonder downtime ondersteunen. |
| Provincie | Omdat deze resources ten minste de levensduur van het systeem hebben, is deze laag vaak verantwoordelijk voor het opslaan van de globale, geo-gerepliceerde status. |
| Reach | De resources moeten wereldwijd worden gedistribueerd. Het wordt aanbevolen om deze resources te communiceren met regionale of andere resources met lage latentie en de gewenste consistentie. |
| Afhankelijkheden | De resources moeten afhankelijkheden van regionale resources voorkomen omdat hun onbeschikbaarheid een oorzaak kan zijn van globale fouten. Certificaten of geheimen die in één kluis worden bewaard, kunnen bijvoorbeeld globale gevolgen hebben als er een regionale fout optreedt in de kluis. |
| Schaallimieten | Deze resources zijn vaak singleton-exemplaren in het systeem en daarom moeten ze zodanig kunnen schalen dat ze de doorvoer van het systeem als geheel kunnen verwerken. |
| Beschikbaarheid/herstel na noodgevallen | Omdat regionale en stempelresources globale resources kunnen verbruiken of eraan vooraf gaan, is het essentieel dat wereldwijde resources zijn geconfigureerd met hoge beschikbaarheid en herstel na noodgevallen voor de status van het hele systeem. |
In deze architectuur zijn globale laag-resources Azure Front Door, Azure Cosmos DB, Azure Container Registry en Azure Log Analytics voor het opslaan van logboeken en metrische gegevens van andere globale laag-resources.
Er zijn andere basisbronnen in dit ontwerp, zoals Microsoft Entra ID en Azure DNS. Ze zijn weggelaten in deze afbeelding voor beknoptheid.

Globale load balancer
Azure Front Door wordt gebruikt als het enige toegangspunt voor gebruikersverkeer. Azure garandeert dat Azure Front Door de aangevraagde inhoud zonder fout 99,99% van de tijd levert. Zie Front Door-servicelimieten voor meer informatie. Als Front Door niet meer beschikbaar is, ziet de eindgebruiker dat het systeem niet beschikbaar is.
Het Front Door-exemplaar verzendt verkeer naar de geconfigureerde back-endservices, zoals het rekencluster dat als host fungeert voor de API en de front-end-BEVEILIGD-WACHTWOORDVERIFICATIE. Onjuiste configuraties van back-end in Front Door kunnen leiden tot storingen. Als u storingen wilt voorkomen vanwege onjuiste configuraties, moet u uw Front Door-instellingen uitgebreid testen.
Een andere veelvoorkomende fout kan afkomstig zijn van onjuist geconfigureerde of ontbrekende TLS-certificaten, waardoor gebruikers de front-end of Front Door-communicatie met de back-end kunnen voorkomen. Voor risicobeperking is mogelijk handmatige interventie vereist. U kunt er bijvoorbeeld voor kiezen om terug te keren naar de vorige configuratie en het certificaat indien mogelijk opnieuw uit te geven. U kunt ook verwachten dat de wijzigingen niet beschikbaar zijn terwijl wijzigingen van kracht worden. Het gebruik van beheerde certificaten die door Front door worden aangeboden, wordt aanbevolen om de operationele overhead te verminderen, zoals het afhandelen van vervaldatums.
Front Door biedt veel extra mogelijkheden naast wereldwijde verkeersroutering. Een belangrijke mogelijkheid is de Web Application Firewall (WAF), omdat Front Door verkeer kan inspecteren dat wordt doorgegeven. Wanneer deze is geconfigureerd in de preventiemodus , wordt verdacht verkeer geblokkeerd voordat zelfs een van de back-ends wordt bereikt.
Zie veelgestelde vragen over Azure Front Door voor meer informatie over de mogelijkheden van Front Door.
Zie Bedrijfskritieke richtlijnen in Well-architected Framework: Global Routing voor andere overwegingen over wereldwijde distributie van verkeer.
Container Registry
Azure Container Registry wordt gebruikt voor het opslaan van OCI-artefacten (Open Container Initiative), met name helm-grafieken en containerinstallatiekopieën. Het neemt niet deel aan de aanvraagstroom en wordt alleen periodiek geopend. Containerregister is vereist om te bestaan voordat stempelbronnen worden geïmplementeerd en mag geen afhankelijkheid hebben van resources in de regionale laag.
Schakel zoneredundantie en geo-replicatie van registers in, zodat runtimetoegang tot installatiekopieën snel en bestand is tegen fouten. Als het niet beschikbaar is, kan het exemplaar vervolgens een failover uitvoeren naar replicaregio's en worden aanvragen automatisch opnieuw gerouteerd naar een andere regio. Verwacht tijdelijke fouten bij het ophalen van installatiekopieën totdat de failover is voltooid.
Er kunnen ook fouten optreden als installatiekopieën per ongeluk worden verwijderd, kunnen nieuwe rekenknooppunten geen installatiekopieën ophalen, maar bestaande knooppunten kunnen nog steeds afbeeldingen in de cache gebruiken. De primaire strategie voor herstel na noodgevallen is opnieuw implementeren. De artefacten in een containerregister kunnen opnieuw worden gegenereerd vanuit pijplijnen. Containerregister moet bestand zijn tegen veel gelijktijdige verbindingen om al uw implementaties te ondersteunen.
Het is raadzaam om de Premium-SKU te gebruiken om geo-replicatie in te schakelen. De functie zoneredundantie zorgt voor tolerantie en hoge beschikbaarheid binnen een specifieke regio. In het geval van een regionale storing zijn replica's in andere regio's nog steeds beschikbaar voor gegevensvlakbewerkingen. Met deze SKU kunt u de toegang tot afbeeldingen beperken via privé-eindpunten.
Zie Best practices voor Azure Container Registry voor meer informatie.
Database
Het wordt aanbevolen dat alle statussen wereldwijd worden opgeslagen in een database, gescheiden van regionale stempels. Bouw redundantie door de database in verschillende regio's te implementeren. Voor bedrijfskritieke workloads moet het synchroniseren van gegevens tussen regio's het belangrijkste probleem zijn. In het geval van een fout moeten schrijfaanvragen naar de database nog steeds functioneel zijn.
Gegevensreplicatie in een actief-actief-configuratie wordt sterk aanbevolen. De toepassing moet direct verbinding kunnen maken met een andere regio. Alle exemplaren moeten lees- en schrijfaanvragen kunnen verwerken.
Zie Data Platform voor bedrijfskritieke workloads voor meer informatie.
Wereldwijde bewaking
Azure Log Analytics wordt gebruikt voor het opslaan van diagnostische logboeken van alle globale resources. Het wordt aanbevolen om het dagelijkse quotum voor opslag te beperken, met name voor omgevingen die worden gebruikt voor belastingstests. Stel ook bewaarbeleid in. Deze beperkingen verhinderen overschrijdingen die worden gemaakt door het opslaan van gegevens die niet nodig zijn buiten een limiet.
Overwegingen voor basisservices
Het systeem gebruikt waarschijnlijk andere essentiële platformservices die ertoe kunnen leiden dat het hele systeem risico loopt, zoals Azure DNS en Microsoft Entra ID. Azure DNS garandeert een SLA voor 100% beschikbaarheid voor geldige DNS-aanvragen. Microsoft Entra garandeert ten minste 99,99% uptime. Toch moet u rekening houden met de impact in het geval van een fout.
Het nemen van harde afhankelijkheid van basisservices is onvermijdelijk omdat veel Azure-services hiervan afhankelijk zijn. Verwacht onderbrekingen in het systeem als ze niet beschikbaar zijn. Bijvoorbeeld:
- Azure Front Door maakt gebruik van Azure DNS om de back-end en andere globale services te bereiken.
- Azure Container Registry maakt gebruik van Azure DNS om failover-aanvragen naar een andere regio uit te voeren.
In beide gevallen worden beide Azure-services beïnvloed als Azure DNS niet beschikbaar is. Naamomzetting voor gebruikersaanvragen van Front Door mislukt; Docker-installatiekopieën worden niet opgehaald uit het register. Het gebruik van een externe DNS-service als back-up vermindert het risico niet omdat veel Azure-services dergelijke configuratie niet toestaan en afhankelijk zijn van interne DNS. Verwacht volledige storing.
Op dezelfde manier wordt Microsoft Entra-id gebruikt voor besturingsvlakbewerkingen, zoals het maken van nieuwe AKS-knooppunten, het ophalen van installatiekopieën uit Container Registry of het openen van Key Vault bij het opstarten van pods. Als Microsoft Entra-id niet beschikbaar is, moeten bestaande onderdelen niet worden beïnvloed, maar de algehele prestaties kunnen afnemen. Nieuwe pods of AKS-knooppunten zijn niet functioneel. Voor het geval er in deze periode uitschaalbewerkingen nodig zijn, verwacht u dus een verminderde gebruikerservaring.
Regionale implementatiestempelbronnen
In deze architectuur implementeert het implementatiestempel de workload en richt de resources in die deelnemen aan het voltooien van zakelijke transacties. Een stempel komt meestal overeen met een implementatie in een Azure-regio. Hoewel een regio meer dan één stempel kan hebben.
| Kenmerken | Overwegingen |
|---|---|
| Levenslang | Naar verwachting hebben de resources een korte levensduur (kortstondig) met de bedoeling dat ze dynamisch kunnen worden toegevoegd en verwijderd, terwijl regionale resources buiten de stempel blijven bestaan. De tijdelijke aard is nodig om gebruikers meer flexibiliteit, schaal en nabijheid te bieden. |
| Provincie | Omdat stempels kortstondig zijn en op elk gewenst moment kunnen worden vernietigd, moet een stempel zoveel mogelijk staatloos zijn. |
| Reach | Kan communiceren met regionale en wereldwijde resources. Communicatie met andere regio's of andere stempels moet echter worden vermeden. In deze architectuur is het niet nodig dat deze resources wereldwijd worden gedistribueerd. |
| Afhankelijkheden | De stempelbronnen moeten onafhankelijk zijn. Dat wil gezegd, ze mogen niet afhankelijk zijn van andere stempels of onderdelen in andere regio's. Naar verwachting hebben ze regionale en wereldwijde afhankelijkheden. Het belangrijkste gedeelde onderdeel is de databaselaag en het containerregister. Dit onderdeel vereist synchronisatie tijdens runtime. |
| Schaallimieten | De doorvoer wordt tot stand gebracht door middel van testen. De doorvoer van de algehele zegel is beperkt tot de minst presterende resource. Zegeldoorvoer moet rekening houden met het geschatte hoge vraagniveau en eventuele failovers als gevolg van een andere stempel in de regio die niet beschikbaar is. |
| Beschikbaarheid/herstel na noodgevallen | Vanwege de tijdelijke aard van stempels wordt herstel na noodgevallen uitgevoerd door de stempel opnieuw te implementeren. Als resources een slechte status hebben, kan de stempel als geheel worden vernietigd en opnieuw worden geïmplementeerd. |
In deze architectuur zijn stempelbronnen Azure Kubernetes Service, Azure Event Hubs, Azure Key Vault en Azure Blob Storage.
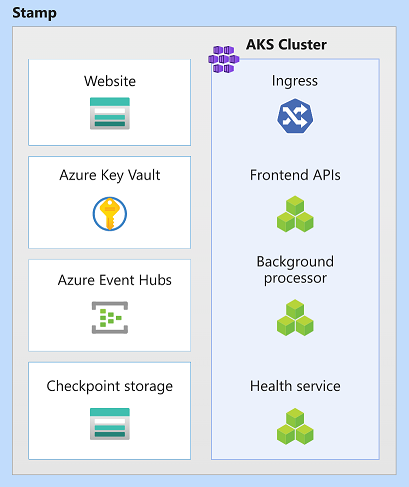
Schaaleenheid
Een stempel kan ook worden beschouwd als een schaaleenheid (SU). Alle onderdelen en services binnen een bepaalde stempel worden geconfigureerd en getest om aanvragen in een bepaald bereik te verwerken. Hier volgt een voorbeeld van een schaaleenheid die wordt gebruikt in de implementatie.
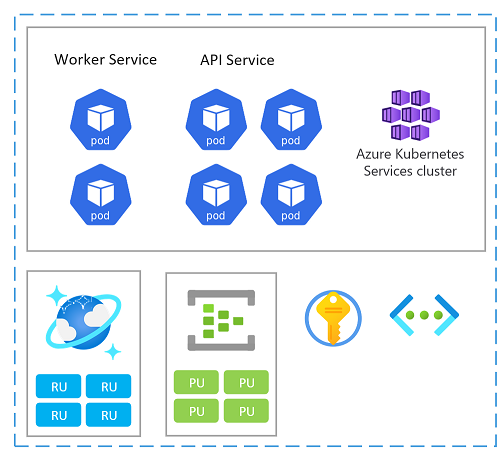
Elke schaaleenheid wordt geïmplementeerd in een Azure-regio en verwerkt daarom voornamelijk verkeer van dat opgegeven gebied (hoewel het verkeer van andere regio's kan overnemen wanneer dat nodig is). Deze geografische verspreiding leidt waarschijnlijk tot belastingspatronen en kantooruren die kunnen variëren van regio tot regio en als zodanig is elke SU ontworpen om in-/omlaag te schalen wanneer deze niet actief is.
U kunt een nieuwe stempel implementeren op schaal. Binnen een stempel kunnen afzonderlijke resources ook schaaleenheden zijn.
Hier volgen enkele overwegingen voor schalen en beschikbaarheid bij het kiezen van Azure-services in een eenheid:
Evalueer capaciteitsrelaties tussen alle resources in een schaaleenheid. Als u bijvoorbeeld 100 binnenkomende aanvragen, 5 controllerpods voor inkomend verkeer en 3 catalogusservicepods en 1000 RU's in Azure Cosmos DB nodig hebt. Wanneer de toegangspods automatisch worden geschaald, verwacht u dus schaalaanpassing van de catalogusservice en Azure Cosmos DB-RU's op basis van deze bereiken.
Test de services om een bereik te bepalen waarin aanvragen worden verwerkt. Op basis van de resultaten worden minimale en maximale exemplaren en metrische doelgegevens geconfigureerd. Wanneer het doel is bereikt, kunt u ervoor kiezen om het schalen van de hele eenheid te automatiseren.
Bekijk de schaallimieten en quota van het Azure-abonnement ter ondersteuning van de capaciteit en het kostenmodel dat is ingesteld op basis van de bedrijfsvereisten. Controleer ook de limieten van afzonderlijke services in overweging. Omdat eenheden doorgaans samen worden geïmplementeerd, moet u rekening houden met de resourcelimieten van het abonnement die vereist zijn voor canary-implementaties. Zie Azure-servicelimieten voor meer informatie.
Kies services die beschikbaarheidszones ondersteunen om redundantie te bouwen. Dit kan uw technologiekeuzes beperken. Zie Beschikbaarheidszones voor meer informatie.
Voor andere overwegingen over de grootte van een eenheid en een combinatie van resources raadpleegt u Bedrijfskritieke richtlijnen in goed ontworpen framework: Architectuur voor schaaleenheden.
Rekencluster
Als u de werkbelasting wilt containeriseren, moet elke zegel een rekencluster uitvoeren. In deze architectuur wordt Azure Kubernetes Service (AKS) gekozen omdat Kubernetes het populairste rekenplatform is voor moderne, containertoepassingen.
De levensduur van het AKS-cluster is gebonden aan de tijdelijke aard van de stempel. Het cluster is staatloos en heeft geen permanente volumes. Het maakt gebruik van tijdelijke besturingssysteemschijven in plaats van beheerde schijven, omdat ze naar verwachting geen onderhoud op toepassings- of systeemniveau ontvangen.
Om de betrouwbaarheid te vergroten, is het cluster geconfigureerd voor het gebruik van alle drie de beschikbaarheidszones in een bepaalde regio. Daarnaast moet het cluster de Standard- of Premium-laag gebruiken om sla voor AKS in te schakelen met gegarandeerde SLA-beschikbaarheid van 99,95%. Zie AKS-prijscategorieën voor meer informatie.
Andere factoren, zoals schaallimieten, rekencapaciteit, abonnementsquotum, kunnen ook van invloed zijn op de betrouwbaarheid. Als er onvoldoende capaciteit of limieten zijn bereikt, mislukken uit- en opschalen van bewerkingen, maar wordt verwacht dat bestaande berekeningen werken.
Het cluster heeft automatische schaalaanpassing ingeschakeld om knooppuntgroepen automatisch uit te schalen indien nodig, waardoor de betrouwbaarheid wordt verbeterd. Wanneer u meerdere knooppuntgroepen gebruikt, moeten alle knooppuntgroepen automatisch worden geschaald.
Op podniveau schaalt de Horizontale automatische schaalaanpassing van pods (HPA) pods op basis van geconfigureerde CPU, geheugen of aangepaste metrische gegevens. Belasting test de onderdelen van de workload om een basislijn voor de automatische schaalaanpassing en HPA-waarden tot stand te brengen.
Het cluster is ook geconfigureerd voor automatische upgrades van knooppuntinstallatiekopieën en voor de juiste schaal tijdens deze upgrades. Door deze schaalaanpassing is er geen downtime mogelijk terwijl upgrades worden uitgevoerd. Als het cluster in één stempel mislukt tijdens een upgrade, mogen andere clusters in andere stempels niet worden beïnvloed, maar moeten upgrades tussen stempels op verschillende tijdstippen plaatsvinden om de beschikbaarheid te behouden. Bovendien worden clusterupgrades automatisch over de knooppunten geïmplementeerd, zodat ze niet tegelijkertijd niet beschikbaar zijn.
Voor sommige onderdelen, zoals certificaatbeheer en inkomend verkeer, zijn containerinstallatiekopieën van externe containerregisters vereist. Als deze opslagplaatsen of installatiekopieën niet beschikbaar zijn, kunnen nieuwe exemplaren op nieuwe knooppunten (waarbij de installatiekopieën niet in de cache zijn opgeslagen) mogelijk niet worden gestart. Dit risico kan worden beperkt door deze installatiekopieën te importeren in het Azure Container Registry van de omgeving.
Waarneembaarheid is essentieel in deze architectuur omdat stempels kortstondig zijn. Diagnostische instellingen zijn geconfigureerd voor het opslaan van alle logboek- en metrische gegevens in een regionale Log Analytics-werkruimte. AKS Container Insights wordt ook ingeschakeld via een OMS-agent in het cluster. Met deze agent kan het cluster bewakingsgegevens verzenden naar de Log Analytics-werkruimte.
Zie Bedrijfskritieke richtlijnen in Well-architected Framework: Container Orchestration en Kubernetes voor andere overwegingen over het rekencluster.
Key Vault
Azure Key Vault wordt gebruikt om globale geheimen, zoals verbindingsreeks s, op te slaan in de database en geheimen te stempelen, zoals de Event Hubs-verbindingsreeks.
Deze architectuur maakt gebruik van een CSI-stuurprogramma Secrets Store in het rekencluster om geheimen op te halen uit Key Vault. Geheimen zijn nodig wanneer nieuwe pods worden gehaald. Als Key Vault niet beschikbaar is, worden nieuwe pods mogelijk niet gestart. Als gevolg hiervan kan er sprake zijn van onderbrekingen; uitschaalbewerkingen kunnen worden beïnvloed, updates kunnen mislukken, nieuwe implementaties kunnen niet worden uitgevoerd.
Key Vault heeft een limiet voor het aantal bewerkingen. Vanwege de automatische update van geheimen kan de limiet worden bereikt als er veel pods zijn. U kunt ervoor kiezen om de frequentie van updates te verlagen om deze situatie te voorkomen.
Zie Bedrijfskritieke richtlijnen in Well-architected Framework: Beveiliging van gegevensintegriteit voor andere overwegingen over geheimbeheer.
Event Hubs
De enige stateful service in de stempel is de berichtenbroker, Azure Event Hubs, waarin aanvragen voor een korte periode worden opgeslagen. De broker biedt de behoefte aan buffering en betrouwbare berichten. De verwerkte aanvragen worden bewaard in de globale database.
In deze architectuur wordt standard-SKU gebruikt en is zoneredundantie ingeschakeld voor hoge beschikbaarheid.
De Status van Event Hubs wordt gecontroleerd door het HealthService-onderdeel dat wordt uitgevoerd op het rekencluster. Het voert periodieke controles uit op verschillende resources. Dit is handig bij het detecteren van beschadigde omstandigheden. Als berichten bijvoorbeeld niet naar de Event Hub kunnen worden verzonden, is het stempel onbruikbaar voor schrijfbewerkingen. HealthService moet deze voorwaarde automatisch detecteren en de status Niet in orde melden bij Front Door, waardoor de zegel uit de rotatie wordt gehaald.
Voor schaalbaarheid wordt het inschakelen van automatisch vergroten aanbevolen.
Zie Berichtenservices voor bedrijfskritieke workloads voor meer informatie.
Zie Bedrijfskritieke richtlijnen in Well-architected Framework: Asynchrone berichten voor andere overwegingen over berichten.
Opslagaccounts
In deze architectuur worden twee opslagaccounts ingericht. Beide accounts worden geïmplementeerd in de zone-redundante modus (ZRS).
Eén account wordt gebruikt voor Event Hubs-controlepunten. Als dit account niet reageert, kan de stempel geen berichten van Event Hubs verwerken en zelfs andere services in de stempel beïnvloeden. Deze voorwaarde wordt periodiek gecontroleerd door de HealthService. Dit is een van de toepassingsonderdelen die in het rekencluster worden uitgevoerd.
De andere wordt gebruikt om de ui-toepassing met één pagina te hosten. Als het leveren van de statische website problemen heeft, detecteert Front Door het probleem en verzendt geen verkeer naar dit opslagaccount. Gedurende deze periode kan Front Door inhoud in de cache gebruiken.
Zie Herstel na noodgevallen en failover van opslagaccounts voor meer informatie over herstel.
Regionale resources
Een systeem kan resources bevatten die zijn geïmplementeerd in de regio, maar de stempelbronnen niet meer gebruiken. In deze architectuur worden waarneembaarheidsgegevens voor stempelbronnen opgeslagen in regionale gegevensarchieven.
| Kenmerken | Overweging |
|---|---|
| Levenslang | De resources delen de levensduur van de regio en live de stempelbronnen. |
| Provincie | Status die is opgeslagen in een regio, kan niet langer duren dan de levensduur van de regio. Als de status moet worden gedeeld tussen regio's, kunt u overwegen een globaal gegevensarchief te gebruiken. |
| Reach | De resources hoeven niet wereldwijd te worden gedistribueerd. Directe communicatie met andere regio's moet ten koste van alle kosten worden vermeden. |
| Afhankelijkheden | De resources kunnen afhankelijk zijn van globale resources, maar niet op stempelbronnen, omdat stempels bedoeld zijn om kort te leven. |
| Schaallimieten | Bepaal de schaallimiet van regionale resources door alle stempels binnen de regio te combineren. |
Bewakingsgegevens voor stempelbronnen
Het implementeren van bewakingsresources is een typisch voorbeeld voor regionale resources. In deze architectuur heeft elke regio een afzonderlijke Log Analytics-werkruimte geconfigureerd voor het opslaan van alle logboek- en metrische gegevens die worden verzonden vanuit stempelbronnen. Omdat regionale resources geen stempelbronnen meer bevatten, zijn gegevens beschikbaar, zelfs wanneer de stempel wordt verwijderd.
Azure Log Analytics en Azure-toepassing Insights worden gebruikt voor het opslaan van logboeken en metrische gegevens van het platform. Het wordt aanbevolen om het dagelijkse quotum voor opslag te beperken, met name voor omgevingen die worden gebruikt voor belastingstests. Stel ook bewaarbeleid in om alle gegevens op te slaan. Deze beperkingen verhinderen overschrijdingen die worden gemaakt door het opslaan van gegevens die niet nodig zijn buiten een limiet.
Op dezelfde manier wordt Application Insights ook geïmplementeerd als een regionale resource om alle toepassingsbewakingsgegevens te verzamelen.
Zie Bedrijfskritieke richtlijnen in Well-architected Framework: Health modeling voor ontwerpaanbevelingen voor bewaking.
Volgende stappen
Implementeer de referentie-implementatie om volledig inzicht te krijgen in de resources en de configuratie die in deze architectuur wordt gebruikt.