Prestaties en schaalbaarheid in Durable Functions (Azure Functions)
Om de prestaties en schaalbaarheid te optimaliseren, is het belangrijk om inzicht te hebben in de unieke schaalkenmerken van Durable Functions. In dit artikel wordt uitgelegd hoe werkrollen worden geschaald op basis van belasting en hoe u de verschillende parameters kunt afstemmen.
Werkrol schalen
Een fundamenteel voordeel van het taakhubconcept is dat het aantal werknemers dat werkitems van de taakhub verwerkt, continu kan worden aangepast. Toepassingen kunnen met name meer werkrollen toevoegen (uitschalen) als het werk sneller moet worden verwerkt en kunnen werkrollen (inschalen) verwijderen als er onvoldoende werk is om de werknemers bezet te houden. Het is zelfs mogelijk om naar nul te schalen als de taakhub volledig inactief is. Wanneer de schaal naar nul wordt geschaald, zijn er helemaal geen werknemers; alleen de schaalcontroller en de opslag moeten actief blijven.
In het volgende diagram ziet u dit concept:
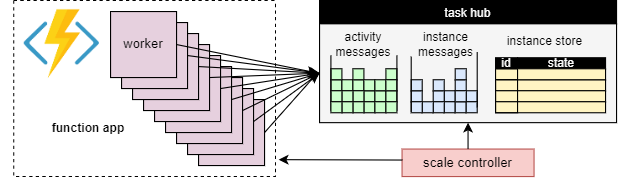
Automatische schaalaanpassing
Net als bij alle Azure Functions die worden uitgevoerd in de consumption- en Elastic Premium-abonnementen, ondersteunt Durable Functions automatisch schalen via de Azure Functions-schaalcontroller. De schaalcontroller controleert hoe lang berichten en taken moeten wachten voordat ze worden verwerkt. Op basis van deze latenties kan worden bepaald of werknemers moeten worden toegevoegd of verwijderd.
Notitie
Vanaf Durable Functions 2.0 kunnen functie-apps worden geconfigureerd voor uitvoering binnen met VNET beveiligde service-eindpunten in het Elastic Premium-abonnement. In deze configuratie starten de Durable Functions-triggers schaalaanvragen in plaats van de schaalcontroller. Zie Bewaking van runtimeschaal voor meer informatie.
In een Premium-abonnement kan automatisch schalen helpen om het aantal werknemers (en daarom de operationele kosten) ongeveer evenredig te houden met de belasting die de toepassing ondervindt.
CPU-gebruik
Orchestrator-functies worden uitgevoerd op één thread om ervoor te zorgen dat de uitvoering deterministisch kan zijn voor veel herhalingen. Vanwege deze uitvoering met één thread is het belangrijk dat orchestratorfunctiethreads geen CPU-intensieve taken uitvoeren, I/O uitvoeren of om welke reden dan ook blokkeren. Elk werk waarvoor I/O, blokkering of meerdere threads nodig kunnen zijn, moeten worden verplaatst naar activiteitsfuncties.
Activiteitsfuncties hebben hetzelfde gedrag als normale door wachtrij geactiveerde functies. Ze kunnen veilig I/O uitvoeren, CPU-intensieve bewerkingen uitvoeren en meerdere threads gebruiken. Omdat activiteitstriggers staatloos zijn, kunnen ze vrij worden uitgeschaald naar een niet-gebonden aantal VM's.
Entiteitsfuncties worden ook uitgevoerd op één thread en bewerkingen worden één voor één verwerkt. Entiteitsfuncties hebben echter geen beperkingen voor het type code dat kan worden uitgevoerd.
Time-outs voor functies
Activiteits-, orchestrator- en entiteitsfuncties zijn onderhevig aan dezelfde functietime-outs als alle Azure Functions. Als algemene regel behandelt Durable Functions functietime-outs op dezelfde manier als niet-verwerkte uitzonderingen die door de toepassingscode worden gegenereerd.
Als er bijvoorbeeld een time-out optreedt voor een activiteit, wordt de uitvoering van de functie vastgelegd als een fout en wordt de orchestrator op de hoogte gesteld en verwerkt de time-out net zoals elke andere uitzondering: nieuwe pogingen worden uitgevoerd als deze zijn opgegeven door de aanroep, of een uitzonderingshandler kan worden uitgevoerd.
Batchverwerking van entiteitsbewerkingen
Om de prestaties te verbeteren en de kosten te verlagen, kan één werkitem een volledige batch entiteitsbewerkingen uitvoeren. Bij verbruiksabonnementen wordt elke batch vervolgens gefactureerd als één functie-uitvoering.
Standaard is de maximale batchgrootte 50 voor verbruiksabonnementen en 5000 voor alle andere abonnementen. De maximale batchgrootte kan ook worden geconfigureerd in het host.json-bestand . Als de maximale batchgrootte 1 is, wordt batchverwerking effectief uitgeschakeld.
Notitie
Als het lang duurt voordat afzonderlijke entiteitsbewerkingen worden uitgevoerd, kan het nuttig zijn om de maximale batchgrootte te beperken om het risico op time-outs van functies te verminderen, met name voor verbruiksplannen.
Exemplaar opslaan in cache
Over het algemeen moet een werkitem voor een indeling een werkrol beide verwerken
- Haal de indelingsgeschiedenis op.
- De orchestratorcode opnieuw afspelen met behulp van de geschiedenis.
Als dezelfde werkrol meerdere werkitems voor dezelfde indeling verwerkt, kan de opslagprovider dit proces optimaliseren door de geschiedenis in het geheugen van de werkrol in de cache op te slaan, waardoor de eerste stap wordt geëlimineerd. Bovendien kan de orchestrator voor de mid-execution in de cache worden opgeslagen, waardoor ook de tweede stap, het opnieuw afspelen van de geschiedenis wordt geëlimineerd.
Het typische effect van caching is minder I/O ten opzichte van de onderliggende opslagservice en een algehele verbeterde doorvoer en latentie. Aan de andere kant verhoogt caching het geheugenverbruik op de werkrol.
Caching van exemplaren wordt momenteel ondersteund door de Azure Storage-provider en door de Netherite-opslagprovider. De onderstaande tabel bevat een vergelijking.
| Azure Storage-provider | Netherite-opslagprovider | MSSQL-opslagprovider | |
|---|---|---|---|
| Exemplaar opslaan in cache | Ondersteund (Alleen in-process worker.NET) |
Ondersteund | Niet ondersteund |
| Standaardinstelling | Disabled | Ingeschakeld | N.v.t. |
| Mechanisme | Uitgebreide sessies | Exemplaarcache | N.v.t. |
| Documentatie | Uitgebreide sessies bekijken | Exemplaarcache bekijken | N.v.t. |
Tip
Caching kan verminderen hoe vaak geschiedenissen opnieuw worden afgespeeld, maar het kan niet helemaal opnieuw afspelen elimineren. Bij het ontwikkelen van orchestrators raden we u ten zeerste aan deze te testen op een configuratie die caching uitschakelt. Dit gedrag voor geforceerde herhaling kan nuttig zijn voor het detecteren van schendingen van orchestrator-functiecode tijdens de ontwikkeling.
Vergelijking van cachemechanismen
De providers gebruiken verschillende mechanismen om caching te implementeren en bieden verschillende parameters om het cachinggedrag te configureren.
- Uitgebreide sessies, zoals gebruikt door de Azure Storage-provider, houden orchestrators voor de uitvoering in het geheugen totdat ze enige tijd inactief zijn. De parameters voor het beheren van dit mechanisme zijn
extendedSessionsEnabledenextendedSessionIdleTimeoutInSeconds. Zie de sectie Uitgebreide sessies van de Azure Storage-providerdocumentatie voor meer informatie.
Notitie
Uitgebreide sessies worden alleen ondersteund in de .NET-in-process worker.
- De instantiecache, zoals wordt gebruikt door de Netherite-opslagprovider, houdt de status van alle exemplaren, inclusief hun geschiedenis, in het geheugen van de werkrol, bij terwijl het totale geheugen wordt bijgehouden. Als de cachegrootte de limiet overschrijdt die is geconfigureerd
InstanceCacheSizeMBdoor, worden de minst recent gebruikte exemplaargegevens verwijderd. AlsCacheOrchestrationCursorsdeze optie is ingesteld op waar, slaat de cache ook de orchestrators voor de mid-execution op, samen met de instantiestatus. Zie de sectie Exemplaarcache van de documentatie van de Netherite-opslagprovider voor meer informatie.
Notitie
Exemplaarcaches werken voor alle taal-SDK's, maar de CacheOrchestrationCursors optie is alleen beschikbaar voor de .NET-in-process worker.
Gelijktijdigheidsbeperkingen
Eén werkrolexemplaren kunnen meerdere werkitems gelijktijdig uitvoeren. Dit helpt bij het verhogen van parallelle uitvoering en efficiënter gebruik te maken van de werknemers. Als een werkrol echter te veel werkitems tegelijk probeert te verwerken, kan het de beschikbare resources, zoals de CPU-belasting, het aantal netwerkverbindingen of het beschikbare geheugen, uitputten.
Om ervoor te zorgen dat een afzonderlijke werknemer niet te veel werk gaat, kan het nodig zijn om de gelijktijdigheid per instantie te beperken. Door het aantal functies te beperken dat gelijktijdig op elke werkrol wordt uitgevoerd, kunnen we voorkomen dat de resourcelimieten voor die werkrol worden uitgeput.
Notitie
De gelijktijdigheidsbeperkingen zijn alleen lokaal van toepassing om te beperken wat er momenteel per werkrol wordt verwerkt. Deze beperkingen beperken dus niet de totale doorvoer van het systeem.
Tip
In sommige gevallen kan het beperken van de gelijktijdigheid per werkrol de totale doorvoer van het systeem verhogen . Dit kan gebeuren wanneer elke werkrol minder werk kost, waardoor de schaalcontroller meer werkrollen toevoegt om de wachtrijen bij te houden, waardoor de totale doorvoer wordt verhoogd.
Configuratie van beperkingen
Gelijktijdigheidslimieten voor activiteits-, orchestrator- en entiteitsfuncties kunnen worden geconfigureerd in het host.json-bestand . De relevante instellingen zijn durableTask/maxConcurrentActivityFunctions voor activiteitsfuncties en durableTask/maxConcurrentOrchestratorFunctions voor orchestrator- en entiteitsfuncties. Deze instellingen bepalen het maximum aantal orchestrator-, entiteits- of activiteitsfuncties die in het geheugen op één werkrol worden geladen.
Notitie
Indelingen en entiteiten worden alleen in het geheugen geladen wanneer ze actief gebeurtenissen of bewerkingen verwerken, of als het opslaan van exemplaren in cache is ingeschakeld. Nadat de logica is uitgevoerd en in afwachting is (dat wil zeggen een await (C#) of yield (JavaScript,Python)-instructie in de orchestratorfunctiecode te bereiken, kunnen ze uit het geheugen worden verwijderd. Indelingen en entiteiten die uit het geheugen worden verwijderd, tellen niet mee voor de maxConcurrentOrchestratorFunctions vertraging. Zelfs als miljoenen indelingen of entiteiten de status Actief hebben, tellen ze alleen mee voor de beperkingslimiet wanneer ze in het actieve geheugen worden geladen. Een indeling die een activiteitsfunctie plant, telt op dezelfde manier niet mee als de orchestration wacht totdat de uitvoering van de activiteit is voltooid.
Functions 2.0
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Functions 1.x
{
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
Overwegingen voor taalruntime
De geselecteerde taalruntime kan strikte gelijktijdigheidsbeperkingen of uw functies opleggen. Durable Function-apps die zijn geschreven in Python of PowerShell bieden bijvoorbeeld alleen ondersteuning voor het uitvoeren van één functie tegelijk op één VIRTUELE machine. Dit kan leiden tot aanzienlijke prestatieproblemen als er niet zorgvuldig rekening mee wordt gehouden. Als een orchestrator bijvoorbeeld uitwisselt naar 10 activiteiten, maar de taalruntime de gelijktijdigheid beperkt tot slechts één functie, blijven 9 van de 10 activiteitsfuncties hangen totdat de uitvoering kan worden uitgevoerd. Bovendien kunnen deze 9 vastgelopen activiteiten niet worden verdeeld over andere werkrollen, omdat de Durable Functions-runtime ze al in het geheugen heeft geladen. Dit wordt vooral problematisch als de activiteitsfuncties langlopend zijn.
Als de taalruntime die u gebruikt een beperking voor gelijktijdigheid plaatst, moet u de Durable Functions-gelijktijdigheidsinstellingen bijwerken zodat deze overeenkomen met de gelijktijdigheidsinstellingen van uw taalruntime. Dit zorgt ervoor dat de Durable Functions-runtime niet probeert meer functies gelijktijdig uit te voeren dan is toegestaan door de taalruntime, zodat alle in behandeling zijnde activiteiten worden verdeeld over andere VM's. Als u bijvoorbeeld een Python-app hebt die gelijktijdigheid beperkt tot 4 functies (mogelijk is deze alleen geconfigureerd met 4 threads op één taalwerkproces of 1 thread op 4 taalwerkprocessen), moet u zowel als maxConcurrentOrchestratorFunctions maxConcurrentActivityFunctions 4 configureren.
Zie De doorvoerprestaties van Python-apps in Azure Functions verbeteren voor meer informatie en aanbevelingen voor prestaties voor Python. De technieken die worden genoemd in deze referentiedocumentatie voor Python-ontwikkelaars kunnen een aanzienlijke invloed hebben op de prestaties en schaalbaarheid van Durable Functions.
Aantal partities
Sommige opslagproviders gebruiken een partitioneringsmechanisme en staan het opgeven van een partitionCount parameter toe.
Bij het gebruik van partitionering concurreren werknemers niet rechtstreeks voor afzonderlijke werkitems. In plaats daarvan worden de werkitems eerst gegroepeerd in partitionCount partities. Deze partities worden vervolgens toegewezen aan werkrollen. Deze gepartitioneerde benadering voor het laden van distributie kan helpen om het totale aantal benodigde opslagtoegang te verminderen. Het kan ook de cache van exemplaren inschakelen en de lokaliteit verbeteren omdat hiermee affiniteit wordt gemaakt: alle werkitems voor hetzelfde exemplaar worden verwerkt door dezelfde werkrol.
Notitie
Partitioneringslimieten worden uitgeschaald omdat bij de meeste partitionCount werkrollen werkitems uit een gepartitioneerde wachtrij kunnen worden verwerkt.
In de volgende tabel ziet u voor elke opslagprovider welke wachtrijen zijn gepartitioneerd en het toegestane bereik en de standaardwaarden voor de partitionCount parameter.
| Azure Storage-provider | Netherite-opslagprovider | MSSQL-opslagprovider | |
|---|---|---|---|
| Exemplaarberichten | Partitioned | Partitioned | Niet gepartitioneerd |
| Activiteitsberichten | Niet gepartitioneerd | Partitioned | Niet gepartitioneerd |
Verstek partitionCount |
4 | 12 | N.v.t. |
Maximum partitionCount |
16 | 32 | N.v.t. |
| Documentatie | Zie Orchestrator uitschalen | Overwegingen voor het tellen van partities bekijken | N.v.t. |
Waarschuwing
Het aantal partities kan niet meer worden gewijzigd nadat een taakhub is gemaakt. Daarom is het raadzaam om deze in te stellen op een groot genoeg waarde om tegemoet te komen aan toekomstige uitschaalvereisten voor het taakhub-exemplaar.
Configuratie van het aantal partities
De partitionCount parameter kan worden opgegeven in het host.json-bestand . In het volgende voorbeeld host.json codefragment de durableTask/storageProvider/partitionCount eigenschap (of durableTask/partitionCount in Durable Functions 1.x) instelt op 3.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Overwegingen voor het minimaliseren van aanroeplatenties
Onder normale omstandigheden moeten aanroepaanvragen (naar activiteiten, orchestrators, entiteiten, enzovoort) vrij snel worden verwerkt. Er is echter geen garantie voor de maximale latentie van een aanroepaanvraag, omdat deze afhankelijk is van factoren zoals: het type schaalgedrag van uw App Service-plan, uw gelijktijdigheidsinstellingen en de grootte van de achterstand van uw toepassing. Daarom raden we u aan te investeren in stresstests om de staartlatenties van uw toepassing te meten en te optimaliseren.
Prestatiedoelen
Bij het plannen van het gebruik van Durable Functions voor een productietoepassing is het belangrijk om vroeg in het planningsproces rekening te houden met de prestatievereisten. Enkele eenvoudige gebruiksscenario's zijn:
- Uitvoering van sequentiële activiteit: in dit scenario wordt een orchestratorfunctie beschreven waarmee een reeks activiteitsfuncties achter elkaar wordt uitgevoerd. Het lijkt het meest op het voorbeeld van functieketens .
- Uitvoering van parallelle activiteit: in dit scenario wordt een orchestratorfunctie beschreven waarmee veel activiteitsfuncties parallel worden uitgevoerd met behulp van het fan-out-, fan-in-patroon .
- Parallelle responsverwerking: dit scenario is de tweede helft van het fan-out- en fan-in-patroon . Het richt zich op de prestaties van de ventilator. Het is belangrijk om te weten dat in tegenstelling tot fan-out fan-in door één orchestratorfunctie-exemplaar wordt uitgevoerd en daarom alleen kan worden uitgevoerd op één VIRTUELE machine.
- Verwerking van externe gebeurtenissen: dit scenario vertegenwoordigt één orchestratorfunctie-exemplaar dat één voor één wacht op externe gebeurtenissen.
- Verwerking van entiteitsbewerkingen: in dit scenario wordt getest hoe snel één tellerentiteit een constante stroom bewerkingen kan verwerken.
We bieden doorvoernummers voor deze scenario's in de respectieve documentatie voor de opslagproviders. Met name:
- zie Prestatiedoelen voor de Azure Storage-provider.
- zie Basisscenario's voor de Netherite-opslagprovider.
- zie Benchmarks voor orchestration-doorvoer voor de MSSQL-opslagprovider.
Tip
In tegenstelling tot fan-out zijn ventilatorbewerkingen beperkt tot één VIRTUELE machine. Als uw toepassing gebruikmaakt van het fan-out-, fan-in-patroon en u zich zorgen maakt over de prestaties van ventilatoren, kunt u overwegen om de activiteitsfunctie uit te delen in meerdere subindelingen.