Actieve geo-replicatie
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
Actieve geo-replicatie is een functie waarmee u een continu gesynchroniseerde, leesbare secundaire database voor een primaire database kunt maken. De leesbare secundaire database bevindt zich mogelijk in dezelfde Azure-regio als de primaire of, wat gebruikelijker is, in een andere regio. Dit type leesbare secundaire database wordt ook wel een geo-secundaire of geo-replica genoemd.
Actieve geo-replicatie wordt per database geconfigureerd en ondersteunt alleen handmatige failover. Als u een failover wilt uitvoeren voor een groep databases of als uw toepassing een stabiel verbindingseindpunt vereist, kunt u in plaats daarvan failovergroepen overwegen.
U kunt SQL Database ook migreren met actieve geo-replicatie.
Overzicht
Actieve geo-replicatie is ontworpen als een bedrijfscontinuïteitsoplossing. Met actieve geo-replicatie kunt u snel herstel na noodgevallen uitvoeren van afzonderlijke databases als er sprake is van een regionale noodgeval of een grootschalige storing. Zodra geo-replicatie is ingesteld, kunt u een geo-failover initiëren naar een geo-secundaire regio in een andere Azure-regio. De geo-failover wordt programmatisch gestart door de toepassing of handmatig door de gebruiker.
In het volgende diagram ziet u een typische configuratie van een geografisch redundante cloudtoepassing met behulp van actieve geo-replicatie.
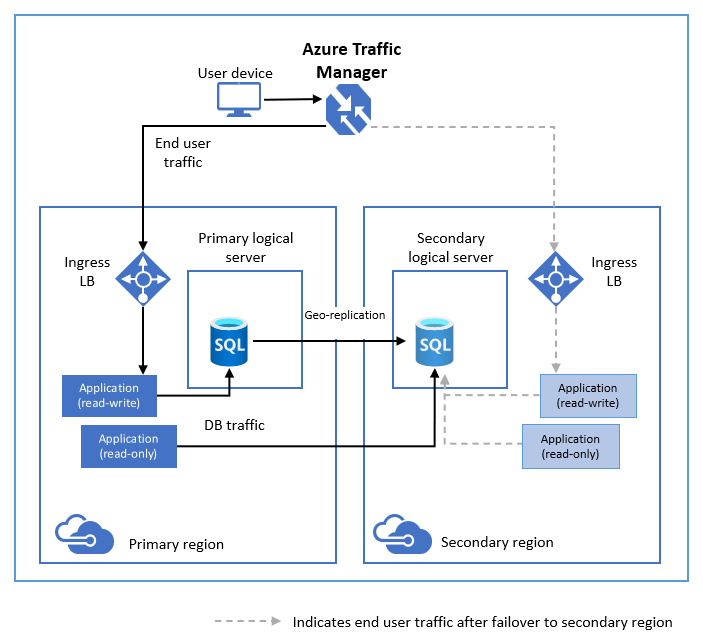
Als uw primaire database om welke reden dan ook uitvalt, kunt u een geo-failover naar een van uw secundaire databases initiëren. Wanneer een secundaire wordt gepromoveerd naar de primaire rol, worden alle andere secundaire secundaire bestanden automatisch gekoppeld aan de nieuwe primaire.
U kunt geo-replicatie beheren en een geo-failover starten met behulp van een van de volgende methoden:
- Azure Portal
- PowerShell: individuele database
- PowerShell: Elastische pool
- Transact-SQL: Individuele database of elastische pool
- REST API: Individuele database
Actieve geo-replicatie maakt gebruik van de AlwaysOn-beschikbaarheidsgroeptechnologie om het transactielogboek dat is gegenereerd op de primaire replica asynchroon te repliceren naar alle geo-replica's. Hoewel op een bepaald moment een secundaire database iets achter kan blijven bij de primaire database, zijn de gegevens op een secundaire database gegarandeerd transactieconsistent. Met andere woorden, wijzigingen die zijn aangebracht door niet-doorgevoerde transacties, zijn niet zichtbaar.
Notitie
Actieve geo-replicatie repliceert wijzigingen door het transactielogboek van de primaire replica naar secundaire replica's te streamen. Het is niet gerelateerd aan transactionele replicatie, waarmee wijzigingen worden gerepliceerd door DML-opdrachten (INSERT, UPDATE, DELETE) uit te voeren op abonnees.
Geo-replicatie biedt regionale redundantie. Met regionale redundantie kunnen toepassingen snel herstellen van een permanent verlies van een hele Azure-regio of delen van een regio, veroorzaakt door natuurrampen, catastrofale menselijke fouten of schadelijke handelingen. RPO voor geo-replicatie vindt u in Overzicht van bedrijfscontinuïteit.
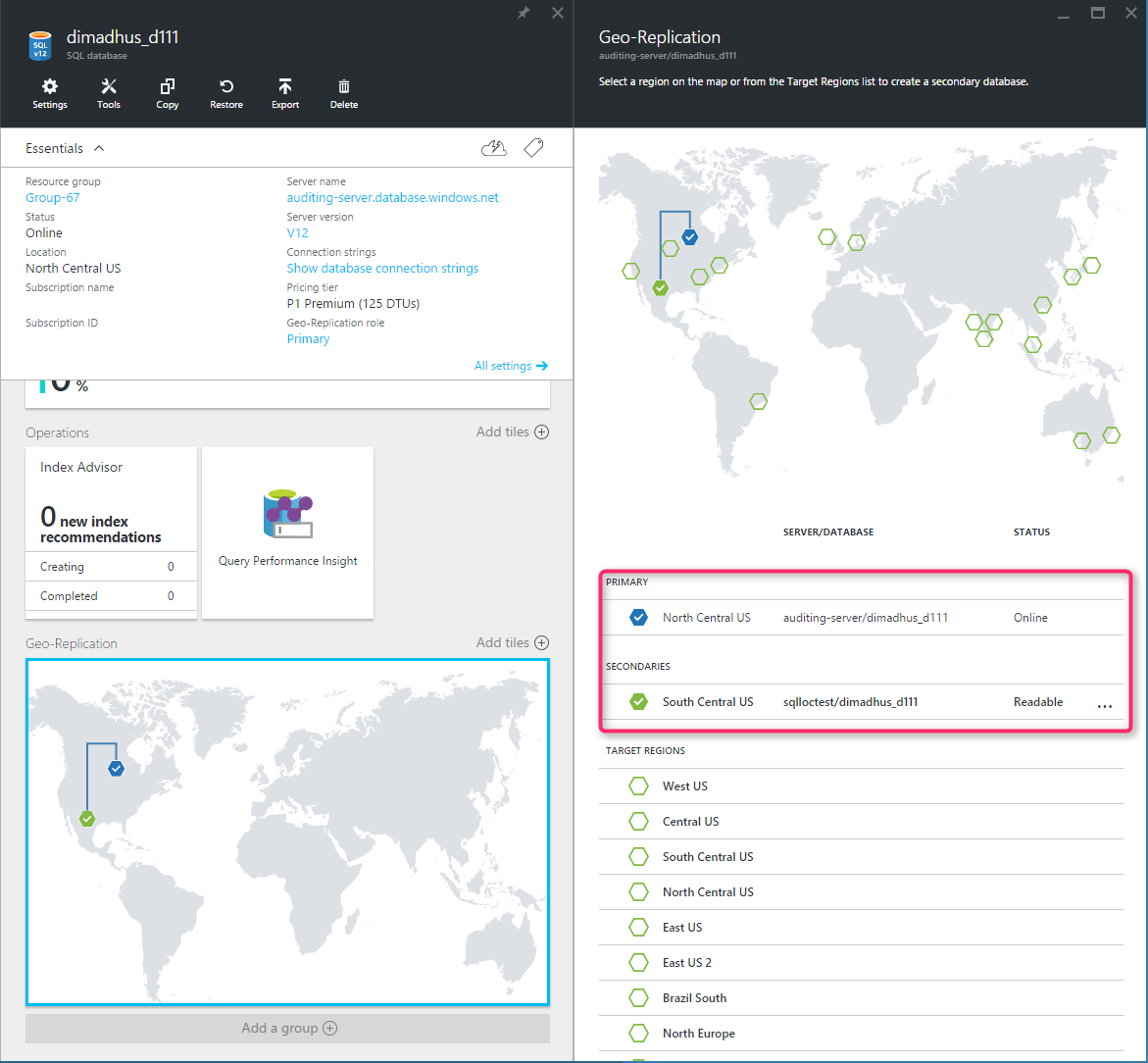
In de volgende afbeelding ziet u een voorbeeld van actieve geo-replicatie die is geconfigureerd met een primaire in de regio VS - noord-centraal en een geo-secundaire regio in de regio VS - zuid-centraal.
Naast herstel na noodgevallen kan actieve geo-replicatie worden gebruikt in de volgende scenario's:
- Databasemigratie: u kunt actieve geo-replicatie gebruiken om een database van de ene server naar de andere te migreren met minimale downtime.
- Toepassingsupgrades: U kunt een extra secundaire maken als een failback-kopie tijdens toepassingsupgrades.
Voor een volledige bedrijfscontinuïteit is het toevoegen van regionale redundantie van databases slechts een onderdeel van de oplossing. Als u een toepassing (service) end-to-end herstelt na een onherstelbare fout, moet u alle onderdelen herstellen die de service en afhankelijke services vormen. Voorbeelden van deze onderdelen zijn de clientsoftware (bijvoorbeeld een browser met een aangepast JavaScript), webfront-ends, opslag en DNS. Het is essentieel dat alle onderdelen bestand zijn tegen dezelfde fouten en beschikbaar zijn binnen de beoogde hersteltijd (RTO) van uw toepassing. Daarom moet u alle afhankelijke services identificeren en inzicht hebben in de garanties en mogelijkheden die ze bieden. Vervolgens moet u voldoende stappen ondernemen om ervoor te zorgen dat uw service functioneert tijdens de failover van de services waarvan deze afhankelijk is. Zie Cloudoplossingen ontwerpen voor herstel na noodgevallen met behulp van actieve geo-replicatie voor meer informatie over het ontwerpen van oplossingen voor herstel na noodgevallen.
Terminologie en mogelijkheden voor actieve geo-replicatie
Automatische asynchrone replicatie
U kunt alleen een geo-secundaire database maken voor een bestaande database. De geo-secundaire database kan worden gemaakt op elke logische server, behalve de server met de primaire database. Zodra de replica is gemaakt, wordt de geo-secundaire replica gevuld met de gegevens van de primaire database. Dit proces wordt seeding genoemd. Nadat een geo-secundaire database is gemaakt en geseed, worden updates voor de primaire database automatisch en asynchroon gerepliceerd naar de geo-secundaire replica. Asynchrone replicatie betekent dat transacties worden doorgevoerd op de primaire database voordat ze worden gerepliceerd.
Leesbare geo-secundaire replica's
Een toepassing heeft toegang tot een geo-secundaire replica om alleen-lezenquery's uit te voeren met dezelfde of verschillende beveiligingsprinciplen die worden gebruikt voor toegang tot de primaire database. Zie Alleen-lezen replica's gebruiken om alleen-lezen queryworkloads te offloaden voor meer informatie.
Belangrijk
U kunt geo-replicatie gebruiken om secundaire replica's te maken in dezelfde regio als de primaire. U kunt deze secundaire databases gebruiken om te voldoen aan uitschaalscenario's voor lezen in dezelfde regio. Een secundaire replica in dezelfde regio biedt echter geen extra tolerantie voor catastrofale storingen of grootschalige uitval, en is daarom geen geschikt failoverdoel voor herstel na noodgevallen. Het garandeert ook geen isolatie van beschikbaarheidszones. Gebruik Bedrijfskritiek of Premium-servicelagen zone-redundante configuratie of zone-redundante configuratie voor algemeen gebruik om isolatie van beschikbaarheidszones te bereiken.
Failover (geen gegevensverlies)
Failover schakelt de rollen van primaire en geo-secundaire databases over nadat de volledige gegevenssynchronisatie is voltooid, zodat er geen gegevensverlies is. De duur van de failover is afhankelijk van de grootte van het transactielogboek op de primaire die moet worden gesynchroniseerd met de geo-secundaire. Failover is ontworpen voor de volgende scenario's:
- Dr-drills uitvoeren in productie wanneer het gegevensverlies niet acceptabel is
- De database verplaatsen naar een andere regio
- Retourneer de database naar de primaire regio nadat de storing is verzacht (ook wel failback genoemd).
Geforceerde failover (mogelijk gegevensverlies)
Geforceerde failover schakelt onmiddellijk de geo-secundaire over naar de primaire rol zonder te wachten op synchronisatie met de primaire rol. Alle transacties die zijn vastgelegd op de primaire, maar nog niet gerepliceerd naar de secundaire, gaan verloren. Deze bewerking is ontworpen als een herstelmethode tijdens storingen wanneer de primaire bewerking niet toegankelijk is, maar de beschikbaarheid van de database moet snel worden hersteld. Wanneer de oorspronkelijke primaire versie weer online is, wordt deze automatisch opnieuw verbonden, opnieuw verzonden met behulp van de huidige gegevens van de primaire en wordt deze de nieuwe geo-secundaire.
Belangrijk
Na een failover of geforceerde failover wordt het verbindingseindpunt voor de nieuwe primaire wijzigingen doorgevoerd, omdat de nieuwe primaire zich nu op een andere logische server bevindt.
Meerdere leesbare geo-secundaire bestanden
Er kunnen maximaal vier geo-secundaire bestanden worden gemaakt voor een primaire database. Als er slechts één secundaire is en deze mislukt, wordt de toepassing blootgesteld aan een hoger risico totdat er een nieuwe secundaire wordt gemaakt. Als er meerdere secundaire bestanden bestaan, blijft de toepassing beveiligd, zelfs als een van de secundaire bestanden mislukt. Extra secundaire databases kunnen ook worden gebruikt om alleen-lezenworkloads uit te schalen.
Tip
Als u actieve geo-replicatie gebruikt om een wereldwijd gedistribueerde toepassing te bouwen en alleen-lezentoegang tot gegevens in meer dan vier regio's moet bieden, kunt u een secundaire van een secundaire (een proces dat bekend staat als keten) maken om extra geo-replica's te maken. Replicatievertraging op geo-replica's in een keten is mogelijk hoger dan op geo-replica's die rechtstreeks zijn verbonden met de primaire replica. Het instellen van gekoppelde geo-replicatietopologieën wordt alleen programmatisch ondersteund en niet vanuit De Azure-portal.
Geo-replicatie van databases in een elastische pool
Elke geo-secundaire database kan één database of een database in een elastische pool zijn. De keuze voor elastische pools voor elke geo-secundaire database is gescheiden en is niet afhankelijk van de configuratie van een andere replica in de topologie (primair of secundair). Elke elastische pool bevindt zich in één logische server. Omdat databasenamen op een logische server uniek moeten zijn, kunnen meerdere geo-secundaire databases van dezelfde primaire server nooit een elastische pool delen.
Door de gebruiker beheerde geo-failover en failback
Een geo-secundaire die de eerste seeding heeft voltooid, kan expliciet worden overgeschakeld naar de primaire rol (failover) op elk gewenst moment door de toepassing of de gebruiker. Tijdens een storing waarbij de primaire niet toegankelijk is, kan alleen geforceerde failover worden gebruikt, waardoor een geo-secundaire locatie onmiddellijk wordt bevorderd als de nieuwe primaire. Wanneer de storing wordt verzacht, wordt het herstelde primaire systeem automatisch een geo-secundair en wordt deze bijgewerkt met de nieuwe primaire. Vanwege de asynchrone aard van geo-replicatie kunnen recente transacties verloren gaan tijdens geforceerde failovers als de primaire failover mislukt voordat deze transacties worden gerepliceerd naar een geo-secundaire. Wanneer een primaire met meerdere geo-secundaire bestanden een failover uitvoert, worden replicatierelaties automatisch opnieuw geconfigureerd en worden de resterende geo-secundaire bestanden gekoppeld aan de zojuist gepromoveerde primaire, zonder tussenkomst van de gebruiker. Na de storing die de geo-failover heeft veroorzaakt, kan het wenselijk zijn om de primaire naar de oorspronkelijke regio te retourneren. Voer hiervoor een handmatige failover uit.
Stand-byreplica
Als uw secundaire replica alleen wordt gebruikt voor herstel na noodgevallen en geen lees- of schrijfworkloads heeft, kunt u de replica als stand-by instellen om te besparen op licentiekosten.
Voorbereiden op geo-failover
Controleer of de verificatie en netwerktoegang voor uw secundaire server correct zijn geconfigureerd om ervoor te zorgen dat uw toepassing direct toegang heeft tot de nieuwe primaire primaire na geo-failover. Zie SQL Database-beveiliging na herstel na noodgeval voor meer informatie. Controleer ook of het bewaarbeleid voor back-ups voor de secundaire database overeenkomt met het beleid van de primaire database. Deze instelling maakt geen deel uit van de database en wordt niet gerepliceerd vanaf de primaire database. De geo-secundaire is standaard geconfigureerd met een standaardretentieperiode van zeven dagen. Zie automatische back-ups van SQL Database voor meer informatie.
Belangrijk
Als uw database lid is van een failovergroep, kunt u de failover niet initiëren met behulp van de opdracht failover voor geo-replicatie. Gebruik de failoveropdracht voor de groep. Als u een failover van een afzonderlijke database wilt uitvoeren, moet u deze eerst verwijderen uit de failovergroep. Zie Failover-groepen voor meer informatie.
Geo-secundair configureren
Zowel de primaire als de geo-secundaire moeten dezelfde servicelaag hebben. Het wordt ook sterk aanbevolen dat de geo-secundaire omgeving is geconfigureerd met dezelfde redundantie voor back-upopslag, rekenlaag (ingericht of serverloos) en rekengrootte (DTU's of vCores) als de primaire. Als de primaire een zware schrijfworkload ondervindt, kan een geo-secundaire met een lagere rekenkracht mogelijk niet bijhouden. Dit veroorzaakt replicatievertraging op de geo-secundaire locatie en kan uiteindelijk leiden tot onbeschikbaarheid van de geo-secundaire locatie. Om deze risico's te beperken, vermindert actieve geo-replicatie de snelheid van het primaire transactielogboek indien nodig om de secundaire bestanden in te halen.
Een ander gevolg van een onevenwichtige geo-secundaire configuratie is dat na een failover de prestaties van toepassingen kunnen lijden vanwege onvoldoende rekencapaciteit van de nieuwe primaire. In dat geval is het nodig om de database omhoog te schalen om voldoende resources te hebben, wat veel tijd kan duren en een failover met hoge beschikbaarheid aan het einde van het proces voor omhoog schalen vereist, waardoor toepassingsworkloads kunnen worden onderbroken.
Als u besluit om de geo-secundaire te maken met een andere configuratie, moet u de I/O-snelheid van het logboek bewaken op de primaire na verloop van tijd. Hiermee kunt u een schatting maken van de minimale rekenkracht van de geo-secundaire die nodig is om de replicatiebelasting te ondersteunen. Als uw primaire database bijvoorbeeld P6 (1000 DTU) is en de bijbehorende logboek-IO 50% heeft, moet de geo-secundaire database ten minste P4 (500 DTU) zijn. Gebruik de sys.resource_stats weergave om historische LOGBOEK-IO-gegevens op te halen. Gebruik de sys.dm_db_resource_stats-weergave om recente IO-gegevens voor logboeken op te halen met een hogere granulariteit die beter op korte termijn pieken weerspiegelt.
Tip
Io-beperking voor transactielogboeken op de primaire server vanwege een lagere rekenkracht op een geo-secundaire locatie wordt gerapporteerd met behulp van het HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO wachttype, zichtbaar in de sys.dm_exec_requests en sys.dm_os_wait_stats databaseweergaven.
Io voor transactielogboek op de primaire schijf kan worden beperkt om redenen die niet zijn gerelateerd aan een lagere rekenkracht op een geo-secundaire locatie. Dit soort beperking kan zich voordoen, zelfs als de geo-secundaire locatie dezelfde of hogere rekenkracht heeft dan de primaire. Zie Beheer van transactielogboeksnelheid voor meer informatie, waaronder wachttypen voor verschillende soorten io-beperking voor logboeken.
Standaard is de redundantie van back-upopslag van de geo-secundaire locatie hetzelfde als voor de primaire database. U kunt ervoor kiezen om een geo-secundaire locatie te configureren met een andere redundantie voor back-upopslag. Back-ups worden altijd gemaakt op de primaire database. Als de secundaire is geconfigureerd met een andere redundantie voor back-upopslag, worden na een geo-failover, wanneer de geo-secundaire wordt gepromoveerd naar de primaire, nieuwe back-ups opgeslagen en gefactureerd op basis van het type opslag (RA-GRS, ZRS, LRS) dat is geselecteerd op de nieuwe primaire (vorige secundaire).
Besparen op kosten met de stand-byreplica
Als uw secundaire replica alleen wordt gebruikt voor herstel na noodgevallen en geen lees- of schrijfworkloads heeft, kunt u besparen op licentiekosten door de database voor stand-by aan te wijzen wanneer u een nieuwe actieve geo-replicatierelatie configureert.
Bekijk licentievrije stand-byreplica voor meer informatie.
Geo-replicatie binnen meerdere abonnementen
Gebruik Transact-SQL (T-SQL) om een geografisch secundair abonnement te maken in een ander abonnement dan het abonnement van het primaire abonnement (ongeacht of deze zich onder dezelfde tenant van Microsoft Entra ID (voorheen Azure Active Directory) bevinden of niet. Raadpleeg Actieve geo-replicatie configureren voor meer informatie.
Referenties en firewallregels gesynchroniseerd houden
Wanneer u openbare netwerktoegang gebruikt om verbinding te maken met de database, raden we u aan IP-firewallregels op databaseniveau te gebruiken voor geo-gerepliceerde databases. Deze regels worden gerepliceerd met de database, waardoor alle geo-secundaire bestanden dezelfde IP-firewallregels hebben als de primaire database. Deze aanpak elimineert de noodzaak voor klanten om firewallregels handmatig te configureren en te onderhouden op servers die als host fungeren voor de primaire en secundaire databases. Op dezelfde manier zorgt het gebruik van ingesloten databasegebruikers voor gegevenstoegang ervoor dat zowel primaire als secundaire databases altijd dezelfde verificatiereferenties hebben. Op deze manier zijn er na een geo-failover geen onderbrekingen vanwege niet-overeenkomende verificatiereferenties. Als u aanmeldingen en gebruikers gebruikt (in plaats van ingesloten gebruikers), moet u extra stappen uitvoeren om ervoor te zorgen dat dezelfde aanmeldingen bestaan voor uw secundaire database. Zie Aanmeldingen en gebruikers configureren voor configuratiedetails.
Primaire database schalen
U kunt de primaire database omhoog of omlaag schalen naar een andere rekenkracht (binnen dezelfde servicelaag) zonder de verbinding met geo-secundaire databases te verbreken. Wanneer u omhoog schaalt, raden we u aan om eerst de geo-secundaire locatie omhoog te schalen en vervolgens de primaire op te schalen. Wanneer u omlaag schaalt, draait u de volgorde om: schaal eerst de primaire database omlaag en schaal vervolgens de secundaire database omlaag.
Notitie
Als u een geo-secundaire database hebt gemaakt als onderdeel van een failovergroepsconfiguratie, wordt het afgeraden deze omlaag te schalen. Zo zorgt u ervoor dat uw gegevenslaag voldoende capaciteit heeft om uw normale workload te verwerken nadat een geo-failover is geactiveerd.
Belangrijk
De primaire database in een failovergroep kan niet worden geschaald naar een hogere servicelaag (editie), tenzij de secundaire database eerst naar de hogere laag wordt geschaald. Als u bijvoorbeeld de primaire schaal omhoog wilt schalen van Algemeen gebruik naar Bedrijfskritiek, moet u eerst de geo-secundaire schaal naar Bedrijfskritiek schalen. Als u de primaire of geo-secundaire schaal probeert te schalen op een manier die deze regel schendt, krijgt u de volgende foutmelding:
The source database 'Primaryserver.DBName' cannot have higher edition than the target database 'Secondaryserver.DBName'. Upgrade the edition on the target before upgrading the source.
Verlies van kritieke gegevens voorkomen
Vanwege de hoge latentie van wide area networks maakt geo-replicatie gebruik van een asynchroon replicatiemechanisme. Asynchrone replicatie maakt de mogelijkheid van gegevensverlies onvermijdelijk als de primaire mislukt. Een toepassingsontwikkelaar kan de sp_wait_for_database_copy_sync opgeslagen procedure onmiddellijk na het doorvoeren van de transactie aanroepen om kritieke transacties te beschermen tegen gegevensverlies. Het aanroepen sp_wait_for_database_copy_sync blokkeert de aanroepende thread totdat de laatste doorgevoerde transactie is verzonden en beperkt in het transactielogboek van de secundaire database. Er wordt echter niet gewacht totdat de verzonden transacties opnieuw worden afgespeeld (opnieuw worden afgespeeld) op de secundaire. sp_wait_for_database_copy_sync is gericht op een specifieke geo-replicatiekoppeling. Elke gebruiker met de verbindingsrechten voor de primaire database kan deze procedure aanroepen.
Notitie
sp_wait_for_database_copy_sync voorkomt gegevensverlies na geo-failover voor specifieke transacties, maar garandeert geen volledige synchronisatie voor leestoegang. De vertraging die wordt veroorzaakt door een sp_wait_for_database_copy_sync procedure-aanroep kan aanzienlijk zijn en is afhankelijk van de grootte van het nog niet verzonden transactielogboek op de primaire op het moment van de oproep.
Vertraging van geo-replicatie bewaken
Als u de vertraging met betrekking tot RTO wilt bewaken, gebruikt u de kolom replication_lag_sec van sys.dm_geo_replication_link_status in de primaire database. Er wordt een vertraging in seconden weergegeven tussen de transacties die zijn doorgevoerd op de primaire en het transactielogboek op de secundaire locatie. Als de vertraging bijvoorbeeld één seconde is, betekent dit dat als de primaire op dit moment wordt beïnvloed door een storing en er een geo-failover wordt gestart, transacties die in de laatste seconde zijn doorgevoerd, verloren gaan.
Als u vertraging wilt meten met betrekking tot wijzigingen in de primaire database die zijn beperkt op de geo-secundaire database, vergelijkt u last_commit tijd op de geo-secundaire database met dezelfde waarde op de primaire database.
Tip
Als replication_lag_sec op de primaire waarde NULL is, betekent dit dat de primaire waarde momenteel niet weet hoe ver achter een geo-secundaire locatie ligt. Dit gebeurt meestal nadat het proces opnieuw is opgestart en een tijdelijke voorwaarde moet zijn. U kunt een waarschuwing verzenden als replication_lag_sec NULL gedurende een langere periode retourneert. Het kan erop wijzen dat de geo-secundaire database niet kan communiceren met de primaire vanwege een verbindingsfout.
Er zijn ook voorwaarden die het verschil tussen last_commit tijd op de geo-secundaire en de primaire kunnen veroorzaken om groot te worden. Als er bijvoorbeeld na een lange periode geen wijzigingen worden doorgevoerd op de primaire doorvoer, springt het verschil omhoog naar een grote waarde voordat u snel terugkeert naar nul. U kunt een waarschuwing verzenden als het verschil tussen deze twee waarden lang groot blijft.
Programmatisch actieve geo-replicatie beheren
Zoals eerder besproken, kan actieve geo-replicatie ook programmatisch worden beheerd met behulp van T-SQL, Azure PowerShell en REST API. In de volgende tabellen wordt de set opdrachten beschreven die beschikbaar zijn. Actieve geo-replicatie bevat een set Azure Resource Manager-API's voor beheer, waaronder de Azure SQL Database REST API en Azure PowerShell-cmdlets. Deze API's ondersteunen op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC). Zie Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) voor meer informatie over het implementeren van toegangsrollen.
T-SQL: Geo-failover van individuele en pooldatabases beheren
Belangrijk
Deze T-SQL-opdrachten zijn alleen van toepassing op actieve geo-replicatie en zijn niet van toepassing op failovergroepen. Daarom zijn ze ook niet van toepassing op SQL Managed Instance, dat alleen failovergroepen ondersteunt.
| Opdracht | Beschrijving |
|---|---|
| ALTER DATABASE | Gebruik HET argument ADD SECONDARY ON SERVER om een secundaire database te maken voor een bestaande database en de gegevensreplicatie te starten |
| ALTER DATABASE | Failover of FORCE_FAILOVER_ALLOW_DATA_LOSS gebruiken om over te schakelen naar een secundaire database om een failover te starten |
| ALTER DATABASE | Gebruik REMOVE SECONDARY ON SERVER om een gegevensreplicatie tussen een SQL Database en de opgegeven secundaire database te beëindigen. |
| sys.geo_replication_links | Retourneert informatie over alle bestaande replicatiekoppelingen voor elke database op een server. |
| sys.dm_geo_replication_link_status | Hiermee haalt u de laatste replicatietijd, laatste replicatievertraging en andere informatie over de replicatiekoppeling voor een bepaalde database op. |
| sys.dm_operation_status | Geeft de status weer voor alle databasebewerkingen, inclusief wijzigingen in replicatiekoppelingen. |
| sys.sp_wait_for_database_copy_sync | Zorgt ervoor dat de toepassing wacht totdat alle vastgelegde transacties worden beperkt tot het transactielogboek van een geo-secundaire locatie. |
PowerShell: Geo-failover van individuele en pooldatabases beheren
Notitie
In dit artikel wordt gebruikgemaakt van de Azure Az PowerShell-module. Dit is de aanbevolen PowerShell-module voor interactie met Azure. Raadpleeg Azure PowerShell installeren om aan de slag te gaan met de Az PowerShell-module. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
Belangrijk
De module PowerShell Azure Resource Manager wordt nog steeds ondersteund in Azure SQL Database, maar alle toekomstige ontwikkeling is voor de Az.Sql-module. Zie AzureRM.Sql voor deze cmdlets. De argumenten voor de opdrachten in de Az-module en in de AzureRm-modules zijn vrijwel identiek.
| Cmdlet | Beschrijving |
|---|---|
| Get-AzSqlDatabase | Hiermee haalt u een of meer databases op. |
| New-AzSqlDatabaseSecondary | Hiermee maakt u een secundaire database voor een bestaande database en wordt gegevensreplicatie gestart. |
| Set-AzSqlDatabaseSecondary | Hiermee wordt overgeschakeld op een secundaire database als primaire om de failover te initiëren. |
| Remove-AzSqlDatabaseSecondary | Hiermee wordt gegevensreplicatie tussen een SQL Database en de opgegeven secundaire database beëindigd. |
| Get-AzSqlDatabaseReplicationLink | Hiermee haalt u de geo-replicatiekoppelingen voor een database op. |
Tip
Zie Een individuele database configureren en failover uitvoeren met behulp van actieve geo-replicatie en een failover uitvoeren van een pooldatabase met behulp van actieve geo-replicatie voor voorbeeldscripts.
REST API: Geo-failover van individuele en pooldatabases beheren
| API | Beschrijving |
|---|---|
| Database maken of bijwerken (createMode=Restore) | Hiermee maakt u een primaire of secundaire database, werkt u deze bij of herstelt u deze. |
| Databasestatus maken of bijwerken | Retourneert de status tijdens een maakbewerking. |
| Secundaire database instellen als primair (geplande failover) | Hiermee wordt ingesteld welke secundaire database primair is door een failover uit te voeren van de huidige primaire database. Deze optie wordt niet ondersteund voor SQL Managed Instance. |
| Secundaire database instellen als primair (niet-geplande failover) | Hiermee wordt ingesteld welke secundaire database primair is door een failover uit te voeren van de huidige primaire database. Deze bewerking kan leiden tot gegevensverlies. Deze optie wordt niet ondersteund voor SQL Managed Instance. |
| Replicatiekoppeling ophalen | Hiermee haalt u een specifieke replicatiekoppeling op voor een bepaalde database in een geo-replicatierelatie. Hiermee wordt de informatie opgehaald die zichtbaar is in de catalogusweergave sys.geo_replication_links. Deze optie wordt niet ondersteund voor SQL Managed Instance. |
| Replicatiekoppelingen - Lijst per database | Haalt alle replicatiekoppelingen voor een bepaalde database op in een geo-replicatierelatie. Hiermee wordt de informatie opgehaald die zichtbaar is in de catalogusweergave sys.geo_replication_links. |
| Replicatiekoppeling verwijderen | Hiermee verwijdert u een databasereplicatiekoppeling. Kan niet worden uitgevoerd tijdens een failover. |
Volgende stappen
- Zie voor voorbeeldscripts:
- SQL Database ondersteunt ook failovergroepen. Zie het gebruik van failovergroepen voor meer informatie.
- Raadpleeg Overzicht van bedrijfscontinuïteit voor een bedrijfscontinuïteitsoverzicht en bedrijfscontinuïteitsscenario's.
- Bespaar op licentiekosten door uw secundaire DR-replica aan te wijzen voor stand-by.
- Voor meer informatie over Azure SQL Database Hyperscale Geo-replica raadpleegt u Hyperscale Geo-replica
- Zie geautomatiseerde back-ups van SQL Database voor meer informatie over geautomatiseerde back-ups van Azure SQL Database.
- Zie Een database herstellen vanuit de door de service geïnitieerde back-ups voor meer informatie over het gebruik van geautomatiseerde back-ups voor herstel.
- Zie SQL Database-beveiliging na noodherstel voor meer informatie over verificatievereisten voor een nieuwe primaire server en database.