Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
De Azure AI Vision Image Analysis-service kan een groot aantal visuele functies uit uw afbeeldingen extraheren. Het kan bijvoorbeeld bepalen of een afbeelding inhoud voor volwassenen bevat, specifieke merken of objecten zoekt of menselijke gezichten zoekt.
De nieuwste versie van Afbeeldingsanalyse, 4.0, die nu algemeen beschikbaar is, heeft nieuwe functies zoals synchrone OCR en detectie van personen. U wordt aangeraden deze versie in de toekomst te gebruiken.
U kunt Afbeeldingsanalyse gebruiken via een clientbibliotheek-SDK of door de REST API rechtstreeks aan te roepen. Volg de snelstart om te beginnen.
U kunt ook de mogelijkheden van Afbeeldingsanalyse snel en eenvoudig uitproberen in uw browser met behulp van Vision Studio.
Deze documentatie bevat de volgende typen artikelen:
- De quickstarts zijn stapsgewijze instructies waarmee u aanroepen naar de service kunt maken en resultaten in een korte periode kunt krijgen.
- De instructiegidsen bevatten instructies voor het gebruik van de service op specifiekere of aangepaste manieren.
- De conceptuele artikelen bieden uitgebreide uitleg over de functionaliteit en functies van de service.
Volg een trainingsmodule voor afbeeldingsanalyse voor een meer gestructureerde benadering.
Versies van afbeeldingsanalyse
Belangrijk
Selecteer de VERSIE van de Afbeeldingsanalyse-API die het beste bij uw vereisten past.
| Versie | Beschikbare functies | Aanbeveling |
|---|---|---|
| versie 4.0 | Tekst, Bijschriften, Dichte bijschriften, Tags, Objectdetectie, Mensen, Slim bijsnijden | Betere modellen; gebruik versie 4.0 als deze uw use-case ondersteunt. |
| versie 3.2 | Tags, Objecten, Beschrijvingen, Merken, Gezichten, Afbeeldingstype, Kleurenschema, Bezienswaardigheden, Beroemdheden, Inhoud voor volwassenen, Slim bijsnijden | Een breder scala aan functies; versie 3.2 gebruiken als uw use-case nog niet wordt ondersteund in versie 4.0 |
U wordt aangeraden de Afbeeldingsanalyse 4.0-API te gebruiken als deze ondersteuning biedt voor uw use-case. Gebruik versie 3.2 als uw use-case nog niet wordt ondersteund door 4.0.
U moet ook versie 3.2 gebruiken als u afbeeldingsbijschriften wilt uitvoeren en uw Vision-resource zich buiten de ondersteunde Azure-regio's bevindt. De functie afbeeldingsbijschriften in Afbeeldingsanalyse 4.0 wordt alleen ondersteund in bepaalde Azure-regio's. Afbeeldingsbijschriften in versie 3.2 zijn beschikbaar in alle Azure AI Vision-regio's. Zie beschikbaarheid van regio's.
Afbeelding Analyseren
U kunt afbeeldingen analyseren om inzicht te krijgen in de visuele kenmerken en eigenschappen van die afbeeldingen. Alle functies in deze tabel worden geleverd door de Analyze Image-API. Volg een snelstart om aan de slag te gaan.
| Naam | Beschrijving | Conceptpagina |
|---|---|---|
| Modelaanpassing (v4.0-preview alleen) (verouderd) | U kunt aangepaste modellen maken en trainen om afbeeldingsclassificatie of objectdetectie uit te voeren. Gebruik uw eigen afbeeldingen, label ze met aangepaste tags en afbeeldingsanalyse traint een model dat is aangepast voor uw use-case. | Modelaanpassing |
| Tekst lezen uit afbeeldingen (alleen v4.0) | Versie 4.0 preview van afbeeldingsanalyse biedt de mogelijkheid om leesbare tekst uit afbeeldingen te extraheren. Vergeleken met de asynchrone Computer Vision 3.2 Read-API biedt de nieuwe versie de vertrouwde Read OCR-engine in een verbeterde, uniforme, synchrone API die het gemakkelijk maakt om OCR samen met andere inzichten in één enkele API-aanroep te verkrijgen. | OCR voor afbeeldingen |
| Personen in afbeeldingen detecteren (alleen v4.0) | Versie 4.0 van afbeeldingsanalyse biedt de mogelijkheid om personen in afbeeldingen te detecteren. De coördinaten van de omsluitende rechthoek van elke gedetecteerde persoon worden samen met een betrouwbaarheidsscore geretourneerd. | Detectie van personen |
| Bijschriften voor afbeeldingen genereren | Genereer een bijschrift van een afbeelding in een door mensen leesbare taal met behulp van volledige zinnen. Met de algoritmen van Computer Vision worden bijschriften gegenereerd op basis van de objecten die in de afbeelding zijn geïdentificeerd. Het model voor het bijschriften van afbeeldingen van versie 4.0 is een geavanceerdere implementatie en werkt met een breder scala aan invoerafbeeldingen. Deze is alleen beschikbaar in de bepaalde geografische regio's. Zie beschikbaarheid van regio's. Met versie 4.0 kunt u ook compacte bijschriften gebruiken, waarmee gedetailleerde bijschriften worden gegenereerd voor afzonderlijke objecten die in de afbeelding worden gevonden. De API-interface retourneert de coördinaten van het omkaderingsvak (in pixels) van elk object in de afbeelding, plus een bijschrift. U kunt deze functionaliteit gebruiken om beschrijvingen te genereren van afzonderlijke onderdelen van een afbeelding. 
|
Bijschriften voor afbeeldingen genereren (v3.2) (v4.0) |
| Objecten detecteren | Objectdetectie is vergelijkbaar met het gebruik van tags, maar de API retourneert de coördinaten van de omsluitende box voor elke tag die wordt toegepast. Als een afbeelding bijvoorbeeld een hond, kat en persoon bevat, worden deze objecten samen met hun coördinaten in de afbeelding vermeld. U kunt deze functie gebruiken om verdere relaties tussen de objecten in een afbeelding te verwerken. Ook weet u daardoor wanneer er meerdere exemplaren van dezelfde tag in een afbeelding voorkomen. 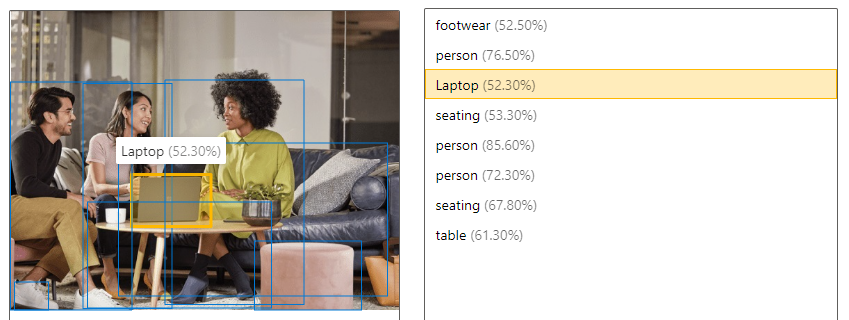
|
Objecten detecteren (v3.2) (v4.0) |
| Visuele kenmerken taggen | Identificeer en tag visuele kenmerken in een afbeelding op basis van een set met duizenden herkenbare objecten, levende wezens, landschappen en acties. Als de tags dubbelzinnig of niet algemeen bekend zijn, worden via de API-reactie tips gegeven om de context van de tag te verduidelijken. U kunt tagging niet alleen gebruiken voor het hoofdonderwerp, zoals een persoon op de voorgrond, maar ook voor de omgeving (binnen of buiten), meubels, gereedschap, planten, dieren, accessoires, gadgets en enzovoort.
|
Visuele kenmerken taggen (v3.2) (v4.0) |
| Het interessegebied ophalen / slim bijsnijden | Analyseer de inhoud van een afbeelding om de coördinaten te retourneren van het interessegebied dat overeenkomt met een opgegeven hoogte-breedteverhouding. Computer Vision retourneert de coördinaten van het begrenzingsvak van de regio, zodat de aanroepende toepassing de oorspronkelijke afbeelding naar wens kan wijzigen. Het model voor slim bijsnijden van versie 4.0 is een geavanceerdere implementatie en werkt met een breder scala aan invoerafbeeldingen. Deze is alleen beschikbaar in bepaalde geografische regio's. Zie beschikbaarheid van regio's. |
Een miniatuur genereren (v3.2) (v4.0 preview) |
| Merken detecteren (alleen v3.2) | Identificeer commerciële merken in afbeeldingen of video's met behulp van een database met duizenden logo's. U kunt deze functie bijvoorbeeld gebruiken om te ontdekken welke merken het populairst zijn op sociale media of het meest voorkomen in productplaatsing in de media. | Merken detecteren |
| Een afbeelding categoriseren (alleen v3.2) | Identificeer en categoriseer een volledige afbeelding met behulp van een categorietaxonomie met bovenliggende/onderliggende erfelijke hiërarchieën. Categorieën kunnen zelfstandig worden gebruikt of met onze nieuwe tagmodellen. Engels is momenteel de enige ondersteunde taal voor het taggen en categoriseren van afbeeldingen. |
Een afbeelding categoriseren |
| Gezichten detecteren (alleen v3.2) | Detecteer gezichten in een afbeelding en geef informatie op over elk gedetecteerd gezicht. Azure AI Vision retourneert de coördinaten, rechthoek, geslacht en leeftijd voor elk gedetecteerd gezicht. U kunt ook de toegewezen Face-API gebruiken voor deze doeleinden. Het biedt gedetailleerdere analyse, zoals gezichtsidentificatie en posedetectie. |
Gezichten detecteren |
| Afbeeldingstypen detecteren (alleen v3.2) | Detecteer kenmerken van een afbeelding, zoals of een afbeelding een lijntekening is of de waarschijnlijkheid dat het een knipkunst is. | Afbeeldingstypen detecteren |
| Domeinspecifieke inhoud detecteren (alleen v3.2) | Gebruik domeinmodellen om domeinspecifieke inhoud in een afbeelding te detecteren en te identificeren, zoals beroemdheden en oriëntatiepunten. Als een afbeelding bijvoorbeeld personen bevat, kan Azure AI Vision een domeinmodel voor beroemdheden gebruiken om te bepalen of de personen die in de afbeelding zijn gedetecteerd bekende beroemdheden zijn. | Domeinspecifieke inhoud detecteren |
| Het kleurenschema detecteren (alleen v3.2) | Analyseer het kleurgebruik in een afbeelding. Azure AI Vision kan bepalen of een afbeelding zwart-wit of kleur is en, voor kleurenafbeeldingen, de dominante en accentkleuren identificeren. | Het kleurenschema detecteren |
| Inhoud modereren in afbeeldingen (alleen v3.2) | U kunt Azure AI Vision gebruiken om inhoud voor volwassenen in een afbeelding te detecteren en betrouwbaarheidsscores te retourneren voor verschillende classificaties. De drempel voor het markeren van inhoud kan worden ingesteld met een glijdende schaal om uw voorkeuren aan te geven. | Inhoud voor volwassenen detecteren |
Productherkenning (alleen beschikbaar in v4.0-preview) (verouderd)
Belangrijk
Deze functie is nu afgeschaft. Op 31 maart 2025 wordt azure AI Image Analysis 4.0 Custom Image Classification, Custom Object Detection en Product Recognition preview-API buiten gebruik gesteld. Na deze datum mislukken API-aanroepen naar deze services.
Als u een soepele werking van uw modellen wilt behouden, gaat u over naar Azure AI Custom Vision. Deze is nu algemeen beschikbaar. Custom Vision biedt vergelijkbare functionaliteit als deze functies die worden uitgefaseerd.
Met de Product Recognition-API's kunt u foto's van planken in een winkel analyseren. U kunt de aanwezigheid of afwezigheid van producten detecteren en hun begrenzingsvakcoördinaten ophalen. Gebruik deze in combinatie met modelaanpassing om een model te trainen om uw specifieke producten te identificeren. U kunt productherkenningsresultaten ook vergelijken met het planogramdocument van uw winkel.
Multimodale insluitingen (alleen v4.0)
De multimodale insluitings-API's maken de vectorisatie van afbeeldingen en tekstquery's mogelijk. Ze converteren afbeeldingen naar coördinaten in een multidimensionale vectorruimte. Vervolgens kunnen binnenkomende tekstquery's ook worden geconverteerd naar vectoren en kunnen afbeeldingen worden vergeleken met de tekst op basis van semantische nabijheid. Hierdoor kan de gebruiker in een set afbeeldingen zoeken met behulp van tekst, zonder dat ze afbeeldingstags of andere metagegevens hoeven te gebruiken. Semantische closeness produceert vaak betere resultaten in de zoekopdracht.
De 2024-02-01 API bevat een multi-lingual model dat ondersteuning biedt voor zoeken in tekst in 102 talen. Het oorspronkelijke engelse model is nog steeds beschikbaar, maar kan niet worden gecombineerd met het nieuwe model in dezelfde zoekindex. Als u tekst en afbeeldingen heeft gevectord met behulp van een Engelstalig model, zullen deze vectoren niet compatibel zijn met meertalige tekst- en afbeeldingsvectoren.
Deze API's zijn alleen beschikbaar in bepaalde geografische regio's. Zie beschikbaarheid van regio's.
Achtergrond verwijderen (alleen v4.0 preview)
Belangrijk
Deze functie is nu afgeschaft. Op 31 maart 2025 wordt de Azure AI Image Analysis 4.0 Segment-API en de achtergrondverwijderingsservice buiten gebruik gesteld. Alle aanvragen voor deze service mislukken na deze datum.
De segmentatiefunctie van het opensource Florence 2-model kan aan uw behoeften voldoen. Er wordt een alfakaart geretourneerd die het verschil tussen de voorgrond en de achtergrond markeert, maar de oorspronkelijke afbeelding wordt niet bewerkt om de achtergrond te verwijderen. Installeer het Florence 2-model en probeer de functie 'Region naar segmentatie' uit.
Overweeg voor volledige functionaliteit van achtergrondverwijdering een hulpprogramma van derden, zoals BiRefNet.
Servicelimieten
Vereisten voor invoer
Afbeeldingsanalyse werkt voor afbeeldingen die voldoen aan de volgende vereisten:
- De afbeelding moet worden weergegeven in de indeling JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF of MPO
- De bestandsgrootte van de afbeelding moet kleiner zijn dan 20 megabyte (MB)
- De afmetingen van de afbeelding moeten groter zijn dan 50 x 50 pixels, en kleiner dan 16.000 x 16.000 pixels
Aanbeveling
Invoervereisten voor multimodale insluitingen verschillen en worden vermeld in multimodale insluitingen
Taalondersteuning
Er zijn verschillende functies voor afbeeldingsanalyse beschikbaar in verschillende talen. Zie de pagina Taalondersteuning .
Regionale beschikbaarheid
Als u de API's voor afbeeldingsanalyse wilt gebruiken, moet u uw Azure AI Vision-resource maken in een ondersteunde regio. De functies voor afbeeldingsanalyse zijn beschikbaar in de volgende regio's:
| Regio | Afbeelding Analyseren (min 4,0 bijschriften minder) |
Afbeelding Analyseren (inclusief 4.0 ondertiteling) |
Productherkenning | Multimodale insluitingen |
|---|---|---|---|---|
| Oost VS | ✅ | ✅ | ✅ | ✅ |
| West VS | ✅ | ✅ | ✅ | |
| West VS 2 | ✅ | ✅ | ✅ | |
| Frankrijk - centraal | ✅ | ✅ | ✅ | |
| Europa - noord | ✅ | ✅ | ✅ | |
| West-Europa | ✅ | ✅ | ✅ | |
| Zweden - centraal | ✅ | ✅ | ||
| Zwitserland - noord | ✅ | ✅ | ||
| Australië - oost | ✅ | ✅ | ||
| Azië - zuidoost | ✅ | ✅ | ✅ | |
| Azië - oost | ✅ | ✅ | ||
| Korea Centraal | ✅ | ✅ | ✅ | |
| Oost-Japan | ✅ | ✅ |
Gegevensprivacy en -beveiliging
Net als bij alle Azure AI-services moeten ontwikkelaars die de Azure AI Vision-service gebruiken, rekening houden met het beleid van Microsoft voor klantgegevens. Zie de pagina Azure AI-services in het Vertrouwenscentrum van Microsoft voor meer informatie.
Volgende stappen
Ga aan de slag met Afbeeldingsanalyse door de snelstartgids te volgen in de ontwikkeltaal en API-versie van uw voorkeur: