Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Overview
Met de debugmodus van Azure Data Factory en Synapse Analytics voor mapping-transformaties kunt u interactief de transformatie van gegevensstructuren bekijken terwijl u uw gegevensstromen bouwt en debugt. De debugsessie kan zowel in Data Flow ontwerpsessies als tijdens het debuggen van de uitvoering van pipeline gegevensstromen worden gebruikt. Als u de foutopsporingsmodus wilt inschakelen, gebruikt u de knop Data Flow Debug op de bovenste balk van data flow canvas of pijplijncanvas wanneer u data flow activiteiten hebt.

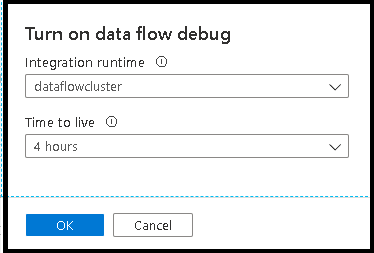
Zodra u de schuifregelaar hebt ingeschakeld, wordt u gevraagd om te selecteren welke integration runtime-configuratie u wilt gebruiken. Als AutoResolveIntegrationRuntime is gekozen, wordt een cluster met acht kernen van algemene rekenkracht met een standaard time-to-live van 60 minuten geactiveerd. Als u meer niet-actieve teams wilt toestaan voordat er een time-out optreedt voor uw sessie, kunt u een hogere TTL-instelling kiezen. Zie Integration Runtime prestaties voor meer informatie over dataflow-integratieruntimes.
Wanneer de foutopsporingsmodus is ingeschakeld, bouwt u interactief uw gegevensstroom met een actief Spark-cluster. De sessie wordt gesloten zodra u foutopsporing uitschakelt. U moet rekening houden met de uurkosten die door Data Factory worden gemaakt tijdens de tijd dat de foutopsporingssessie is ingeschakeld.
In de meeste gevallen is het een goed idee om uw gegevensstromen in de foutopsporingsmodus te bouwen, zodat u uw bedrijfslogica kunt valideren en uw gegevenstransformaties kunt bekijken voordat u uw werk publiceert. Gebruik de knop Foutopsporing in het pijplijnpaneel om uw gegevensstroom in een pijplijn te testen.
Notitie
Elke foutopsporingssessie die een gebruiker start vanuit de gebruikersinterface van de browser, is een nieuwe sessie met een eigen Spark-cluster. U kunt de bewakingsweergave gebruiken voor foutopsporingssessies die worden weergegeven in de vorige afbeeldingen om foutopsporingssessies weer te geven en te beheren. Er worden elk uur kosten in rekening gebracht voor elke foutopsporingssessie, inclusief de TTL-tijd.
In deze videoclip worden tips, trucs en goede procedures besproken voor de foutopsporingsmodus voor gegevensstromen.
Clusterstatus
De clusterstatusindicator boven aan het ontwerpoppervlak wordt groen wanneer het cluster klaar is voor foutopsporing. Als uw cluster al warm is, wordt de groene indicator bijna direct weergegeven. Als uw cluster nog niet draaide toen u de foutopsporingsmodus inging, voert het Spark-cluster een koude start uit. De indicator draait totdat de omgeving gereed is voor interactieve foutopsporing.
Wanneer u klaar bent met de foutopsporing, schakelt u de foutopsporingsschakelaar uit, zodat uw Spark-cluster kan worden beëindigd en er geen kosten meer in rekening worden gebracht voor foutopsporingsactiviteiten.
Instellingen voor foutopsporing
Zodra u de foutopsporingsmodus hebt ingeschakeld, kunt u bewerken hoe een gegevensstroom gegevens previewt. Foutopsporingsinstellingen kunnen worden bewerkt door te klikken op Instellingen voor foutopsporing op de werkbalk van het Data Flow canvas. U kunt hier de rijlimiet of bestandsbron selecteren die u wilt gebruiken voor elk van uw brontransformaties. De rijlimieten in deze instelling gelden alleen voor de huidige debugsessie. U kunt ook de gekoppelde faseringsservice selecteren die moet worden gebruikt voor een Azure Synapse Analytics bron.
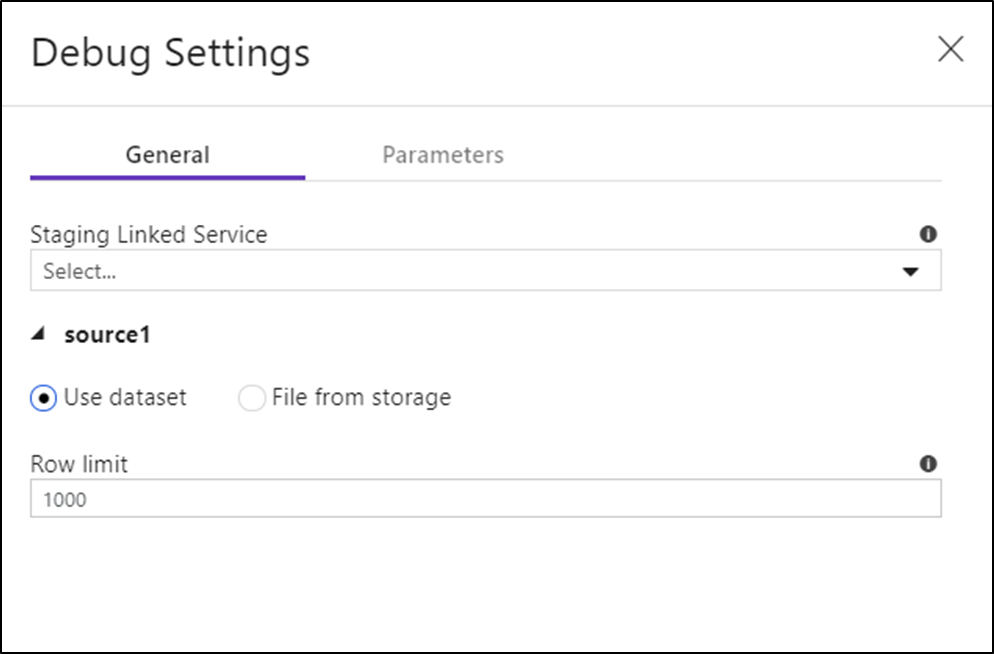
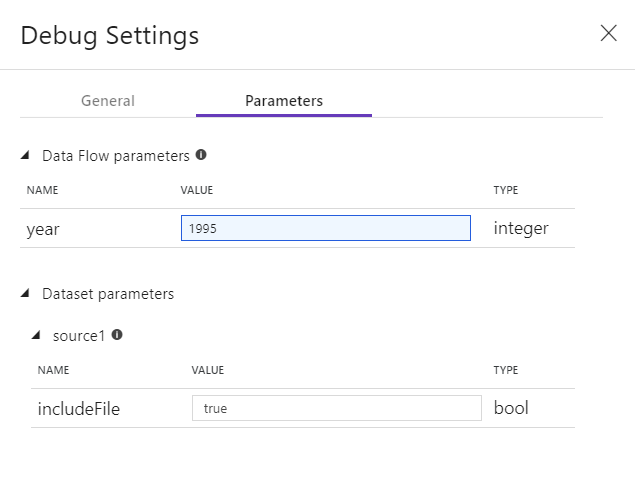
Als u parameters in uw Data Flow of een van de bijbehorende gegevenssets hebt, kunt u opgeven welke waarden u wilt gebruiken tijdens foutopsporing door het tabblad Parameters te selecteren.
Gebruik de voorbeeldinstellingen hier om te verwijzen naar voorbeeldbestanden of voorbeeldtabellen met gegevens, zodat u uw brongegevenssets niet hoeft te wijzigen. Door hier een voorbeeldbestand of tabel te gebruiken, kunt u dezelfde logica- en eigenschapsinstellingen in uw gegevensstroom onderhouden tijdens het testen op basis van een subset met gegevens.
De standaard-IR die wordt gebruikt voor de foutopsporingsmodus in gegevensstromen is een klein 4-core single worker-knooppunt met een 4-core knooppunt met één stuurprogramma. Dit werkt prima met kleinere voorbeelden van gegevens bij het testen van uw gegevensstroomlogica. Als u de rijlimieten in de foutopsporingsinstellingen tijdens gegevenspreview uitbreidt of een hoger aantal gesampleerde rijen in uw gegevensbron instelt tijdens pijplijnfoutopsporing, dan kunt u mogelijk overwegen om een grotere rekenomgeving te configureren in een nieuwe Azure Integration Runtime. Vervolgens kunt u de foutopsporingssessie opnieuw starten met behulp van de grotere rekenomgeving.
Voorbeeldweergave van gegevens
Als de foutopsporing is ingeschakeld, wordt het tabblad Gegevensvoorbeeld op het onderste deelvenster weergegeven. Als de foutopsporingsmodus niet is ingeschakeld, ziet Data Flow alleen de huidige metagegevens in en uit elk van uw transformaties op het tabblad Inspecteren. In het voorbeeld van de gegevens wordt alleen een query uitgevoerd op het aantal rijen dat u hebt ingesteld als uw limiet in de instellingen voor foutopsporing. Selecteer Vernieuwen om de voorbeeldweergave van gegevens bij te werken op basis van uw huidige transformaties. Als uw brongegevens zijn gewijzigd, selecteer dan Vernieuw > Opnieuw ophalen van bron.
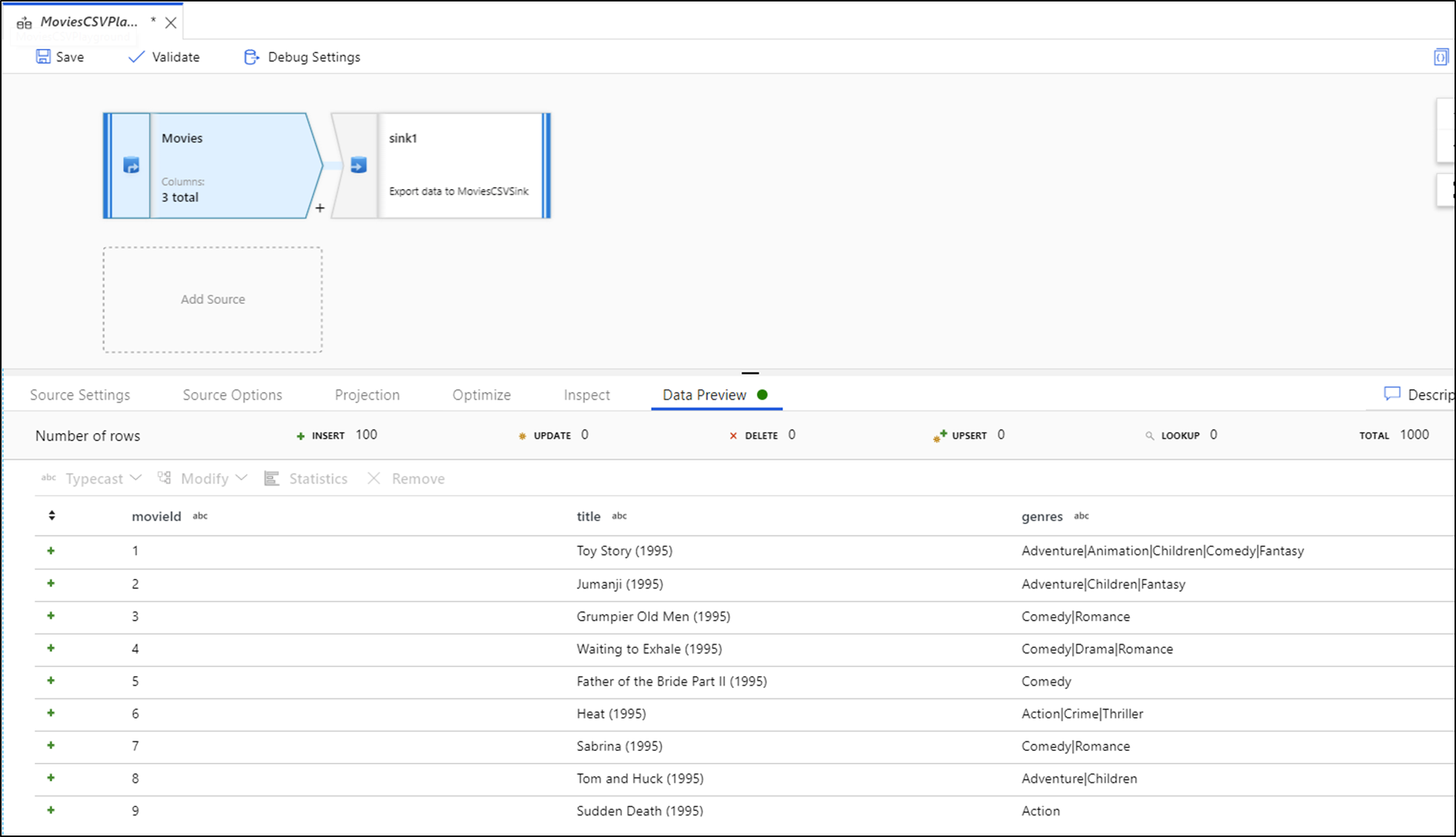
U kunt kolommen sorteren in het voorbeeld van gegevens en kolommen opnieuw rangschikpen met behulp van slepen en neerzetten. Bovendien bevindt zich boven aan het deelvenster Gegevensvoorbeeld een exportknop die u kunt gebruiken om de voorbeeldgegevens te exporteren naar een CSV-bestand voor offline gegevensverkenning. U kunt deze functie gebruiken om maximaal 1000 rijen met voorbeeldgegevens te exporteren.
Notitie
Bestandsbronnen beperken alleen de rijen die u ziet, niet de rijen die worden gelezen. Voor zeer grote gegevenssets is het raadzaam dat u een klein deel van dat bestand gebruikt om te testen. U kunt een tijdelijk bestand selecteren in Instellingen voor foutopsporing voor elke bron die een bestandstype is.
Wanneer u Data Flow uitvoert in de foutopsporingsmodus, worden uw gegevens niet naar de Sink-transformatie geschreven. Een foutopsporingssessie is bedoeld als testharnas voor uw transformaties. Sinks zijn niet vereist tijdens foutopsporing en worden genegeerd in uw gegevensstroom. Als u het schrijven van de gegevens in uw sink wilt testen, voert u de Data Flow vanuit een pijplijn uit en gebruikt u debug-uitvoering vanuit een pijplijn.
Data Preview is een momentopname van uw getransformeerde gegevens met behulp van rijlimieten en gegevenssampling van gegevensframes in Spark-geheugen. Daarom worden de sinkstuurprogramma's niet gebruikt of getest in dit scenario.
Notitie
Gegevensvoorbeeld geeft de tijd weer volgens de landinstelling van de browser.
Het testen van join-voorwaarden
Zorg ervoor dat u bij het testen van joins, exists of lookup-transformaties een kleine set bekende gegevens gebruikt. U kunt de optie Instellingen voor foutopsporing gebruiken die eerder is beschreven om een tijdelijk bestand in te stellen dat moet worden gebruikt voor uw tests. Dit is nodig omdat u bij het beperken of bemonsteren van rijen uit een grote gegevensset niet kunt voorspellen welke rijen en welke sleutels in de stroom worden gelezen om te testen. Het resultaat is niet-deterministisch, wat betekent dat uw joinvoorwaarden kunnen mislukken.
Snelle acties
Zodra u de voorbeeldweergave van gegevens ziet, kunt u een snelle transformatie genereren om een typecast te genereren, te verwijderen of een wijziging uit te voeren in een kolom. Selecteer de kolomkop en kies vervolgens een van de opties in de gegevensvoorbeeldwerkbalk.
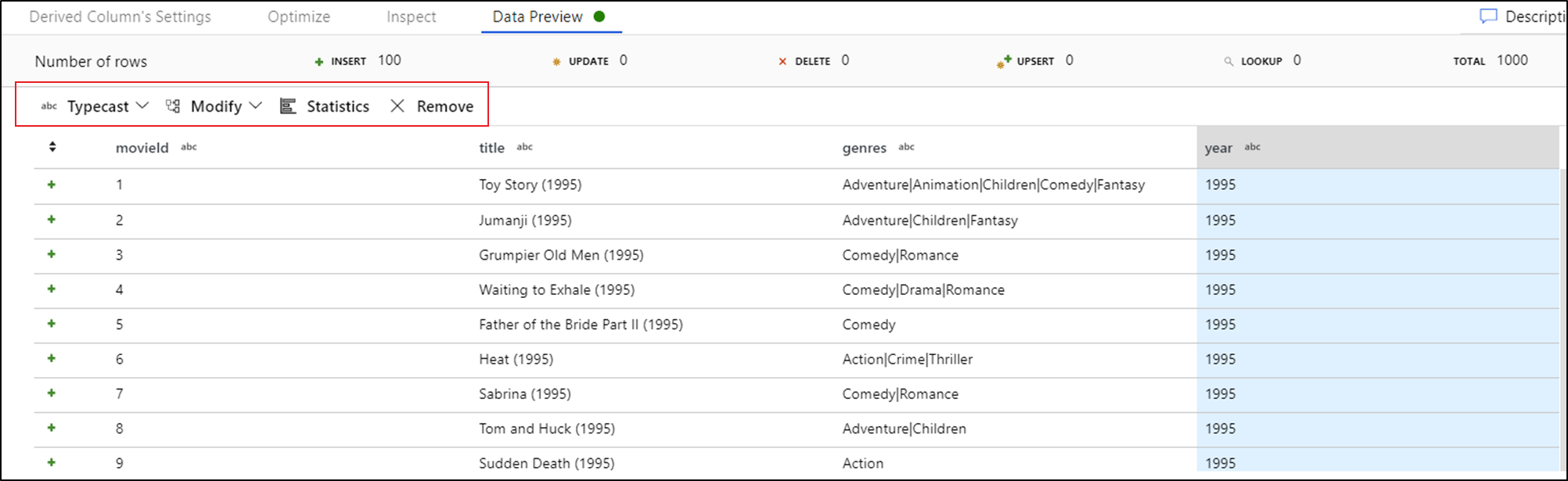
Zodra u een wijziging hebt geselecteerd, wordt het gegevensvoorbeeld onmiddellijk vernieuwd. Selecteer Bevestigen in de rechterbovenhoek om een nieuwe transformatie te genereren.
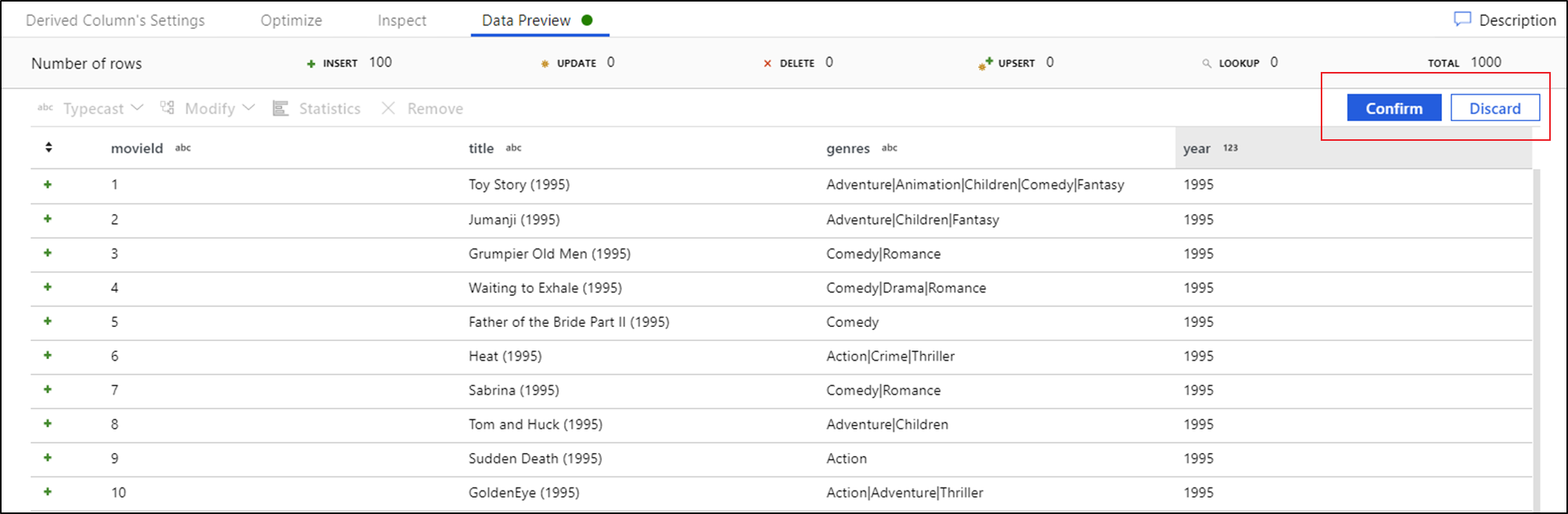
Typecast en Modify genereert een afgeleide kolomtransformatie en Remove genereert een select-transformatie.
Notitie
Als u uw Data Flow bewerkt, moet u de voorbeeldweergave van de gegevens opnieuw ophalen voordat u een snelle transformatie toevoegt.
Gegevensprofilering
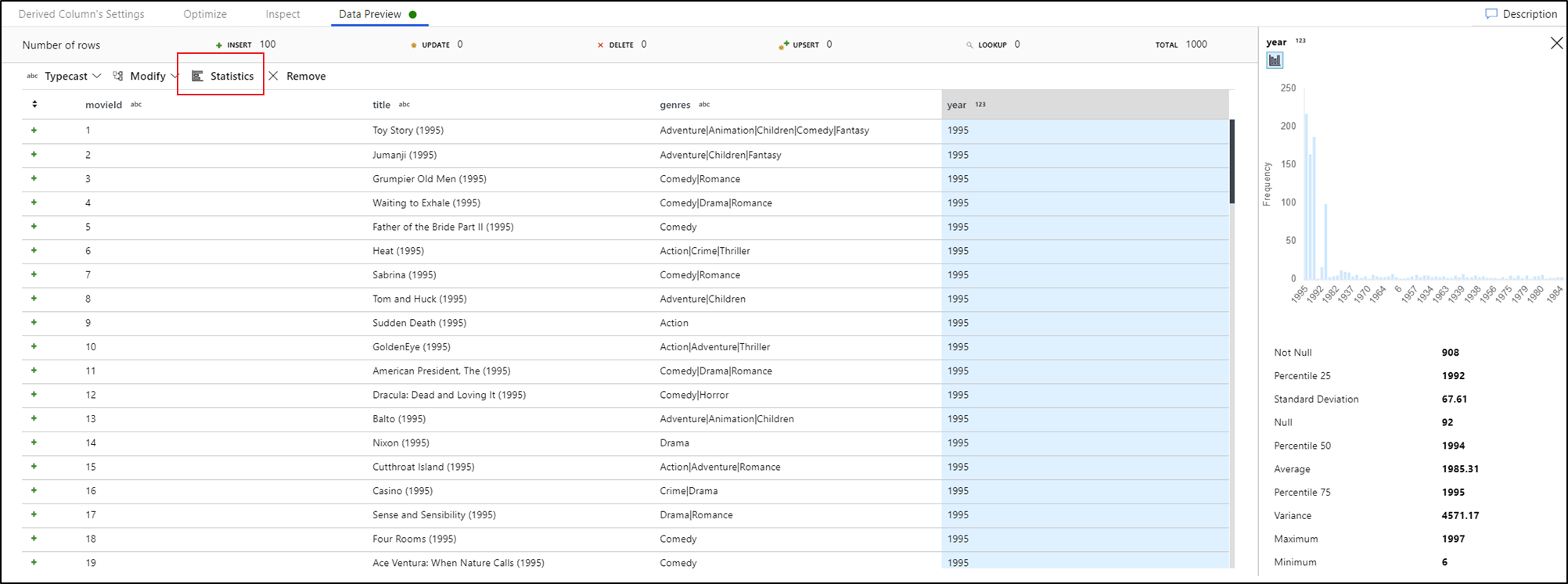
Als u een kolom selecteert op het tabblad Voorbeeld van gegevens en op Statistieken klikt in de werkbalk Gegevensvoorbeeld, wordt een grafiek uiterst rechts van het gegevensraster weergegeven met gedetailleerde statistieken over elk veld. De service maakt een bepaling op basis van de gegevenssampling van welk type grafiek moet worden weergegeven. Velden met hoge kardinaliteit hebben standaard de waarde NULL/NIET-NULL, terwijl categorische en numerieke gegevens met lage kardinaliteit worden weergegeven als staafdiagrammen die de frequentie van gegevenswaarden tonen. U ziet ook de maximale/lengte van tekenreeksen, minimum/maximumwaarden in numerieke velden, standaarddeviatie, percentielen, aantallen en gemiddelde.
Verwante inhoud
- Wanneer u klaar bent met het bouwen en debuggen van uw gegevensstroom, voert u deze uit vanuit een pijplijn.
- Wanneer u uw pijplijn test met een gegevensstroom, gebruikt u de Debug-runuitvoeringsoptie van de pijplijn.