Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Gebruik de Dataflow-activiteit om gegevens te transformeren en te verplaatsen via toewijzing van gegevensstromen. Zie Overzicht van Data Flow mapping als u nieuw bent in gegevensstromen.
Een Data Flow-activiteit maken met de gebruikersinterface
Voer de volgende stappen uit om een Data Flow activiteit in een pijplijn te gebruiken:
Zoek Data Flow in het deelvenster Pijplijnactiviteiten en sleep een Data Flow-activiteit naar het pijplijncanvas.
Selecteer de nieuwe Data Flow-activiteit op het canvas als deze nog niet is geselecteerd en het tabblad Settings om de details ervan te bewerken.
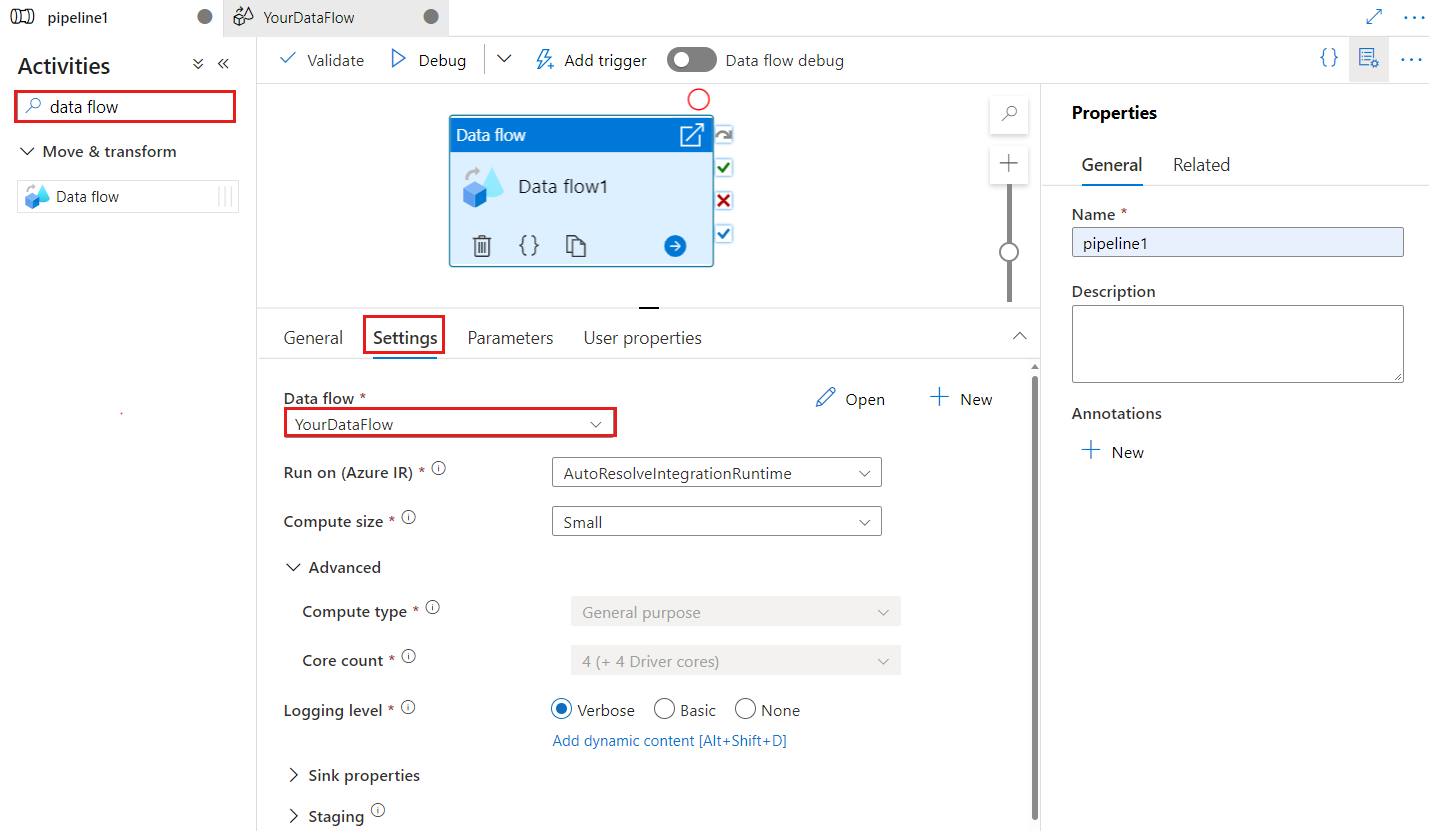
Controlepuntsleutel wordt gebruikt om het controlepunt in te stellen wanneer de gegevensstroom wordt gebruikt voor gewijzigde gegevensopname. U kunt het overschrijven. Gegevensstroomactiviteiten gebruiken een GUID-waarde als controlepuntsleutel in plaats van 'pijplijnnaam + activiteitsnaam' zodat de status van de wijzigingsgegevensopname van de klant altijd kan worden bijgehouden, zelfs als er naamgevingsacties zijn. Alle bestaande gegevensstroomactiviteiten maken gebruik van de oude patroonsleutel voor achterwaartse compatibiliteit. De controlepuntsleuteloptie na het publiceren van een nieuwe gegevensstroomactiviteit met een gegevensstroombron waarvoor change data capture is ingeschakeld, wordt als volgt weergegeven.
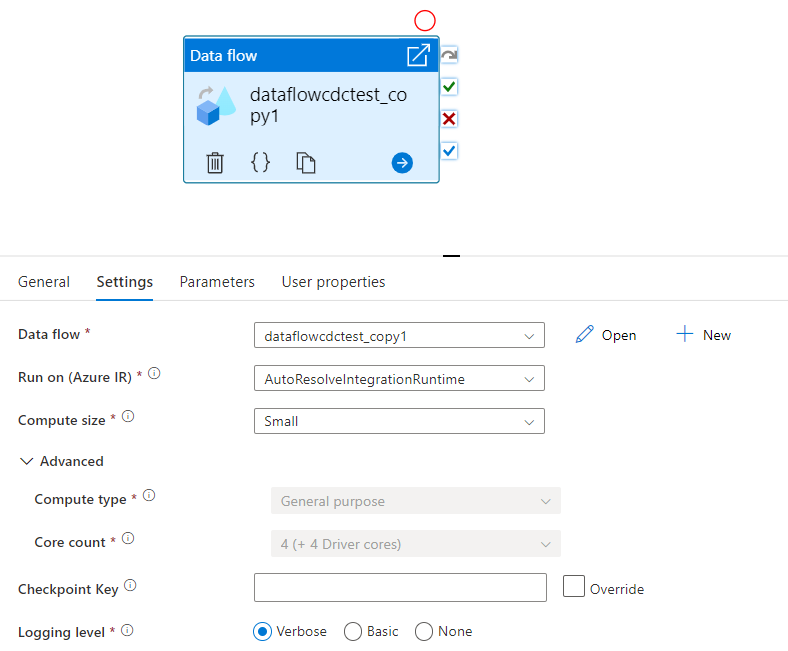
Selecteer een bestaande gegevensstroom of maak een nieuwe stroom met behulp van de knop Nieuw. Selecteer indien nodig andere opties om uw configuratie te voltooien.
Syntaxis
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Typeeigenschappen
| Eigenschap | Beschrijving | Toegestane waarden | Vereist |
|---|---|---|---|
| gegevensstroom | De verwijzing naar de Data Flow die wordt uitgevoerd | DataFlowReference | Ja |
| integrationRuntime | De rekenomgeving waarop de gegevensstroom wordt uitgevoerd. Als dit niet is opgegeven, wordt de autoresolve Azure Integration Runtime gebruikt. | IntegrationRuntimeReference | Nee |
| compute.coreCount | Het aantal kernen dat wordt gebruikt in het Spark-cluster. Kan alleen worden opgegeven als de autoresolve Azure Integration Runtime wordt gebruikt | 8, 16, 32, 48, 80, 144, 272 | Nee |
| compute.computeType | Het type rekenproces dat wordt gebruikt in het Spark-cluster. Kan alleen worden opgegeven als de autoresolve Azure Integration Runtime wordt gebruikt | "Algemeen" | Nee |
| staging.linkedService | Als u een Azure Synapse Analytics bron of sink gebruikt, geeft u het opslagaccount op dat wordt gebruikt voor PolyBase-fasering. Als uw Azure Storage is geconfigureerd met een VNet-service-eindpunt, moet u verificatie van beheerde identiteit gebruiken met 'Vertrouwde Microsoft-service toestaan' ingeschakeld voor het opslagaccount. Raadpleeg Impact van het gebruik van VNet-service-eindpunten met Azure storage. Leer ook de benodigde configuraties voor respectievelijk Azure Blob en Azure Data Lake Storage Gen2. |
LinkedServiceReference | Alleen als de gegevensstroom naar een Azure Synapse Analytics leest of schrijft |
| staging.folderPath | Als u een Azure Synapse Analytics bron of sink gebruikt, wordt het mappad in het blob-opslagaccount gebruikt voor PolyBase-fasering | String | Alleen als de gegevensstroom naar Azure Synapse Analytics leest of schrijft |
| traceLevel | Logboekregistratieniveau instellen van de uitvoering van uw gegevensstroomactiviteit | Fijn, Grof, Geen | Nee |
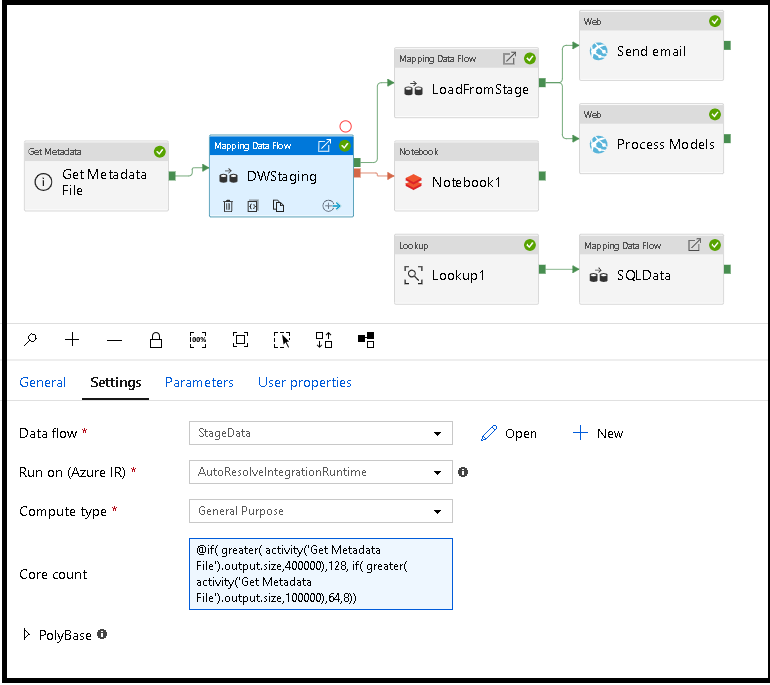
Rekenkracht van gegevensstromen dynamisch aanpassen tijdens runtime
De eigenschappen Kernaantal en Rekentype kunnen dynamisch worden ingesteld om de grootte van uw binnenkomende brongegevens tijdens runtime aan te passen. Gebruik pijplijnactiviteiten zoals Opzoeken of Metagegevens ophalen om de grootte van de brongegevenssetgegevens te vinden. Gebruik vervolgens Dynamische inhoud toevoegen in de eigenschappen van de Data Flow activiteit. U kunt kiezen voor kleine, middelgrote of grote rekenkracht. Kies desgewenst 'Aangepast' en configureer de rekentypen en het aantal kernen handmatig.
Hier volgt een korte videozelfstudie waarin deze techniek wordt uitgelegd
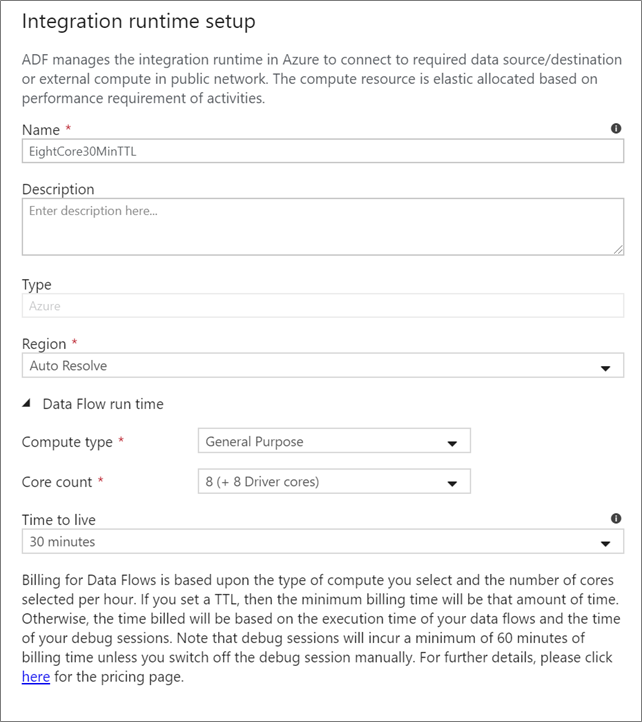
Dataflow-integratieruntime
Kies welke Integration Runtime u wilt gebruiken voor de uitvoering van uw Data Flow activiteit. De service maakt standaard gebruik van de autoresolve Azure Integration Runtime met vier werkkernen. Deze IR heeft een rekentype voor algemeen gebruik en wordt uitgevoerd in dezelfde regio als uw service-exemplaar. Voor operationele pijplijnen wordt u ten zeerste aangeraden uw eigen Azure Integration Runtimes te maken die specifieke regio's, rekentype, kernaantallen en TTL definiëren voor de uitvoering van de gegevensstroomactiviteit.
Een minimaal rekentype algemeen gebruik met een configuratie van 8+8 (16 totale v-cores) en een time-to-live (TTL) van 10 minuten is de minimale aanbeveling voor de meeste productieworkloads. Door een kleine TTL in te stellen, kan de Azure IR een warm cluster behouden, waardoor de opstartvertraging van enkele minuten voor een koud cluster wordt vermeden. Zie Azure Integration Runtime voor meer informatie.
Belangrijk
De Integration Runtime selectie in de Data Flow-activiteit is alleen van toepassing op triggered uitvoeringen van uw pijplijn. Foutopsporing in uw pijplijn met gegevensstromen wordt uitgevoerd op het cluster dat is opgegeven in de foutopsporingssessie.
PolyBase
Als u een Azure Synapse Analytics als sink of bron gebruikt, moet u een faseringslocatie voor uw PolyBase-batchbelasting kiezen. PolyBase maakt het bulksgewijs laden van batches mogelijk in plaats van de gegevensrij per rij te laden. PolyBase vermindert de laadtijd drastisch in Azure Synapse Analytics.
Controlepuntsleutel
Wanneer u de optie voor het vastleggen van wijzigingen gebruikt voor gegevensstroombronnen, onderhoudt en beheert ADF het controlepunt automatisch voor u. De standaardcontrolepuntsleutel is een hash van de naam van de gegevensstroom en de naam van de pijplijn. Als u een dynamisch patroon gebruikt voor uw brontabellen of -mappen, kunt u deze hash overschrijven en hier uw eigen controlepuntsleutelwaarde instellen.
Niveau van logboekregistratie
Als u niet elke pijplijnuitvoering van uw gegevensstroomactiviteiten nodig hebt om alle uitgebreide telemetrielogboeken volledig te registreren, kunt u eventueel het logboekregistratieniveau instellen op Basis of Geen. Wanneer u uw gegevensstromen uitvoert in de modus Uitgebreid (standaard), vraagt u de service om activiteiten op elk afzonderlijk partitieniveau volledig te registreren tijdens uw gegevenstransformatie. Dit kan een dure bewerking zijn, dus alleen gedetailleerde logging inschakelen bij het oplossen van problemen kan de algehele prestaties van uw gegevensstroom en pijplijnen verbeteren. In de basismodus worden alleen de duur van de transformaties vastgelegd, terwijl 'Geen' alleen een samenvatting van de duur biedt.

Sink-eigenschappen
Met de groeperingsfunctie in gegevensstromen kunt u zowel de volgorde van de uitvoering van uw sinks instellen als sinks groeperen met hetzelfde groepsnummer. Als u groepen wilt beheren, kunt u de service vragen om taken in dezelfde groep parallel uit te voeren. U kunt ook instellen dat de sinkgroep zelfs wordt voortgezet nadat een van de afvoeren een fout ondervindt.
Het standaardgedrag van gegevensstroomsinks is het sequentieel uitvoeren van elke sink, op een seriële manier en het mislukken van de gegevensstroom wanneer er een fout optreedt in de sink. Bovendien worden alle sinks standaard ingesteld op dezelfde groep, tenzij u naar de eigenschappen van de gegevensstroom gaat en verschillende prioriteiten voor de sinks instelt.

Alleen eerste rij
Deze optie is alleen beschikbaar voor gegevensstromen waarvoor cache-sinks zijn ingeschakeld voor uitvoer naar activiteit. De uitvoer van de gegevensstroom die rechtstreeks in uw pijplijn wordt geïnjecteerd, is beperkt tot 2 MB. Als u 'alleen de eerste rij' instelt, kunt u de data-uitvoer van de gegevensstroom beperken wanneer u de uitvoer van de gegevensstroomactiviteit rechtstreeks in uw pijplijn injecteert.
Parameteriseren van Gegevensstroom s
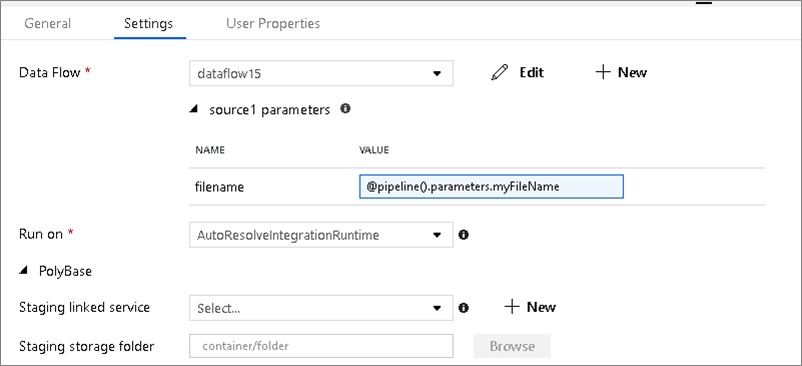
Geparameteriseerde gegevenssets
Als uw gegevensstroom geparameteriseerde gegevenssets gebruikt, stelt u de parameterwaarden in op het tabblad Instellingen .
Geparameteriseerde gegevensstromen
Als uw gegevensstroom is geparameteriseerd, stelt u de dynamische waarden van de gegevensstroomparameters in op het tabblad Parameters . U kunt de taal van de pijplijnexpressie of de expressietaal voor de gegevensstroom gebruiken om dynamische of letterlijke parameterwaarden toe te wijzen. Zie Data Flow Parameters voor meer informatie.
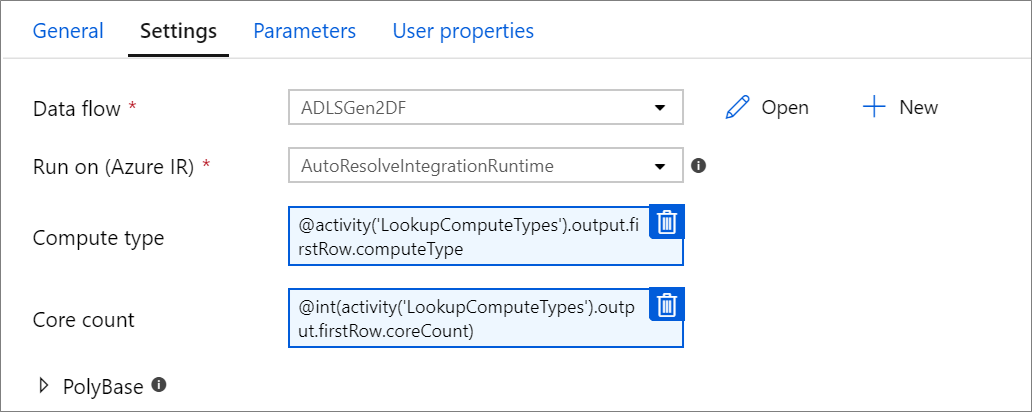
Geparameteriseerde rekeneigenschappen.
U kunt het aantal kernen of rekentypen parameteriseren als u de autoresolve Azure Integration Runtime gebruikt en waarden opgeeft voor compute.coreCount en compute.computeType.
Pijplijnopsporing van Data Flow-activiteit
Als u een foutopsporingspijplijnuitvoering wilt uitvoeren met een Data Flow activiteit, moet u de foutopsporingsmodus in data flow schakelen via de schuifregelaar Data Flow Debug op de bovenste balk. De debugmodus geeft u de mogelijkheid om de gegevensstroom op een actief Spark-cluster uit te voeren. Zie De foutopsporingsmodus voor meer informatie.

De foutopsporingspijplijn wordt uitgevoerd op het actieve foutopsporingscluster, niet op de integratieruntime-omgeving die is opgegeven in de Data Flow activiteitsinstellingen. U kunt de foutopsporingsomgeving kiezen bij het starten van de foutopsporingsmodus.
De Data Flow-activiteit bewaken
De Data Flow-activiteit heeft een speciale bewakingservaring waar u gegevens over partitionering, fasetijd en gegevensherkomst kunt bekijken. Open het bewakingsvenster via het brilpictogram onder Acties. Voor meer informatie, zie Gegevensstromen Monitoren.
Gebruik Data Flow activiteitsresultaten in een volgende activiteit
De gegevensstroomactiviteit levert metrische gegevens over het aantal rijen dat naar elke sink is geschreven en rijen die uit elke bron worden gelezen. Deze resultaten worden geretourneerd in de output sectie van het resultaat van de activiteitsuitvoering. De geretourneerde metrische gegevens hebben de indeling van de onderstaande json.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Als u bijvoorbeeld het aantal rijen wilt ophalen dat naar een sink is geschreven met de naam 'sink1' in een activiteit met de naam 'dataflowActivity', gebruikt u @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Als u het aantal rijen wilt ophalen dat wordt gelezen uit een bron met de naam 'source1' die in die sink is gebruikt, gebruikt u @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Notitie
Als een sink nul rijen heeft geschreven, wordt deze niet weergegeven in de metrics. Bestaan kan worden geverifieerd met behulp van de contains functie. Controleert bijvoorbeeld contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') of er rijen naar sink1 zijn geschreven.
Gerelateerde inhoud
Bekijk ondersteunde controlestroomactiviteiten: