Schemadrift in toewijzingsgegevensstroom
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Schemadrift is het geval wanneer uw bronnen vaak metagegevens wijzigen. Velden, kolommen en typen kunnen snel worden toegevoegd, verwijderd of gewijzigd. Zonder afhandeling voor schemadrift wordt uw gegevensstroom kwetsbaar voor wijzigingen in de upstream-gegevensbron. Typische ETL-patronen mislukken wanneer binnenkomende kolommen en velden veranderen, omdat ze meestal zijn gekoppeld aan die bronnamen.
Als u zich wilt beschermen tegen schemadrift, is het belangrijk dat u over de faciliteiten beschikt in een hulpprogramma voor gegevensstromen, zodat u, als Data-engineer, het volgende kunt doen:
- Bronnen definiëren met onveranderbare veldnamen, gegevenstypen, waarden en grootten
- Transformatieparameters definiëren die kunnen werken met gegevenspatronen in plaats van in vastgelegde velden en waarden
- Expressies definiëren die inzicht krijgen in patronen die overeenkomen met binnenkomende velden, in plaats van benoemde velden te gebruiken
Azure Data Factory biedt systeemeigen ondersteuning voor flexibele schema's die veranderen van uitvoering in uitvoering, zodat u algemene logica voor gegevenstransformatie kunt bouwen zonder dat u uw gegevensstromen opnieuw hoeft te compileren.
U moet een architectuurbeslissing nemen in uw gegevensstroom om schemadrift in uw stroom te accepteren. Wanneer u dit doet, kunt u zich beschermen tegen schemawijzigingen van de bronnen. U verliest echter vroege binding van uw kolommen en typen in uw gegevensstroom. Azure Data Factory behandelt schemadriftstromen als laatbindingsstromen, dus wanneer u uw transformaties bouwt, zijn de namen van de gedrifte kolommen niet beschikbaar in de schemaweergaven in de hele stroom.
Deze video biedt een inleiding tot enkele van de complexe oplossingen die u eenvoudig kunt bouwen in Azure Data Factory- of Synapse Analytics-pijplijnen met de schemadriftfunctie van de gegevensstroom. In dit voorbeeld bouwen we herbruikbare patronen op basis van flexibele databaseschema's:
Schemadrift in bron
Kolommen die afkomstig zijn van uw gegevensstroom vanuit uw brondefinitie, worden gedefinieerd als 'drift' wanneer ze niet aanwezig zijn in uw bronprojectie. U kunt de bronprojectie bekijken op het tabblad Projectie in de brontransformatie. Wanneer u een gegevensset voor uw bron selecteert, neemt de service automatisch het schema uit de gegevensset en maakt u een projectie op basis van die definitie van het gegevenssetschema.
In een brontransformatie wordt schemadrift gedefinieerd als leeskolommen die niet zijn gedefinieerd in uw gegevenssetschema. Als u schemadrift wilt inschakelen, schakelt u schemadrift toestaan in uw brontransformatie in.
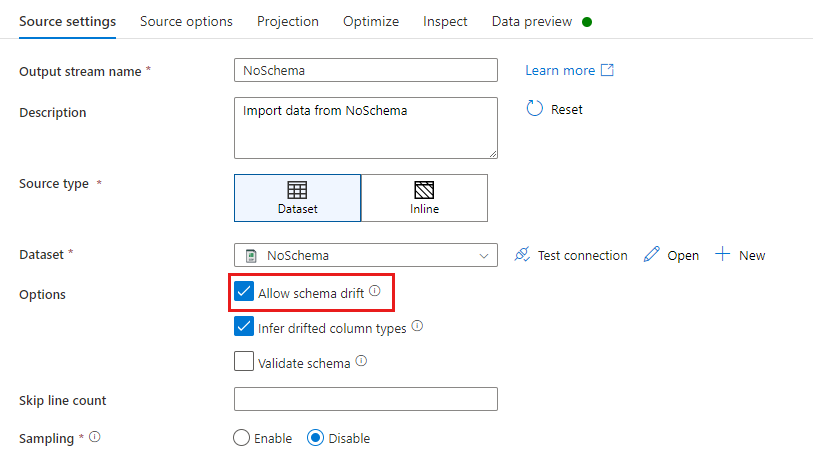
Wanneer schemadrift is ingeschakeld, worden alle binnenkomende velden tijdens de uitvoering gelezen uit uw bron en doorgegeven aan de gehele stroom naar de sink. Standaard komen alle nieuw gedetecteerde kolommen, ook wel gedrifte kolommen genoemd, binnen als een gegevenstype tekenreeks. Als u wilt dat de gegevensstroom automatisch gegevenstypen van gedrifte kolommen afdrijft, controleert u in de broninstellingen de afdrijvende kolomtypen .
Schemadrift in sink
Bij een sinktransformatie schrijft u extra kolommen boven op wat is gedefinieerd in het sinkgegevensschema. Als u schemadrift wilt inschakelen, schakelt u schemadrift in uw sinktransformatie toestaan in.
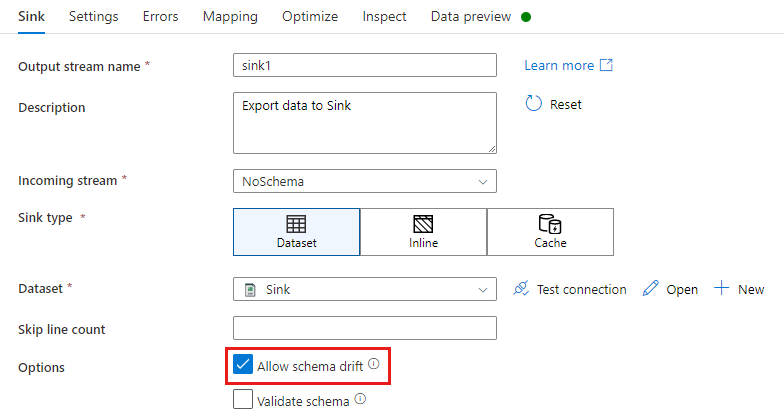
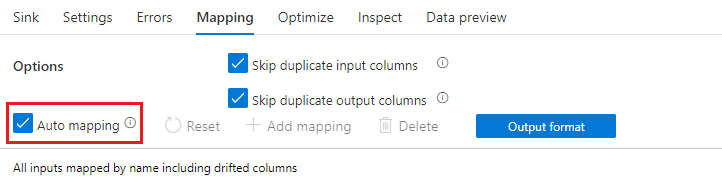
Als schemadrift is ingeschakeld, controleert u of de schuifregelaar voor automatisch toewijzen op het tabblad Toewijzing is ingeschakeld. Als deze schuifregelaar is ingeschakeld, worden alle binnenkomende kolommen naar uw bestemming geschreven. Anders moet u toewijzing op basis van regels gebruiken om gedrifte kolommen te schrijven.
Gedrifte kolommen transformeren
Wanneer uw gegevensstroom kolommen heeft gedrift, kunt u deze openen in uw transformaties met de volgende methoden:
- Gebruik de
byPositionenbyNameexpressies om expliciet te verwijzen naar een kolom op naam of positienummer. - Een kolompatroon toevoegen in een afgeleide kolom of aggregatietransformatie die overeenkomt met elke combinatie van naam, stroom, positie, oorsprong of type
- Op regels gebaseerde toewijzing toevoegen in een Select- of Sink-transformatie om gedrifte kolommen te koppelen aan kolommenaliassen via een patroon
Zie Kolompatronen in de toewijzingsgegevensstroom voor meer informatie over het implementeren van kolompatronen.
Snelle actie voor gedrifte kolommen toewijzen
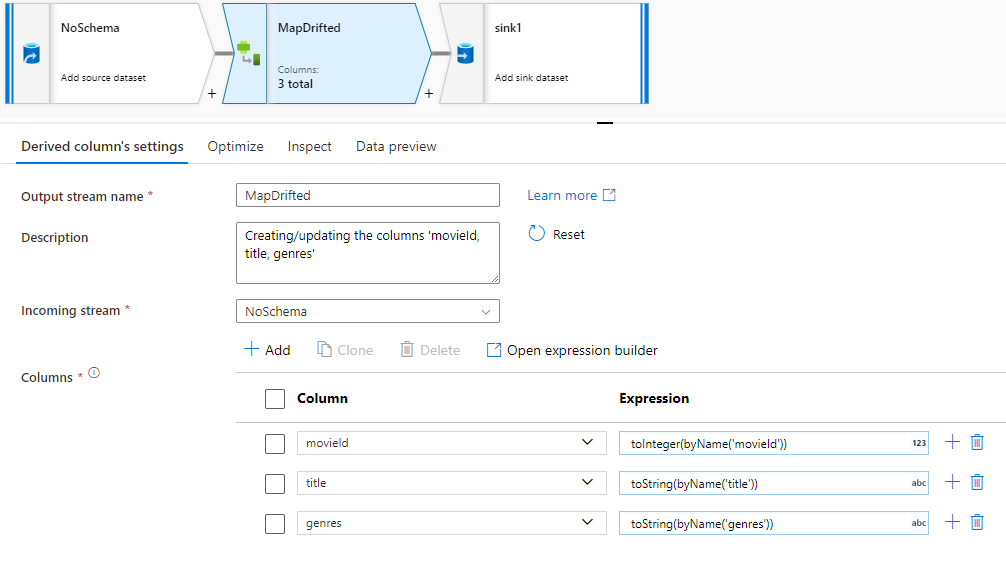
Als u expliciet naar gedrifte kolommen wilt verwijzen, kunt u snel toewijzingen voor deze kolommen genereren via een snelle actie voor gegevensvoorbeelden. Zodra de foutopsporingsmodus is ingeschakeld, gaat u naar het tabblad Gegevensvoorbeeld en klikt u op Vernieuwen om een voorbeeld van gegevens op te halen. Als data factory detecteert dat er gedrifte kolommen bestaan, kunt u op Map Drifted klikken en een afgeleide kolom genereren waarmee u kunt verwijzen naar alle gedrifte kolommen in schemaweergaven downstream.
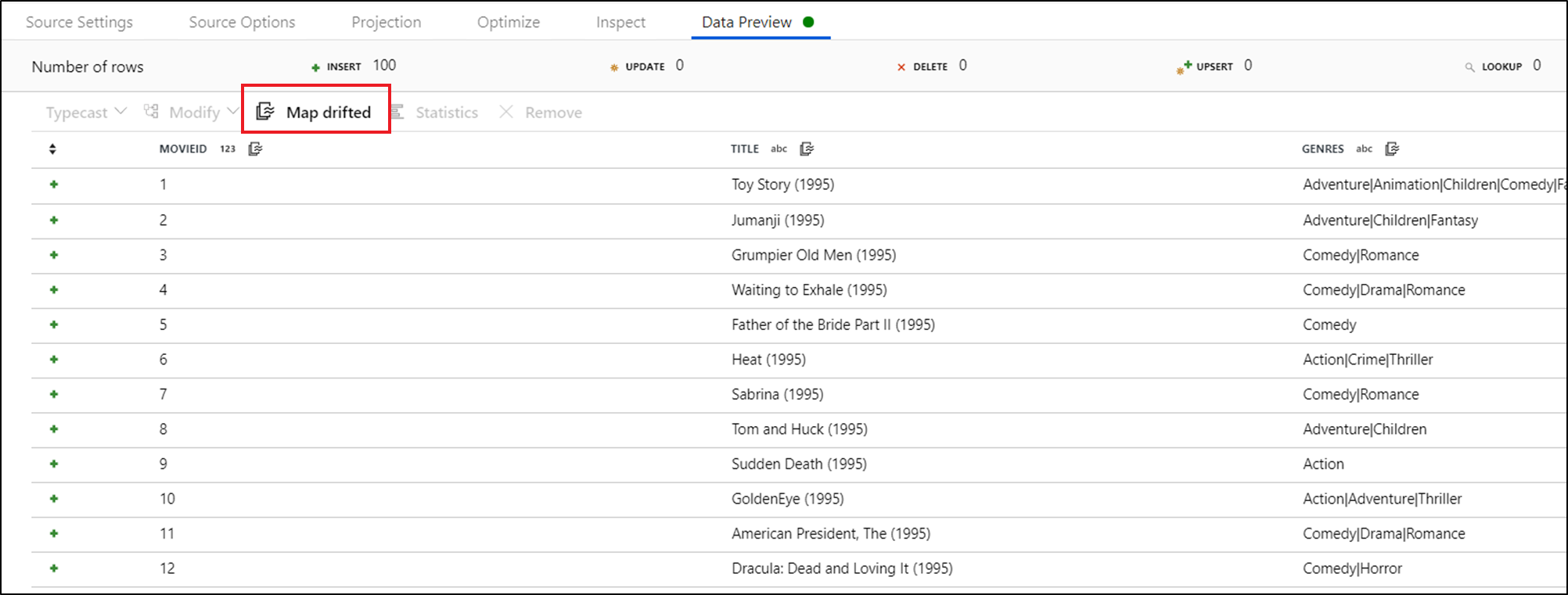
In de gegenereerde transformatie van afgeleide kolommen wordt elke gedrifte kolom toegewezen aan de gedetecteerde naam en het gegevenstype. In het bovenstaande gegevensvoorbeeld wordt de kolom 'movieId' gedetecteerd als een geheel getal. Nadat op Map Drifted is geklikt, wordt movieId gedefinieerd in de afgeleide kolom als toInteger(byName('movieId')) en opgenomen in schemaweergaven in downstreamtransformaties.
Gerelateerde inhoud
In de Gegevensstroom Expressietaal vindt u extra faciliteiten voor kolompatronen en schemadrift, waaronder 'byName' en 'byPosition'.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor