Continue integratie en levering in Azure Data Factory
VAN TOEPASSING OP:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Continue integratie is de praktijk van het automatisch en zo vroeg mogelijk testen van elke wijziging in uw codebase. Continue levering volgt de tests die tijdens continue integratie worden uitgevoerd en pusht wijzigingen naar een faserings- of productiesysteem.
In Azure Data Factory wordt onder continue integratie en levering (CI/CD) de mogelijkheid verstaan dat Data Factory-pijplijnen van de ene omgeving (ontwikkeling, test, productie) naar de andere worden verplaatst. Azure Data Factory maakt gebruik van Azure Resource Manager-sjablonen voor het opslaan van de configuratie van uw verschillende ADF-entiteiten (pijplijnen, gegevenssets, gegevensstromen, enzovoort). Er zijn twee voorgestelde methoden om een data factory te promoveren naar een andere omgeving:
- Geautomatiseerde implementatie met behulp van de integratie van Data Factory met Azure Pipelines
- Upload handmatig een Resource Manager-sjabloon met behulp van Data Factory UX-integratie met Azure Resource Manager.
Notitie
Het wordt aanbevolen de Azure Az PowerShell-module te gebruiken om te communiceren met Azure. Zie Azure PowerShell installeren om aan de slag te gaan. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
CI/CD-levenscyclus
Notitie
Zie Verbeteringen voor continue implementatie voor meer informatie.
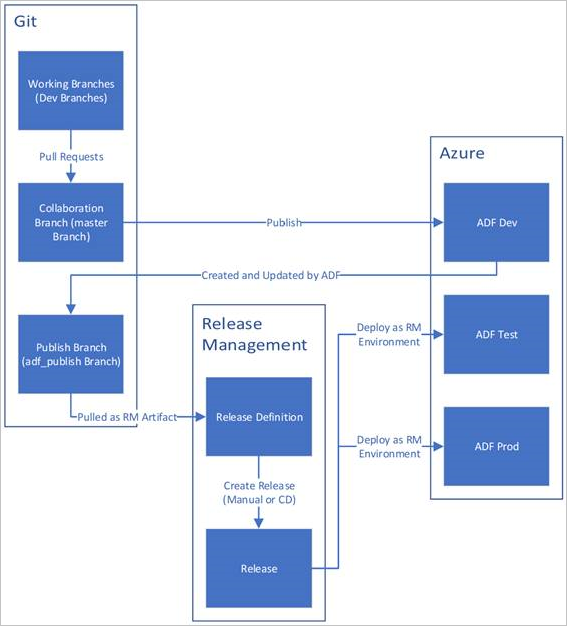
Hieronder ziet u een voorbeeldoverzicht van de CI/CD-levenscyclus in een Azure-gegevensfactory die is geconfigureerd met Azure Repos Git. Zie Broncodebeheer in Azure Data Factory voor meer informatie over het configureren van een Git-opslagplaats.
Er wordt een ontwikkelingsdata factory gemaakt en geconfigureerd met Azure Repos Git. Alle ontwikkelaars moeten gemachtigd zijn om Data Factory-resources te ontwerpen, zoals pijplijnen en gegevenssets.
Een ontwikkelaar maakt een functiebranch om een wijziging aan te brengen. Ze opsporen fouten in hun pijplijnuitvoeringen met de meest recente wijzigingen. Zie Iteratieve ontwikkeling en foutopsporing met Azure Data Factory voor meer informatie over het opsporen van fouten in een pijplijnuitvoering.
Nadat een ontwikkelaar tevreden is met de wijzigingen, maakt hij een pull-aanvraag van de functiebranch naar de hoofd- of samenwerkingsbranch om de wijzigingen door collega's te laten beoordelen.
Nadat een pull-aanvraag is goedgekeurd en wijzigingen zijn samengevoegd in de hoofdbranch, worden de wijzigingen gepubliceerd naar de ontwikkelingsfactory.
Wanneer het team klaar is om de wijzigingen in een test- of UAT-factory (User Acceptance Testing) te implementeren, gaat het team naar de release van Azure Pipelines en implementeert het de gewenste versie van de ontwikkelingsfactory in UAT. Deze implementatie vindt plaats als onderdeel van een Azure Pipelines-taak en gebruikt Resource Manager-sjabloonparameters om de juiste configuratie toe te passen.
Nadat de wijzigingen in de testfactory zijn geverifieerd, implementeert u deze in de productiefactory met behulp van de volgende taak van de release van de pijplijnen.
Notitie
Alleen de ontwikkelingsfactory is gekoppeld aan een Git-opslagplaats. Aan de test- en productiefabrieken mag geen Git-opslagplaats zijn gekoppeld en moet alleen worden bijgewerkt via een Azure DevOps-pijplijn of via een Resource Management-sjabloon.
In de onderstaande afbeelding ziet u de verschillende stappen van deze levenscyclus.
Best practices voor CI/CD
Als u Git-integratie met uw data factory gebruikt en een CI/CD-pijplijn hebt waarmee uw wijzigingen van de ontwikkeling naar de test worden verplaatst en vervolgens naar productie, raden we deze aanbevolen procedures aan:
Git-integratie. Configureer alleen uw ontwikkelingsdata factory met Git-integratie. Wijzigingen in testen en productie worden geïmplementeerd via CI/CD en hebben geen Git-integratie nodig.
Script vóór en na de implementatie. Voordat de Resource Manager-implementatiestap in CI/CD wordt uitgevoerd, moet u bepaalde taken uitvoeren, zoals het stoppen en opnieuw starten van triggers en het uitvoeren van opschonen. U wordt aangeraden PowerShell-scripts vóór en na de implementatietaak te gebruiken. Zie Actieve triggers bijwerken voor meer informatie. Het data factory-team heeft een script opgegeven dat onder aan deze pagina kan worden gebruikt.
Notitie
Gebruik PrePostDeploymentScript.Ver2.ps1 als u alleen de triggers wilt uitschakelen of inschakelen die zijn gewijzigd in plaats van alle triggers uit of in te schakelen tijdens CI/CD.
Waarschuwing
Zorg ervoor dat u PowerShell Core in ADO-taak gebruikt om het script uit te voeren.
Waarschuwing
Als u geen gebruik maakt van de nieuwste versies van de Module PowerShell en Data Factory, kunnen er fouten optreden bij het deserialisatiegebruik tijdens het uitvoeren van de opdrachten.
Integratieruntimes en delen. Integratieruntimes veranderen niet vaak en zijn vergelijkbaar in alle fasen in uw CI/CD. Data Factory verwacht dus dat u dezelfde naam, hetzelfde type en subtype integratieruntime hebt in alle fasen van CI/CD. Als u integratieruntimes in alle fasen wilt delen, kunt u overwegen om een ternaire factory te gebruiken om alleen de gedeelde integratieruntimes te bevatten. U kunt deze gedeelde factory in al uw omgevingen gebruiken als een gekoppeld type Integration Runtime.
Notitie
De integratieruntime delen is alleen beschikbaar voor zelf-hostende Integration Runtimes. Azure-SSIS Integration Runtimes bieden geen ondersteuning voor delen.
Beheerde privé-eindpuntimplementatie. Als er al een privé-eindpunt bestaat in een factory en u probeert een ARM-sjabloon te implementeren die een privé-eindpunt met dezelfde naam maar met gewijzigde eigenschappen bevat, mislukt de implementatie. Met andere woorden, u kunt een privé-eindpunt implementeren zolang het dezelfde eigenschappen heeft als het eindpunt dat al in de fabriek bestaat. Als een eigenschap verschilt tussen omgevingen, kunt u deze overschrijven door die eigenschap te parameteriseren en de betreffende waarde op te geven tijdens de implementatie.
Key Vault. Wanneer u gekoppelde services gebruikt waarvan de verbindingsgegevens zijn opgeslagen in Azure Key Vault, wordt u aangeraden afzonderlijke sleutelkluizen voor verschillende omgevingen te bewaren. U kunt ook afzonderlijke machtigingsniveaus configureren voor elke sleutelkluis. U wilt bijvoorbeeld niet dat uw teamleden machtigingen hebben voor productiegeheimen. Als u deze aanpak volgt, raden we u aan om dezelfde geheime namen in alle fasen te bewaren. Als u dezelfde geheime namen bewaart, hoeft u niet elke verbindingsreeks te parameteriseren in CI/CD-omgevingen, omdat het enige dat verandert de naam van de sleutelkluis is. Dit is een afzonderlijke parameter.
Naamgeving van resources. Vanwege arm-sjabloonbeperkingen kunnen er problemen in de implementatie optreden als uw resources spaties in de naam bevatten. Het Azure Data Factory-team raadt aan om tekens '_' of '-' te gebruiken in plaats van spaties voor resources. 'Pipeline_1' is bijvoorbeeld een voorkeursnaam boven 'Pijplijn 1'.
Opslagplaats wijzigen. ADF beheert inhoud van git-opslagplaatsen automatisch. Als u handmatig niet-gerelateerde bestanden of mappen wijzigt of toevoegt aan een willekeurige locatie in de gegevensmap van de Git-opslagplaats in ADF, kan dit leiden tot fouten bij het laden van resources. De aanwezigheid van .bak bestanden kan bijvoorbeeld een ADF CI/CD-fout veroorzaken, zodat deze moeten worden verwijderd om ADF te laden.
Belichtingsbeheer en functievlagmen. Wanneer u in een team werkt, zijn er exemplaren waarin u wijzigingen kunt samenvoegen, maar ze niet in verhoogde omgevingen zoals PROD en QA willen uitvoeren. Om dit scenario af te handelen, raadt het ADF-team het DevOps-concept aan om functievlagmen te gebruiken. In ADF kunt u globale parameters combineren en de if-voorwaardeactiviteit om sets logica te verbergen op basis van deze omgevingsvlagmen.
Zie de onderstaande videozelfstudie voor meer informatie over het instellen van een functievlag:
Niet-ondersteunde functies
Data Factory staat standaard het kiezen van doorvoeringen of selectief publiceren van resources niet toe. Publiceren bevatten alle wijzigingen die zijn aangebracht in de data factory.
- Data Factory-entiteiten zijn afhankelijk van elkaar. Triggers zijn bijvoorbeeld afhankelijk van pijplijnen en pijplijnen zijn afhankelijk van gegevenssets en andere pijplijnen. Selectief publiceren van een subset van resources kan leiden tot onverwacht gedrag en fouten.
- In zeldzame gevallen waarin u selectief publiceren nodig hebt, kunt u overwegen een hotfix te gebruiken. Zie Hotfix-productieomgeving voor meer informatie.
Het Azure Data Factory-team raadt niet aan om Azure RBAC-besturingselementen toe te wijzen aan afzonderlijke entiteiten (pijplijnen, gegevenssets, enzovoort) in een data factory. Als een ontwikkelaar bijvoorbeeld toegang heeft tot een pijplijn of gegevensset, heeft deze toegang tot alle pijplijnen en gegevenssets in de data factory. Als u denkt dat u veel Azure-rollen binnen een data factory moet implementeren, bekijkt u het implementeren van een tweede data factory.
U kunt niet publiceren vanuit privévertakkingen.
U kunt momenteel geen projecten hosten in Bitbucket.
U kunt momenteel geen waarschuwingen en matrices exporteren en importeren als parameters.
Gedeeltelijke ARM-sjablonen in uw publicatiebranch worden vanaf 1 november 2021 niet meer ondersteund. Als uw project gebruikmaakt van deze functie, schakelt u over naar een ondersteund mechanisme voor implementaties met behulp van:
ARMTemplateForFactory.jsonoflinkedTemplatesbestanden.
Gerelateerde inhoud
- Verbeteringen voor continue implementatie
- Continue integratie automatiseren met Azure Pipelines-versies
- Een Resource Manager-sjabloon handmatig promoveren naar elke omgeving
- Aangepaste parameters gebruiken met een Resource Manager-sjabloon
- Gekoppelde Resource Manager-sjablonen
- Een hotfix-productieomgeving gebruiken
- Voorbeeldscript vóór en na implementatie