Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Gegevensstromen zijn beschikbaar in zowel Azure Data Factory pijplijnen als Azure Synapse Analytics pijplijnen. Dit artikel is van toepassing op het in kaart brengen van datastromen. Als u nieuw bent met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van mapping-dataflows.
Tip
Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory, de volgende generatie van Azure Data Factory. De venstertransformatie wordt momenteel niet ondersteund in Dataflow Gen2. Zie Een handleiding voor Dataflow Gen2 voor mapping van gegevensstroomgebruikers voor een lijst met ondersteunde transformaties en hun equivalenten.
In de venstertransformatie definieert u op vensters gebaseerde aggregaties van kolommen in uw gegevensstromen. In de opbouwfunctie voor expressies kunt u verschillende typen aggregaties definiëren die zijn gebaseerd op gegevens- of tijdvensters (SQL OVER-component), zoals LEAD, LAG, NTILE, CUMEDIST en RANK. Er wordt een nieuw veld gegenereerd in uw uitvoer met deze aggregaties. U kunt ook optionele group-by-velden opnemen.
Over
Stel de partitionering van kolomgegevens in voor uw venstertransformatie. Het SQL-equivalent is de Partition By in de Over-component in SQL. Als u een berekening wilt maken of een expressie wilt maken die u voor de partitionering wilt gebruiken, kunt u dit doen door de muisaanwijzer op de kolomnaam te bewegen en berekende kolom te selecteren.
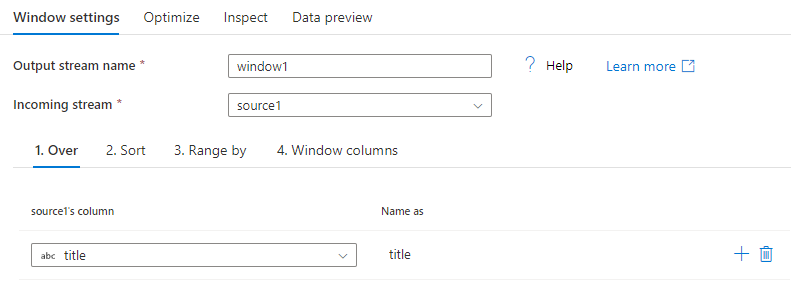
Sorteren
Een ander deel van de Over-clause is het instellen van Order By. Met deze component wordt de sorteervolgorde van gegevens ingesteld. U kunt ook een expressie maken voor een berekeningswaarde in dit kolomveld voor sorteren.
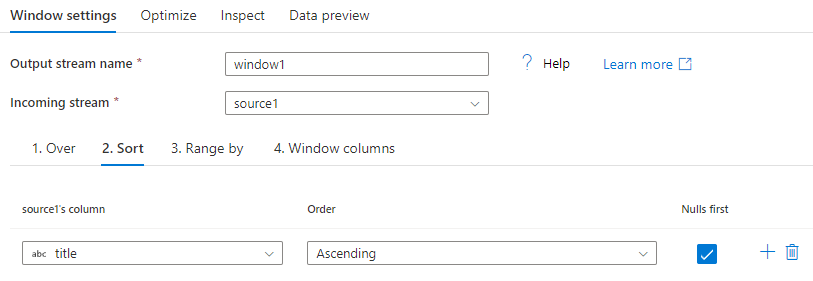
Sorteren op
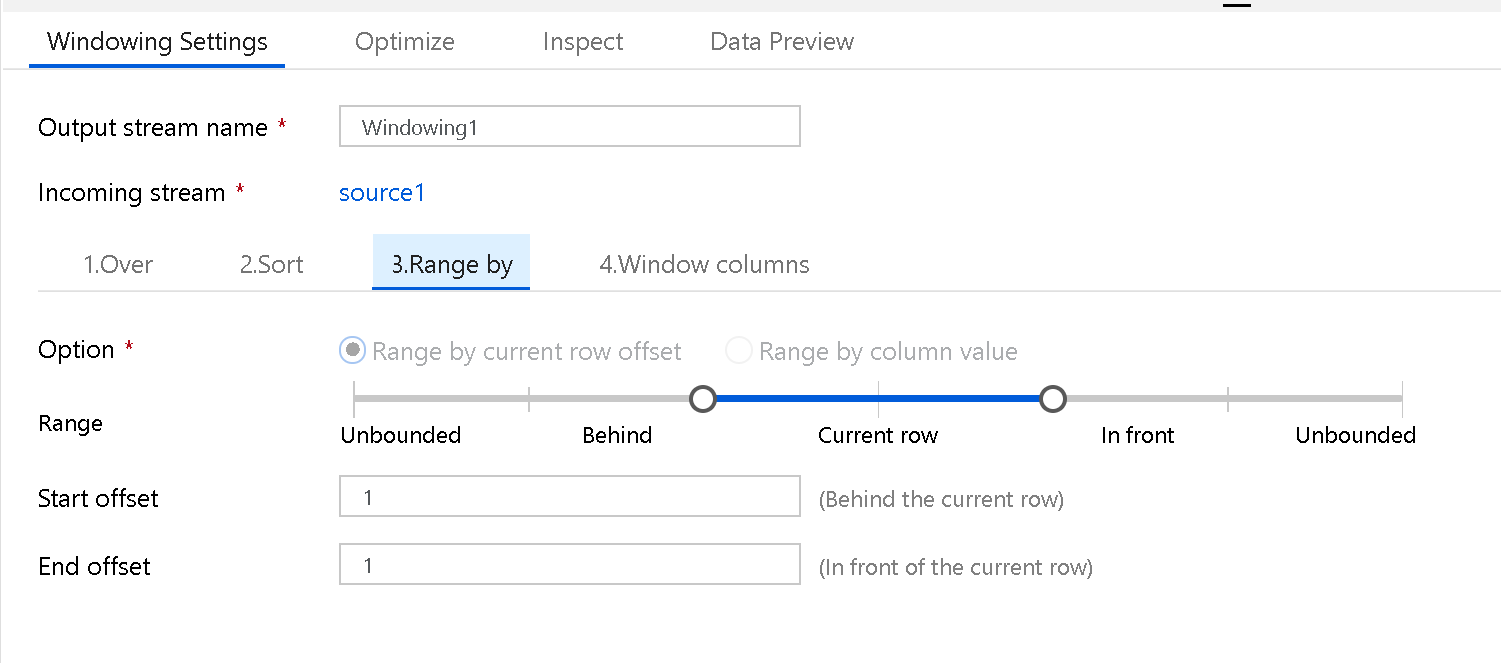
Stel vervolgens het vensterkader in als Onbegrensd of Begrensd. Als u een niet-afhankelijk vensterkader wilt instellen, stelt u de schuifregelaar in op Niet-afhankelijk aan beide uiteinden. Als u een instelling kiest tussen Ongelimiteerd en Huidige rij, moet u de begin- en eindwaarden voor offset instellen. Beide waarden zijn positieve gehele getallen. U kunt relatieve getallen of waarden uit uw gegevens gebruiken.
De schuifregelaar venster heeft twee waarden die moeten worden ingesteld: de waarden vóór de huidige rij en de waarden na de huidige rij. De verschuiving tussen begin en einde komt overeen met de twee selectors op de schuifregelaar.
Vensterkolommen
Gebruik tot slot de opbouwfunctie voor expressies om de aggregaties te definiëren die u wilt gebruiken met de gegevensvensters zoals RANK, COUNT, MIN, MAX, DENSE RANK, LEAD, LAG, enzovoort.
De volledige lijst met aggregatie- en analytische functies die u kunt gebruiken in de Gegevensstroom Expressietaal via de Expression Builder, worden weergegeven in Gegevenstransformatie-expressies in mapping-gegevensstroom.
Verwante inhoud
Als je op zoek bent naar een eenvoudige group-by-aggregatie, gebruik dan de Aggregate-transformatie