Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Gegevensstromen zijn beschikbaar in zowel Azure Data Factory pijplijnen als Azure Synapse Analytics pijplijnen. Dit artikel is van toepassing op gegevensverwerkingsstromen. Als u nieuw bent met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van mapping-dataflows.
Tip
Voor de equivalente transformatie (Group by) in Dataflow Gen2 raadpleegt u een handleiding voor Dataflow Gen2 voor het toewijzen van gegevensstroomgebruikers.
Met de aggregatietransformatie worden aggregaties van kolommen in uw gegevensstromen gedefinieerd. Met de opbouwfunctie voor expressies kunt u verschillende typen aggregaties definiëren, zoals SUM, MIN, MAX en COUNT, gegroepeerd op bestaande of berekende kolommen.
Groeperen op
Selecteer een bestaande kolom of maak een nieuwe berekende kolom die u wilt gebruiken als een GROUP BY-clausule voor uw aggregatie. Als u een bestaande kolom wilt gebruiken, selecteert u deze in de vervolgkeuzelijst. Als u een nieuwe berekende kolom wilt maken, beweegt u de muisaanwijzer over de component en klikt u op Berekende kolom. Hiermee opent u de opbouwfunctie voor expressies voor gegevensstromen. Nadat u de berekende kolom hebt gemaakt, voert u de naam van de uitvoerkolom in onder het veld Naam als . Als u een extra groep per component wilt toevoegen, plaatst u de muisaanwijzer op een bestaande component en klikt u op het pluspictogram.
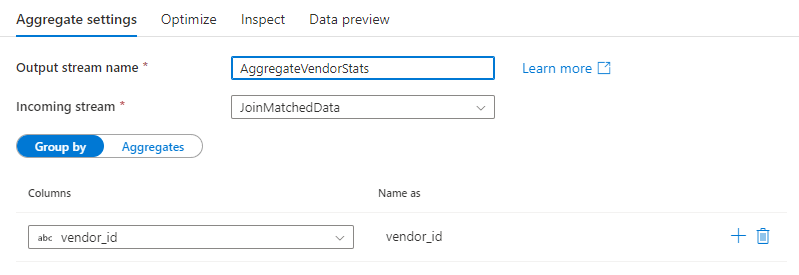
Een Groeperen op-clausule is optioneel in een Aggregatietransformatie.
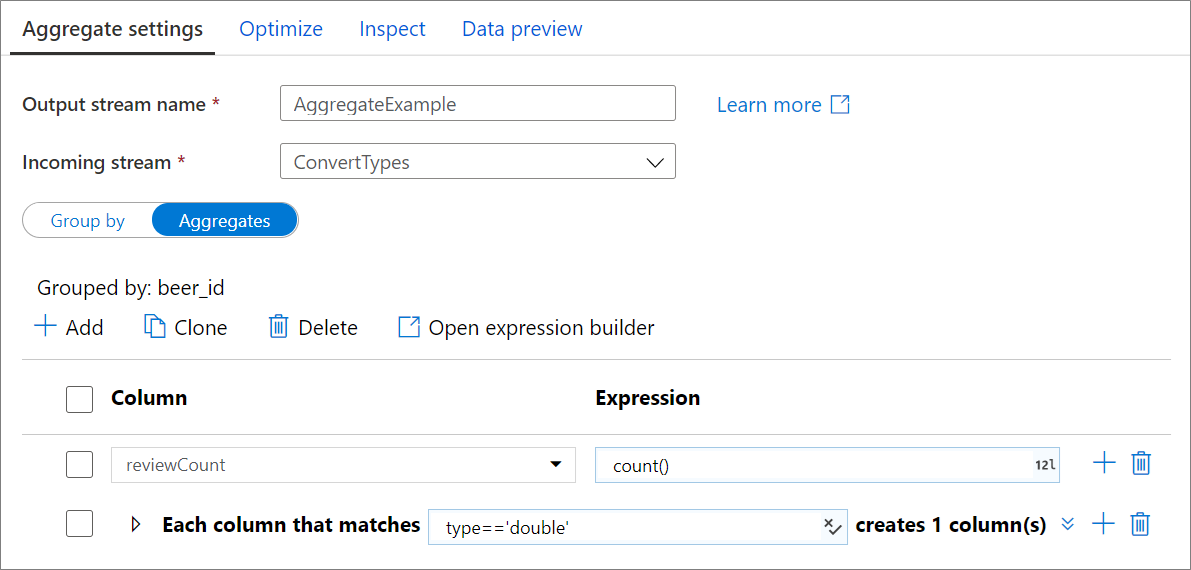
Geaggregeerde kolommen
Ga naar het tabblad Aggregaties om aggregatie-expressies te maken. U kunt een bestaande kolom overschrijven met een aggregatie of een nieuw veld maken met een nieuwe naam. De aggregatie-expressie wordt ingevoerd in het rechtervak naast de kolomnaamkiezer. Als u de expressie wilt bewerken, klikt u op het tekstvak en opent u de opbouwfunctie voor expressies. Als u meer samengevoegde kolommen wilt toevoegen, klikt u op Toevoegen boven de kolomlijst of het pluspictogram naast een bestaande statistische kolom. Kies Kolom toevoegen of Kolompatroon toevoegen. Elke aggregatie-expressie moet ten minste één statistische functie bevatten.
Notitie
In de foutopsporingsmodus kan de expressiebouwer geen voorbeeld van gegevens produceren met aggregatiefuncties. Als u voorbeelden van gegevens wilt weergeven voor samengevoegde transformaties, sluit u de opbouwfunctie voor expressies en bekijkt u de gegevens via het tabblad Gegevensvoorbeeld.
Kolompatronen
Gebruik kolompatronen om dezelfde aggregatie toe te passen op een set kolommen. Dit is handig als u veel kolommen uit het invoerschema wilt behouden omdat deze standaard worden verwijderd. Gebruik een heuristiek zoals first() om invoerkolommen bij de aggregatie te behouden.
Rijen en kolommen opnieuw verbinden
Aggregatietransformaties zijn vergelijkbaar met SQL aggregatie select query's. Kolommen die niet zijn opgenomen in uw groep per component of statistische functies, stromen niet door naar de uitvoer van uw geaggregeerde transformatie. Als u andere kolommen in de geaggregeerde uitvoer wilt opnemen, voert u een van de volgende methoden uit:
- Gebruik een statistische functie, zoals
last()offirst()om die extra kolom op te nemen. - Voeg de kolommen opnieuw toe aan uw uitvoerstroom met behulp van het self join-patroon.
Dubbele rijen verwijderen
Een veelvoorkomend gebruik van de statistische transformatie is het verwijderen of identificeren van dubbele vermeldingen in brongegevens. Dit proces wordt ontdubbeling genoemd. Gebruik een set van sleutelgroepen en pas een heuristiek naar keuze toe om te bepalen welke dubbele rij moet worden behouden. Algemene heuristieken zijnfirst(), last(), en max()min(). Gebruik kolompatronen om de regel toe te passen op elke kolom, met uitzondering van de groep op kolommen.
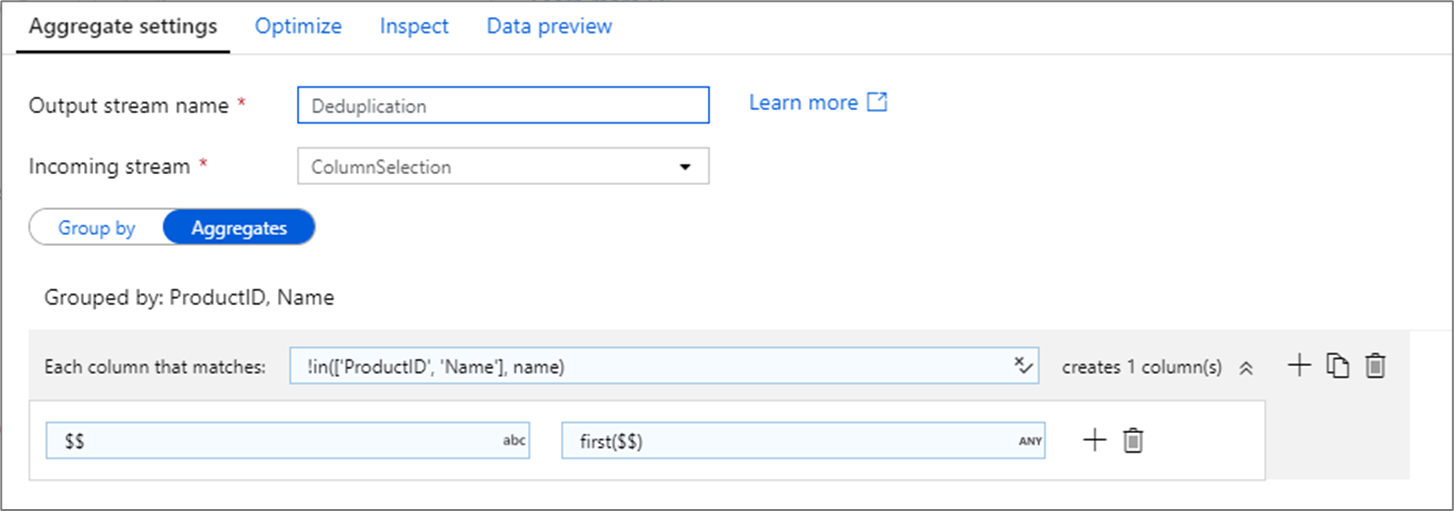
In het bovenstaande voorbeeld worden kolommen ProductID en Name gebruikt voor groepering. Als twee rijen dezelfde waarden hebben voor deze twee kolommen, worden ze beschouwd als duplicaten. In deze cumulatieve transformatie worden de waarden van de overeenkomende eerste rij bewaard en worden alle andere waarden verwijderd. Met behulp van de kolompatroon-syntaxis worden alle kolommen waarvan de namen niet ProductID en Name zijn, toegewezen aan hun bestaande kolomnaam en krijgen zij de waarde van de eerste overeenkomende rijen. Het uitvoerschema is hetzelfde als het invoerschema.
Voor scenario's voor gegevensvalidatie kan de count() functie worden gebruikt om te tellen hoeveel duplicaten er zijn.
Script voor gegevensstroom
Syntaxis
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Voorbeeld
In het onderstaande voorbeeld wordt een binnenkomende stroom gebruikt MoviesYear en worden rijen gegroepeerd op kolom year. Met de transformatie wordt een geaggregeerde kolom avgrating gemaakt die resulteert in het gemiddelde van de kolom Rating. Deze aggregatietransformatie heeft de naam AvgComedyRatingsByYear.
In de gebruikersinterface ziet deze transformatie eruit als in de onderstaande afbeelding:
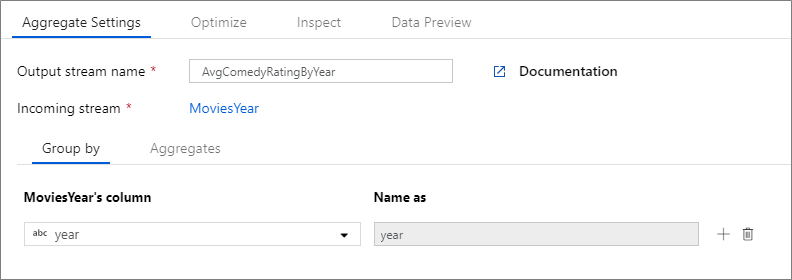
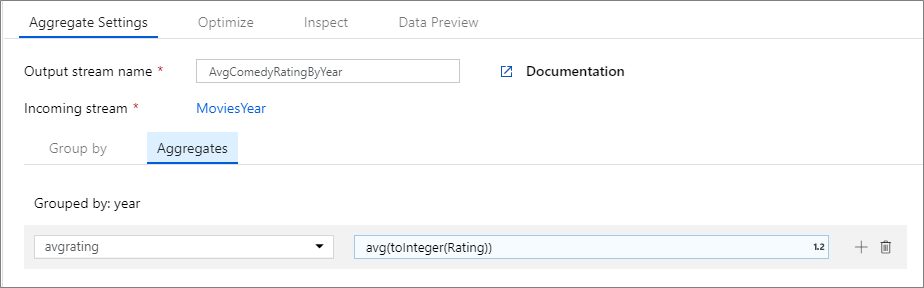
Het gegevensstroomscript voor deze transformatie bevindt zich in het onderstaande fragment.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
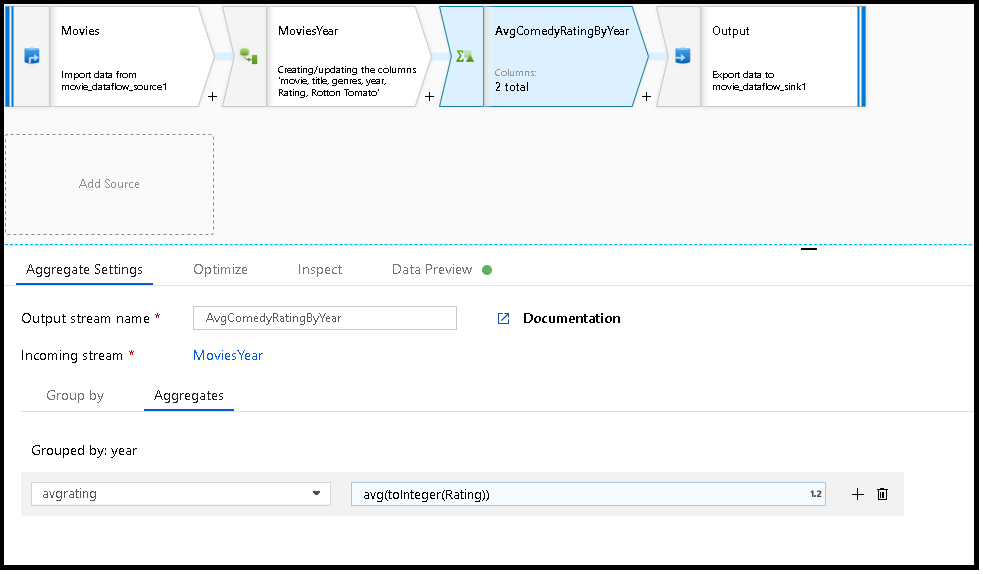
MoviesYear: Afgeleide kolom die jaar- en titelkolommen AvgComedyRatingByYeardefinieert: geaggregeerde transformatie voor gemiddelde classificatie van comedies gegroepeerd per jaar avgrating: Naam van nieuwe kolom die wordt gemaakt om de geaggregeerde waarde te bewaren
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Gerelateerde inhoud
- Aggregatie op basis van vensters definiëren met behulp van de venstertransformatie