De Databricks Notebook-activiteit uitvoeren in Azure Data Factory op een Databricks-notebook
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie gebruikt u Azure Portal om een Azure Data Factory-pijplijn te maken die een Databricks-notebook uitvoert op basis van het Databricks-takencluster. Bovendien worden tijdens de uitvoering Azure Data Factory-parameters doorgestuurd naar de Databricks-notebook.
In deze zelfstudie voert u de volgende stappen uit:
Een data factory maken.
Een pijplijn maken die gebruikmaakt van Databricks Notebook-activiteit.
Een pijplijnuitvoering activeren.
Controleer de pijplijnuitvoering.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Bekijk de volgende video voor een inleiding en demonstratie van deze functie van 11 minuten:
Vereisten
- Azure Databricks-werkruimte. Maak een Databricks-werkruimte of gebruik een bestaande werkruimte. U maakt een Python-notebook in uw Azure Databricks-werkruimte. Vervolgens voert u de notebook uit en geeft u er parameters aan door met behulp van Azure Data Factory.
Een data factory maken
Start de webbrowser Microsoft Edge of Google Chrome. Op dit moment wordt de Data Factory-gebruikersinterface alleen ondersteund in de webbrowsers Microsoft Edge en Google Chrome.
Selecteer Een resource maken in het menu van Azure Portal, selecteer Integratie en selecteer vervolgens Data Factory.
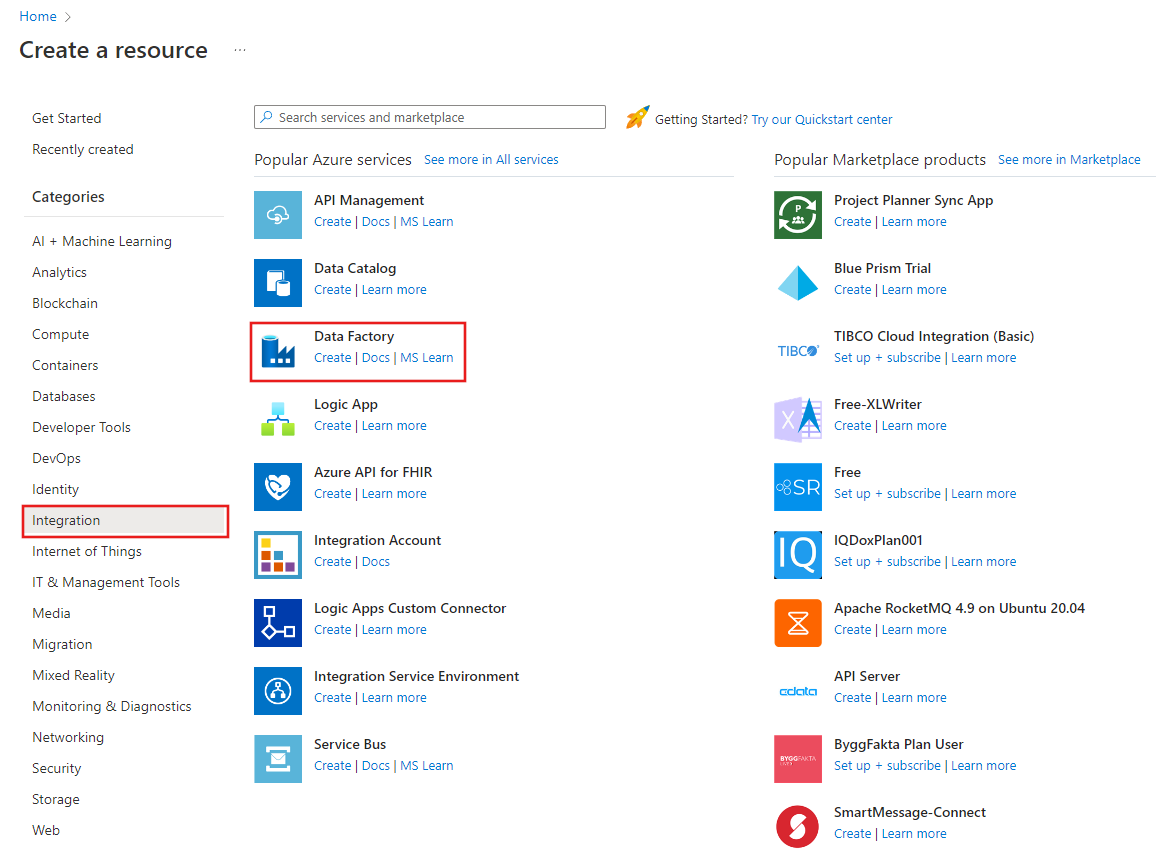
Selecteer op de pagina Data factory maken op het tabblad Basisbeginselen het Azure-abonnement waarin u de data factory wilt maken.
Voer een van de volgende stappen uit voor Resourcegroep:
Selecteer een bestaande resourcegroep in de vervolgkeuzelijst.
Selecteer Nieuwe maken en voer de naam van een nieuwe resourcegroep in.
Zie Resourcegroepen gebruiken om Azure-resources te beheren voor meer informatie.
Selecteer bij Regio de locatie voor de data factory.
De lijst bevat alleen locaties die worden ondersteund door Data Factory en waar uw Azure Data Factory-metagegevens worden opgeslagen. De bijbehorende gegevensarchieven (zoals Azure Storage en Azure SQL Database) en berekeningen (zoals Azure HDInsight) die Data Factory gebruikt, kunnen in andere regio's worden uitgevoerd.
Voer ADFTutorialDataFactory in bij Naam.
De naam van de Azure-gegevensfactory moet wereldwijd uniek zijn. Als u de volgende fout ziet, wijzigt u de naam van de gegevensfactory (gebruik bijvoorbeeld <uw naam>ADFTutorialDataFactory). Zie het artikel Data factory - Naamgevingsregels voor naamgevingsregels voor Data Factory-artefacten.
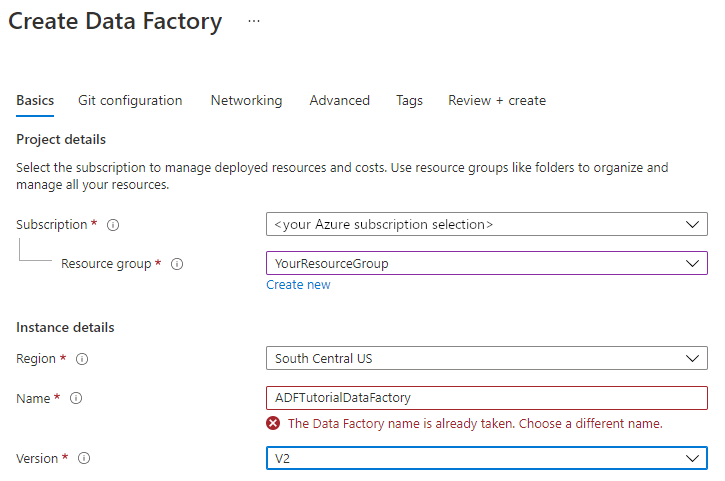
Selecteer V2 als Versie.
Selecteer Volgende: Git-configuratie en schakel het selectievakje Git later configureren in.
Selecteer Controleren en maken, en selecteer Maken nadat de validatie is voltooid.
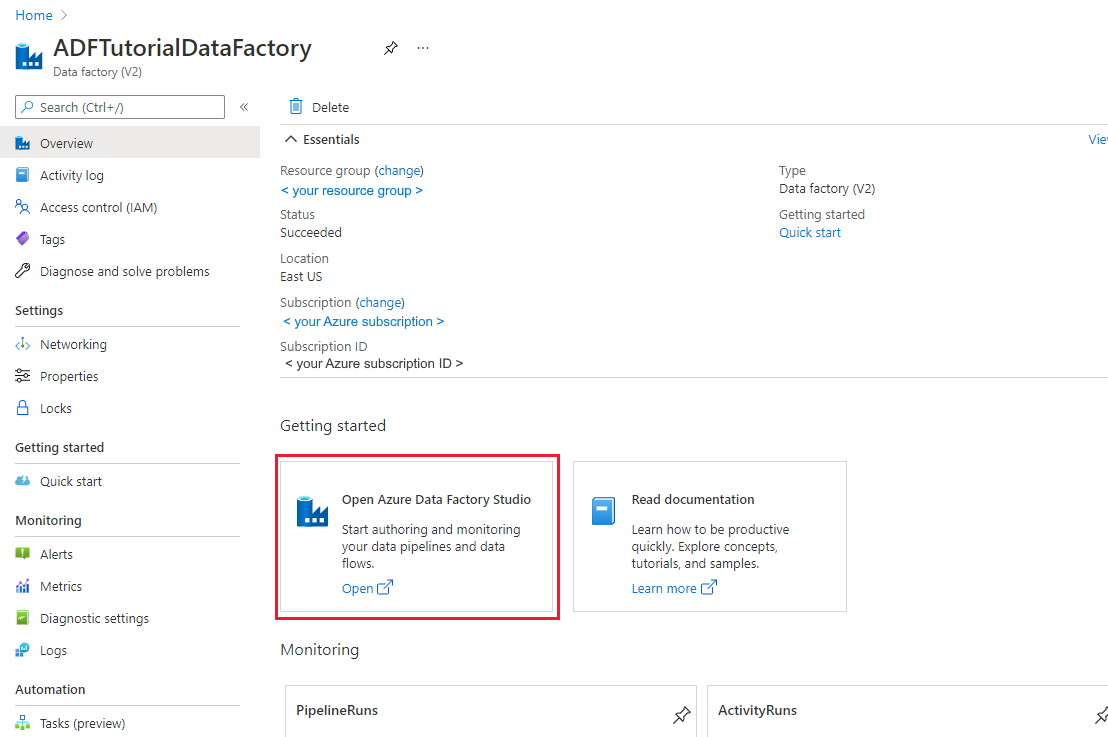
Nadat het maken is voltooid, selecteert u Ga naar resource om naar de pagina Data Factory te gaan. Selecteer de tegel Azure Data Factory Studio openen om de gebruikersinterfacetoepassing (UI) van Azure Data Factory te starten op een afzonderlijk browsertabblad.
Gekoppelde services maken
In deze sectie maakt u een aan Databricks gekoppelde service. Deze gekoppelde service bevat de verbindingsgegevens voor het Databricks-cluster:
Een aan Azure Databricks gekoppelde service maken
Ga op de startpagina naar het tabblad Beheren in het linkerdeelvenster.
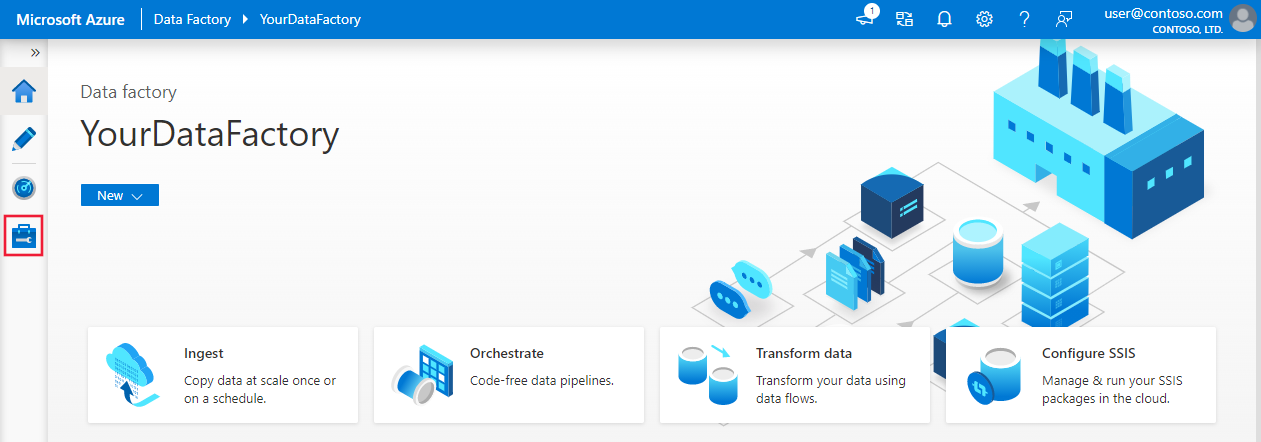
Selecteer Gekoppelde services onder Verbindingen en selecteer vervolgens + Nieuw.
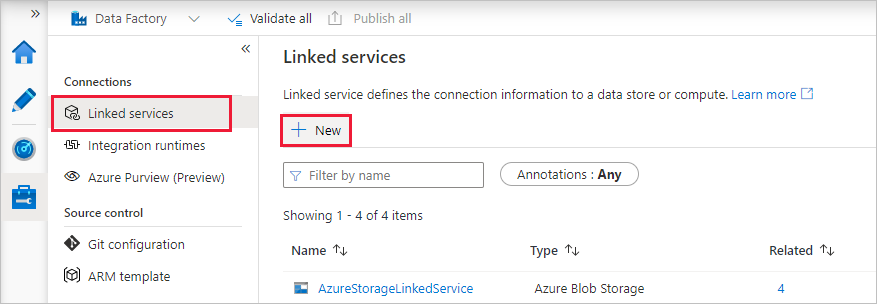
Selecteer Compute>Azure Databricks in het venster Nieuwe gekoppelde service en selecteer Vervolgens Doorgaan.

Voer in het venster Nieuwe gekoppelde service de volgende stappen uit:
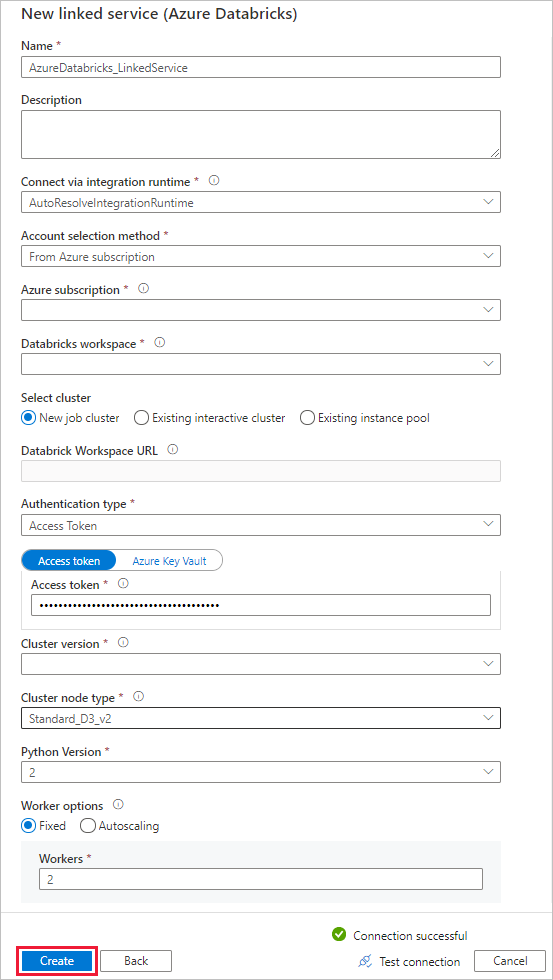
Voer bij Naam AzureDatabricks_LinkedService in.
Selecteer de juiste Databricks-werkruimte waarin u uw notebook gaat uitvoeren.
Selecteer voor Cluster selecteren de optie Nieuw taakcluster.
Voor de URL van de Databrick-werkruimte moet de informatie automatisch worden ingevuld.
Als u toegangstoken selecteert, genereert u dit voor verificatietype op de Azure Databricks-werkplek. U kunt de daarvoor benodigde stappen hier vinden. Voor beheerde service-identiteit en door de gebruiker toegewezen beheerde identiteit verleent u de rol Inzender aan beide identiteiten in het toegangsbeheermenu van de Azure Databricks-resource .
Selecteer voor clusterversie de versie die u wilt gebruiken.
Selecteer voor clusterknooppunttype Standard_D3_v2 onder categorie Algemeen gebruik (HDD) voor deze zelfstudie.
Voer bij Werkrollen2 in.
Selecteer Maken.
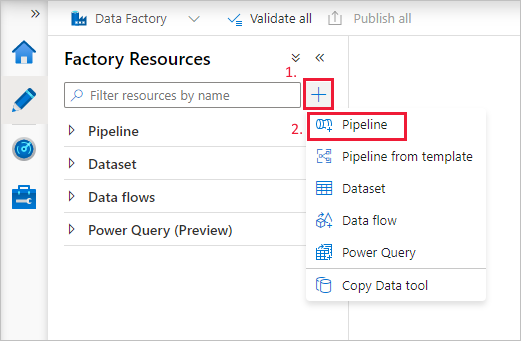
Een pipeline maken
Selecteer de knop + (plusteken) en selecteer vervolgens Pijplijn in het menu.
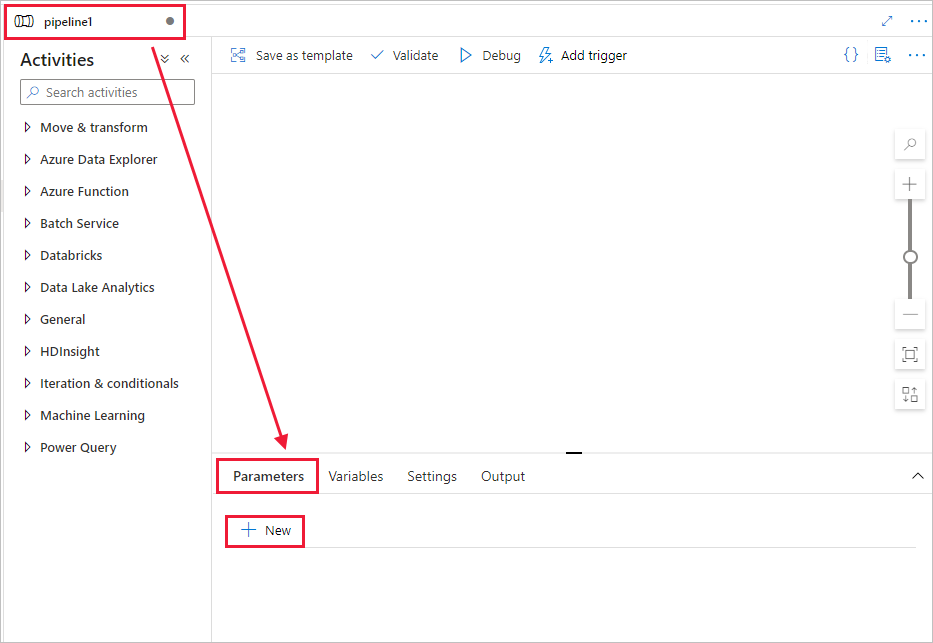
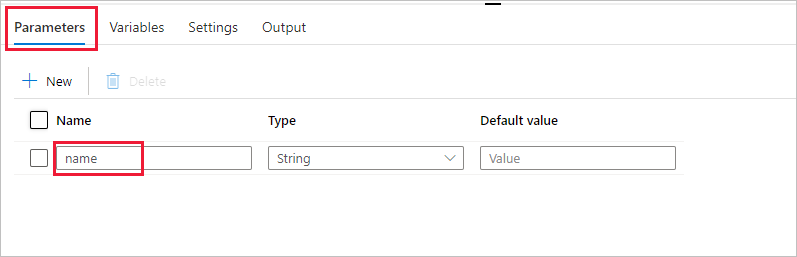
Maak een parameter voor gebruik in de pijplijn. Deze parameter geeft u later door aan de Databricks Notebook-activiteit. Selecteer in de lege pijplijn het tabblad Parameters en selecteer vervolgens + Nieuw en geef deze de naam 'naam'.
Vouw in de werkset ActiviteitenDatabricks uit. Sleep de activiteit Notebook vanuit de werkset Activiteiten naar het ontwerpoppervlak voor pijplijnen.
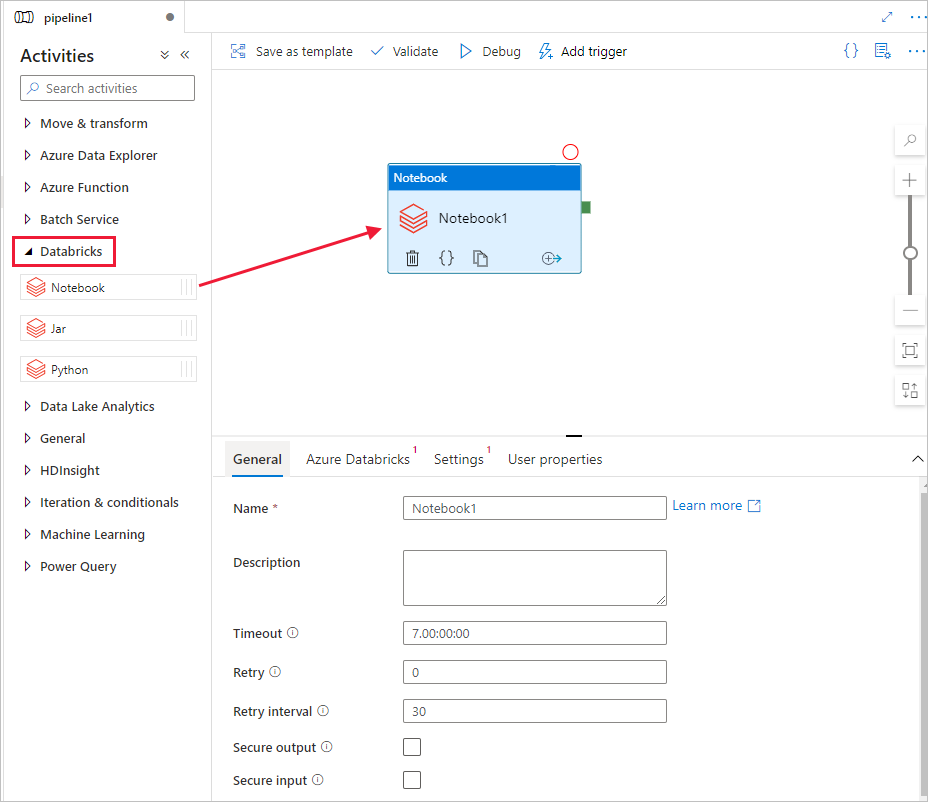
Voer de volgende stappen uit in de eigenschappen voor het DatabricksNotebook-activiteitvenster onderaan:
Schakel over naar het tabblad Azure Databricks.
Selecteer AzureDatabricks_LinkedService (die u in de vorige procedure hebt gemaakt).
Schakel over naar het tabblad Instellingen.
Zoek en selecteer een Databricks notebook-pad. We gaan een notebook maken en geven daarvoor hier het pad op. U krijgt het pad van de notebook door de volgende stappen uit te voeren.
Start uw Azure Databricks-werkruimte.
Maak een Nieuwe map in de werkruimte en roep deze aan als adftutorial.
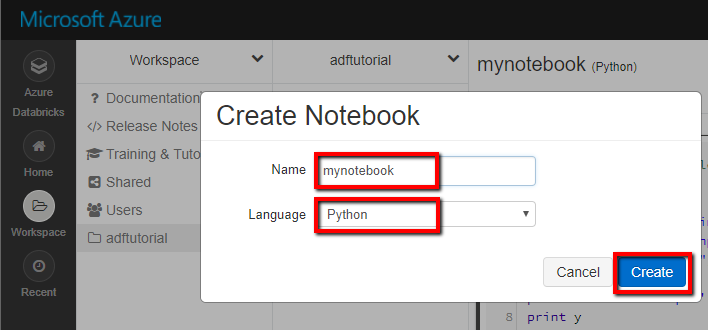
Schermopname die laat zien hoe u een nieuw notitieblok maakt. (Python), we noemen het mynotebook onder adftutorial Folder en klik op Maken.

In de zojuist gemaakte notebook 'mynotebook' voegt u de volgende code toe:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)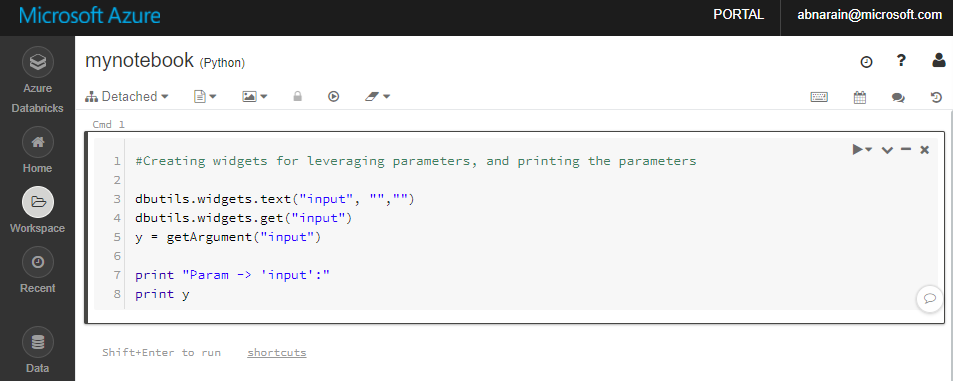
Het notebookpad in dit geval is /adftutorial/mynotebook.
Ga terug naar de gebruikersinterface van Data Factory. Navigeer naar het tabblad Instellingen onder de activiteit Notebook1 .
a. Voeg een parameter toe aan de notebookactiviteit. U gebruikt dezelfde parameter die u eerder aan de pijplijn hebt toegevoegd.
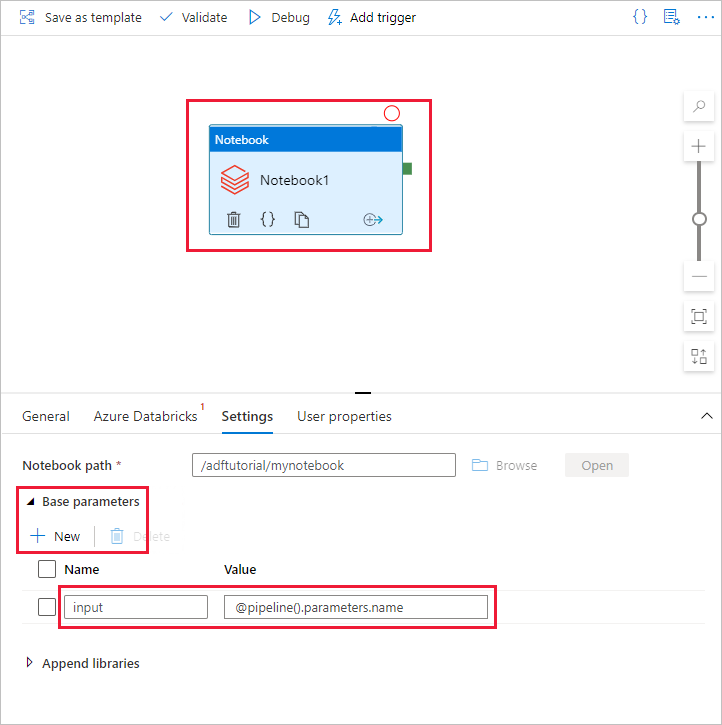
b. Geef de parameter een naam als invoer en geef de waarde op als expressie @pipeline().parameters.name.
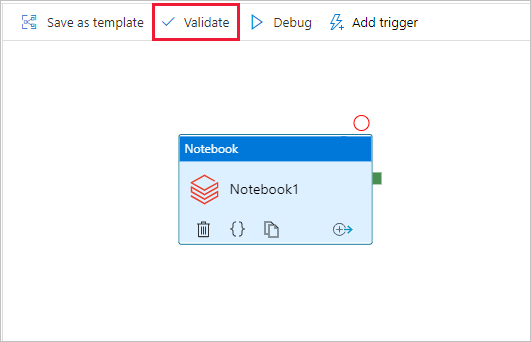
Selecteer op de werkbalk de knop Valideren om de pijplijn te valideren. Als u het validatievenster wilt sluiten, selecteert u de knop Sluiten .
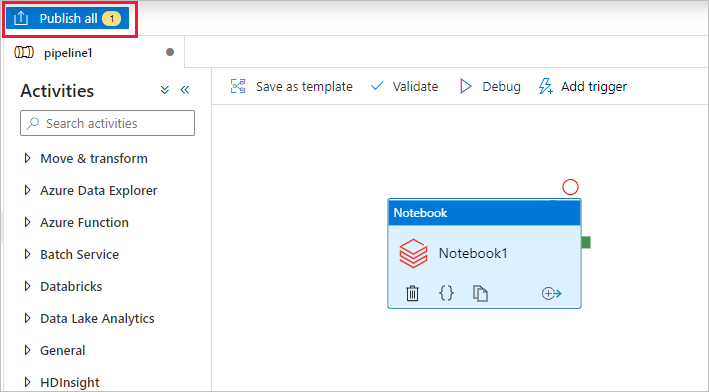
Selecteer Alles publiceren. De gebruikersinterface van Data Factory publiceert entiteiten (gekoppelde services en pijplijn) naar de Azure Data Factory-service.
Een pijplijnuitvoering activeren
Selecteer Trigger toevoegen op de werkbalk en selecteer Nu activeren.
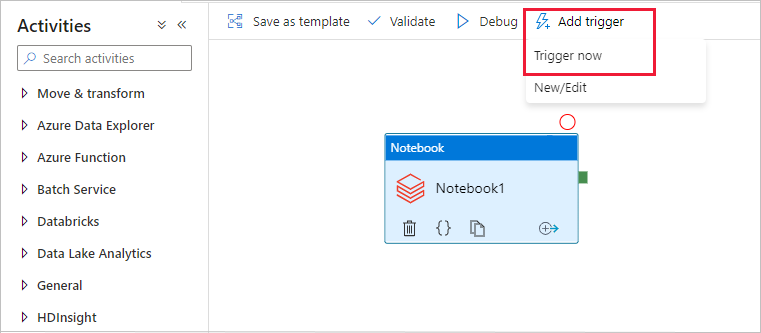
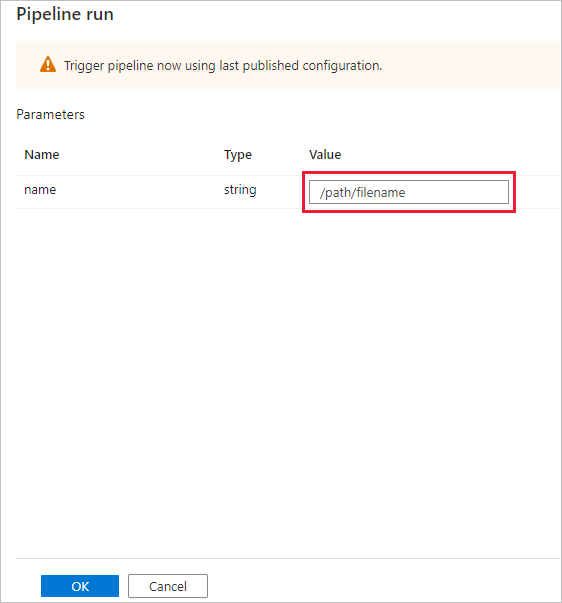
Het dialoogvenster Pijplijnuitvoering vraagt om de naamparameter . Gebruik hier /pad/bestandsnaam als parameter. Selecteer OK.
De pijplijnuitvoering controleren.
Ga naar het tabblad Controleren . Controleer of u een pijplijnuitvoering ziet. Het duurt 5 tot 8 minuten om een Databricks-taakcluster te maken, waar de notebook wordt uitgevoerd.
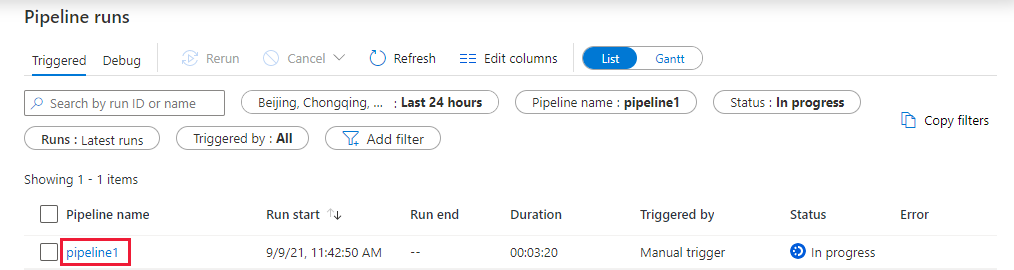
Selecteer regelmatig Vernieuwen om de status van de pijplijnuitvoering te controleren.
Als u de activiteitsuitvoeringen wilt zien die zijn gekoppeld aan de pijplijnuitvoering, selecteert u de koppeling pipeline1 in de kolom Pijplijnnaam .
Selecteer op de pagina Uitvoeringen van activiteit uitvoer in de kolom Activiteitsnaam om de uitvoer van elke activiteit weer te geven. U vindt de koppeling naar Databricks-logboeken in het deelvenster Uitvoer voor gedetailleerdere Spark-logboeken.
U kunt teruggaan naar de weergave pijplijnuitvoeringen door de koppeling Alle pijplijnuitvoeringen te selecteren in het breadcrumb-menu bovenaan.
De uitvoer controleren
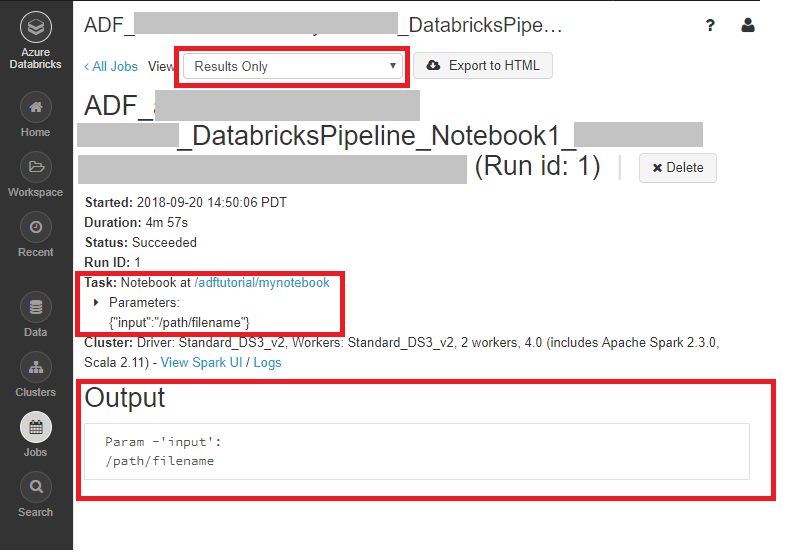
Meld u aan bij de Azure Databricks-werkruimte, ga naar Clusters en de Taak-status wordt weergegeven als uitvoering in behandeling, wordt uitgevoerd of beëindigd.
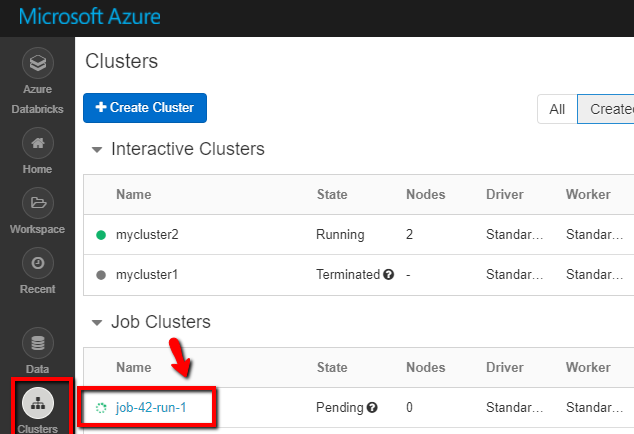
U kunt klikken op de Taaknaam om meer informatie weer te geven. Na een gelukte uitvoering kunt u de doorgegeven parameters en de uitvoer van de Python-notebook valideren.
Gerelateerde inhoud
De pijplijn in dit voorbeeld activeert een Databricks Notebook-activiteit en geeft daar een parameter aan door. U hebt geleerd hoe u:
Een data factory maken.
Een pijplijn maken die gebruikmaakt van de Databricks Notebook-activiteit.
Een pijplijnuitvoering activeren.
Controleer de pijplijnuitvoering.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor