Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
De HDInsight MapReduce-activiteit in een Azure Data Factory of Synapse Analytics pipeline roept het MapReduce-programma aan op eigen of on-demand HDInsight-cluster. Dit artikel is gebaseerd op het artikel over activiteiten voor gegevenstransformatie , waarin een algemeen overzicht wordt weergegeven van de gegevenstransformatie en de ondersteunde transformatieactiviteiten.
Lees voor meer informatie de inleidende artikelen voor Azure Data Factory en Synapse Analytics en voer de zelfstudie uit: Tutorial: gegevens transformeren voordat u dit artikel leest.
Zie Pig en Hive voor meer informatie over het uitvoeren van Pig/Hive-scripts in een HDInsight-cluster vanuit een pijplijn met behulp van HDInsight Pig- en Hive-activiteiten.
Een HDInsight MapReduce-activiteit toevoegen aan een pijplijn met de UI
Voer de volgende stappen uit om een HDInsight MapReduce-activiteit te gebruiken voor een pijplijn:
Zoek naar MapReduce in het deelvenster Pijplijnactiviteiten en sleep een MapReduce-activiteit naar het pijplijncanvas.
Selecteer de nieuwe MapReduce-activiteit op het canvas als deze nog niet is geselecteerd.
Selecteer het tabblad HDI-cluster om een nieuwe gekoppelde service te selecteren of te maken voor een HDInsight-cluster dat wordt gebruikt om de MapReduce-activiteit uit te voeren.
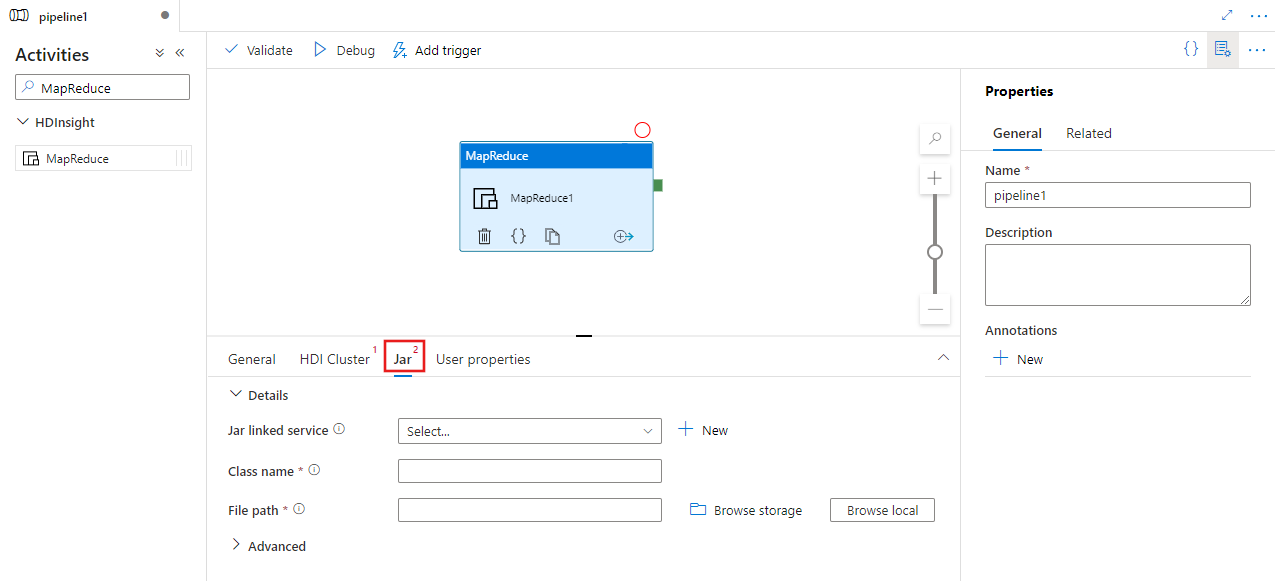
Selecteer het tabblad Jar om een nieuwe jar-gekoppelde service te selecteren of te maken voor een Azure Storage-account dat als host fungeert voor uw script. Geef een klassenaam op die daar moet worden uitgevoerd en een bestandspad binnen de opslaglocatie. U kunt ook geavanceerde details configureren, waaronder een Jar-bibliothekenlocatie, foutopsporingsconfiguratie en argumenten en parameters die moeten worden doorgegeven aan het script.
Syntaxis
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Details van de syntaxis
| Eigenschap | Beschrijving | Vereist |
|---|---|---|
| naam | Naam van de activiteit | Ja |
| beschrijving | Tekst waarin wordt beschreven waarvoor de activiteit wordt gebruikt | Nee |
| type | Voor MapReduce-activiteit is het activiteitstype HDinsightMapReduce | Ja |
| naam van de gekoppelde service | Verwijzing naar het HDInsight-cluster dat is geregistreerd als een gekoppelde service. Zie het artikel Compute als Gekoppelde Services voor meer informatie over deze gekoppelde service. | Ja |
| className | Naam van de klasse die moet worden uitgevoerd | Ja |
| jarLinkedService | Verwijzing naar een Azure Storage gekoppelde service die wordt gebruikt om de Jar-bestanden op te slaan. Alleen Azure Blob Storage en ADLS Gen2 gekoppelde services worden hier ondersteund. Als u deze gekoppelde service niet opgeeft, wordt de in de HDInsight gekoppelde service gedefinieerde Azure Storage gekoppelde service gebruikt. | Nee |
| jarFilePath | Geef het pad op naar de Jar-bestanden die zijn opgeslagen in de Azure Storage waarnaar wordt verwezen door jarLinkedService. De bestandsnaam is hoofdlettergevoelig. | Ja |
| jarlibs | Tekenreeksmatrix van het pad naar de Jar-bibliotheekbestanden waarnaar wordt verwezen door de taak die is opgeslagen in de Azure Storage gedefinieerd in jarLinkedService. De bestandsnaam is hoofdlettergevoelig. | Nee |
| getDebugInfo | Hiermee geeft u op wanneer de logboekbestanden worden gekopieerd naar de Azure Storage die worden gebruikt door het HDInsight-cluster (of) dat is opgegeven door jarLinkedService. Toegestane waarden: Geen, Altijd of Fout. Standaardwaarde: Geen. | Nee |
| Argumenten | Specificeer een array van argumenten voor een Hadoop-taak. De argumenten worden doorgegeven als opdrachtregelargumenten aan elke taak. | Nee |
| Definieert | Geef parameters op als sleutel-waardeparen voor verwijzingen in het Hive-script. | Nee |
Voorbeeld
U kunt de HDInsight MapReduce-activiteit gebruiken om een MapReduce JAR-bestand uit te voeren op een HDInsight-cluster. In de volgende JSON-voorbeelddefinitie van een pijplijn is de HDInsight-activiteit geconfigureerd voor het uitvoeren van een Mahout JAR-bestand.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
U kunt eventuele argumenten voor het MapReduce-programma opgeven in de sectie argumenten . Tijdens runtime ziet u enkele extra argumenten (bijvoorbeeld mapreduce.job.tags) uit het MapReduce-framework. Als u uw argumenten wilt onderscheiden van de MapReduce-argumenten, kunt u overwegen om beide opties en waarden te gebruiken als argumenten, zoals wordt weergegeven in het volgende voorbeeld (-s,--input,--output, enzovoort, zijn opties direct gevolgd door hun waarden).
Gerelateerde inhoud
Zie de volgende artikelen waarin wordt uitgelegd hoe u gegevens op andere manieren kunt transformeren: