Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
De Spark-activiteit in een Data Factory en in Synapse-pijplijnen, voert een Spark-programma uit op uw eigen of on-demand HDInsight-cluster. Dit artikel is gebaseerd op het artikel over activiteiten voor gegevenstransformatie , waarin een algemeen overzicht wordt weergegeven van de gegevenstransformatie en de ondersteunde transformatieactiviteiten. Wanneer u een gekoppelde Spark-service op aanvraag gebruikt, maakt de service automatisch een Spark-cluster voor u just-in-time om de gegevens te verwerken en wordt het cluster vervolgens verwijderd zodra de verwerking is voltooid.
Een Spark-activiteit toevoegen aan een pijplijn met de gebruikersinterface
Voer de volgende stappen uit om een Spark-activiteit te gebruiken voor een pijplijn:
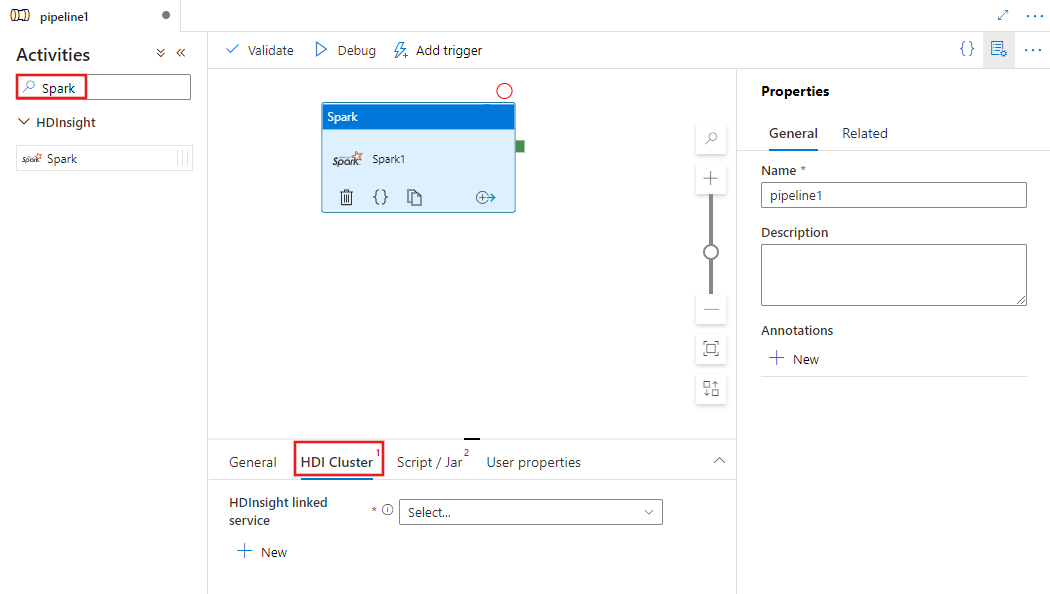
Zoek naar Spark in het deelvenster Pijplijnactiviteiten en sleep een Spark-activiteit naar het pijplijncanvas.
Selecteer de nieuwe Spark-activiteit op het canvas als deze nog niet is geselecteerd.
Selecteer het tabblad HDI-cluster om een nieuwe gekoppelde service te selecteren of te maken voor een HDInsight-cluster dat wordt gebruikt om de Spark-activiteit uit te voeren.
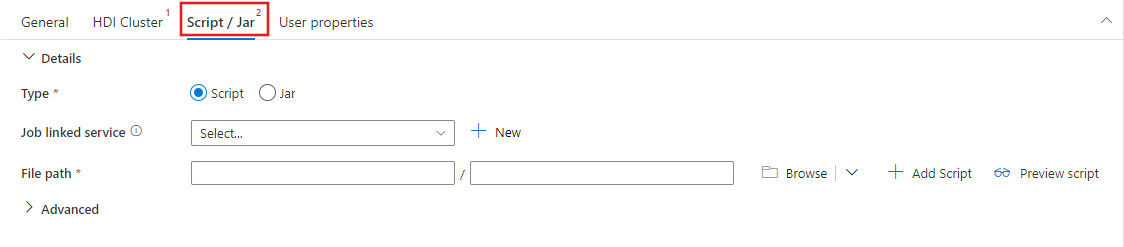
Selecteer het tabblad Script/Jar om een nieuwe taak te selecteren of te maken die is gekoppeld aan een Azure Storage-account dat als host fungeert voor uw script. Geef een pad op naar het bestand dat daar moet worden uitgevoerd. U kunt ook geavanceerde details configureren, waaronder een proxygebruiker, foutopsporingsconfiguratie en argumenten en Spark-configuratieparameters die moeten worden doorgegeven aan het script.
Eigenschappen van Spark-activiteit
Hier volgt de JSON-voorbeelddefinitie van een Spark-activiteit:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
In de volgende tabel worden de JSON-eigenschappen beschreven die worden gebruikt in de JSON-definitie:
| Eigenschap | Beschrijving | Vereist |
|---|---|---|
| naam | Naam van de activiteit in de pijplijn. | Ja |
| beschrijving | Tekst die beschrijft wat de activiteit doet. | Nee |
| type | Voor Spark-activiteit is het activiteitstype HDInsightSpark. | Ja |
| gekoppeldeServiceNaam | Naam van de gekoppelde HDInsight Spark-service waarop het Spark-programma wordt uitgevoerd. Zie het artikel Gekoppelde services berekenen voor meer informatie over deze gekoppelde service. | Ja |
| SparkJobLinkedService | De Azure Storage gekoppelde service die het Spark-taakbestand, afhankelijkheden en logboeken bevat. Alleen Azure Blob Storage en ADLS Gen2 gekoppelde services worden hier ondersteund. Als u geen waarde voor deze eigenschap opgeeft, wordt de opslag die is gekoppeld aan het HDInsight-cluster gebruikt. De waarde van deze eigenschap kan alleen een Azure Storage gekoppelde service zijn. | Nee |
| rootPath | De Azure Blob-container en -map die het Spark-bestand bevat. De bestandsnaam is hoofdlettergevoelig. Raadpleeg de sectie Mapstructuur (volgende sectie) voor meer informatie over de structuur van deze map. | Ja |
| entryFilePath | Relatief pad naar de hoofdmap van de Spark-code/het pakket. Het invoerbestand moet een Python of een .jar bestand zijn. | Ja |
| className | De Java/Spark-hoofdklasse van de toepassing | Nee |
| Argumenten | Een lijst met opdrachtregelargumenten voor het Spark-programma. | Nee |
| proxyUser | Het gebruikersaccount dat moet worden geïmiteerd om het Spark-programma uit te voeren | Nee |
| sparkConfig | Geef waarden op voor Spark-configuratie-eigenschappen die worden vermeld in het onderwerp: Spark-configuratie - toepassingseigenschappen. | Nee |
| getDebugInfo | Hiermee geeft u op wanneer de Spark-logboekbestanden worden gekopieerd naar de Azure-opslag die wordt gebruikt door het HDInsight-cluster (of) dat is opgegeven door sparkJobLinkedService. Toegestane waarden: Geen, Altijd of Fout. Standaardwaarde: Geen. | Nee |
Mapstructuur
Spark-taken zijn uitbreidbaarer dan Pig/Hive-taken. Voor Spark-taken kunt u meerdere afhankelijkheden opgeven, zoals JAR-pakketten (geplaatst in het Java CLASSPATH), Python bestanden (op het PYTHONPATH) en eventuele andere bestanden.
Maak de volgende mapstructuur in de Azure Blob Storage waarnaar wordt verwezen door de gekoppelde HDInsight-service. Upload vervolgens afhankelijke bestanden naar de juiste submappen in de hoofdmap die worden vertegenwoordigd door entryFilePath. Upload bijvoorbeeld Python bestanden naar de submap pyFiles en JAR-bestanden naar de JAR-submap van de hoofdmap. Tijdens runtime verwacht de service de volgende mapstructuur in de Azure Blob Storage:
| Path | Beschrijving | Vereist | Type |
|---|---|---|---|
. (wortel) |
Het hoofdpad van de Spark-taak in de gekoppelde opslagservice | Ja | Map |
| <door de gebruiker gedefinieerd > | Het pad dat verwijst naar het invoerbestand van de Spark-taak | Ja | Bestand |
| ./jar-bestanden | Alle bestanden onder deze map worden geüpload en op het Java klassepad van het cluster geplaatst | Nee | Map |
| ./pyFiles | Alle bestanden onder deze map worden geüpload en op het PYTHONPATH van het cluster geplaatst | Nee | Map |
| ./bestanden | Alle bestanden onder deze map worden geüpload en in de werkmap van de uitvoerders geplaatst | Nee | Map |
| ./archieven | Alle bestanden onder deze map zijn niet gecomprimeerd | Nee | Map |
| ./logs | De map die logboeken uit het Spark-cluster bevat. | Nee | Map |
Hier volgt een voorbeeld voor een opslag met twee Spark-taakbestanden in de Azure Blob Storage waarnaar wordt verwezen door de gekoppelde HDInsight-service.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Gerelateerde inhoud
Zie de volgende artikelen waarin wordt uitgelegd hoe u gegevens op andere manieren kunt transformeren: