Incrementeel nieuwe en gewijzigde bestanden kopiëren op basis van LastModifiedDate met behulp van het hulpprogramma Copy Data
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie gebruikt u Azure Portal om een data factory te maken. Vervolgens gebruikt u het hulpprogramma Copy Data om een pijplijn te maken waarmee alleen nieuwe en gewijzigde bestanden incrementeel worden gekopieerd van Azure Blob Storage naar Azure Blob Storage. Het gebruikt LastModifiedDate om te bepalen welke bestanden moeten worden gekopieerd.
Nadat u de stappen hier hebt voltooid, scant Azure Data Factory alle bestanden in het bronarchief, past u het bestandsfilter LastModifiedDatetoe op en kopieert u deze naar het doelarchief alleen bestanden die nieuw zijn of zijn bijgewerkt sinds de laatste keer. Houd er rekening mee dat als Data Factory grote aantallen bestanden scant, u nog steeds lange duur moet verwachten. Het scannen van bestanden kost veel tijd, zelfs wanneer de hoeveelheid gekopieerde gegevens wordt verminderd.
Notitie
Zie Inleiding tot Azure Data Factory als u niet bekend bent met Azure Data Factory.
In deze zelfstudie voert u de volgende taken uit:
- Een data factory maken.
- Het hulpprogramma Copy Data gebruiken om een pijplijn te maken.
- De uitvoering van de pijplijn en van de activiteit controleren.
Vereisten
- Azure-abonnement: als u nog geen abonnement op Azure hebt, maakt u een gratis Azure-account aan voordat u begint.
- Azure Storage-account: Blob Storage gebruiken voor de bron- en sinkgegevensarchieven. Als u geen Azure Storage-account hebt, volgt u de instructies in Een opslagaccount maken.
Twee containers maken in Blob Storage
Bereid uw Blob Storage voor voor de zelfstudie door de volgende stappen uit te voeren:
Maak een container met de naam bron. U kunt verschillende hulpprogramma's gebruiken om deze taak uit te voeren, zoals Azure Storage Explorer.
Maak een container met de naam bestemming.
Een data factory maken
Selecteer Een resource maken in het linkerdeelvenster. Selecteer Integration>Data Factory:
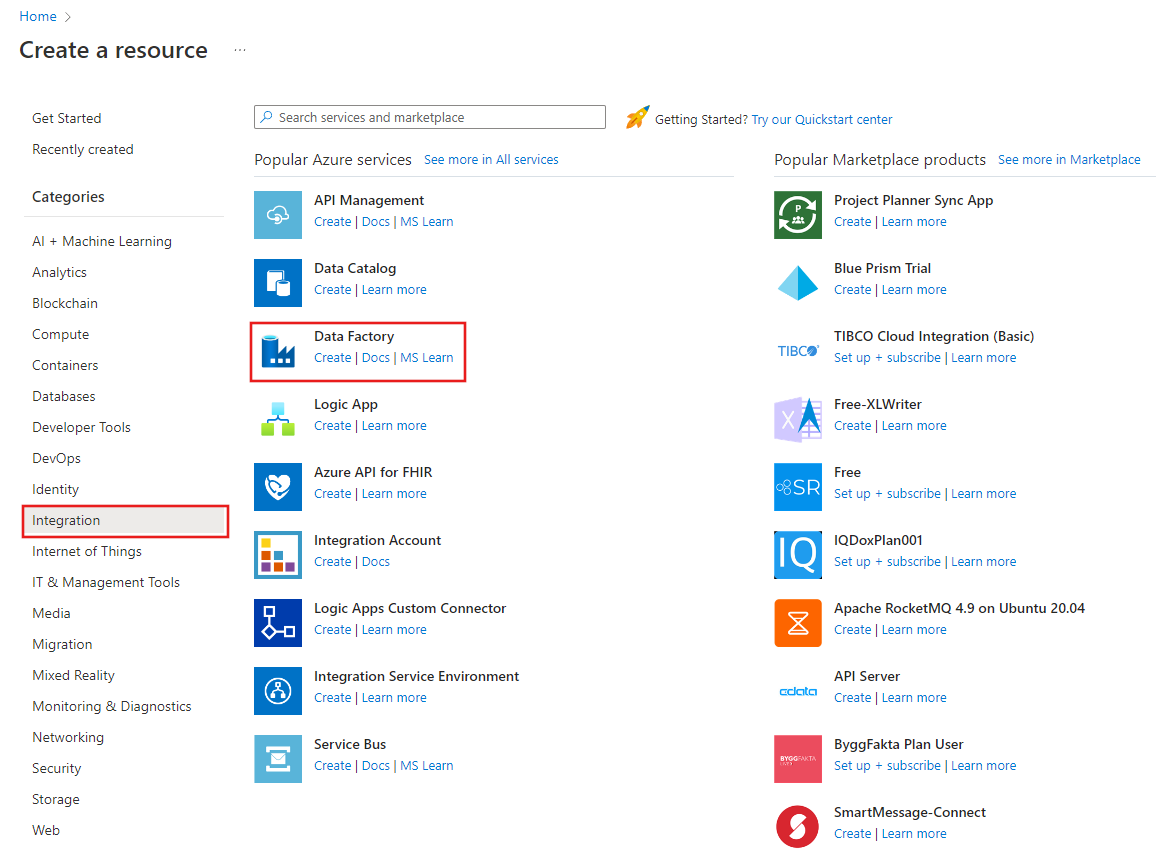
Voer op de pagina Nieuwe data factoryADFTutorialDataFactory in bij Naam.
De naam van de data factory moet wereldwijd uniek zijn. Mogelijk ontvangt u dit foutbericht:
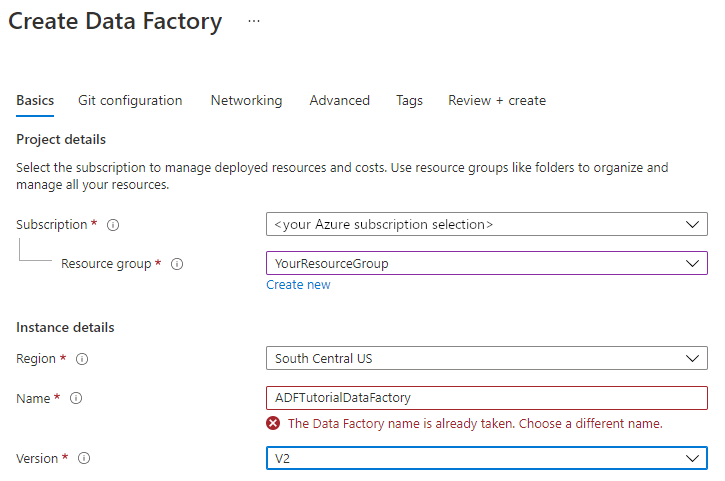
Als u een foutbericht ontvangt dat betrekking heeft op de waarde die bij de naam is ingevuld, voert u een andere naam in voor de data factory. Gebruik bijvoorbeeld de naam uwnaamADFTutorialDataFactory. Raadpleeg het onderwerp Data Factory - Naamgevingsregels voor meer informatie over naamgevingsregels voor Data Factory-artefacten.
Selecteer onder Abonnement het Azure-abonnement waarin u de nieuwe data factory maakt.
Voer onder Resourcegroep een van de volgende stappen uit:
Selecteer Bestaande gebruiken en selecteer vervolgens een bestaande resourcegroep in de lijst.
Selecteer Nieuwe maken en voer een naam in voor de resourcegroep.
Zie Resourcegroepen gebruiken om Azure-resources te beheren voor meer informatie.
Selecteer V2 onder Versie.
Selecteer bij Locatie de locatie voor de data factory. Alleen ondersteunde locaties worden weergegeven in de lijst. De gegevensarchieven (bijvoorbeeld Azure Storage en Azure SQL Database) en berekeningen (bijvoorbeeld Azure HDInsight) die uw data factory gebruikt, kunnen zich op andere locaties en regio's bevinden.
Selecteer Maken.
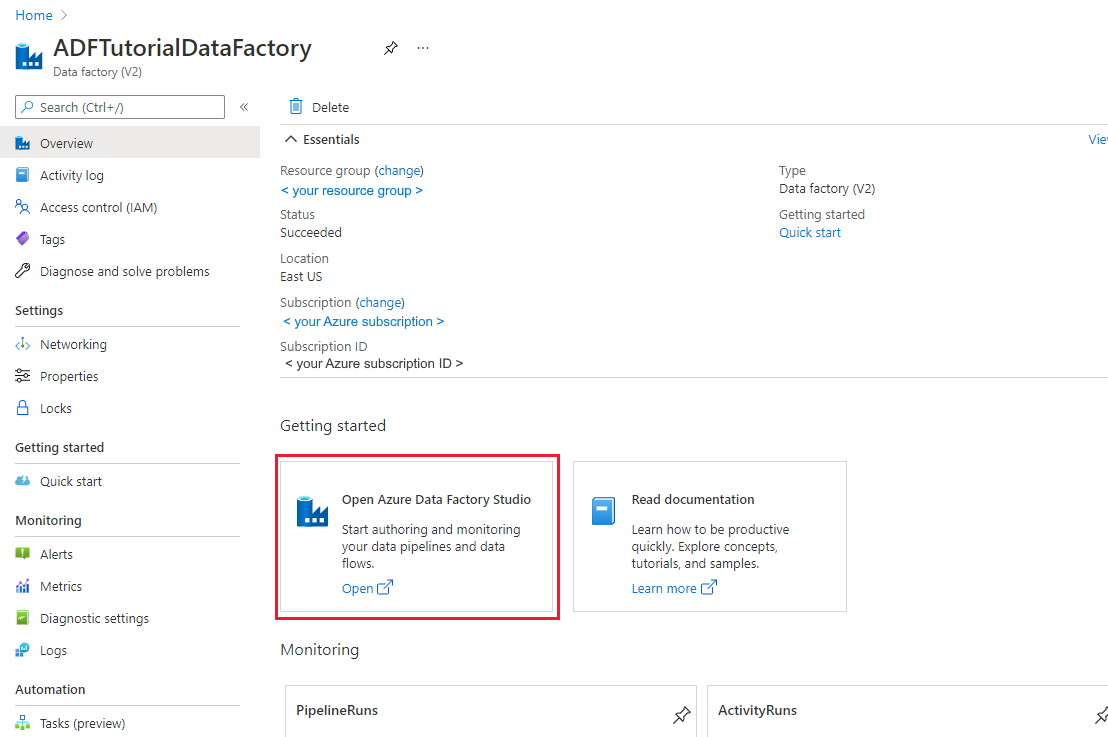
Nadat de data factory is gemaakt, wordt de startpagina van de data factory weergegeven.
Als u de gebruikersinterface (UI) van Azure Data Factory wilt openen op een afzonderlijk tabblad, selecteert u Openen op de tegel Azure Data Factory Studio openen:
Het hulpprogramma Copy Data gebruiken om een pijplijn te maken
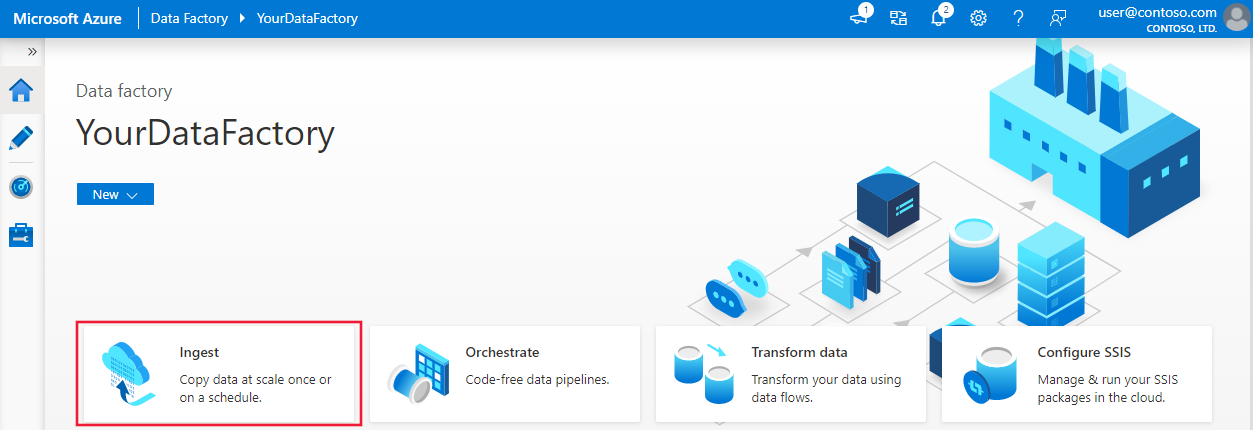
Selecteer op de startpagina van Azure Data Factory de tegel Opnemen om het hulpprogramma Copy Data te openen:
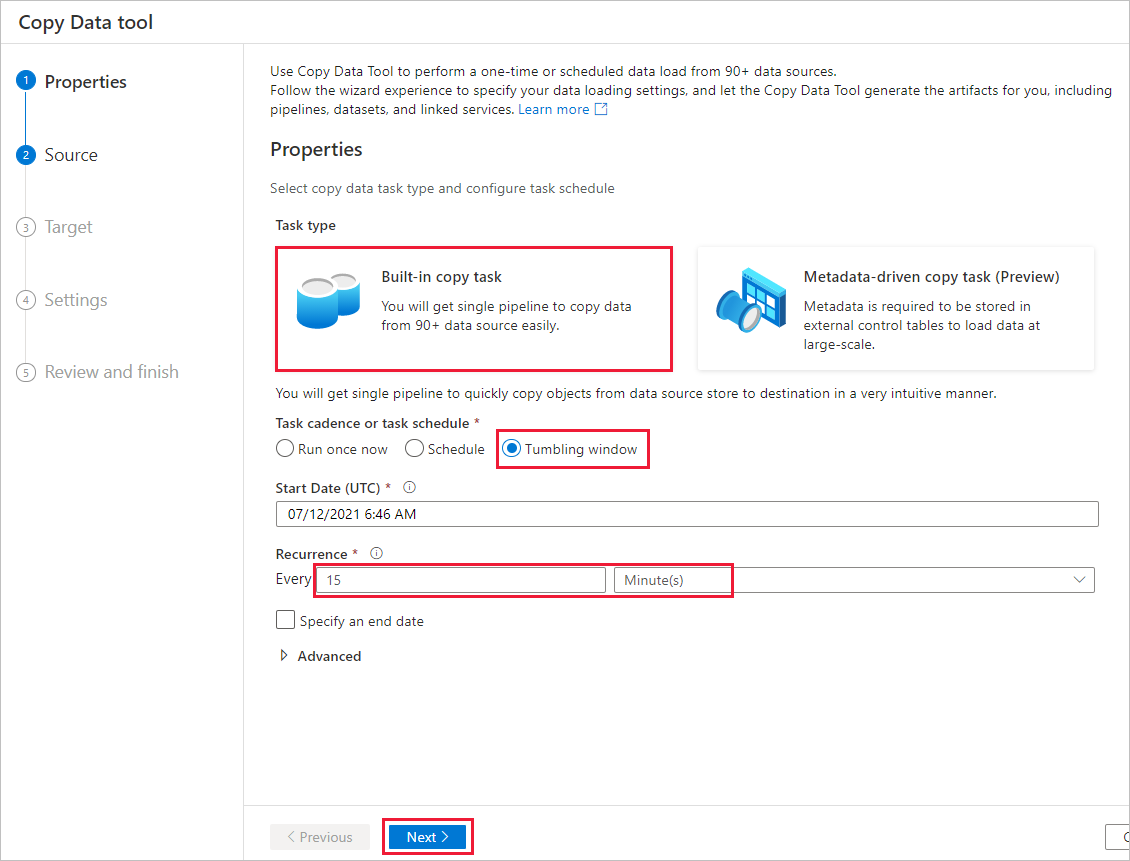
Voer op de pagina Eigenschappen de volgende stappen uit:
Selecteer onder Taaktype de optie Ingebouwde kopieertaak.
Selecteer onder Taakfrequentie of taakplanning het Tumblingvenster.
Voer onder Terugkeerpatroon 15 minuten in.
Selecteer Volgende.
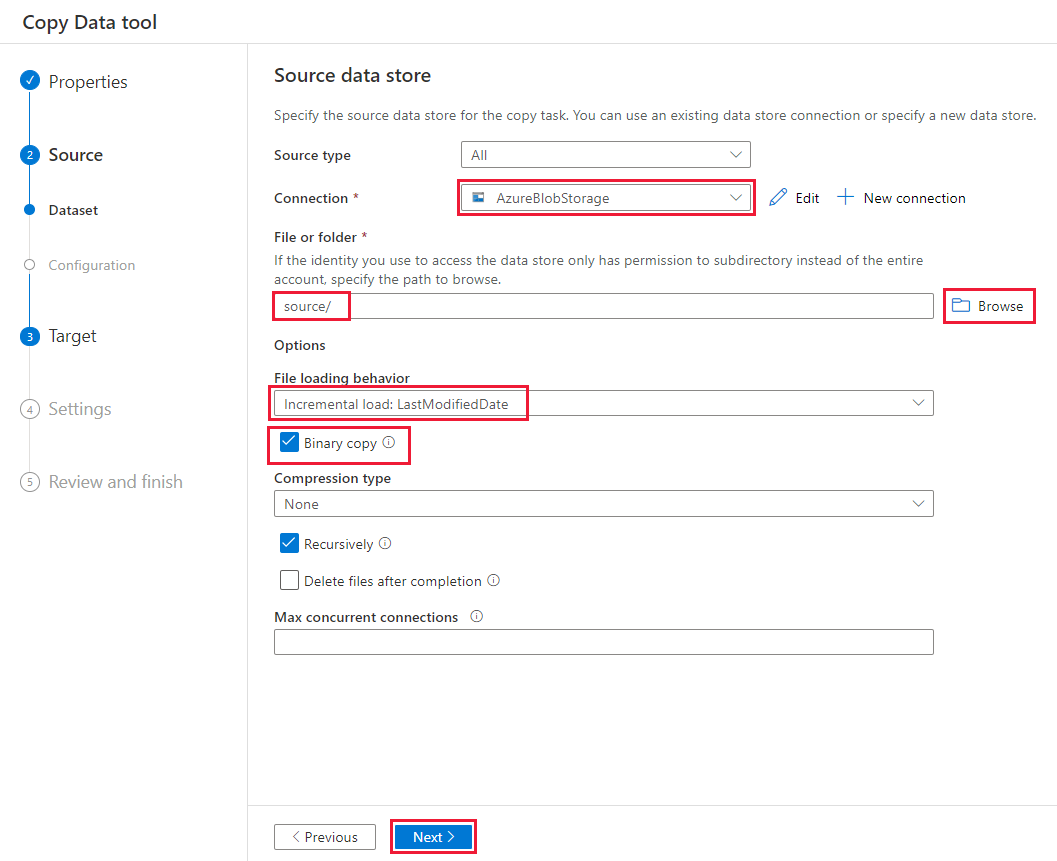
Voer op de pagina Brongegevensarchief de volgende stappen uit:
Selecteer + Nieuwe verbinding om een verbinding toe te voegen.
Selecteer Azure Blob Storage in de galerie en selecteer vervolgens Doorgaan:

Selecteer op de pagina Nieuwe verbinding (Azure Blob Storage) uw Azure-abonnement in de lijst met Azure-abonnementen en uw opslagaccount in de lijst met opslagaccountnamen . Test de verbinding en selecteer Vervolgens Maken.
Selecteer de zojuist gemaakte verbinding in het verbindingsblok .
Selecteer Bladeren in het gedeelte Bestand of map de optie Bladeren en kies de bronmap en selecteer vervolgens OK.
Selecteer onder Gedrag van bestand laden incrementeel laden: LastModifiedDate en kies Binaire kopie.
Selecteer Volgende.
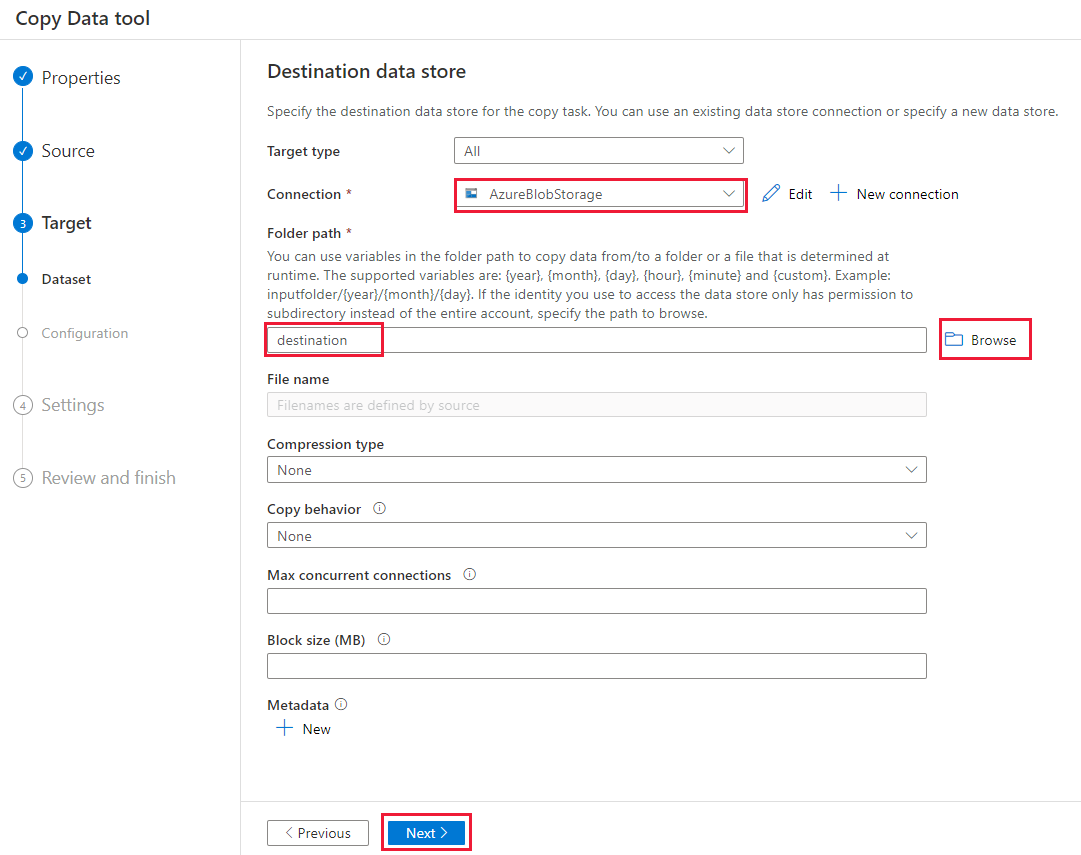
Voer op de pagina Doelgegevensarchief de volgende stappen uit:
Selecteer de AzureBlobStorage-verbinding die u hebt gemaakt. Dit is hetzelfde opslagaccount als het brongegevensarchief.
Blader in de sectie Mappad naar de doelmap en selecteer deze en selecteer vervolgens OK.
Selecteer Volgende.
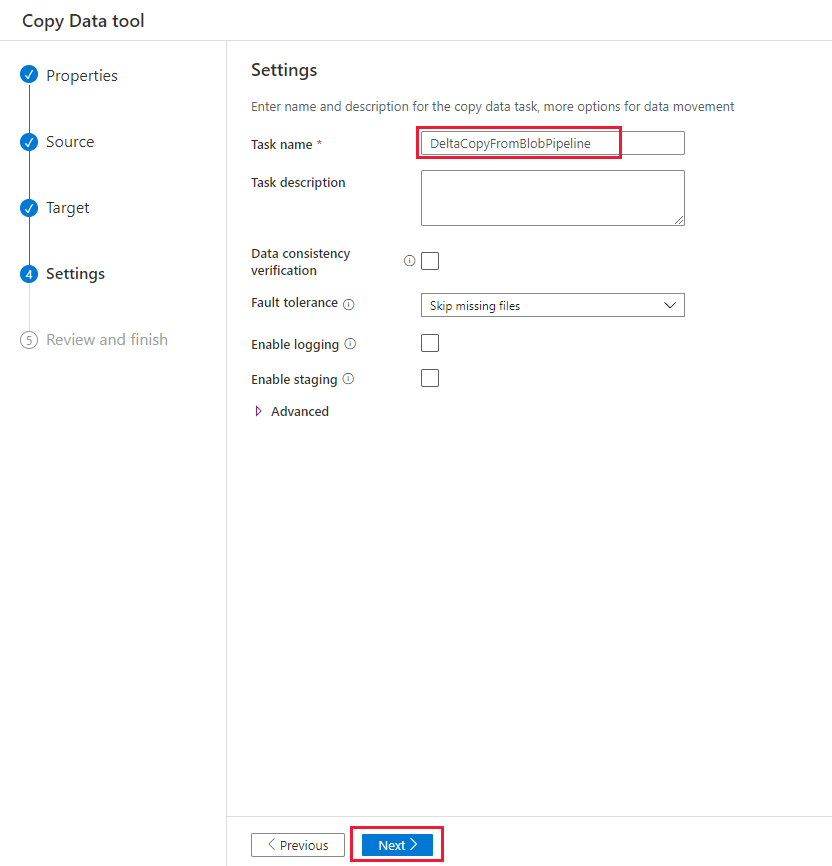
Voer op de pagina Instellingen, onder Taaknaam, DeltaCopyFromBlobPipeline in en selecteer vervolgens Volgende. Data Factory maakt een pijplijn met de opgegeven taaknaam.
Controleer de instellingen op de pagina Samenvatting en selecteer vervolgens Volgende.
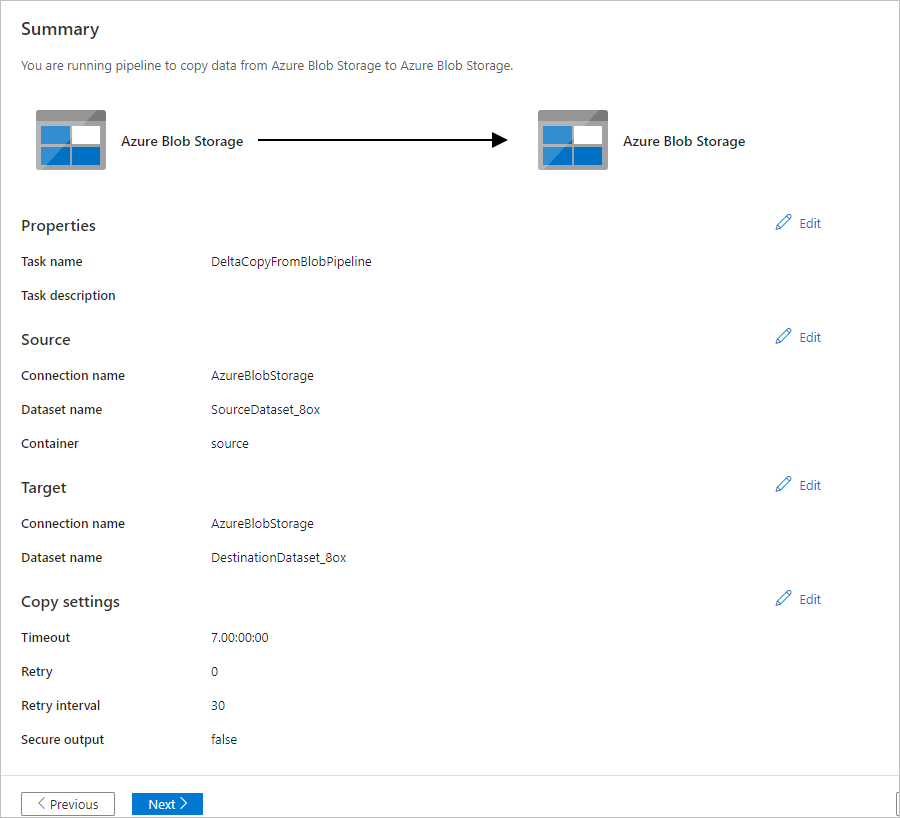
Selecteer op de pagina Implementatie de optie Controleren om de pijplijn of taak te controleren.
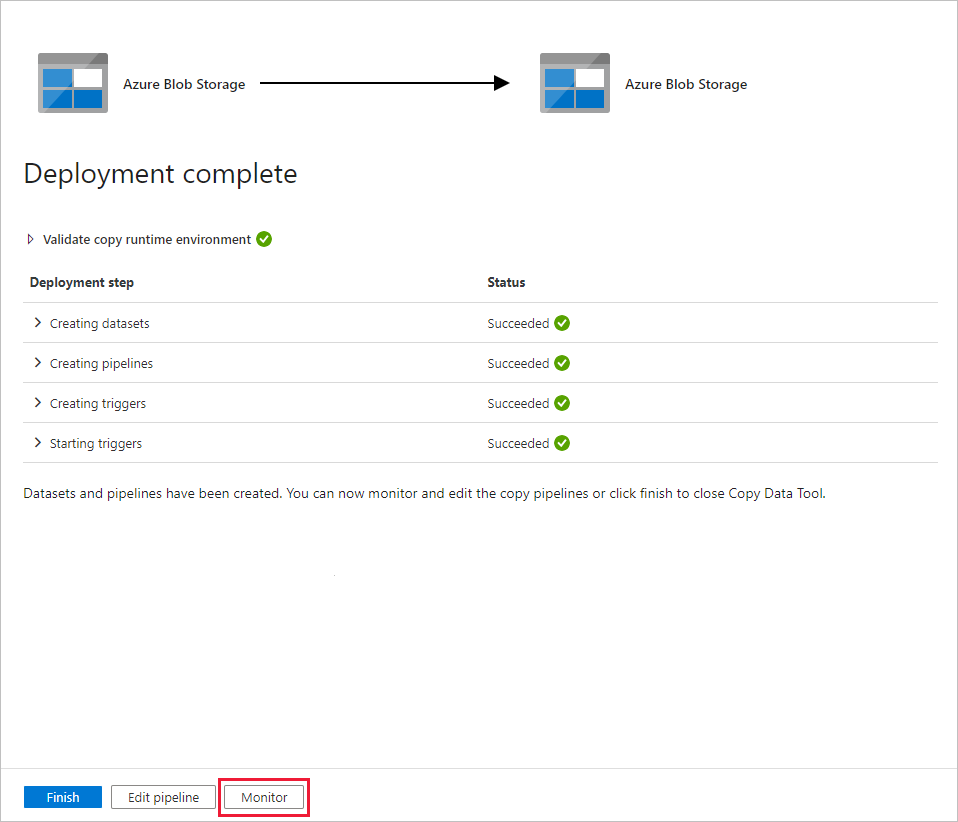
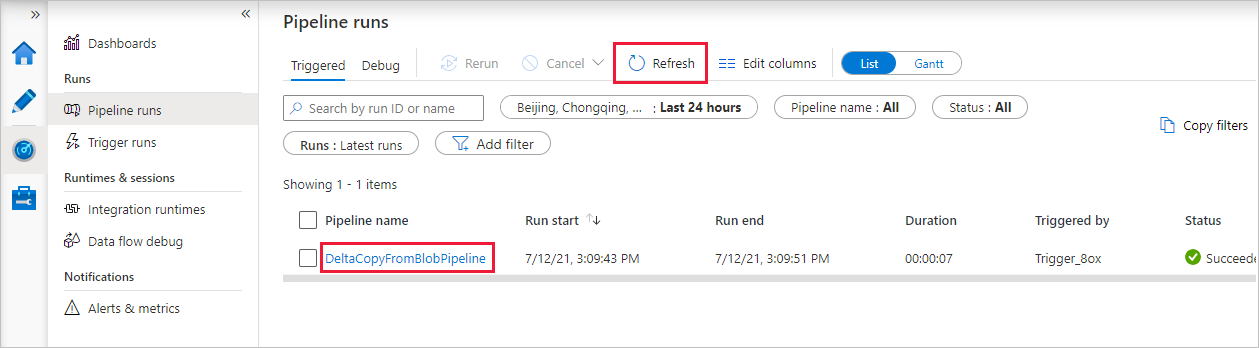
U ziet dat het tabblad Controleren aan de linkerkant automatisch wordt geselecteerd. De toepassing schakelt over naar het tabblad Monitor . U ziet de status van de pijplijn. Selecteer Vernieuwen om de lijst te vernieuwen. Selecteer de koppeling onder Naam van de pijplijn om details van de activiteitsuitvoering weer te geven of om de pijplijn opnieuw uit te voeren.
Er is slechts één activiteit (de kopieeractiviteit) in de pijplijn, dus u ziet slechts één vermelding. Voor meer informatie over de kopieerbewerking selecteert u op de pagina Uitvoeringen van activiteit de koppeling Details (het brilpictogram) in de kolom Activiteitsnaam . Zie Copy-activiteit overzicht voor meer informatie over de eigenschappen.
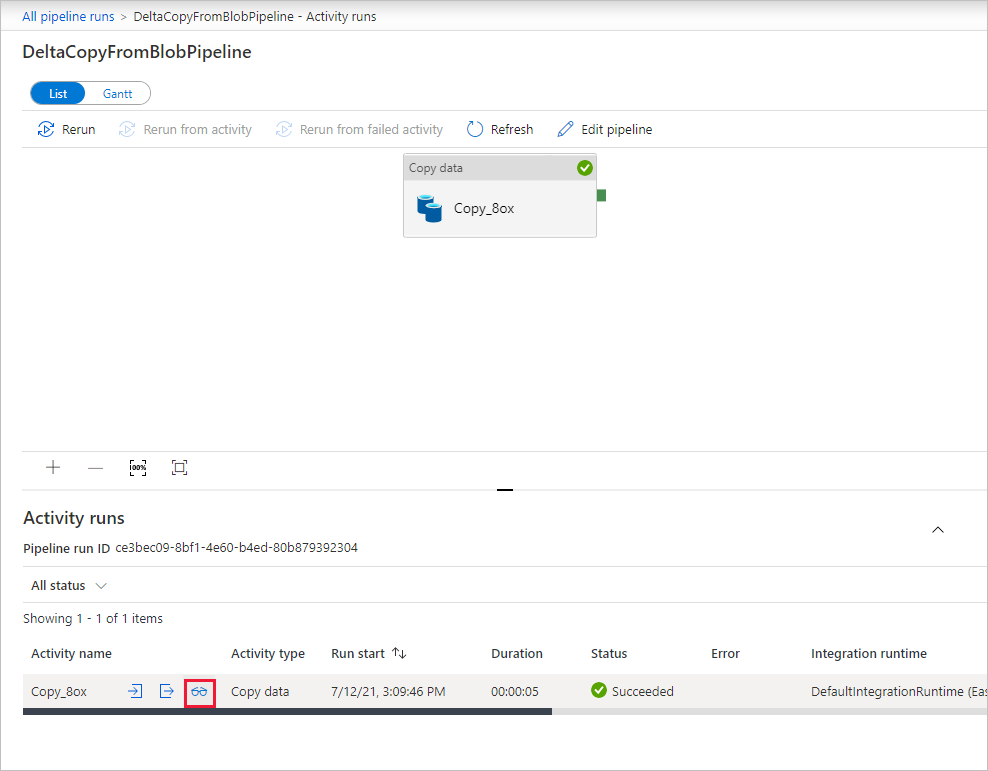
Omdat er geen bestanden in de broncontainer in uw Blob Storage-account staan, ziet u geen bestanden die naar de doelcontainer in het account zijn gekopieerd:
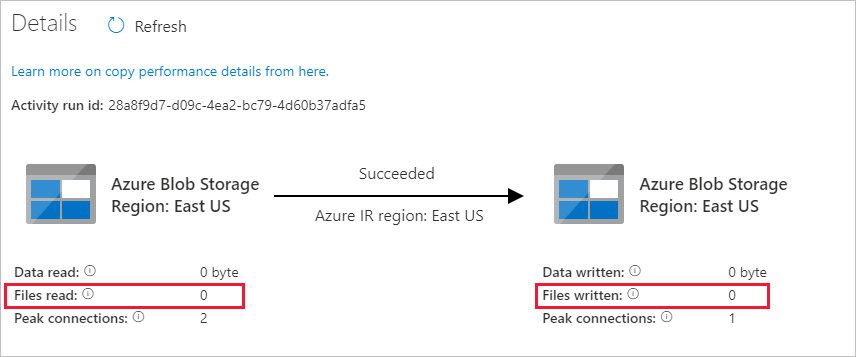
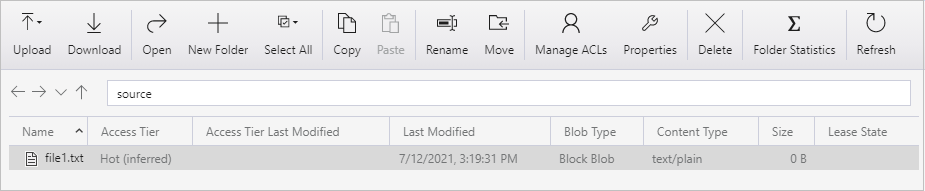
Maak een leeg tekstbestand en geef het file1.txt een naam. Upload dit tekstbestand naar de broncontainer in uw opslagaccount. U kunt verschillende hulpprogramma's gebruiken om deze taken uit te voeren, zoals Azure Storage Explorer.
Als u wilt teruggaan naar de weergave Pijplijnuitvoeringen , selecteert u de koppeling Alle pijplijnuitvoeringen in het breadcrumb-menu op de pagina Uitvoeringen van activiteit en wacht u tot dezelfde pijplijn automatisch opnieuw wordt geactiveerd.
Wanneer de tweede pijplijnuitvoering is voltooid, volgt u dezelfde stappen die eerder zijn vermeld om de details van de uitvoering van de activiteit te bekijken.
U ziet dat één bestand (file1.txt) is gekopieerd van de broncontainer naar de doelcontainer van uw Blob Storage-account:
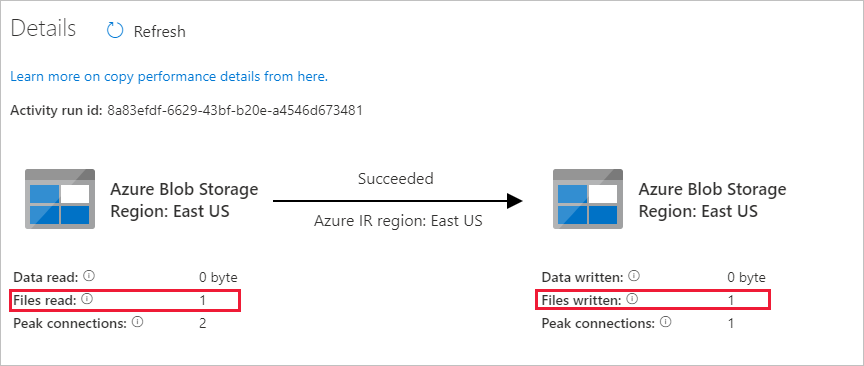
Maak nog een leeg tekstbestand en geef het file2.txt een naam. Upload dit tekstbestand naar de broncontainer in uw Blob Storage-account.
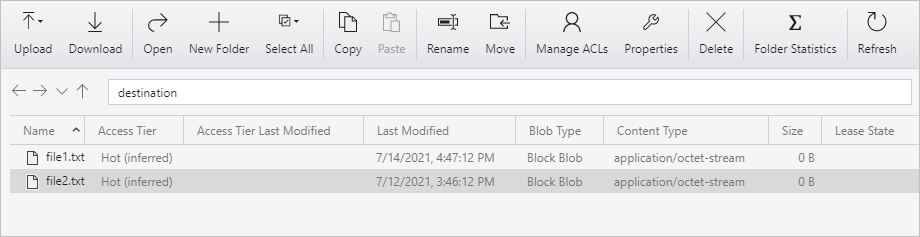
Herhaal stap 11 en 12 voor het tweede tekstbestand. U ziet dat alleen het nieuwe bestand (file2.txt) is gekopieerd van de broncontainer naar de doelcontainer van uw opslagaccount tijdens deze pijplijnuitvoering.
U kunt ook controleren of er slechts één bestand is gekopieerd met behulp van Azure Storage Explorer om de bestanden te scannen:
Gerelateerde inhoud
Ga naar de volgende zelfstudie voor meer informatie over het transformeren van gegevens met behulp van een Apache Spark-cluster in Azure:
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor