Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Deze zelfstudie begeleidt u bij het instellen van de Databricks-extensie voor Visual Studio Code en het uitvoeren van Python op een Azure Databricks-cluster en als een Azure Databricks taak in uw externe werkruimte. Zie Databricks-extensie voor Visual Studio Code.
Vereisten
Voor deze zelfstudie zijn de volgende vereisten nodig:
- U hebt de Databricks-extensie geïnstalleerd voor Visual Studio Code. Zie Install the Databricks extension for Visual Studio Code.
- U hebt een extern Azure Databricks-cluster dat u wilt gebruiken. Noteer de naam van het cluster. Als u de beschikbare clusters wilt weergeven, klikt u in de zijbalk van de Azure Databricks werkruimte op Compute. Zie Compute.
Stap 1: Een nieuw Databricks-project maken
In deze stap maakt u een nieuw Databricks-project en configureert u de verbinding met uw externe Azure Databricks werkruimte.
- Start Visual Studio Code en klik vervolgens op Bestand > Map openen en open een lege map op uw lokale ontwikkelcomputer.
- Klik op de zijbalk op het logopictogram van Databricks . Hiermee opent u de Databricks-extensie.
- Klik in de weergave Configuration op Configuratie maken.
- Het opdrachtpalet voor het configureren van uw Databricks-werkruimte wordt geopend. Voor Databricks Hostvoert u uw URL per werkruimte in of selecteert u deze, bijvoorbeeld
https://adb-1234567890123456.7.azuredatabricks.net. - Selecteer een verificatieprofiel voor het project. Zie Autorisatie instellen voor de Databricks-extensie voor Visual Studio Code.
Stap 2: clustergegevens toevoegen aan de Databricks-extensie en het cluster starten
Als de configuratieweergave al is geopend, klikt u op Selecteer een cluster of klikt u op het tandwielpictogram (Cluster configureren).
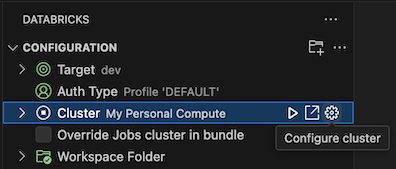
Selecteer in het opdrachtpaletde naam van het cluster dat u eerder hebt gemaakt.
Klik op het afspeelpictogram (Cluster starten) als dit nog niet is gestart.
Stap 3: Python code maken en uitvoeren
Maak een lokaal Python-codebestand: klik in de zijbalk op het mapicoon (Explorer).
Klik in het hoofdmenu op Bestand > Nieuw bestand en kies een Python bestand. Geef het bestand een naam demo.py en sla het op in de hoofdmap van het project.
Voeg de volgende code toe aan het bestand en sla deze vervolgens op. Met deze code wordt de inhoud van een eenvoudig PySpark-dataframe gemaakt en weergegeven:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Klik op het pictogram Uitvoeren op Databricks naast de lijst met editortabbladen en klik vervolgens op uploaden en uitvoeren van bestand. De uitvoer wordt weergegeven in de consoleweergave voor foutopsporing.
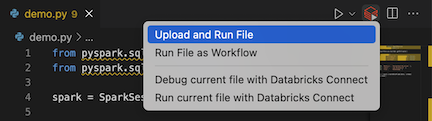
U kunt ook in de Verkenner-weergave met de rechtermuisknop op het bestand klikken en vervolgens "Uitvoeren op Databricks"
demo.py"Uploaden en Bestand Uitvoeren" > selecteren.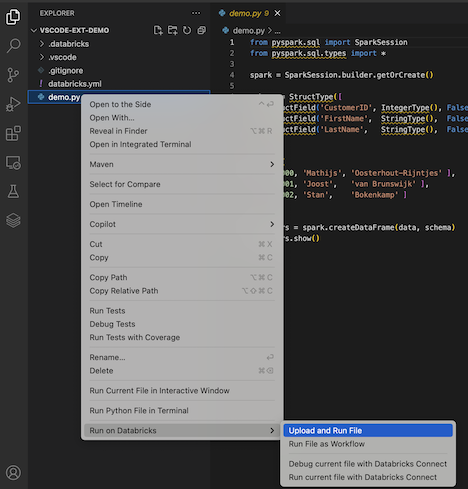
Stap 4: De code uitvoeren als een taak
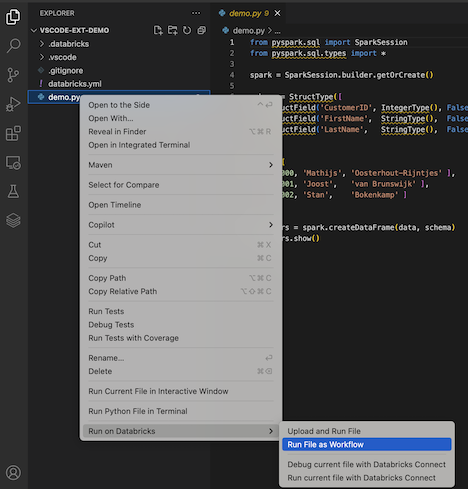
Als u demo.py als taak wilt uitvoeren, klikt u op het pictogram Uitvoeren op Databricks naast de lijst met editortabbladen en klikt u vervolgens op Bestand uitvoeren als werkstroom. De uitvoer wordt weergegeven op een afzonderlijk editortabblad naast de demo.py bestandseditor.
![]()
U kunt ook met de rechtermuisknop op het demo.py bestand klikken in het deelvenster Explorer en dan Uitvoeren op Databricks>Run File as Workflowselecteren.
Volgende stappen
Nu u de Databricks-extensie voor Visual Studio Code hebt gebruikt om een lokaal Python-bestand te uploaden en op afstand uit te voeren, kunt u ook het volgende doen:
- Verken de resources en variabelen van Declarative Automation Bundles met behulp van de gebruikersinterface van de extensie. Zie de functies van de extensie Declarative Automation Bundles.
- Voer Python code uit of debuggen met Databricks Connect. Zie Debug-code met behulp van Databricks Connect voor de Databricks-extensie voor Visual Studio Code.
- Voer een bestand of notebook uit als een Azure Databricks taak. Zie Een bestand uitvoeren op een cluster of een bestand of notitieblok als een taak in Azure Databricks met behulp van de Databricks-extensie voor Visual Studio Code.
- Voer tests uit met
pytest. Zie Run Python tests met behulp van de Databricks-extensie voor Visual Studio Code.