Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Databricks heeft meerdere hulpprogramma's en API's voor interactie met bestanden op de volgende locaties:
- Unity Catalog-volumes
- Werkruimtebestanden
- Cloudobjectopslag
- DBFS-koppelingen en DBFS-hoofdmap
- Tijdelijke opslag die is gekoppeld aan het stuurprogrammaknooppunt van het cluster
Dit artikel bevat voorbeelden voor interactie met bestanden op deze locaties voor de volgende hulpprogramma's:
- Apache Spark
- Spark SQL en Databricks SQL
- Hulpprogramma's voor bestandsysteem van Databricks (
dbutils.fsof%fs) - Databricks-CLI
- Databricks REST API
- Bash-shellopdrachten (
%sh) - Bibliotheekinstallaties met notebookbereik met behulp van
%pip - Pandas
- OSS Python-hulpprogramma's voor bestandsbeheer en -verwerking
Belangrijk
Sommige bewerkingen in Databricks, met name die gebruikmaken van Java- of Scala-bibliotheken, worden uitgevoerd als JVM-processen, bijvoorbeeld:
- Een afhankelijkheid van een JAR-bestand opgeven met behulp van
--jarsin Spark-configuraties - Het aanroepen van
catofjava.io.Filein Scala-notebooks - Aangepaste gegevensbronnen, zoals
spark.read.format("com.mycompany.datasource") - Bibliotheken die bestanden laden met behulp van Java
FileInputStreamofPaths.get()
Deze bewerkingen bieden geen ondersteuning voor lezen van of schrijven naar Unity Catalog-volumes of werkruimtebestanden met behulp van standaardbestandspaden, zoals /Volumes/my-catalog/my-schema/my-volume/my-file.csv. Als u toegang nodig hebt tot volumebestanden of werkruimtebestanden vanuit JAR-afhankelijkheden of op JVM gebaseerde bibliotheken, kopieert u eerst de bestanden om lokale opslag te berekenen met behulp van Python of %sh opdrachten, zoals %sh mv.. Gebruik %fs en dbutils.fs niet, die de JVM gebruiken. Als u bestanden wilt openen die al lokaal zijn gekopieerd, gebruikt u taalspecifieke opdrachten zoals Python shutil of %sh opdrachten. Als een bestand aanwezig moet zijn tijdens het starten van het cluster, gebruikt u een init-script om het bestand eerst te verplaatsen. Zie Wat zijn init-scripts?.
Moet ik een URI-schema opgeven voor toegang tot gegevens?
Paden voor gegevenstoegang in Azure Databricks volgen een van de volgende standaarden:
Paden in een URI-stijl moeten een URI-schema bevatten. Voor databricks-systeemeigen oplossingen voor gegevenstoegang zijn URI-schema's optioneel voor de meeste gebruiksvoorbeelden. Wanneer u rechtstreeks toegang hebt tot gegevens in de opslag van cloudobjecten, moet u het juiste URI-schema opgeven voor het opslagtype.
diagram met
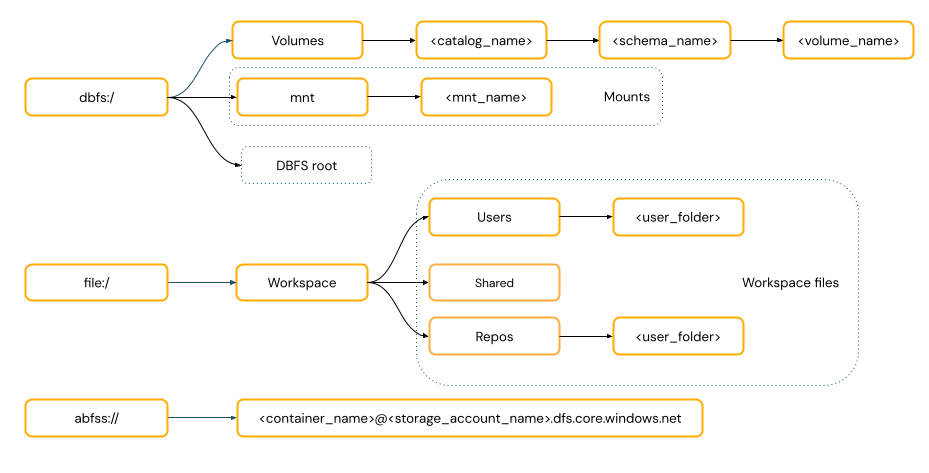
POSIX-paden bieden gegevenstoegang relatief aan de hoofdmap van het stuurprogramma (
/). POSIX-paden vereisen nooit een schema. U kunt Unity Catalog volumes of DBFS-mounts gebruiken om POSIX-stijl toegang te bieden tot gegevens in cloudobjectopslag. Voor veel ML-frameworks en andere OSS Python-modules is FUSE vereist en kunnen alleen PADEN in POSIX-stijl worden gebruikt.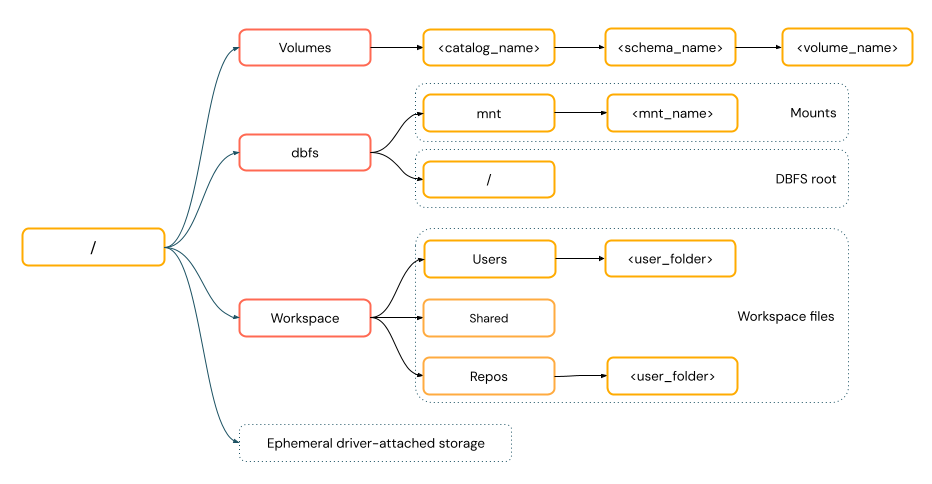
Notitie
Bestandsbewerkingen waarvoor FUSE-gegevenstoegang vereist, hebben geen rechtstreeks toegang tot cloudobjectopslag met behulp van URI's. Databricks raadt het gebruik van Unity Catalog-volumes aan om de toegang tot deze locaties voor FUSE te configureren.
Op berekeningen die zijn geconfigureerd met de toegewezen toegangsmodus (voorheen modus voor toegang tot één gebruiker) en Databricks Runtime 14.3 en hoger, ondersteunt Scala FUSE voor Unity Catalog-volumes en werkruimtebestanden, met uitzondering van subprocessen die afkomstig zijn van Scala, zoals de Scala-opdracht "cat /Volumes/path/to/file".!!.
Werken met bestanden in Unity Catalog-volumes
Databricks raadt het gebruik van Unity Catalog-volumes aan om toegang te configureren tot niet-tabellaire gegevensbestanden die zijn opgeslagen in cloudobjectopslag. Zie Werken met bestanden in Unity Catalog-volumes voor volledige documentatie over het beheren van bestanden in volumes, inclusief gedetailleerde instructies en best practices.
In de volgende voorbeelden ziet u algemene bewerkingen met behulp van verschillende hulpprogramma's en interfaces:
| Werktuig | Voorbeeld |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL en Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`;LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/")%fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks-CLI | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create{"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Bash-shellopdrachten | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Bibliotheekinstallaties | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| Open Source Software Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Zie Beperkingen voor het werken met bestanden in volumes voor informatie over volumesbeperkingen en tijdelijke oplossingen.
Werken met werkruimtebestanden
Databricks werkruimtebestanden zijn de bestanden in een werkruimte, die zijn opgeslagen in het werkruimteopslagaccount. U kunt werkruimtebestanden gebruiken om bestanden zoals notebooks, broncodebestanden, gegevensbestanden en andere werkruimteassets op te slaan en te openen.
Belangrijk
Omdat werkruimtebestanden groottebeperkingen hebben, raadt Databricks aan om hier alleen kleine gegevensbestanden op te slaan voor ontwikkeling en testen. Zie Bestandstypen voor aanbevelingen voor het opslaan van andere bestandstypen.
| Werktuig | Voorbeeld |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL en Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/")%fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks-CLI | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete{"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Bash-shellopdrachten | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Bibliotheekinstallaties | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| Open Source Software Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Notitie
Het file:/ schema is vereist bij het werken met Databricks Utilities, Apache Spark of SQL.
In werkruimten waarin de DBFS-root en mountpunten zijn uitgeschakeld, kunt u ook toegang krijgen dbfs:/Workspace tot werkruimtebestanden met Databricks-hulpprogramma's. Hiervoor is Databricks Runtime 13.3 LTS of hoger vereist. Zie Toegang tot DBFS-hoofdmap en -koppelingen uitschakelen in uw bestaande Azure Databricks-werkruimte.
Zie Beperkingenvoor de beperkingen in het werken met werkruimtebestanden.
Waar gaan verwijderde werkruimtebestanden naartoe?
Als u een werkruimtebestand verwijdert, wordt het naar de prullenbak verzonden. U kunt bestanden uit de prullenbak herstellen of permanent verwijderen met behulp van de gebruikersinterface.
Werken met bestanden in cloudobjectopslag
Databricks raadt het gebruik van Unity Catalog-volumes aan om beveiligde toegang tot bestanden in cloudobjectopslag te configureren. U moet machtigingen configureren als u ervoor kiest om rechtstreeks toegang te krijgen tot gegevens in de opslag van cloudobjecten met behulp van URI's. Zie Beheerde en externe volumes.
In de volgende voorbeelden worden URI's gebruikt voor toegang tot gegevens in de opslag van cloudobjecten:
| Werktuig | Voorbeeld |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL en Databricks SQL |
SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`;
LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path';
|
| Hulpprogramma's voor databricks-bestandssysteem |
dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/")
%fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/
|
| Databricks-CLI | Niet ondersteund |
| Databricks REST API | Niet ondersteund |
| Bash-shellopdrachten | Niet ondersteund |
| Bibliotheekinstallaties | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | Niet ondersteund |
| Open Source Software Python | Niet ondersteund |
Werken met bestanden in DBFS-koppelingen en DBFS-hoofdmap
Belangrijk
Zowel DBFS root als DBFS mounts zijn verouderd en worden niet aanbevolen door Databricks. Nieuwe accounts worden ingericht zonder toegang tot deze functies. Databricks raadt u aan om in plaats daarvan Unity Catalog-volumes, externe locaties of werkruimtebestanden te gebruiken.
| Werktuig | Voorbeeld |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL en Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("/mnt/path")%fs ls /mnt/path |
| Databricks-CLI | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Bash-shellopdrachten | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Bibliotheekinstallaties | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| Open Source Software Python | os.listdir('/dbfs/mnt/path/to/directory') |
Notitie
Het dbfs:/-schema is vereist bij het werken met de Databricks CLI.
Werken met bestanden in tijdelijke opslag die is gekoppeld aan het stuurprogrammaknooppunt
De tijdelijke opslag die is gekoppeld aan het stuurprogrammaknooppunt is blokopslag met ingebouwde op POSIX gebaseerde padtoegang. Alle gegevens die op deze locatie zijn opgeslagen, verdwijnen wanneer een cluster wordt beëindigd of opnieuw wordt opgestart.
| Werktuig | Voorbeeld |
|---|---|
| Apache Spark | Niet ondersteund |
| Spark SQL en Databricks SQL | Niet ondersteund |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("file:/path")%fs ls file:/path |
| Databricks-CLI | Niet ondersteund |
| Databricks REST API | Niet ondersteund |
| Bash-shellopdrachten | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Bibliotheekinstallaties | Niet ondersteund |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| Open Source Software Python | os.listdir('/path/to/directory') |
Notitie
Het file:/-schema is vereist bij het werken met Databricks Utilities.
Gegevens verplaatsen van tijdelijke opslag naar volumes
Mogelijk wilt u toegang krijgen tot gegevens die zijn gedownload of opgeslagen in tijdelijke opslag met behulp van Apache Spark. Omdat tijdelijke opslag is gekoppeld aan het stuurprogramma en Spark een gedistribueerde verwerkingsengine is, hebben niet alle bewerkingen hier rechtstreeks toegang tot gegevens. Stel dat u gegevens van het bestandssysteem van het stuurprogramma moet verplaatsen naar Unity Catalog-volumes. In dat geval kunt u bestanden kopiëren met behulp van magic-opdrachten of de Databricks-hulpprogramma's, zoals in de volgende voorbeelden:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>