Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Databricks-notebooks ondersteunen codeopmaak, automatisch aanvullen, meerdere talen en magic-opdrachten voor het ontwikkelen van code in Python, SQL, Scala en R.
Zie Navigate the Databricks notebook and file editorvoor meer informatie over geavanceerde functionaliteit die beschikbaar is in de editor, zoals automatisch aanvullen, variabele selectie, ondersteuning voor meerdere cursors en side-by-side diffs.
Wanneer u het notebook of de bestandseditor gebruikt, is Genie Code beschikbaar om u te helpen bij het genereren, uitleggen en opsporen van fouten in code. Zie Genie Code gebruiken voor meer informatie.
Databricks-notebooks bevatten ook een ingebouwd interactief foutopsporingsprogramma voor Python notebooks. Zie Fouten opsporen in Databricks-notebooks.
Belangrijk
Het notebook moet zijn gekoppeld aan een actieve compute sessie voor functies voor hulp bij code, waaronder automatisch aanvullen, Python codeopmaak en het foutopsporingsprogramma.
Uw code modulariseren
Met Databricks Runtime 11.3 LTS en hoger kunt u broncodebestanden maken en beheren in de Azure Databricks werkruimte en deze bestanden vervolgens naar wens importeren in uw notebooks.
Zie Code delen tussen Databricks-notebooks en Werk met Python- en R-modules voor meer informatie over het werken met broncodebestanden.
Codecellen opmaken
Azure Databricks biedt hulpprogramma's waarmee u Python en SQL-code in notebookcellen kunt opmaken. Deze hulpprogramma's verminderen de moeite om uw code geformatteerd te houden en om dezelfde coderingsstandaarden af te dwingen in uw notebooks.
Python zwarte formatterbibliotheek
Belangrijk
Deze functie is beschikbaar als openbare preview.
Azure Databricks ondersteunt Python codeopmaak met behulp van black in het notebook. Het notebook moet zijn gekoppeld aan een cluster met black en tokenize-rt Python-pakketten geïnstalleerd.
Op Databricks Runtime 11.3 LTS en hoger installeert het Azure Databricks vooraf black en tokenize-rt. U kunt de formatter rechtstreeks gebruiken zonder deze bibliotheken te hoeven installeren.
Op Databricks Runtime 10.4 LTS en hieronder moet u black==22.3.0 en tokenize-rt==4.2.1 installeren vanuit PyPI in uw notebook of cluster om de Python formatter te gebruiken. U kunt de volgende opdracht uitvoeren in uw notebook:
%pip install black==22.3.0 tokenize-rt==4.2.1
of installeer de bibliotheek op uw cluster.
Zie Python omgevingsbeheer voor meer informatie over het installeren van bibliotheken.
Voor bestanden en notebooks in Databricks Git-mappen kunt u de Python formatter configureren op basis van het bestand pyproject.toml. Als u deze functie wilt gebruiken, maakt u een pyproject.toml bestand in de hoofdmap van de Git-map en configureert u het volgens de black-configuratie-indeling. Bewerk de sectie [tool.black] in het bestand. De configuratie wordt toegepast wanneer u elk bestand en notitieblok in die Git-map formatteert.
Opmaak van Python en SQL-cellen
U moet de machtiging CAN EDIT voor het notitieblok hebben om code op te maken.
Azure Databricks maakt gebruik van een aangepaste SQL-formatter voor het opmaken van SQL en de black code formatter voor Python.
U kunt de formatter op de volgende manieren activeren:
Een enkele cel opmaken
- Sneltoets: Druk op Cmd+Shift+F.
- Opdrachtcontextmenu
- SQL-cel opmaken: selecteer Format SQL in het opdrachtencontextmenu van een SQL-cel. Dit menu-item is alleen zichtbaar in SQL Notebook-cellen of cellen met een
%sqltaalmagie. - Opmaak Python-cel: selecteer Opmaak Python in het opdrachtcontext-keuzemenu van een Python-cel. Dit menu-item is alleen zichtbaar in Python-notebookcellen of in cellen met een
%pythonlanguage magic.
- SQL-cel opmaken: selecteer Format SQL in het opdrachtencontextmenu van een SQL-cel. Dit menu-item is alleen zichtbaar in SQL Notebook-cellen of cellen met een
- Notebook Edit menu: Selecteer een Python of SQL-cel en selecteer vervolgens Bewerken > Cel(en).
Meerdere cellen opmaken
Selecteer meerdere cellen en selecteer > Cel(en) bewerken. Als u cellen van meer dan één taal selecteert, worden alleen SQL- en Python cellen opgemaakt. Dit omvat degenen die
%sqlen%pythongebruiken.Formatteer alle Python- en SQL-cellen in het notebook
Selecteer > BewerkenNotitieblok opmaken. Als uw notebook meer dan één taal bevat, worden alleen SQL- en Python cellen opgemaakt. Dit omvat degenen die
%sqlen%pythongebruiken.
Om aan te passen hoe uw SQL-query's zijn opgemaakt, zie Aangepaste opmaak van SQL-instructies.
Beperkingen van codeopmaak
- Black handhaaft de PEP 8-standaarden voor inspringen met vier spaties. Inspringing kan niet worden geconfigureerd.
- Het opmaken van ingesloten Python tekenreeksen in een SQL UDF wordt niet ondersteund. Op dezelfde manier wordt het opmaken van SQL-tekenreeksen binnen een Python UDF niet ondersteund.
Codetalen in notebooks
standaardtaal instellen
De standaardtaal voor het notitieblok wordt weergegeven onder de naam van het notitieblok.

Als u de standaardtaal wilt wijzigen, klikt u op de taalknop en selecteert u de nieuwe taal in de vervolgkeuzelijst. Om ervoor te zorgen dat bestaande opdrachten blijven werken, worden opdrachten van de vorige standaardtaal automatisch voorafgegaan door een taal-magische opdracht.
Talen combineren
Cellen gebruiken standaard de standaardtaal van het notitieblok. U kunt de standaardtaal in een cel overschrijven door op de taalknop te klikken en een taal te selecteren in de vervolgkeuzelijst.
U kunt ook het taal-magic commando %<language> aan het begin van een cel gebruiken. De ondersteunde magic-opdrachten zijn: %python, %r, %scalaen %sql.
Notitie
Wanneer u een magic-opdracht voor taal aanroept, wordt de opdracht verzonden naar de REPL in de uitvoeringscontext voor het notebook. Variabelen die zijn gedefinieerd in één taal (en dus in de REPL voor die taal) zijn niet beschikbaar in de REPL van een andere taal. REPLs kunnen alleen de status delen via externe bronnen, zoals bijvoorbeeld bestanden in DBFS of objecten in objectopslag.
Notebooks bieden ook ondersteuning voor een aantal aanvullende magic-opdrachten:
-
%sh: Hiermee kunt u shellcode uitvoeren in uw notebook. Als u de cel wilt laten falen wanneer de shell-opdracht een niet-nul afsluitstatus heeft, voegt u de-e-optie toe. Deze opdracht wordt alleen uitgevoerd op het Apache Spark-stuurprogramma en niet op de werkers. Als u een shell-opdracht wilt uitvoeren op alle knooppunten, gebruikt u een init-script. -
%fs: Hiermee kunt u bestandssysteemopdrachten gebruikendbutils. Als u bijvoorbeeld de opdrachtdbutils.fs.lswilt uitvoeren om bestanden weer te geven, kunt u in plaats daarvan%fs lsopgeven. Zie Werk met bestanden op Azure Databricks voor meer informatie. -
%md: Hiermee kunt u verschillende soorten documentatie opnemen, waaronder tekst, afbeeldingen en wiskundige formules en vergelijkingen. Bekijk de volgende sectie.
SQL-syntaxis markeren en automatisch aanvullen in Python opdrachten
Syntaxismarkering en SQL-autocomplete zijn beschikbaar wanneer u SQL binnen een Python opdracht gebruikt, zoals in een opdracht spark.sql.
Sql-celresultaten verkennen
In een Databricks-notebook worden resultaten van een SQL-taalcel automatisch beschikbaar gemaakt als een impliciet DataFrame dat is toegewezen aan de variabele _sqldf. U kunt deze variabele vervolgens gebruiken in alle Python en SQL-cellen die u later uitvoert, ongeacht hun positie in het notebook.
Notitie
Deze functie heeft de volgende beperkingen:
- De
_sqldfvariabele is niet beschikbaar in notebooks die gebruikmaken van een SQL-warehouse voor berekening. - Het gebruik van
_sqldfin volgende Python cellen wordt ondersteund in Databricks Runtime 13.3 en hoger. - Het gebruik
_sqldfin volgende SQL-cellen wordt alleen ondersteund in Databricks Runtime 14.3 en hoger. - Als de query gebruikmaakt van de trefwoorden
CACHE TABLEofUNCACHE TABLE, is de_sqldfvariabele niet beschikbaar.
In de onderstaande schermopname ziet u hoe _sqldf kan worden gebruikt in volgende Python en SQL-cellen:

Belangrijk
De variabele _sqldf wordt telkens opnieuw toegewezen wanneer een SQL-cel wordt uitgevoerd. Als u wilt voorkomen dat verwijzingen naar een specifiek DataFrame-resultaat verloren gaan, wijst u deze toe aan een nieuwe variabelenaam voordat u de volgende SQL-cel uitvoert:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
SQL-cellen parallel uitvoeren
Terwijl een opdracht wordt uitgevoerd en uw notebook is gekoppeld aan een interactief cluster, kunt u een SQL-cel tegelijk uitvoeren met de huidige opdracht. De SQL-cel wordt uitgevoerd in een nieuwe, parallelle sessie.
Een cel parallel uitvoeren:
Voer de cel uit.
Klik op Nu uitvoeren. De cel wordt onmiddellijk uitgevoerd.
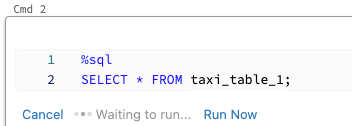
Omdat de cel wordt uitgevoerd in een nieuwe sessie, worden tijdelijke weergaven, UDF's en de implicit Python DataFrame (_sqldf) niet ondersteund voor cellen die parallel worden uitgevoerd. Daarnaast worden de standaardcatalogus- en databasenamen gebruikt tijdens parallelle uitvoering. Als uw code verwijst naar een tabel in een andere catalogus of database, moet u de tabelnaam opgeven met een naamruimte met drie niveaus (catalog.schema.table).
SQL-cellen uitvoeren in een SQL-warehouse
U kunt SQL-opdrachten uitvoeren in een Databricks-notebook in een SQL-warehouse, een type rekenproces dat is geoptimaliseerd voor SQL-analyses. Zie Een notebook gebruiken met een SQL-warehouse.
Magic-opdrachten gebruiken
Databricks-notebooks ondersteunen verschillende magic-opdrachten die functionaliteit uitbreiden buiten de standaardsyntaxis om algemene taken te vereenvoudigen. Lijnmagie wordt voorafgegaan door % en is van toepassing op één regel. Celmagics worden voorafgegaan door %% en zijn van toepassing op de gehele cel.
| Magische opdracht | Voorbeeld | Beschrijving |
|---|---|---|
%python |
%pythonprint("Hello") |
Schakel de celtaal over naar Python. Voert Python code uit in de cel. |
%r |
%rprint("Hello") |
Stel de celtaal in op R. Voert R-code uit in de cel. |
%scala |
%scalaprintln("Hello") |
Schakel de celtaal over naar Scala. Hiermee wordt Scala-code in de cel uitgevoerd. |
%sql |
%sqlSELECT * FROM table |
Schakel de celtaal over naar SQL. Resultaten zijn beschikbaar als _sqldf in Python/SQL-cellen. |
%md |
%md# TitleContent here |
Schakel de celtaal over naar Markdown. Hiermee wordt Markdown-inhoud in de cel weergegeven. Ondersteunt tekst, afbeeldingen, formules en LaTeX. |
%pip |
%pip install pandas |
Installeer Python pakketten (notebook-scoped). Zie Notebook-scoped Python bibliotheken. |
%run |
%run /path/to/notebook |
Voer een ander notebook uit, waarbij u de functies en variabelen importeert. Zie Notebook-werkstromen. |
%fs |
%fs ls /path |
Voer dbutils-bestandssysteemopdrachten uit. Afkorting voor dbutils.fs opdrachten. Zie Werken met bestanden. |
%sh |
%sh ls -la |
Voer shell-opdrachten uit. Wordt alleen uitgevoerd op het stuurprogrammaknooppunt. Gebruik -e om bij een fout te stoppen. |
%tensorboard |
%tensorboard --logdir /logs |
De TensorBoard-gebruikersinterface in de tekst weergeven. Alleen beschikbaar op Databricks Runtime ML. Zie TensorBoard. |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
Stel de maximale celuitvoergrootte in. Bereik: 1-20 MB. Is van toepassing op alle volgende cellen in notebook. |
%skip |
%skipprint("This won't run") |
Uitvoering van cellen overslaan. Hiermee voorkomt u dat de cel wordt uitgevoerd wanneer het notitieboek wordt uitgevoerd. |
%%profile |
%%profilemy_function() |
Profileren van de uitvoering van Python-code. Geeft een hiërarchische oproepstructuur weer met tijdsinstellingen. Vereist Databricks Runtime 17.2 en hoger. |
%%oprofile |
%%oprofilemy_function() |
Profielobject maken tijdens het uitvoeren van de cel. Geeft een tabel weer met nieuwe objecten die zijn gemaakt, gegroepeerd op type. Vereist Databricks Runtime 17.2 en hoger. |
%uv pip |
%uv pip install simplejson |
Installeer en beheer Python pakketten (notebook-scoped) met uv en standaard pip-subopdrachten (install, uninstall, list, show, freeze, check, tree). Zie snellere installaties met %uv pip. |
Notitie
IPython Automagic: Databricks-notebooks hebben IPython automatisch magisch standaard ingeschakeld, zodat bepaalde opdrachten werken zonder het pip% voorvoegsel. Werkt bijvoorbeeld pip install pandas hetzelfde als %pip install pandas.
Belangrijk
- Variabelen en statussen worden geïsoleerd tussen verschillende taal-REPL's. Python variabelen zijn bijvoorbeeld niet toegankelijk in Scala-cellen.
- Een notebookcel kan slechts één magic-opdracht bevatten. Deze opdracht moet de eerste regel van de cel zijn.
-
%runmoet in een aparte cel staan, omdat het hele notebook inline wordt uitgevoerd. - Wanneer u
%pipop Databricks Runtime 12.2 LTS en hieronder gebruikt, plaatst u alle pakketinstallatieopdrachten aan het begin van uw notebook, omdat de status Python na de installatie opnieuw wordt ingesteld.