Hoe biedt Databricks ondersteuning voor CI/CD voor machine learning?
CI/CD (continue integratie en continue levering) verwijst naar een geautomatiseerd proces voor het ontwikkelen, implementeren, bewaken en onderhouden van uw toepassingen. Door het bouwen, testen en implementeren van code te automatiseren, kunnen ontwikkelteams vaker en betrouwbaarder releases leveren dan handmatige processen die nog steeds voorkomen in veel data engineering- en data science-teams. CI/CD voor machine learning brengt technieken van MLOps, DataOps, ModelOps en DevOps samen.
In dit artikel wordt beschreven hoe Databricks CI/CD ondersteunt voor machine learning-oplossingen. In machine learning-toepassingen is CI/CD niet alleen belangrijk voor codeassets, maar wordt ook toegepast op gegevenspijplijnen, inclusief invoergegevens en de resultaten die door het model worden gegenereerd.
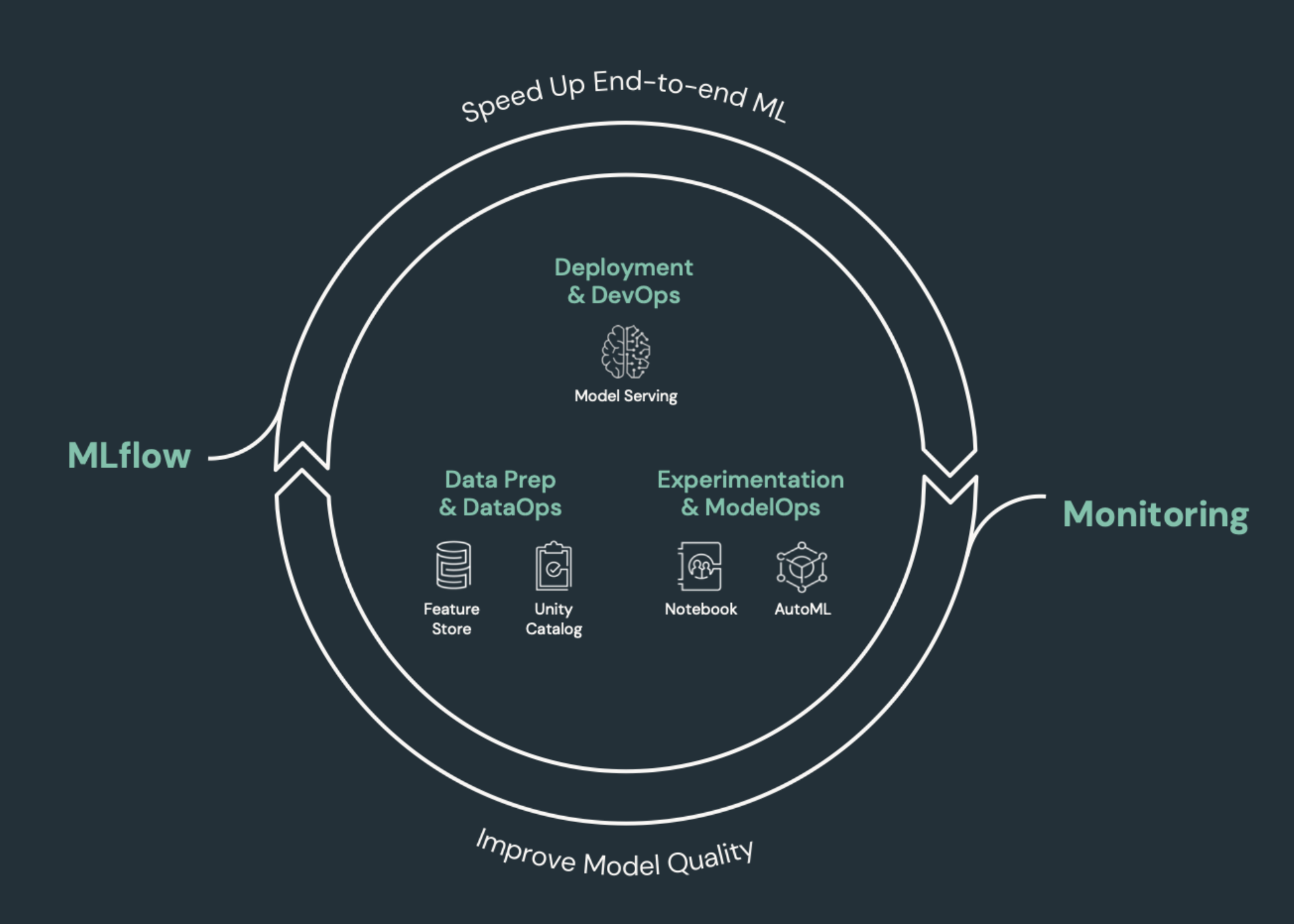
Machine learning-elementen die CI/CD nodig hebben
Een van de uitdagingen van ML-ontwikkeling is dat verschillende teams verschillende onderdelen van het proces bezitten. Teams kan afhankelijk zijn van verschillende hulpprogramma's en verschillende releaseschema's hebben. Azure Databricks biedt één geïntegreerd gegevens- en ML-platform met geïntegreerde hulpprogramma's om de efficiëntie van teams te verbeteren en consistentie en herhaalbaarheid van gegevens en ML-pijplijnen te garanderen.
Over het algemeen moet voor machine learning-taken het volgende worden bijgehouden in een geautomatiseerde CI/CD-werkstroom:
- Trainingsgegevens, waaronder gegevenskwaliteit, schemawijzigingen en distributiewijzigingen.
- Gegevenspijplijnen invoeren.
- Code voor het trainen, valideren en bedienen van het model.
- Modelvoorspellingen en prestaties.
Databricks integreren in uw CI/CD-processen
MLOps, DataOps, ModelOps en DevOps verwijzen naar de integratie van ontwikkelingsprocessen met 'bewerkingen', waardoor de processen en infrastructuur voorspelbaar en betrouwbaar worden. In deze set artikelen wordt beschreven hoe u bewerkingen ('ops')-principes integreert in uw ML-werkstromen op het Databricks-platform.
Databricks bevat alle onderdelen die vereist zijn voor de ML-levenscyclus, inclusief hulpprogramma's voor het bouwen van 'configuratie als code' om reproduceerbaarheid en infrastructuur als code te garanderen om het inrichten van cloudservices te automatiseren. Het bevat ook logboekregistratie- en waarschuwingsservices om u te helpen bij het detecteren en oplossen van problemen wanneer ze optreden.
DataOps: Betrouwbare en beveiligde gegevens
Goede ML-modellen zijn afhankelijk van betrouwbare gegevenspijplijnen en infrastructuur. Met het Databricks Data Intelligence Platform is de volledige gegevenspijplijn van het opnemen van gegevens naar de uitvoer van het aangeboden model op één platform en wordt dezelfde toolset gebruikt, waardoor productiviteit, reproduceerbaarheid, delen en probleemoplossing mogelijk zijn.

DataOps-taken en -hulpprogramma's in Databricks
De tabel bevat algemene DataOps-taken en -hulpprogramma's in Databricks:
| DataOps-taak | Hulpprogramma in Databricks |
|---|---|
| Gegevens opnemen en transformeren | Automatisch laden en Apache Spark |
| Wijzigingen in gegevens bijhouden, inclusief versiebeheer en herkomst | Delta-tabellen |
| Pijplijnen voor gegevensverwerking bouwen, beheren en bewaken | Delta Live-tabellen |
| Gegevensbeveiliging en -governance garanderen | Unity-catalogus |
| Verkennende gegevensanalyse en dashboards | Databricks SQL-, Dashboards- en Databricks-notebooks |
| Algemene codering | Databricks SQL - en Databricks-notebooks |
| Gegevenspijplijnen plannen | Databricks-taken |
| Algemene werkstromen automatiseren | Databricks-taken |
| Functies voor modeltraining maken, opslaan, beheren en ontdekken | Databricks Feature Store |
| Gegevensbewaking | Lakehouse Monitoring |
ModelOps: Modelontwikkeling en levenscyclus
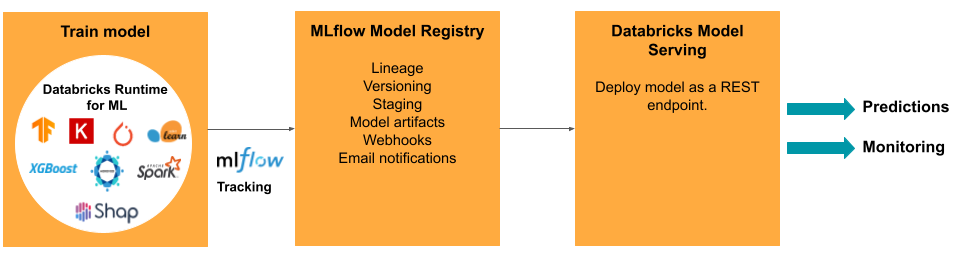
Het ontwikkelen van een model vereist een reeks experimenten en een manier om de voorwaarden en resultaten van deze experimenten bij te houden en te vergelijken. Het Databricks Data Intelligence Platform bevat MLflow voor het bijhouden van modelontwikkeling en het MLflow-modelregister voor het beheren van de levenscyclus van het model, waaronder fasering, het leveren en opslaan van modelartefacten.
Nadat een model is vrijgegeven voor productie, kunnen veel dingen veranderen die van invloed kunnen zijn op de prestaties. Naast het bewaken van de voorspellingsprestaties van het model, moet u ook invoergegevens controleren op wijzigingen in de kwaliteit of statistische kenmerken waarvoor het model mogelijk opnieuw moet worden getraind.
ModelOps-taken en -hulpprogramma's in Databricks
De tabel bevat algemene ModelOps-taken en -hulpprogramma's die worden geleverd door Databricks:
| ModelOps-taak | Hulpprogramma in Databricks |
|---|---|
| Ontwikkeling van traceringsmodellen | MLflow-modeltracking |
| Levenscyclus van modellen beheren | Modellen in Unity Catalog |
| Versiebeheer en delen van modelcode | Git-mappen in Databricks |
| Modelontwikkeling zonder code | Databricks AutoML |
| Modelbewaking | Lakehouse Monitoring |
DevOps: Productie en automatisering
Het Databricks-platform ondersteunt ML-modellen in productie met het volgende:
- End-to-end gegevens- en modelherkomst: Van modellen in productie terug naar de onbewerkte gegevensbron, op hetzelfde platform.
- Model op productieniveau: schaalt automatisch omhoog of omlaag op basis van de behoeften van uw bedrijf.
- Taken: Automatiseert taken en maakt geplande machine learning-werkstromen.
- Git-mappen: Met codeversiebeheer en delen vanuit de werkruimte kunnen teams ook de aanbevolen procedures voor software-engineering volgen.
- Databricks Terraform-provider: automatiseert de implementatie-infrastructuur in clouds voor ML-deductietaken, het leveren van eindpunten en featurization-taken.
Modellering
Voor het implementeren van modellen in productie vereenvoudigt MLflow het proces aanzienlijk, waardoor implementatie met één klik als batchtaak wordt geboden voor grote hoeveelheden gegevens of als EEN REST-eindpunt op een automatisch schalend cluster. De integratie van Databricks Feature Store met MLflow zorgt ook voor consistentie van functies voor training en bediening; MLflow-modellen kunnen ook automatisch functies opzoeken uit de Feature Store, zelfs voor online serveren met lage latentie.
Het Databricks-platform ondersteunt veel modelimplementatieopties:
- Code en containers.
- Batchverwerking.
- Online serveren met lage latentie.
- Serveren op het apparaat of de rand.
- Meerdere clouds trainen bijvoorbeeld het model in de ene cloud en implementeren met een andere cloud.
Zie Mosaic AI Model Serving voor meer informatie.
Projecten
Met Databricks-taken kunt u elk type workload automatiseren en plannen, van ETL naar ML. Databricks ondersteunt ook integraties met populaire orchestrators van derden , zoals Airflow.
Git-mappen
Het Databricks-platform bevat Git-ondersteuning in de werkruimte om teams te helpen best practices voor software-engineering te volgen door Git-bewerkingen uit te voeren via de gebruikersinterface. Beheerders en DevOps-technici kunnen API's gebruiken om automatisering in te stellen met hun favoriete CI/CD-hulpprogramma's. Databricks ondersteunt elk type Git-implementatie, inclusief privénetwerken.
Zie CI/CD-werkstromen met Git-integratie en Databricks Git-mappen en CI/CD gebruiken voor meer informatie over aanbevolen procedures voor het ontwikkelen van code met behulp van Databricks Git-mappen. Met deze technieken kunt u, samen met de Databricks REST API, geautomatiseerde implementatieprocessen bouwen met GitHub Actions, Azure DevOps-pijplijnen of Jenkins-taken.
Unity-catalogus voor governance en beveiliging
Het Databricks-platform bevat Unity Catalog, waarmee beheerders gedetailleerd toegangsbeheer, beveiligingsbeleid en governance kunnen instellen voor alle gegevens en AI-assets in Databricks.