Trainingscode beheren met MLflow-uitvoeringen
In dit artikel worden MLflow-uitvoeringen beschreven voor het beheren van machine learning-training. Het bevat ook richtlijnen voor het beheren en vergelijken van uitvoeringen in experimenten.
Een MLflow-uitvoering komt overeen met één uitvoering van modelcode. Elke uitvoering registreert de volgende informatie:
- Bron: Naam van het notebook dat de uitvoering heeft gestart of de projectnaam en het toegangspunt voor de uitvoering.
- Versie: Git commit-hash als notebook is opgeslagen in een Databricks Git-map of wordt uitgevoerd vanuit een MLflow-project. Anders wordt notitieblokrevisie bijgewerkt.
- Begin- en eindtijd: begin- en eindtijd van de uitvoering.
- Parameters: Modelparameters die zijn opgeslagen als sleutel-waardeparen. Zowel sleutels als waarden zijn tekenreeksen.
- Metrische gegevens: Metrische gegevens voor modelevaluatie die zijn opgeslagen als sleutel-waardeparen. De waarde is numeriek. Elke metriek kan tijdens de uitvoering worden bijgewerkt (bijvoorbeeld om bij te houden hoe de verliesfunctie van uw model wordt samengevoegd), en MLflow-records en kunt u de geschiedenis van de metrische gegevens visualiseren.
- Tags: Voer metagegevens uit die zijn opgeslagen als sleutel-waardeparen. U kunt tags bijwerken tijdens en nadat een uitvoering is voltooid. Zowel sleutels als waarden zijn tekenreeksen.
- Artefacten: Uitvoerbestanden in elke indeling. U kunt bijvoorbeeld afbeeldingen, modellen (bijvoorbeeld een pickled scikit-learn-model) en gegevensbestanden (bijvoorbeeld een Parquet-bestand) opnemen als artefact.
Alle MLflow-uitvoeringen worden geregistreerd bij het actieve experiment. Als u een experiment niet expliciet hebt ingesteld als het actieve experiment, worden uitvoeringen vastgelegd in het notebookexperiment.
Uitvoeringen weergeven
U kunt een uitvoering openen vanaf de bovenliggende experimentpagina of rechtstreeks vanuit het notebook waarmee de uitvoering is gemaakt.
Klik op de experimentpagina in de uitvoeringstabel op de begintijd van een uitvoering.
Klik in het notebook naast ![]() de datum en tijd van de uitvoering in de zijbalk Experimentuitvoeringen.
de datum en tijd van de uitvoering in de zijbalk Experimentuitvoeringen.
In het uitvoeringsscherm worden de parameters weergegeven die worden gebruikt voor de uitvoering, de metrische gegevens die voortvloeien uit de uitvoering en eventuele tags of notities. Als u notities, parameters, metrische gegevens of tags voor deze uitvoering wilt weergeven, klikt u![]() links van het label.
links van het label.
U hebt ook toegang tot artefacten die zijn opgeslagen tijdens een uitvoering in dit scherm.

Codefragmenten voor voorspelling
Als u een model bij een uitvoering aanmeldt, wordt het model weergegeven in de sectie Artefacten van deze pagina. Als u codefragmenten wilt weergeven die laten zien hoe u het model laadt en gebruikt om voorspellingen te doen op Spark- en Pandas DataFrames, klikt u op de naam van het model.

Het notebook of Git-project weergeven dat wordt gebruikt voor een uitvoering
De versie van het notebook weergeven waarmee een uitvoering is gemaakt:
- Klik op de experimentpagina op de koppeling in de kolom Bron .
- Klik op de uitvoeringspagina op de koppeling naast Bron.
- Klik in het notitieblok in de zijbalk experimentuitvoeringen op het notitieblokpictogram
 in het vak voor de uitvoering van het experiment.
in het vak voor de uitvoering van het experiment.
De versie van het notebook dat is gekoppeld aan de uitvoering wordt weergegeven in het hoofdvenster met een markeringsbalk met de datum en tijd van de uitvoering.
Als de uitvoering extern vanuit een Git-project is gestart, klikt u op de koppeling in het veld Git Commit om de specifieke versie van het project te openen dat in de uitvoering wordt gebruikt. De koppeling in het veld Bron opent de hoofdbranch van het Git-project dat in de uitvoering wordt gebruikt.
Een tag toevoegen aan een uitvoering
Tags zijn sleutel-waardeparen die u later kunt maken en gebruiken om te zoeken naar uitvoeringen.
Klik op de uitvoeringspagina
 als deze nog niet is geopend. De tabel tags wordt weergegeven.
als deze nog niet is geopend. De tabel tags wordt weergegeven.
Klik in de velden Naam en Waarde en typ de sleutel en waarde voor uw tag.
Klik op Toevoegen.
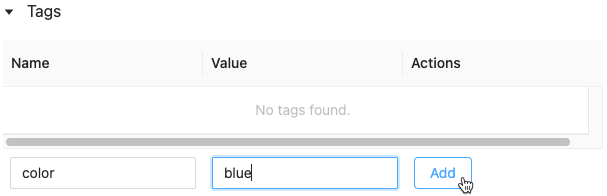
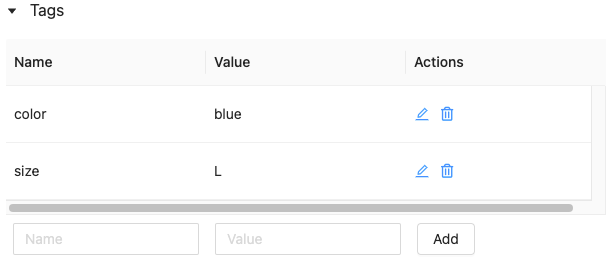
Een tag voor een uitvoering bewerken of verwijderen
Als u een bestaande tag wilt bewerken of verwijderen, gebruikt u de pictogrammen in de kolom Acties .
De softwareomgeving van een uitvoering reproduceren
U kunt de exacte softwareomgeving voor de uitvoering reproduceren door op Uitvoeren reproduceren te klikken. Het volgende dialoogvenster wordt weergegeven:

Met de standaardinstellingen klikt u op Bevestigen:
- Het notebook wordt gekloond naar de locatie die wordt weergegeven in het dialoogvenster.
- Als het oorspronkelijke cluster nog steeds bestaat, wordt het gekloonde notebook gekoppeld aan het oorspronkelijke cluster en wordt het cluster gestart.
- Als het oorspronkelijke cluster niet meer bestaat, wordt er een nieuw cluster met dezelfde configuratie, inclusief geïnstalleerde bibliotheken, gemaakt en gestart. Het notebook is gekoppeld aan het nieuwe cluster.
U kunt een andere locatie voor het gekloonde notebook selecteren en de clusterconfiguratie en geïnstalleerde bibliotheken inspecteren:
- Als u een andere map wilt selecteren om het gekloonde notitieblok op te slaan, klikt u op Map bewerken.
- Als u de clusterspecificatie wilt zien, klikt u op Specificatie weergeven. Als u alleen het notebook en niet het cluster wilt klonen, schakelt u deze optie uit.
- Als u wilt zien welke bibliotheken op het oorspronkelijke cluster zijn geïnstalleerd, klikt u op Bibliotheken weergeven. Als u niet wilt dat u dezelfde bibliotheken installeert als op het oorspronkelijke cluster, schakelt u deze optie uit.
Uitvoeringen beheren
Naam van uitvoering wijzigen
Als u de naam van een uitvoering wilt wijzigen, klikt u ![]() in de rechterbovenhoek van de uitvoeringspagina en selecteert u Naam wijzigen.
in de rechterbovenhoek van de uitvoeringspagina en selecteert u Naam wijzigen.
Filteruitvoeringen
U kunt zoeken naar uitvoeringen op basis van parameters of metrische waarden. U kunt ook zoeken naar uitvoeringen op tag.
Als u wilt zoeken naar uitvoeringen die overeenkomen met een expressie met parameter- en metrische waarden, voert u een query in het zoekveld in en klikt u op Zoeken. Enkele voorbeelden van querysyntaxis zijn:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Standaard worden metrische waarden gefilterd op basis van de laatst vastgelegde waarde. Met
MINofMAXkunt u zoeken naar uitvoeringen op basis van respectievelijk de minimum- of maximumwaarden voor metrische gegevens. Alleen uitvoeringen die na augustus 2024 zijn geregistreerd, hebben minimum- en maximumwaarden voor metrische gegevens.Als u wilt zoeken naar uitvoeringen op tag, voert u tags in de indeling in:
tags.<key>="<value>". Tekenreekswaarden moeten tussen aanhalingstekens worden geplaatst, zoals wordt weergegeven.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Zowel sleutels als waarden kunnen spaties bevatten. Als de sleutel spaties bevat, moet u deze in backticks plaatsen zoals wordt weergegeven.
tags.`my custom tag` = "my value"
U kunt uitvoeringen ook filteren op basis van hun status (actief of verwijderd) en op basis van of een modelversie aan de uitvoering is gekoppeld. Hiervoor selecteert u respectievelijk de vervolgkeuzelijsten Status en Tijd die u hebt gemaakt .
Uitvoeringen downloaden
Selecteer een of meer uitvoeringen.
Klik op CSV downloaden. Een CSV-bestand met de volgende velden wordt gedownload:
Run ID,Name,Source Type,Source Name,User,Status,<parameter1>,<parameter2>,...,<metric1>,<metric2>,...
Uitvoeringen verwijderen
U kunt uitvoeringen verwijderen met behulp van de Databricks Mosaic AI-gebruikersinterface met de volgende stappen:
- Selecteer in het experiment een of meer uitvoeringen door in het selectievakje links van de uitvoering te klikken.
- Klik op Verwijderen.
- Als de uitvoering een bovenliggende uitvoering is, moet u beslissen of u ook onderliggende uitvoeringen wilt verwijderen. Deze optie is standaard geselecteerd.
- Klik op Verwijderen om te bevestigen. Verwijderde uitvoeringen worden 30 dagen opgeslagen. Als u verwijderde uitvoeringen wilt weergeven, selecteert u Verwijderd in het veld Status.
Uitvoeringen voor bulksgewijs verwijderen op basis van de aanmaaktijd
U kunt Python gebruiken om uitvoeringen van een experiment dat is gemaakt vóór of bij een UNIX-tijdstempel bulksgewijs te verwijderen.
Met Databricks Runtime 14.1 of hoger kunt u de mlflow.delete_runs API aanroepen om uitvoeringen te verwijderen en het aantal verwijderde uitvoeringen te retourneren.
Hier volgen de mlflow.delete_runs parameters:
experiment_id: De id van het experiment met de uitvoeringen die moeten worden verwijderd.max_timestamp_millis: De maximale tijdstempel voor het maken in milliseconden sinds de UNIX-epoch voor het verwijderen van uitvoeringen. Alleen uitvoeringen die vóór of op deze tijdstempel zijn gemaakt, worden verwijderd.max_runs:Facultatief. Een positief geheel getal dat het maximum aantal uitvoeringen aangeeft dat moet worden verwijderd. De maximaal toegestane waarde voor max_runs is 10000. Als dit niet is opgegeven,max_runswordt standaard ingesteld op 10000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Met Databricks Runtime 13.3 LTS of eerder kunt u de volgende clientcode uitvoeren in een Azure Databricks Notebook.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Zie de DOCUMENTATIE van de Azure Databricks Experiments-API voor parameters en specificaties voor retourwaarden voor het verwijderen van uitvoeringen op basis van de aanmaaktijd.
Hersteluitvoeringen
U kunt eerder verwijderde uitvoeringen herstellen met behulp van de Databricks Mosaic AI-gebruikersinterface.
- Selecteer Op de pagina Experiment de optie Verwijderd in het veld Status om verwijderde uitvoeringen weer te geven.
- Selecteer een of meer uitvoeringen door in het selectievakje links van de uitvoering te klikken.
- Klik op Herstellen.
- Klik op Herstellen om te bevestigen. Als u de herstelde uitvoeringen wilt weergeven, selecteert u Actief in het veld Status.
Bulksgewijs herstellen wordt uitgevoerd op basis van de verwijderingstijd
U kunt Python ook gebruiken om bulksgewijs uitvoeringen te herstellen van een experiment dat is verwijderd op of na een UNIX-tijdstempel.
Met Databricks Runtime 14.1 of hoger kunt u de mlflow.restore_runs API aanroepen om uitvoeringen te herstellen en het aantal herstelde uitvoeringen te retourneren.
Hier volgen de mlflow.restore_runs parameters:
experiment_id: De id van het experiment met de uitvoeringen die moeten worden hersteld.min_timestamp_millis: De minimale tijdstempel voor verwijdering in milliseconden sinds de UNIX-epoch voor het herstellen van uitvoeringen. Alleen uitgevoerd die zijn verwijderd op of nadat deze tijdstempel is hersteld.max_runs:Facultatief. Een positief geheel getal dat het maximum aantal uitvoeringen aangeeft dat moet worden hersteld. De maximaal toegestane waarde voor max_runs is 10000. Als dit niet is opgegeven, wordt max_runs standaard ingesteld op 10000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Met Databricks Runtime 13.3 LTS of eerder kunt u de volgende clientcode uitvoeren in een Azure Databricks Notebook.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Zie de DOCUMENTATIE van de Azure Databricks Experiments-API voor parameters en specificaties voor retourwaarden voor het herstellen van uitvoeringen op basis van de verwijderingstijd.
Uitvoeringen vergelijken
U kunt uitvoeringen vergelijken vanuit één experiment of uit meerdere experimenten. De pagina Uitvoeringen vergelijken bevat informatie over de geselecteerde uitvoeringen in grafische en tabelvorm. U kunt ook visualisaties maken van uitvoeringsresultaten en tabellen met uitvoeringsinformatie, parameters en metrische gegevens.
Een visualisatie maken:
- Selecteer het tekentype (parallelcoördinatendiagram, spreidingsplot of contourdiagram).
Selecteer de parameters en metrische gegevens die u wilt uitzetten voor een plot van parallelle coördinaten. Hier kunt u relaties tussen de geselecteerde parameters en metrische gegevens identificeren, zodat u de afstemmingsruimte voor hyperparameters voor uw modellen beter kunt definiëren.

Voor een spreidingsplot of contourdiagram selecteert u de parameter of metrische waarde die op elke as moet worden weergegeven.
In de tabellen Parameters en Metrische gegevens worden de uitvoeringsparameters en metrische gegevens van alle geselecteerde uitvoeringen weergegeven. De kolommen in deze tabellen worden geïdentificeerd door de tabel Details uitvoeren direct erboven. Ter vereenvoudiging kunt u parameters en metrische gegevens verbergen die identiek zijn in alle geselecteerde uitvoeringen door te schakelen  .
.

Uitvoeringen van één experiment vergelijken
- Selecteer op de experimentpagina twee of meer uitvoeringen door in het selectievakje links van de uitvoering te klikken of alle uitvoeringen te selecteren door het selectievakje boven aan de kolom in te schakelen.
- Klik op Vergelijken. Het scherm Uitvoeringen vergelijken
<N>wordt weergegeven.
Uitvoeringen van meerdere experimenten vergelijken
- Selecteer op de pagina experimenten de experimenten die u wilt vergelijken door in het vak links van de naam van het experiment te klikken.
- Klik op Vergelijken (n) (n is het aantal experimenten dat u hebt geselecteerd). Er wordt een scherm weergegeven met alle uitvoeringen van de experimenten die u hebt geselecteerd.
- Selecteer twee of meer uitvoeringen door in het selectievakje links van de uitvoering te klikken of selecteer alle uitvoeringen door het selectievakje boven aan de kolom in te schakelen.
- Klik op Vergelijken. Het scherm Uitvoeringen vergelijken
<N>wordt weergegeven.
Uitvoeringen kopiëren tussen werkruimten
Als u MLflow-uitvoeringen wilt importeren of exporteren naar of vanuit uw Databricks-werkruimte, kunt u het door de community gestuurde opensource-project MLflow Export-Import gebruiken.