Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Op deze pagina worden de opties voor rekenresources van notebooks beschreven. U kunt een notebook uitvoeren op een rekenresource voor alle doeleinden, serverloze berekeningen of, voor SQL-opdrachten, kunt u een SQL-warehouse gebruiken, een type rekenproces dat is geoptimaliseerd voor SQL-analyses. Zie Compute voor meer informatie over rekentypen.
Standaard berekenen
In werkruimten die zijn ingeschakeld voor Unity Catalog, worden nieuwe notebooks standaard ingesteld op serverloze berekeningen. Als u geen rekenresource handmatig selecteert en een cel uitvoert, maakt het notebook automatisch verbinding met serverloze berekeningen.
Berekening automatisch koppelen
In uw ontwikkelaarsinstellingen kunt u notebooks configureren om automatisch te koppelen aan een rekenresource en een sessie te starten wanneer u met de editor werkt:
Klik linksboven op het gebruikerspictogram.
Klik op Instellingen.
Klik op Ontwikkelaars om naar uw instellingen voor ontwikkelaars te gaan.
In-/uitschakelen op Sessie automatisch maken bij interactie van editor om automatisch een rekensessie te starten bij interactie met de editor. Databricks is standaard ingesteld op een rekenresource op basis van uw voorkeuren (serverloos of SQL Warehouse) en de laatste gebruikte rekenresource.
OR
Schakel deze instelling uit als u niet wilt dat het notebook automatisch verbinding maakt en een rekenresource start.
Voor functies voor codeondersteuning, waaronder automatisch aanvullen, codeopmaak en het foutopsporingsprogramma, moet het notebook worden gekoppeld aan een actieve rekensessie. Als het notebook geen rekensessie heeft gestart, zijn functies voor codeondersteuning inactief.
Serverloze rekenkracht voor notebooks
Met serverless computing kunt u uw notebook snel verbinden met on-demand computing-resources.
Als u wilt koppelen aan de serverloze berekening, klikt u op de vervolgkeuzelijst compute in het notebook en selecteert u Serverloos.
Zie Serverloze verwerking voor notebooks voor meer informatie.
Automatisch sessieherstel voor serverloze notebooks
Beëindiging van inactieve processen van serverloze berekeningen kan ertoe leiden dat u bezig zijnde werk verliest, zoals waarden van Python-variabelen, in uw notebooks. U kunt dit voorkomen door automatische sessieherstel in te schakelen voor serverloze notebooks.
- Klik op uw gebruikersnaam in de rechterbovenhoek van uw werkruimte en klik vervolgens op Instellingen in de vervolgkeuzelijst.
- Selecteer Developerin de zijbalk Instellingen.
- Schakel onder Experimentele functies de optie Automatisch sessieherstel in voor de instelling voor serverloze notebooks .
Als u deze instelling inschakelt, kan Databricks een momentopname maken van de geheugenstatus van het serverloze notebook voordat deze wordt beëindigd. Wanneer u terugkeert naar een notitieblok nadat de verbinding is verbroken, wordt boven aan de pagina een banner weergegeven. Klik op Opnieuw verbinding maken om de werkstatus te herstellen.
Wanneer u opnieuw verbinding maakt, wordt in Databricks uw volledige werkomgeving hersteld, waaronder:
- Python variabelen, functies en klassedefinities: Python status wordt verwerkt met pickle/cloudpickle en hersteld in een nieuwe REPL, zodat u deze niet opnieuw hoeft te importeren of opnieuw hoeft te declareren.
- Spark DataFrames, cacheweergaven en tijdelijke weergaven: gegevens die u hebt geladen, getransformeerd of in de cache opgeslagen (inclusief tijdelijke weergaven), zodat u kostbare herlaad- of hercomputatie vermijdt.
- Spark-sessiestatus: configuratie-instellingen op Spark-niveau, tijdelijke weergaven, cataloguswijzigingen en door de gebruiker gedefinieerde functies (UDF's) worden hersteld via spark Connect-sessiemigratie, zodat u ze niet opnieuw hoeft in te stellen.
Als de omgeving zodanig is gewijzigd dat deserialisatie onveilig wordt, bijvoorbeeld incompatibele Python of pakketversies, wordt de momentopname ongeldig gemaakt en valt het notebook terug op een nieuwe sessie.
Opslag van momentopnamegegevens
Momentopnamegegevens worden opgeslagen in de standaardopslag van uw werkruimte. In het notebook zelf worden alleen metagegevens opgeslagen, inclusief een aanwijzer met de notebook-id, een tijdstempel en sessiegegevens. De nettolading van de gegevens wordt niet opgeslagen in het notebook. Blobpaden worden versleuteld voordat ze worden opgeslagen in notebookkenmerken en momentopnamepaden worden uitgesloten van het exporteren en importeren van notebooks om te voorkomen dat de status wordt hersteld in een andere werkruimte.
Momentopnamen volgen de TTL-standaardinstellingen voor cloudopslag (ongeveer één maand) en verlopen automatisch. Als u een notebook verwijdert, worden ook de momentopnamen verwijderd. Voor uw cloudaccount worden opslagkosten in rekening gebracht als onderdeel van het standaardopslaggebruik van de werkruimte. De functie maakt gebruik van Python processerialisatie in plaats van controlepunten op containerniveau, waardoor momentopnamen kleiner en sneller worden gemaakt.
Beveiliging en toegangsbeheer
Herstel van momentopnamen respecteert notitieblokmachtigingen. Voor het herstellen van de status is de RUN-machtiging voor het notebook vereist. Met versleutelde metagegevens kunnen kijkers geen momentopname-blobs rechtstreeks ophalen en worden machtigingscontroles afgedwongen bij het herstellen.
Beperkingen
Deze functie heeft beperkingen en biedt geen ondersteuning voor het herstellen van het volgende:
- Spark-statussen ouder dan 4 dagen
- Spark-statussen groter dan 50 MB
- Gegevens met betrekking tot SQL-scripts
- Bestandsingangen
- Vergrendelingen en andere gelijktijdigheidsprimitieven
- Netwerkverbindingen
een notebook koppelen aan een rekenresource voor alle doeleinden
Als u een notebook wilt koppelen aan een rekenresource voor alle doeleinden, hebt u de KAN KOPPELEN AAN machtiging voor de rekenresource.
Belangrijk
Zolang een notebook is gekoppeld aan een rekenresource, heeft elke gebruiker met de machtiging KAN UITVOEREN op het notebook impliciete machtigingen om toegang te krijgen tot de rekenresource.
Als u een notebook wilt koppelen aan een rekenresource, klikt u op de rekenkiezer op de werkbalk van het notitieblok en selecteert u de resource in de vervolgkeuzelijst.
In het menu ziet u een selectie van alle reken- en SQL-warehouses die u onlangs hebt gebruikt of die momenteel worden uitgevoerd.

Als u een keuze wilt maken uit alle beschikbare berekeningen, klikt u op Meer.... Selecteer een van de beschikbare algemene reken- of SQL-magazijnen.
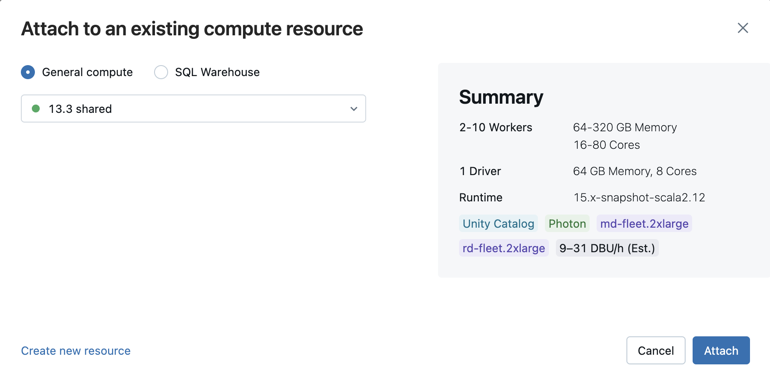
U kunt ook een nieuwe rekenresource voor alle doeleinden maken door nieuwe resource maken te selecteren... in de vervolgkeuzelijst.
Belangrijk
Voor een gekoppeld notebook zijn de volgende Apache Spark-variabelen gedefinieerd.
| Klasse | Variabelenaam |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Maak geen SparkSession, SparkContext of SQLContext. Dit leidt tot inconsistent gedrag.
Een notebook gebruiken met een SQL-warehouse
Wanneer een notebook is gekoppeld aan een SQL-warehouse, kunt u SQL- en Markdown-cellen uitvoeren. Als u een cel uitvoert in een andere taal (zoals Python of R), treedt er een fout op. SQL-cellen die worden uitgevoerd op een SQL-magazijn, worden weergegeven in de querygeschiedenis van het SQL-warehouse. De gebruiker die een query heeft uitgevoerd, kan het queryprofiel uit het notebook bekijken door te klikken op het verstreken tijdstip onderaan de uitvoer.
Notebooks die zijn gekoppeld aan SQL Warehouses ondersteunen SQL Warehouse-sessies, waar u variabelen kunt definiëren, tijdelijke weergaven kunt maken en de status kunt behouden voor meerdere queryuitvoeringen. U kunt SQL-logica iteratief bouwen zonder dat u alle instructies tegelijk hoeft uit te voeren. Zie Wat zijn SQL Warehouse-sessies?
Voor het uitvoeren van een notebook is een pro- of serverloze SQL-warehouse vereist. U moet toegang hebben tot de werkruimte en het SQL-warehouse.
Ga als volgt te werk om een notebook toe te voegen aan een SQL Warehouse :
Klik op de rekenkiezer op de werkbalk van het notitieblok. In de vervolgkeuzelijst ziet u rekenresources die momenteel worden uitgevoerd of die u onlangs hebt gebruikt. SQL-magazijnen zijn gemarkeerd met
 .
.Selecteer een SQL Warehouse in het menu.
Als u alle beschikbare SQL-magazijnen wilt zien, selecteert u Meer... in de vervolgkeuzelijst. Er wordt een dialoogvenster weergegeven met rekenresources die beschikbaar zijn voor het notebook. Selecteer SQL Warehouse, selecteer het magazijn dat u wilt gebruiken en klik op Bijvoegen.
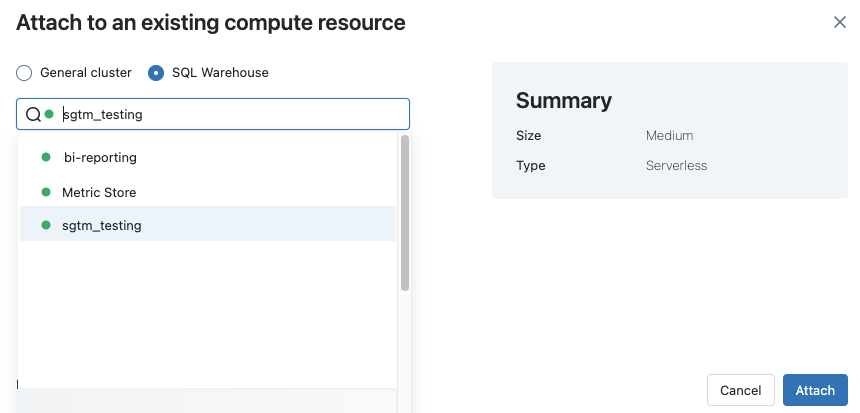
U kunt ook een SQL Warehouse selecteren als de rekenresource voor een SQL-notebook wanneer u een werkstroom of geplande taak maakt.
Beperkingen van SQL Warehouse
Zie Bekende beperkingen van Databricks-notebooks voor meer informatie.