Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Nadat u een notebook aan een cluster hebt gekoppeld en een of meer cellen hebt uitgevoerd, heeft uw notebook een status en wordt de uitvoer weergegeven. In deze sectie wordt beschreven hoe u de status en uitvoer van het notitieblok beheert.
De status en uitvoer van notitieblokken resetten
Als u de status en uitvoer van het notitieblok wilt wissen, selecteert u een van de opties onderaan het menu 'Uitvoeren'.
| Menuoptie | Beschrijving |
|---|---|
| Alle celuitvoer wissen | Wist de uitvoer van de cel. Dit is handig als u het notitieblok deelt en geen resultaten wilt opnemen. |
| Toestand wissen | Hiermee wordt de status van het notebook gewist, inclusief functie- en variabeledefinities, data en geïmporteerde bibliotheken. |
| Status en uitvoer wissen | Hiermee worden de uitvoer van de cellen en de status van de notebook gewist. |
| Status opnieuw instellen en alles uitvoeren | Hiermee wist u de status van de notebook en start u een nieuwe sessie. |
Resultatentabel
Wanneer een cel wordt uitgevoerd, worden de resultaten weergegeven in een resultaten tabel. Met de resultatentabel kunt u het volgende doen:
- Kopieer een kolom of een andere subset met tabelgegevens naar het klembord.
- Een tekstzoekactie uitvoeren op de resultatentabel.
- Gegevens sorteren en filteren.
- Navigeren tussen tabelcellen met behulp van de pijltoetsen op het toetsenbord.
- Selecteer een deel van een kolomnaam of celwaarde door te dubbelklikken en te slepen om de gewenste tekst te selecteren.
- Gebruik kolomverkenner om kolommen te zoeken, weer te geven of te verbergen, vast te maken en opnieuw te rangschikpen.
resultatentabel van de notebook 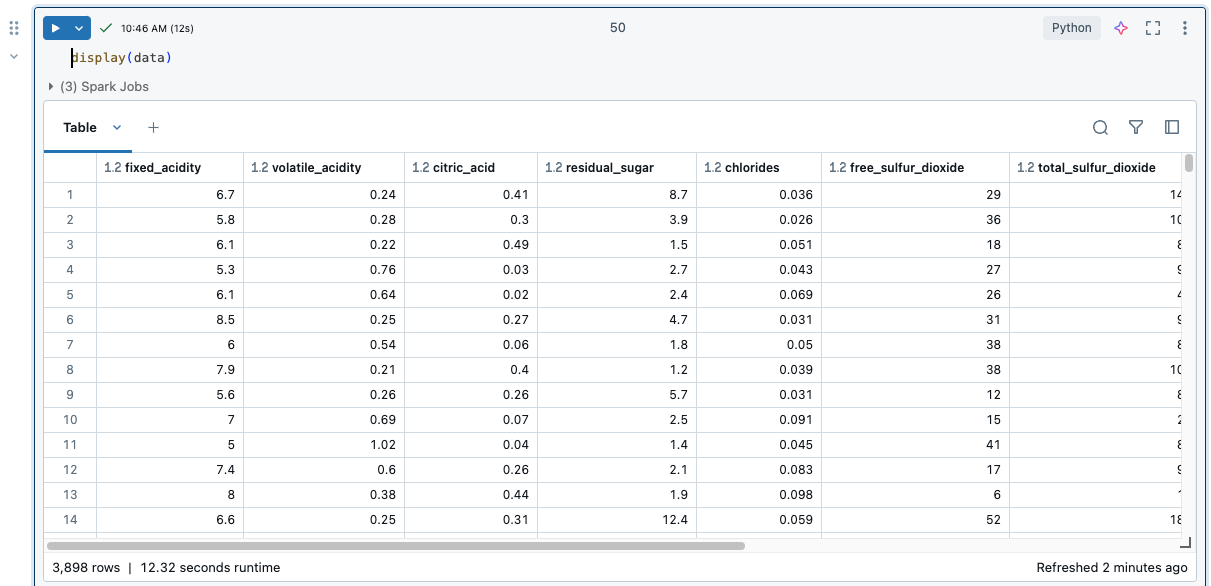
Zie limieten voor de resultatentabel van de notebook om limieten op de resultatentabel te bekijken.
Gegevens selecteren
Ga op een van de volgende manieren te werk om gegevens in de resultatentabel te selecteren.
- Kopieer de gegevens of een subset van de gegevens naar het klembord.
- Klik op een kolom- of rijkop.
- Klik in de cel linksboven in de tabel om de hele tabel te selecteren.
- Sleep de cursor over een willekeurige set cellen om deze te selecteren.
- Als u meerdere kolommen wilt selecteren, houdt u Ctrl (Windows) of Cmd (macOS) ingedrukt en klikt u op extra kolomkoppen. Vervolgens kunt u acties zoals kopiëren, filteren, opmaken en vastmaken aan alle geselecteerde kolommen tegelijk toepassen met behulp van het

Als u een zijpaneel met selectiegegevens wilt openen, klikt u op het ![]() in de rechterbovenhoek, naast het zoekvak.
in de rechterbovenhoek, naast het zoekvak.
![]()
Gegevens kopiëren naar klembord
Als u de resultatentabel in CSV-indeling naar het klembord wilt kopiëren, klikt u op de pijl-omlaag naast het tabblad Tabeltitel en klikt u vervolgens op Resultaten naar klembord kopiëren.
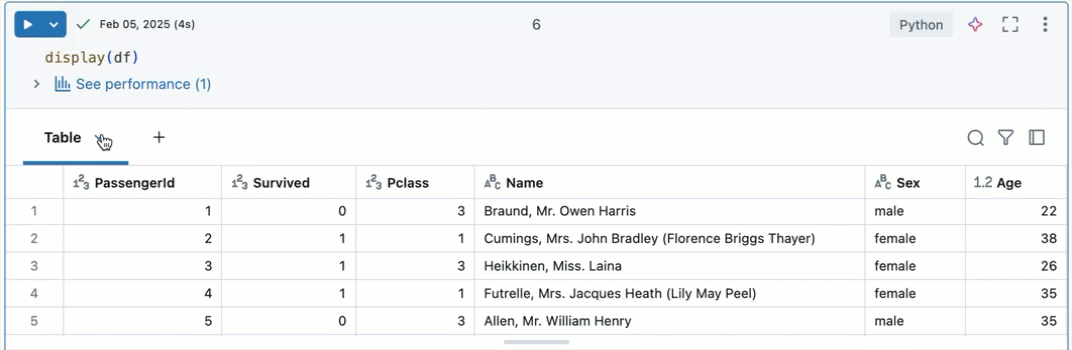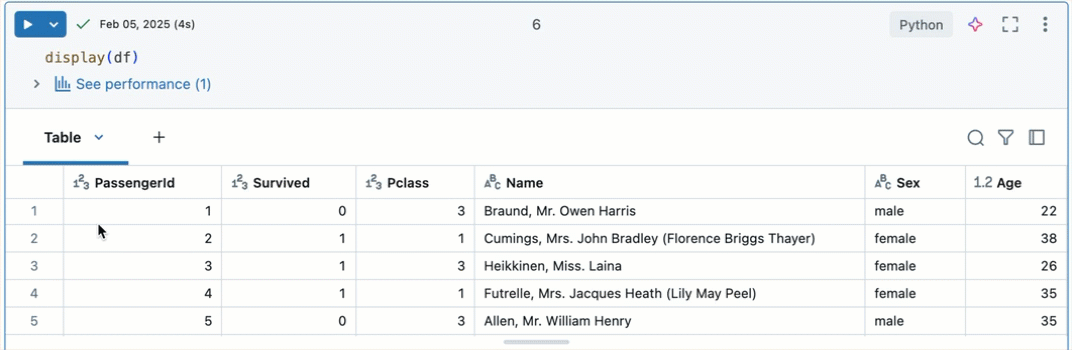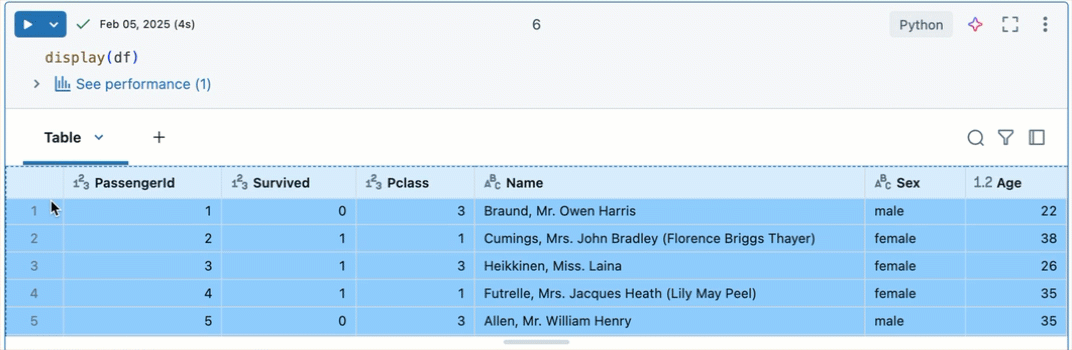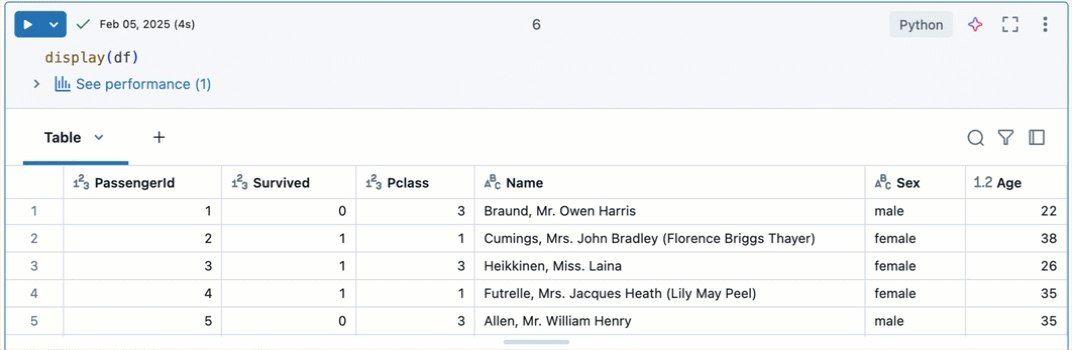
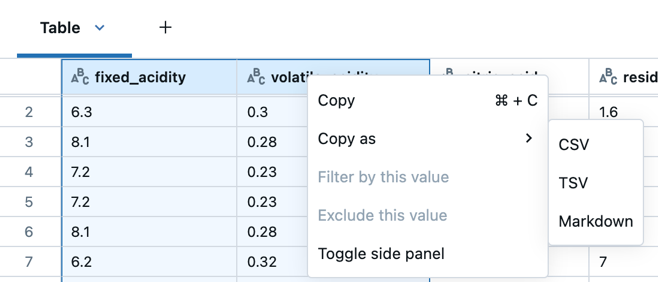
U kunt ook op het vak in de linkerbovenhoek van de tabel klikken om de volledige tabel te selecteren en vervolgens met de rechtermuisknop klikken en Kopiëren selecteren in het uitklapmenu.
Er zijn verschillende manieren om geselecteerde gegevens te kopiëren:
- Druk op
Cmd + Cop MacOS ofCtrl + Cop Windows om de resultaten naar het klembord in CSV-indeling te kopiëren. - Klik met de rechtermuisknop en selecteer Kopiëren om de resultaten naar het klembord in CSV-formaat te kopiëren.
- Klik met de rechtermuisknop en selecteer Kopiëren als om de geselecteerde gegevens te kopiëren in csv-, TSV- of Markdown-indeling.
Resultaten sorteren
Als u de resultatentabel wilt sorteren op de waarden in een kolom, plaatst u de cursor boven de kolomnaam. Rechts van de cel wordt een pictogram met de kolomnaam weergegeven. Klik op de pijl om de kolom te sorteren.
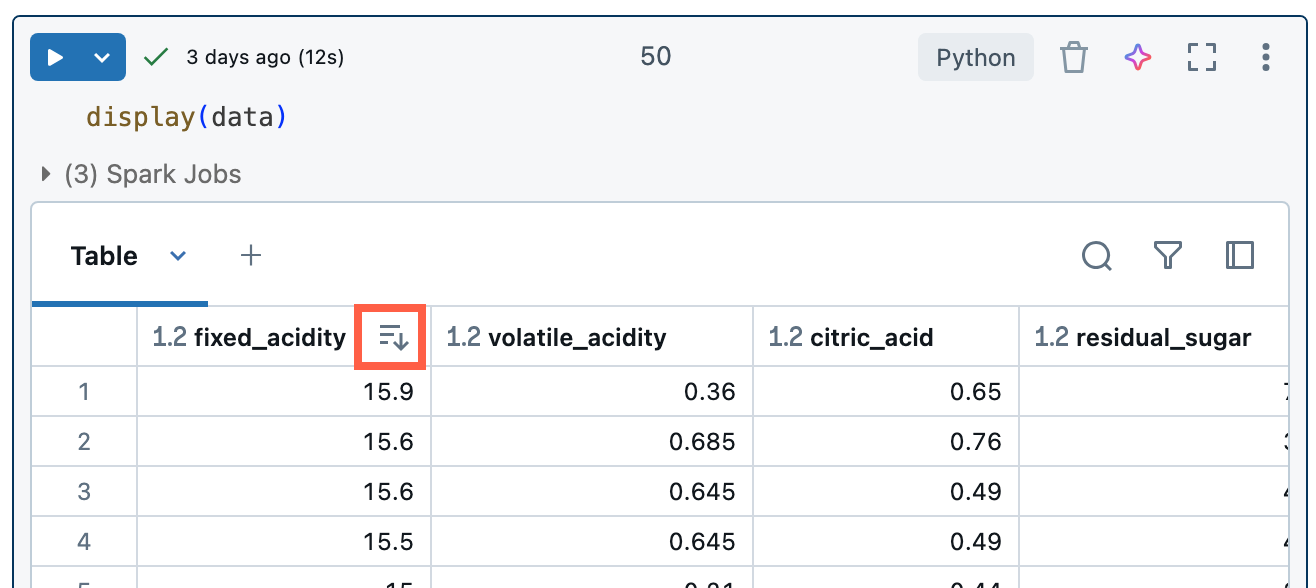
Als u op meerdere kolommen wilt sorteren, houdt u de Shift-toets ingedrukt terwijl u op de sorteerpijl voor de kolommen klikt.
Sorteren volgt standaard de natuurlijke sorteervolgorde. Als u een lexicografische sorteervolgorde wilt afdwingen, gebruikt u ORDER BY in SQL of de respectieve SORT functies die beschikbaar zijn in uw omgeving.
Resultaten filteren
Gebruik filters in een resultatentabel om de gegevens nader te bekijken. Filters die worden toegepast op resultaattabellen zijn ook van invloed op visualisaties, waardoor interactieve verkenning mogelijk is zonder de onderliggende query of gegevensset te wijzigen. Zie Een visualisatie filteren.
Er zijn verschillende manieren om een filter te maken:
Databricks Assistent
Vragen in natuurlijke taal gebruiken met Assistent
Filters maken met behulp van prompts voor natuurlijke taal:
- Klik op
 rechtsboven in de celresultaten.
rechtsboven in de celresultaten. - Voer in het dialoogvenster dat wordt weergegeven tekst in waarmee het gewenste filter wordt beschreven.
- Klik op
 . Genie Code genereert en past het filter voor u toe.
. Genie Code genereert en past het filter voor u toe.
Als u extra filters wilt maken met Assistent, klikt u op het ![]() Klik naast de filter(en) om een andere prompt in te voeren.
Klik naast de filter(en) om een andere prompt in te voeren.
Zie gegevens filteren met prompts voor natuurlijke taal.
Dialoogvenster Filter
Het ingebouwde filterdialoogvenster gebruiken
- Als u Genie Code niet hebt ingeschakeld, klikt u op Klik rechtsboven in de celresultaten om het filterdialoogvenster te openen. U kunt dit dialoogvenster ook openen door op de
 te klikken.
te klikken. - Selecteer de kolom die u wilt filteren.
- Selecteer de filterregel die u wilt toepassen.
- Selecteer de waarde(s) die u wilt filteren.
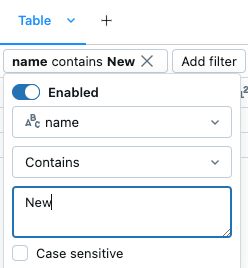
Op waarde
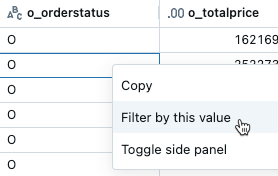
Filteren op een specifieke waarde
- Klik in de resultatentabel met de rechtermuisknop op een cel met die waarde.
- Selecteer Filteren op deze waarde in de vervolgkeuzelijst.
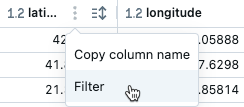
Per kolom
Filteren op een specifieke kolom
- Beweeg de muisaanwijzer over de kolom waarop u wilt filteren.
- Klik op .
- Klik op Filteren.
- Selecteer de waarden waarvoor u wilt filteren.
Als u een filter tijdelijk wilt in- of uitschakelen, klikt u op de knop Ingeschakeld/Uitgeschakeld in het dialoogvenster.
Als u een filter wilt verwijderen, klikt u op ![]() Klik naast filternaam
Klik naast filternaam  .
.
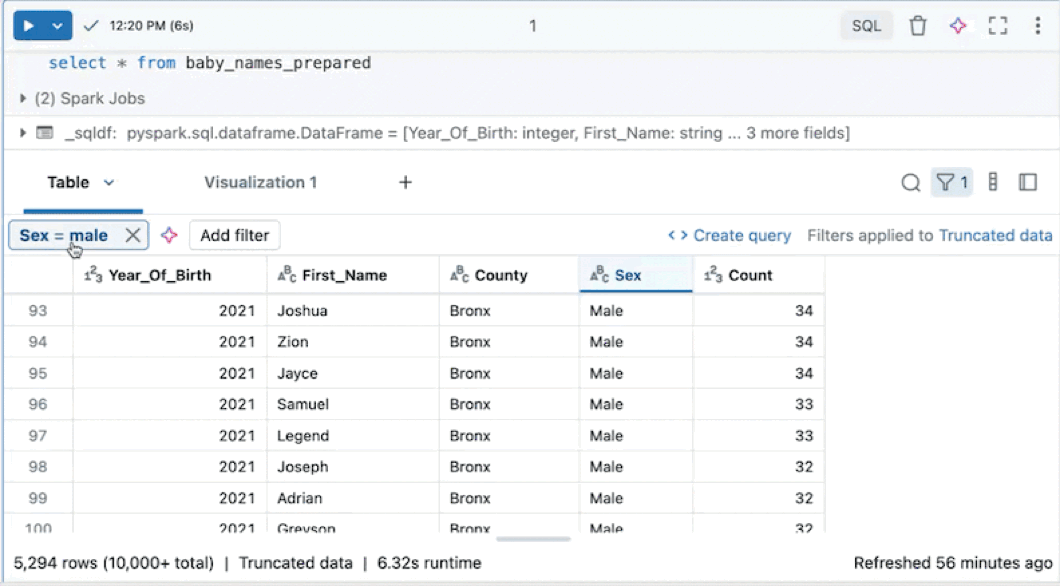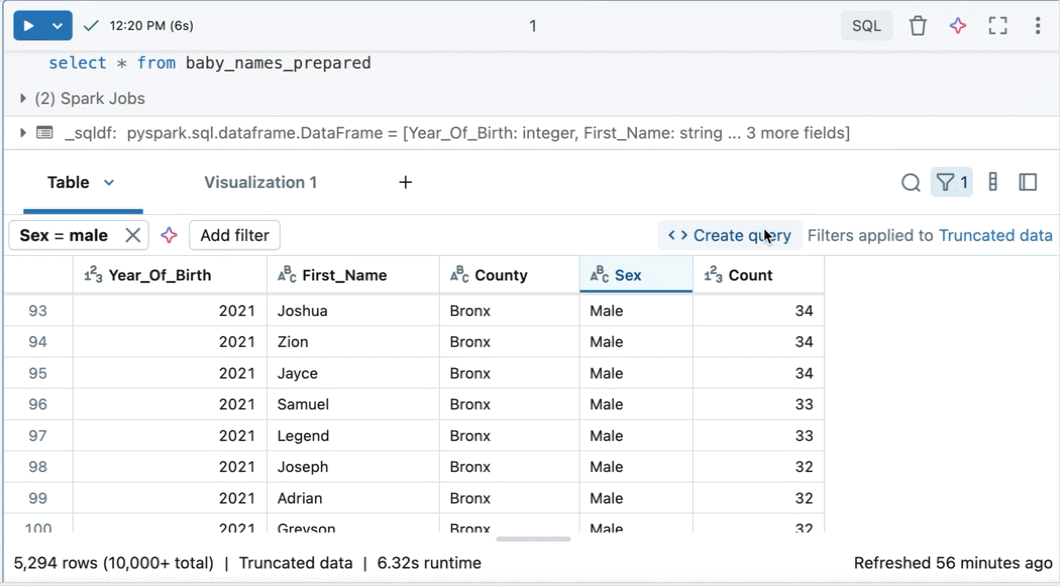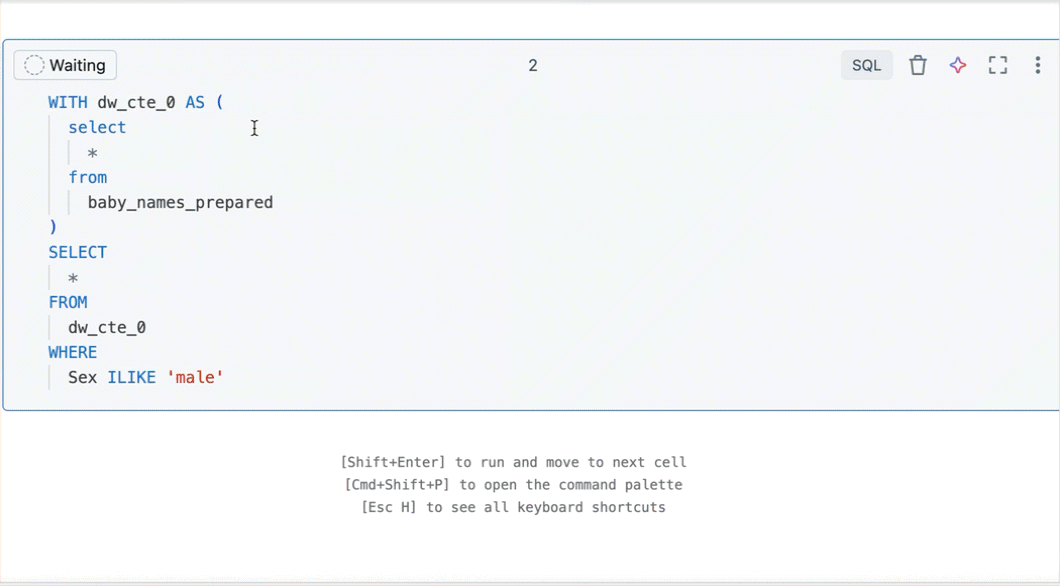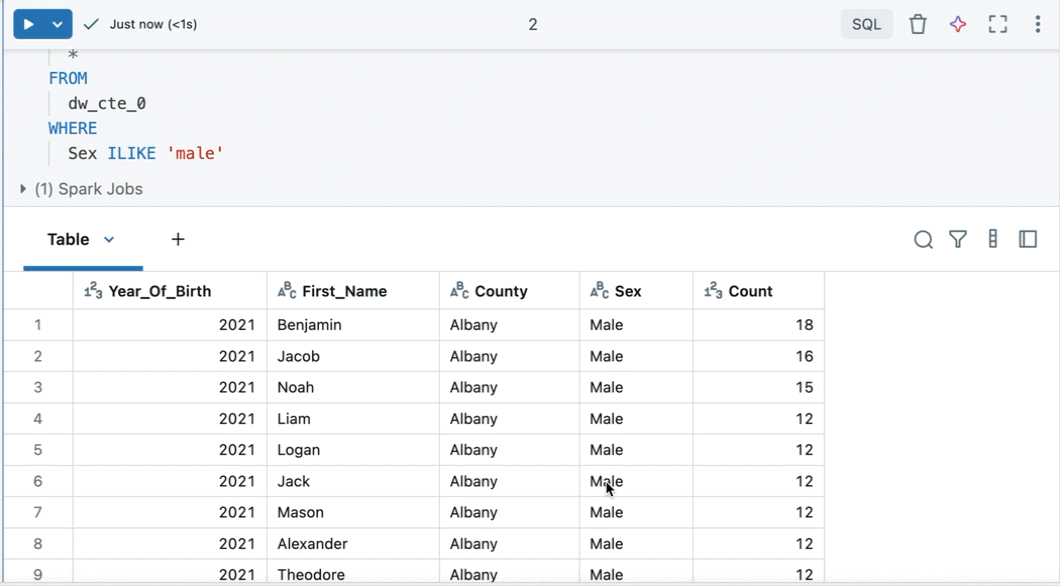
Filters toepassen op de volledige gegevensset
Filters worden standaard alleen toegepast op de resultaten die worden weergegeven in de resultatentabel. Als de geretourneerde gegevens worden afgekapt (bijvoorbeeld wanneer een query meer dan 10.000 rijen retourneert of de gegevensset groter is dan 2 MB), wordt het filter alleen toegepast op de geretourneerde rijen. Een opmerking in de rechterbovenhoek van de tabel geeft aan dat het filter is toegepast op afgekapte gegevens.
U kunt in plaats daarvan de volledige gegevensset filteren. Klik op Afgekapte gegevens en selecteer vervolgens Volledige gegevensset. Afhankelijk van de grootte van de gegevensset kan het lang duren voordat het filter is toegepast.

Een query maken op basis van gefilterde resultaten
Vanuit een gefilterde resultatentabel of visualisatie in een notebook met SQL als standaardtaal kunt u een nieuwe query maken waarop de filters zijn toegepast. Klik rechtsboven in de tabel of visualisatie op Query maken. De query wordt toegevoegd als de volgende cel in het notitieblok.
Met de gemaakte query worden uw filters toegepast op de oorspronkelijke query. Hierdoor kunt u werken met een kleinere, relevantere gegevensset, waardoor u efficiënter gegevens kunt verkennen en analyseren.
Kolommen verkennen
Om het werken met tabellen met veel kolommen te vergemakkelijken, kunt u de kolomverkenner gebruiken. Als u de kolomverkenner wilt openen, klikt u op het kolompictogram (![]() ) in de rechterbovenhoek van een resultatentabel.
) in de rechterbovenhoek van een resultatentabel.
Met de kolomverkenner kunt u het volgende doen:
- Kolommen zoeken: typ in de zoekbalk om de lijst met kolommen te filteren. Klik op een kolom in de verkenner om ernaartoe te gaan in de resultatentabel.
- Kolommen weergeven of verbergen: gebruik de selectievakjes om de zichtbaarheid van kolommen te beheren. Het selectievakje bovenaan schakelt de zichtbaarheid van alle kolommen tegelijk in. Afzonderlijke kolommen kunnen worden weergegeven of verborgen met behulp van de selectievakjes naast hun namen.
- Kolommen vastmaken: Plaats de muisaanwijzer op een kolomnaam om een speldpictogram weer te geven. Klik op het speldpictogram om de kolom vast te maken. Vastgemaakte kolommen blijven zichtbaar terwijl u horizontaal door de resultatentabel schuift.
-
Kolommen opnieuw rangschikpen: klik op het sleeppictogram (
 ) rechts van de naam van een kolom en sleep de kolom naar de nieuwe gewenste positie. Hiermee worden de kolommen in de resultatentabel opnieuw gerangschikt.
) rechts van de naam van een kolom en sleep de kolom naar de nieuwe gewenste positie. Hiermee worden de kolommen in de resultatentabel opnieuw gerangschikt.
kolommen opmaken
Kolomkoppen geven het gegevenstype van de kolom aan.
 geeft bijvoorbeeld het gegevenstype Geheel getal aan. Beweeg de muisaanwijzer over de indicator om het gegevenstype weer te geven.
geeft bijvoorbeeld het gegevenstype Geheel getal aan. Beweeg de muisaanwijzer over de indicator om het gegevenstype weer te geven.
U kunt kolommen in resultatentabellen opmaken als typen zoals Valuta, Percentage, URL- en meer, met controle over decimalen voor duidelijkere tabellen.
Kolommen formatteren vanuit het kebabmenu in de kolomnaam.
Resultaten downloaden
Het downloaden van resultaten is standaard ingeschakeld. Als u deze instelling wilt wijzigen, raadpleegt u De mogelijkheid om resultaten van notebooks te downloaden beheren.
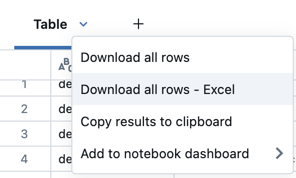
U kunt een celresultaat met tabeluitvoer downloaden naar uw lokale computer. Klik op de pijl-omlaag naast de tabtitel. De menuopties zijn afhankelijk van het aantal rijen in het resultaat en de Databricks Runtime-versie. Gedownloade resultaten worden opgeslagen op uw lokale computer als een CSV-bestand met een naam die overeenkomt met de naam van uw notitieblok.
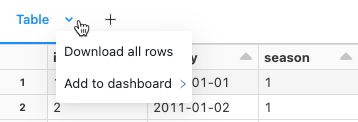
Voor notebooks die zijn verbonden met SQL-warehouses of serverloze berekeningen, kunt u de resultaten ook downloaden als een Excel-bestand.
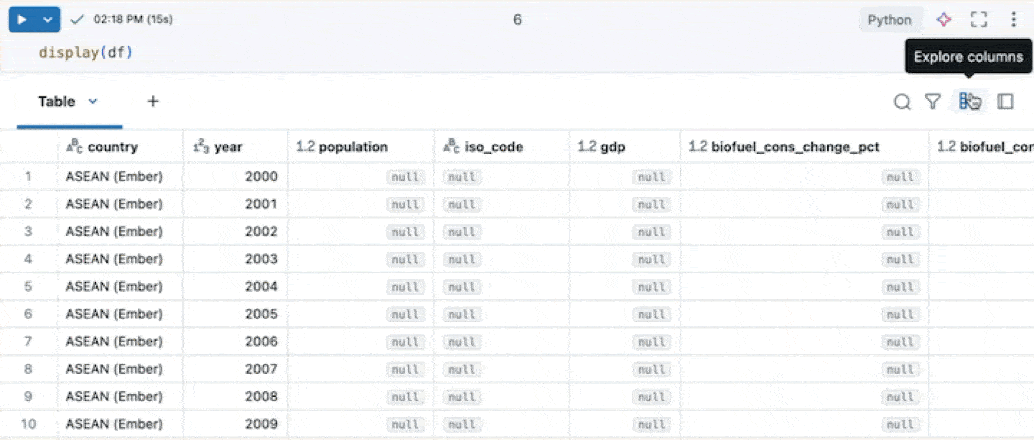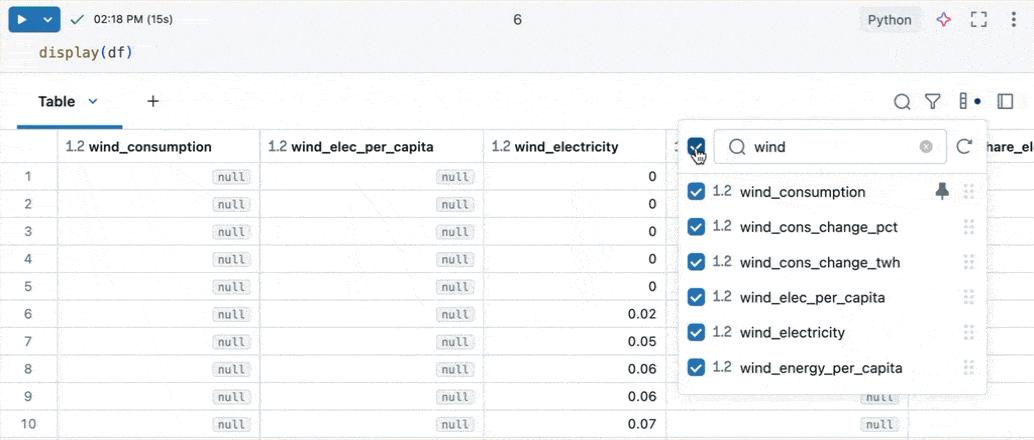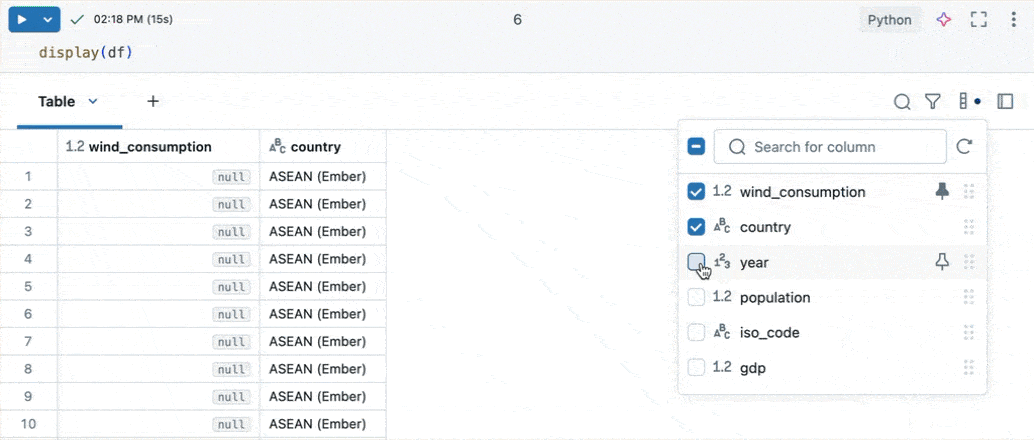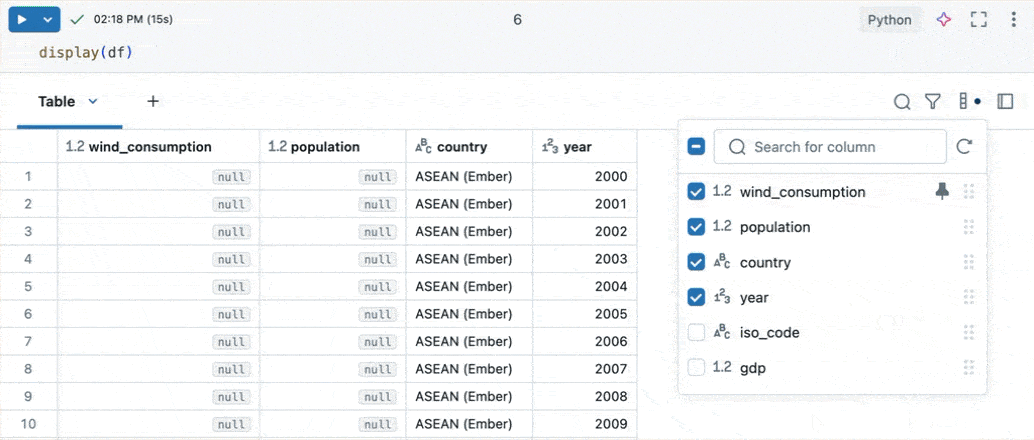
Sql-celresultaten verkennen
In een Databricks-notebook zijn resultaten van een SQL-taalcel automatisch beschikbaar als een DataFrame dat is toegewezen aan de variabele _sqldf. U kunt de variabele _sqldf gebruiken om te verwijzen naar de vorige SQL-uitvoer in volgende Python en SQL-cellen. Zie De resultaten van SQL-cellen verkennen voor meer informatie.
Meerdere uitvoer per cel weergeven
Python notebooks en %python cellen in niet-Python notebooks ondersteunen meerdere uitvoer per cel. De uitvoer van de volgende code bevat bijvoorbeeld zowel de plot als de tabel:
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
Uitvoerformaat wijzigen
Wijzig het formaat van de uitvoer van cellen door de rechterbenedenhoek van de tabel of visualisatie te slepen.
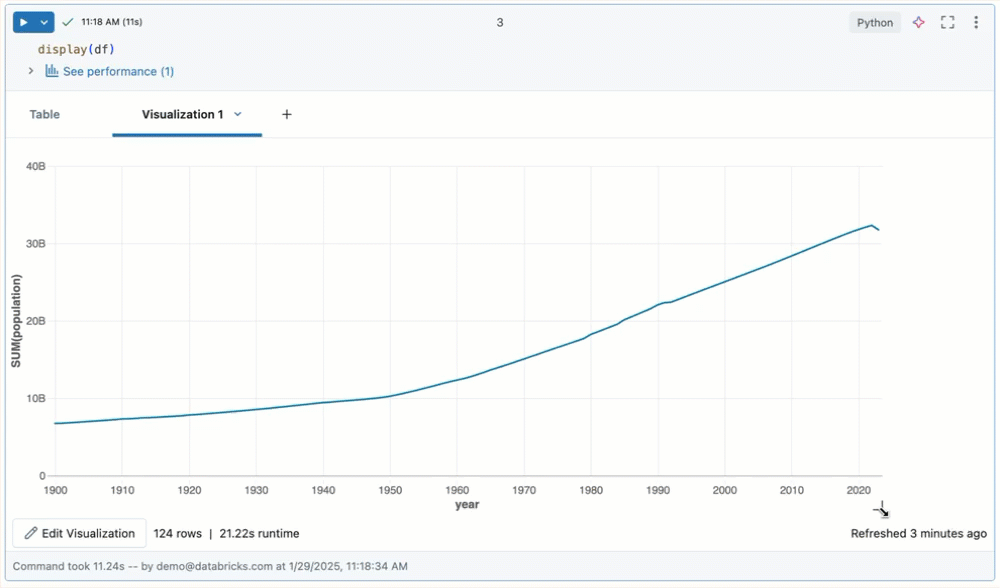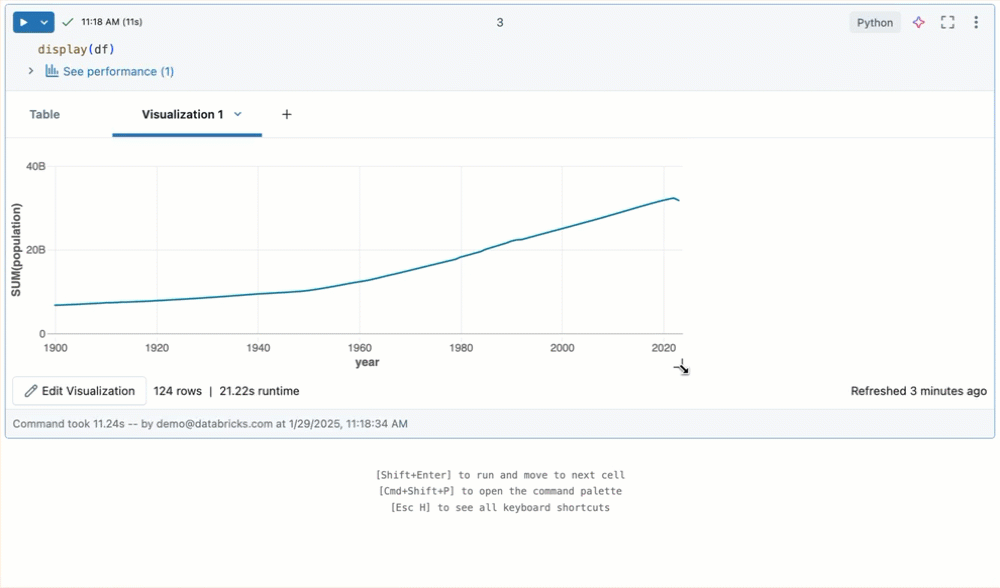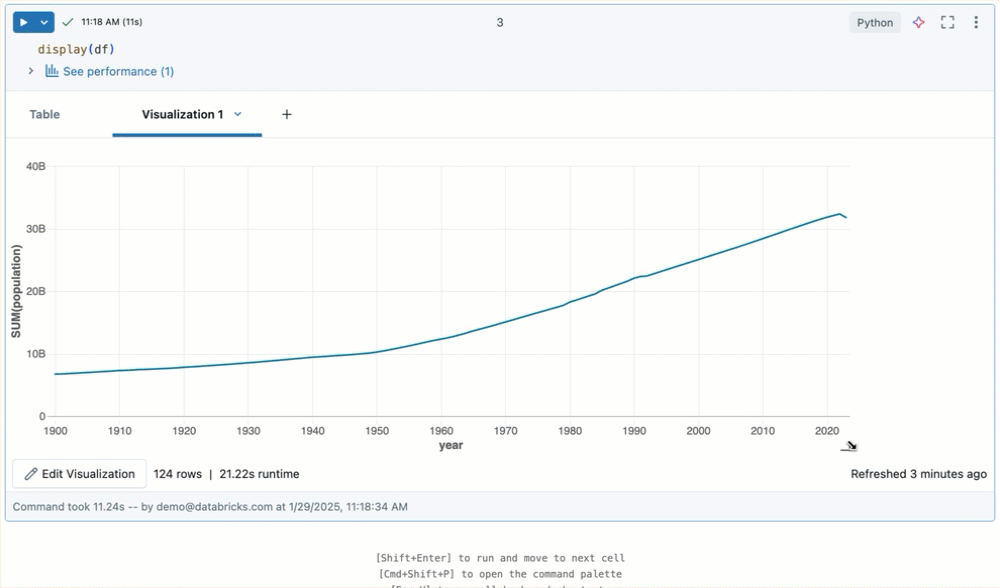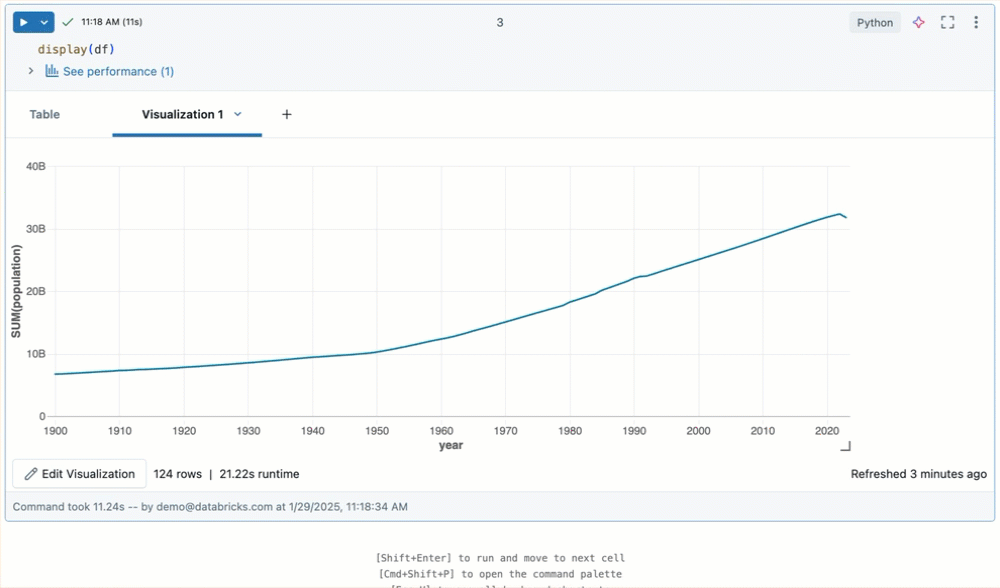
Notebookuitvoer doorvoeren in Git-mappen van Databricks
- Het notebook moet een .ipynb-bestand zijn
- Instellingen voor werkruimtebeheerders moeten het toestaan dat notebookuitvoer wordt doorgevoerd