Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie gebruikt u LangChain.js om een LangChain.js agent te bouwen waarmee de werknemers van het NorthWind-bedrijf vragen kunnen stellen die betrekking hebben op personeelszaken. Door het framework te gebruiken, voorkomt u standaardcode die doorgaans vereist is voor LangChain.js agents en Azure-serviceintegratie, zodat u zich kunt richten op uw bedrijfsbehoeften.
In deze handleiding leert u:
- Een LangChain.js-agent instellen
- Azure-resources integreren in uw LangChain.js-agent
- Uw LangChain.js-agent eventueel testen in LangSmith Studio
NorthWind is afhankelijk van twee gegevensbronnen: openbare HR-documentatie die toegankelijk is voor alle werknemers en een vertrouwelijke HR-database met gevoelige werknemersgegevens. Deze zelfstudie is gericht op het bouwen van een LangChain.js agent die bepaalt of de vraag van een werknemer kan worden beantwoord met behulp van de openbare HR-documenten. Zo ja, dan geeft de LangChain.js agent het antwoord rechtstreeks.
Waarschuwing
In dit artikel worden sleutels gebruikt voor toegang tot resources. In een productieomgeving wordt aanbevolen om Azure RBAC en beheerde identiteit te gebruiken. Deze aanpak elimineert de noodzaak om sleutels te beheren of te draaien, de beveiliging te verbeteren en het toegangsbeheer te vereenvoudigen.
Vereiste voorwaarden
- Een actief Azure-account. Maak gratis een account als u er nog geen hebt.
- Node.js LTS geïnstalleerd op uw systeem.
- TypeScript voor het schrijven en compileren van TypeScript-code.
- LangChain.js bibliotheek voor het opzetten van de agent.
- Optioneel: LangSmith voor het bewaken van AI-gebruik. U hebt de projectnaam, sleutel en eindpunt nodig.
- Optioneel: LangGraph Studio voor foutopsporing van LangGraph-ketens en LangChain.js agents.
- Azure AI Search-resource: zorg ervoor dat u beschikt over het resource-eindpunt, de beheersleutel (voor documentinvoeging), de querysleutel (voor het lezen van documenten) en de indexnaam.
-
Azure OpenAI-resource: u hebt de naam, sleutel en twee modellen van het resource-exemplaar nodig met hun API-versies:
- Een insluitmodel zoals
text-embedding-ada-002. - Een groot taalmodel zoals
gpt-4o.
- Een insluitmodel zoals
Agentarchitectuur
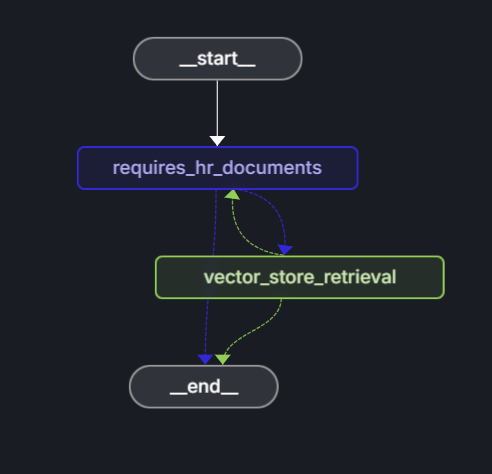
Het LangChain.js framework biedt een beslissingsstroom voor het bouwen van intelligente agents als LangGraph. In deze zelfstudie maakt u een LangChain.js agent die kan worden geïntegreerd met Azure AI Search en Azure OpenAI om HR-gerelateerde vragen te beantwoorden. De architectuur van de agent is ontworpen voor:
- Bepaal of een vraag relevant is voor HR-documentatie.
- Relevante documenten ophalen uit Azure AI Search.
- Gebruik Azure OpenAI om een antwoord te genereren op basis van de opgehaalde documenten en het LLM-model.
Belangrijkste onderdelen:
Grafiekstructuur: De LangChain.js-agent wordt weergegeven als een grafiek, waarbij:
- Knooppunten voeren specifieke taken uit, zoals besluitvorming of het ophalen van gegevens.
- Randen definiëren de stroom tussen knooppunten en bepalen de volgorde van bewerkingen.
Integratie van Azure AI Search:
- Voegt HR-documenten als embeddings toe aan een vectoropslag.
- Maakt gebruik van een insluitingsmodel (
text-embedding-ada-002) om deze insluitingen te maken. - Hiermee worden relevante documenten opgehaald op basis van de gebruikersprompt.
Azure OpenAI-integratie:
- Maakt gebruik van een model voor grote talen (
gpt-4o) om:- Bepaalt of een vraag kan worden beantwoord vanuit algemene HR-documenten.
- Hiermee wordt een antwoord gegenereerd met behulp van context uit documenten en de vraag van de gebruiker.
- Maakt gebruik van een model voor grote talen (
De volgende tabel bevat voorbeelden van gebruikersvragen die relevant en niet relevant zijn en kunnen worden beantwoord vanuit algemene Documenten voor Human Resources:
| Vraag | Relevantie voor HR-documenten |
|---|---|
Does the NorthWind Health Plus plan cover eye exams? |
Relevant. De HR-documenten, zoals het handboek voor werknemers, moeten een antwoord geven. |
How much of my perks + benefits have I spent? |
Niet relevant. Deze vraag vereist toegang tot vertrouwelijke werknemersgegevens, die buiten het bereik van deze agent vallen. |
Door het framework te gebruiken, voorkomt u standaardcode die doorgaans vereist is voor LangChain.js agents en Azure-serviceintegratie, zodat u zich kunt richten op uw bedrijfsbehoeften.
Uw Node.js-project initialiseren
Initialiseer uw Node.js project in een nieuwe map voor uw TypeScript-agent. Voer de volgende opdrachten uit:
npm init -y
npm pkg set type=module
npx tsc --init
Een omgevingsbestand maken
Maak een .env bestand voor lokale ontwikkeling voor het opslaan van omgevingsvariabelen voor Azure-resources en LangGraph. Zorg ervoor dat de naam van de resource-instantie van het embedden en LLM alleen de resourcenaam is, niet het eindpunt.
Optioneel: Als u LangSmith gebruikt, stel LANGSMITH_TRACING in op true voor lokale ontwikkeling. Schakel deze uit (false) of verwijder deze in productie.
Afhankelijkheden installeren
Installeer Azure-afhankelijkheden voor Azure AI Search:
npm install @azure/search-documentsInstalleer LangChain.js vereisten voor het creëren en gebruiken van een agent.
npm install @langchain/community @langchain/core @langchain/langgraph @langchain/openai langchainOntwikkelafhankelijkheden installeren voor lokale ontwikkeling:
npm install --save-dev dotenv
Configuratiebestanden voor Azure AI Search-resources maken
Als u de verschillende Azure-resources en -modellen wilt beheren die in deze zelfstudie worden gebruikt, maakt u specifieke configuratiebestanden voor elke resource. Deze aanpak zorgt voor duidelijkheid en scheiding van zorgen, waardoor het eenvoudiger is om de configuraties te beheren en te onderhouden.
Configuratie voor het uploaden van documenten naar vectorarchief
Het Azure AI Search-configuratiebestand gebruikt de beheersleutel om documenten in te voegen in het vectorarchief. Deze sleutel is essentieel voor het beheren van de opname van gegevens in Azure AI Search.
const endpoint = process.env.AZURE_AISEARCH_ENDPOINT;
const adminKey = process.env.AZURE_AISEARCH_ADMIN_KEY;
const indexName = process.env.AZURE_AISEARCH_INDEX_NAME;
export const VECTOR_STORE_ADMIN = {
endpoint,
key: adminKey,
indexName,
};
LangChain.js abstraheert de noodzaak om een schema te definiëren voor gegevensopname in Azure AI Search, wat een standaardschema biedt dat geschikt is voor de meeste scenario's. Deze abstractie vereenvoudigt het proces en vermindert de behoefte aan aangepaste schemadefinities.
Configuratie voor het opvragen van vectoropslag.
Maak voor het uitvoeren van query's op het vectorarchief een afzonderlijk configuratiebestand:
import {
AzureAISearchConfig,
AzureAISearchQueryType,
} from "@langchain/community/vectorstores/azure_aisearch";
const endpoint = process.env.AZURE_AISEARCH_ENDPOINT;
const queryKey = process.env.AZURE_AISEARCH_QUERY_KEY;
const indexName = process.env.AZURE_AISEARCH_INDEX_NAME;
export const DOC_COUNT = 3;
export const VECTOR_STORE_QUERY: AzureAISearchConfig = {
endpoint,
key: queryKey,
indexName,
search: {
type: AzureAISearchQueryType.Similarity,
},
};
Wanneer u een query uitvoert op het vectorarchief, gebruikt u in plaats daarvan de querysleutel. Deze scheiding van sleutels zorgt voor veilige en efficiënte toegang tot de resource.
Configuratiebestanden voor Azure OpenAI-resources maken
Als u de twee verschillende modellen wilt beheren, maakt u insluitingen en LLM afzonderlijke configuratiebestanden. Deze aanpak zorgt voor duidelijkheid en scheiding van zorgen, waardoor het eenvoudiger is om de configuraties te beheren en te onderhouden.
Configuratie voor embeddings voor vectoropslag
Als u insluitingen wilt maken voor het invoegen van documenten in het Azure AI Search-vectorarchief, maakt u een configuratiebestand:
const key = process.env.AZURE_OPENAI_EMBEDDING_KEY;
const instance = process.env.AZURE_OPENAI_EMBEDDING_INSTANCE;
const apiVersion =
process.env.AZURE_OPENAI_EMBEDDING_API_VERSION || "2023-05-15";
const model =
process.env.AZURE_OPENAI_EMBEDDING_MODEL || "text-embedding-ada-002";
export const EMBEDDINGS_CONFIG = {
azureOpenAIApiKey: key,
azureOpenAIApiInstanceName: instance,
azureOpenAIApiEmbeddingsDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
maxRetries: 1,
};
Configuratie voor LLM voor het genereren van antwoorden
Als u antwoorden wilt maken op basis van het grote taalmodel, maakt u een configuratiebestand:
const key = process.env.AZURE_OPENAI_COMPLETE_KEY;
const instance = process.env.AZURE_OPENAI_COMPLETE_INSTANCE;
const apiVersion =
process.env.AZURE_OPENAI_COMPLETE_API_VERSION || "2024-10-21";
const model = process.env.AZURE_OPENAI_COMPLETE_MODEL || "gpt-4o";
const maxTokens = process.env.AZURE_OPENAI_COMPLETE_MAX_TOKENS;
export const LLM_CONFIG = {
model,
azureOpenAIApiKey: key,
azureOpenAIApiInstanceName: instance,
azureOpenAIApiDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
maxTokens: maxTokens ? parseInt(maxTokens, 10) : 100,
maxRetries: 1,
timeout: 60000,
};
Constanten en prompts
AI-toepassingen zijn vaak afhankelijk van vaste tekenreeksen en prompts. Beheer deze constanten met afzonderlijke bestanden.
Maak de systeemprompt:
export const SYSTEM_PROMPT = `Answer the query with a complete paragraph based on the following context:`;
Maak de knooppuntconstanten:
export const ANSWER_NODE = "vector_store_retrieval";
export const DECISION_NODE = "requires_hr_documents";
export const START = "__start__";
export const END = "__end__";
Voorbeeldquery's voor gebruikers maken:
export const USER_QUERIES = [
"Does the NorthWind Health plus plan cover eye exams?",
"What is included in the NorthWind Health plus plan that is not included in the standard?",
"What happens in a performance review?",
];
Documenten laden in Azure AI Search
Als u documenten wilt laden in Azure AI Search, gebruikt u LangChain.js om het proces te vereenvoudigen. De documenten, opgeslagen als PDF-bestanden, worden geconverteerd naar insluitingen en ingevoegd in het vectorarchief. Dit proces zorgt ervoor dat de documenten gereed zijn voor efficiënt ophalen en query's uitvoeren.
Belangrijkste overwegingen:
- LangChain.js abstractie: LangChain.js verwerkt veel van de complexiteit, zoals schemadefinities en het maken van clients, waardoor het proces eenvoudig is.
- Beperkings- en herhaal-logica: terwijl de voorbeeldcode een minimale wachtfunctie bevat, moeten productietoepassingen uitgebreide foutafhandeling en herhaal-logica implementeren om te kunnen omgaan met beperkingen en tijdelijke fouten.
Stappen voor het laden van documenten
Zoek de PDF-documenten: de documenten worden opgeslagen in de gegevensmap.
PDF-bestanden laden in LangChain.js: gebruik de
loadPdfsFromDirectoryfunctie om de documenten te laden. Deze functie maakt gebruik van de methode van de LangChain.js communityPDFLoader.loadom elk bestand te lezen en eenDocument[]matrix te retourneren. Deze matrix is een standaard LangChain.js documentindeling.import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf"; import { waiter } from "../utils/waiter.js"; import { loadDocsIntoAiSearchVector } from "./load_vector_store.js"; import fs from "fs/promises"; import path from "path"; export async function loadPdfsFromDirectory( embeddings: any, dirPath: string, ): Promise<void> { try { const files = await fs.readdir(dirPath); console.log( `PDF: Loading directory ${dirPath}, ${files.length} files found`, ); for (const file of files) { if (file.toLowerCase().endsWith(".pdf")) { const fullPath = path.join(dirPath, file); console.log(`PDF: Found ${fullPath}`); const pdfLoader = new PDFLoader(fullPath); console.log(`PDF: Loading ${fullPath}`); const docs = await pdfLoader.load(); console.log(`PDF: Sending ${fullPath} to index`); const storeResult = await loadDocsIntoAiSearchVector(embeddings, docs); console.log(`PDF: Indexing result: ${JSON.stringify(storeResult)}`); await waiter(1000 * 60); // waits for 1 minute between files } } } catch (err) { console.error("Error loading PDFs:", err); } }Documenten invoegen in Azure AI Search: gebruik de
loadDocsIntoAiSearchVectorfunctie om de documentmatrix naar het Azure AI Search-vectorarchief te verzenden. Deze functie maakt gebruik van de insluitingsclient om de documenten te verwerken en bevat een eenvoudige wachtfunctie voor het reguleren van de snelheid. Implementeer voor productie een robuust mechanisme voor opnieuw proberen/uitstel.import { AzureAISearchVectorStore } from "@langchain/community/vectorstores/azure_aisearch"; import type { Document } from "@langchain/core/documents"; import type { EmbeddingsInterface } from "@langchain/core/embeddings"; import { VECTOR_STORE_ADMIN } from "../config/vector_store_admin.js"; export async function loadDocsIntoAiSearchVector( embeddings: EmbeddingsInterface, documents: Document[], ): Promise<AzureAISearchVectorStore> { const vectorStore = await AzureAISearchVectorStore.fromDocuments( documents, embeddings, VECTOR_STORE_ADMIN, ); return vectorStore; }
Agentwerkstroom maken
Bouw in LangChain.jsde LangChain.js-agent met een LangGraph. Met LangGraph kunt u de knooppunten en randen definiëren:
- Knooppunt: waar werk wordt uitgevoerd.
- Edge: definieert de verbinding tussen knooppunten.
Werkstroomonderdelen
In deze toepassing zijn de twee werkknooppunten:
- vereistHrResources: bepaalt of de vraag relevant is voor HR-documentatie met behulp van de Azure OpenAI LLM.
- getAnswer: haalt het antwoord op. Het antwoord is afkomstig van een LangChain.js retriever-keten, die gebruikmaakt van de document-insluitingen van Azure AI Search en deze verzendt naar de Azure OpenAI LLM. Dit is de essentie van retrieval-augmented generatie.
De randen bepalen waar te starten, waar te eindigen en de voorwaarde die nodig is om het getAnswer-knooppunt aan te roepen.
De grafiek exporteren
Als u LangGraph Studio wilt gebruiken om de grafiek uit te voeren en fouten op te sporen, exporteert u deze als een eigen object.
import { StateGraph } from "@langchain/langgraph";
import { StateAnnotation } from "./langchain/state.js";
import { route as endRoute } from "./langchain/check_route_end.js";
import { getAnswer } from "./azure/get_answer.js";
import { START, ANSWER_NODE, DECISION_NODE } from "./config/nodes.js";
import {
requiresHrResources,
routeRequiresHrResources,
} from "./azure/requires_hr_documents.js";
const builder = new StateGraph(StateAnnotation)
.addNode(DECISION_NODE, requiresHrResources)
.addNode(ANSWER_NODE, getAnswer)
.addEdge(START, DECISION_NODE)
.addConditionalEdges(DECISION_NODE, routeRequiresHrResources)
.addConditionalEdges(ANSWER_NODE, endRoute);
export const hr_documents_answer_graph = builder.compile();
hr_documents_answer_graph.name = "Azure AI Search + Azure OpenAI";
In de methoden addNode, addEdge en addConditionalEdges is de eerste parameter een naam, als tekenreeks, om het object in de grafiek te identificeren. De tweede parameter is de functie die in die stap moet worden aangeroepen of de naam van het knooppunt dat moet worden aangeroepen.
Voor de methode addEdge is de naam START ('start' gedefinieerd in het bestand ./src/config/nodes.ts) en wordt altijd de DECISION_NODE aangeroepen. Dat knooppunt wordt gedefinieerd met de twee parameters: de eerste is de naam, DECISION_NODE, en de tweede is de functie genaamd requiresHrResources.
Algemene functionaliteit
Deze app biedt algemene LangChain-functionaliteit:
Statusbeheer:
import { BaseMessage, BaseMessageLike } from "@langchain/core/messages"; import { Annotation, messagesStateReducer } from "@langchain/langgraph"; export const StateAnnotation = Annotation.Root({ messages: Annotation<BaseMessage[], BaseMessageLike[]>({ reducer: messagesStateReducer, default: () => [], }), });Routebeëindiging:
import { StateAnnotation } from "./state.js"; import { END, ANSWER_NODE } from "../config/nodes.js"; export const route = ( state: typeof StateAnnotation.State, ): typeof END | typeof ANSWER_NODE => { if (state.messages.length > 0) { return END; } return ANSWER_NODE; };
De enige aangepaste route voor deze toepassing is de routeRequiresHrResources. Deze route wordt gebruikt om te bepalen of het antwoord van het knooppunt VereistHrResources aangeeft dat de vraag van de gebruiker moet doorgaan naar het ANSWER_NODE knooppunt. Omdat deze route de uitvoer van requiresHrResources ontvangt, bevindt deze zich in hetzelfde bestand.
Azure OpenAI-resources integreren
De Azure OpenAI-integratie maakt gebruik van twee verschillende modellen:
- Embeddings: worden gebruikt om de documenten in de vectoropslag te plaatsen.
- LLM: Wordt gebruikt om vragen te beantwoorden door query's uit te voeren op het vectorarchief en antwoorden te genereren.
De insluitingsclient en de LLM-client dienen verschillende doeleinden. Verminder ze niet tot één model of client.
Model voor insluiten
De embed-client is vereist wanneer documenten worden opgehaald uit de vectoropslag. Het bevat een configuratie voor maxRetries voor het afhandelen van tijdelijke fouten.
import { AzureOpenAIEmbeddings } from "@langchain/openai";
import { EMBEDDINGS_CONFIG } from "../config/embeddings.js";
export function getEmbeddingClient(): AzureOpenAIEmbeddings {
return new AzureOpenAIEmbeddings({ ...EMBEDDINGS_CONFIG, maxRetries: 1 });
}
LLM-model
Het LLM-model wordt gebruikt om twee typen vragen te beantwoorden:
- Relevantie voor HR: bepaalt of de vraag van de gebruiker relevant is voor HR-documentatie.
- Antwoordgeneratie: biedt een antwoord op de vraag van de gebruiker, uitgebreid met documenten van Azure AI Search.
De LLM-client wordt gemaakt en aangeroepen wanneer een antwoord vereist is.
import { RunnableConfig } from "@langchain/core/runnables";
import { StateAnnotation } from "../langchain/state.js";
import { AzureChatOpenAI } from "@langchain/openai";
import { LLM_CONFIG } from "../config/llm.js";
export const getLlmChatClient = (): AzureChatOpenAI => {
return new AzureChatOpenAI({
...LLM_CONFIG,
temperature: 0,
});
};
export const callChatCompletionModel = async (
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> => {
const llm = new AzureChatOpenAI({
...LLM_CONFIG,
temperature: 0,
});
const completion = await llm.invoke(state.messages);
completion;
return {
messages: [
...state.messages,
{
role: "assistant",
content: completion.content,
},
],
};
};
De LangChain.js-agent gebruikt de LLM om te bepalen of de vraag relevant is voor HR-documentatie of dat de werkstroom naar het einde van het diagram moet worden gerouteerd.
// @ts-nocheck
import { getLlmChatClient } from "./llm.js";
import { StateAnnotation } from "../langchain/state.js";
import { RunnableConfig } from "@langchain/core/runnables";
import { BaseMessage } from "@langchain/core/messages";
import { ANSWER_NODE, END } from "../config/nodes.js";
const PDF_DOCS_REQUIRED = "Answer requires HR PDF docs.";
export async function requiresHrResources(
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> {
const lastUserMessage: BaseMessage = [...state.messages].reverse()[0];
let pdfDocsRequired = false;
if (lastUserMessage && typeof lastUserMessage.content === "string") {
const question = `Does the following question require general company policy information that could be found in HR documents like employee handbooks, benefits overviews, or company-wide policies, then answer yes. Answer no if this requires personal employee-specific information that would require access to an individual's private data, employment records, or personalized benefits details: '${lastUserMessage.content}'. Answer with only "yes" or "no".`;
const llm = getLlmChatClient();
const response = await llm.invoke(question);
const answer = response.content.toLocaleLowerCase().trim();
console.log(`LLM question (is HR PDF documents required): ${question}`);
console.log(`LLM answer (is HR PDF documents required): ${answer}`);
pdfDocsRequired = answer === "yes";
}
// If HR documents (aka vector store) are required, append an assistant message to signal this.
if (!pdfDocsRequired) {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content:
"Not a question for our HR PDF resources. This requires data specific to the asker.",
},
],
};
return updatedState;
} else {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content: `${PDF_DOCS_REQUIRED} You asked: ${lastUserMessage.content}. Let me check.`,
},
],
};
return updatedState;
}
}
export const routeRequiresHrResources = (
state: typeof StateAnnotation.State,
): typeof END | typeof ANSWER_NODE => {
const lastMessage: BaseMessage = [...state.messages].reverse()[0];
if (lastMessage && !lastMessage.content.includes(PDF_DOCS_REQUIRED)) {
console.log("go to end");
return END;
}
console.log("go to llm");
return ANSWER_NODE;
};
De functie requiresHrResources stelt een bericht in met inhoud in de bijgewerkte toestand HR resources required detected. De router, routeRequiresHrResources, zoekt naar die inhoud om te bepalen waar de berichten moeten worden verzonden.
Azure AI Search-resource integreren voor vectorstore
De Integratie van Azure AI Search biedt de vector store-documenten, zodat de LLM het antwoord voor het getAnswer-knooppunt kan uitbreiden. LangChain.js biedt opnieuw een groot deel van de abstractie, zodat de vereiste code minimaal is. De functies zijn:
- getReadOnlyVectorStore: haalt de client op met de querysleutel.
- getDocsFromVectorStore: zoekt relevante documenten naar de vraag van de gebruiker.
import { AzureAISearchVectorStore } from "@langchain/community/vectorstores/azure_aisearch";
import { VECTOR_STORE_QUERY, DOC_COUNT } from "../config/vector_store_query.js";
import { getEmbeddingClient } from "./embeddings.js";
export function getReadOnlyVectorStore(): AzureAISearchVectorStore {
const embeddings = getEmbeddingClient();
return new AzureAISearchVectorStore(embeddings, VECTOR_STORE_QUERY);
}
export async function getDocsFromVectorStore(
query: string,
): Promise<Document[]> {
const store = getReadOnlyVectorStore();
// @ts-ignore
//return store.similaritySearchWithScore(query, DOC_COUNT);
return store.similaritySearch(query, DOC_COUNT);
}
De LangChain.js integratiecode maakt het ophalen van de relevante documenten uit het vectorarchief ongelooflijk eenvoudig.
Code schrijven om antwoord te krijgen van LLM
Nu de integratieonderdelen zijn gebouwd, maakt u de functie getAnswer om relevante vectorarchiefdocumenten op te halen en een antwoord te genereren met behulp van de LLM.
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
import { createRetrievalChain } from "langchain/chains/retrieval";
import { getLlmChatClient } from "./llm.js";
import { StateAnnotation } from "../langchain/state.js";
import { AIMessage } from "@langchain/core/messages";
import { getReadOnlyVectorStore } from "./vector_store.js";
const EMPTY_STATE = { messages: [] };
export async function getAnswer(
state: typeof StateAnnotation.State = EMPTY_STATE,
): Promise<typeof StateAnnotation.Update> {
const vectorStore = getReadOnlyVectorStore();
// Extract the last user message's content from the state as input
const lastMessage = state.messages[state.messages.length - 1];
const userInput =
lastMessage && typeof lastMessage.content === "string"
? lastMessage.content
: "";
const questionAnsweringPrompt = ChatPromptTemplate.fromMessages([
[
"system",
"Answer the user's questions based on the below context:\n\n{context}",
],
["human", "{input}"],
]);
const combineDocsChain = await createStuffDocumentsChain({
llm: getLlmChatClient(),
prompt: questionAnsweringPrompt,
});
const retrievalChain = await createRetrievalChain({
retriever: vectorStore.asRetriever(2),
combineDocsChain,
});
const result = await retrievalChain.invoke({ input: userInput });
const assistantMessage = new AIMessage(result.answer);
return {
messages: [...state.messages, assistantMessage],
};
}
Deze functie biedt een prompt met twee tijdelijke aanduidingen: één voor de vraag van de gebruiker en één voor context. De context omvat alle relevante documenten uit de AI-zoek vectorwinkel. Geef de prompt en de LLM-client door aan de createStuffDocumentsChain om een LLM-keten te maken. Geef de LLM-keten door aan createRetrievalChain om een keten te creëren die de prompt, relevante documenten en de LLM bevat.
Voer de ketens uit met ophaalKetting.invoke en de vraag van de gebruiker als invoer om het antwoord te krijgen. Retourneer het antwoord in de berichtstatus.
Het agentpakket bouwen
Voeg een script toe aan package.json om de TypeScript-toepassing te bouwen:
"build": "tsc",Bouw de LangChain.js-agent.
npm run build
Optioneel: voer de LangChain.js-agent uit in lokale ontwikkeling met LangChain Studio
Optioneel, voor lokale ontwikkeling, gebruikt u LangChain Studio om met uw LangChain.js-agent te werken.
Maak een
langgraph.jsonbestand om de grafiek te definiëren.{ "dependencies": [], "graphs": { "agent": "./src/graph.ts:hr_documents_answer_graph" }, "env": "../.env" }Installeer de LangGraph CLI.
npm install @langchain/langgraph-cli --save-devMaak een script in package.json om het
.envbestand door te geven aan de LangGraph CLI."studio": "npx @langchain/langgraph-cli dev",De CLI wordt uitgevoerd in uw terminal en opent een browser naar LangGraph Studio.
Welcome to ╦ ┌─┐┌┐┌┌─┐╔═╗┬─┐┌─┐┌─┐┬ ┬ ║ ├─┤││││ ┬║ ╦├┬┘├─┤├─┘├─┤ ╩═╝┴ ┴┘└┘└─┘╚═╝┴└─┴ ┴┴ ┴ ┴.js - 🚀 API: http://localhost:2024 - 🎨 Studio UI: https://smith.langchain.com/studio?baseUrl=http://localhost:2024 This in-memory server is designed for development and testing. For production use, please use LangGraph Cloud. info: ▪ Starting server... info: ▪ Initializing storage... info: ▪ Registering graphs from C:\Users\myusername\azure-typescript-langchainjs\packages\langgraph-agent info: ┏ Registering graph with id 'agent' info: ┗ [1] { graph_id: 'agent' } info: ▪ Starting 10 workers info: ▪ Server running at ::1:2024Bekijk de LangChain.js-agent in LangGraph Studio.
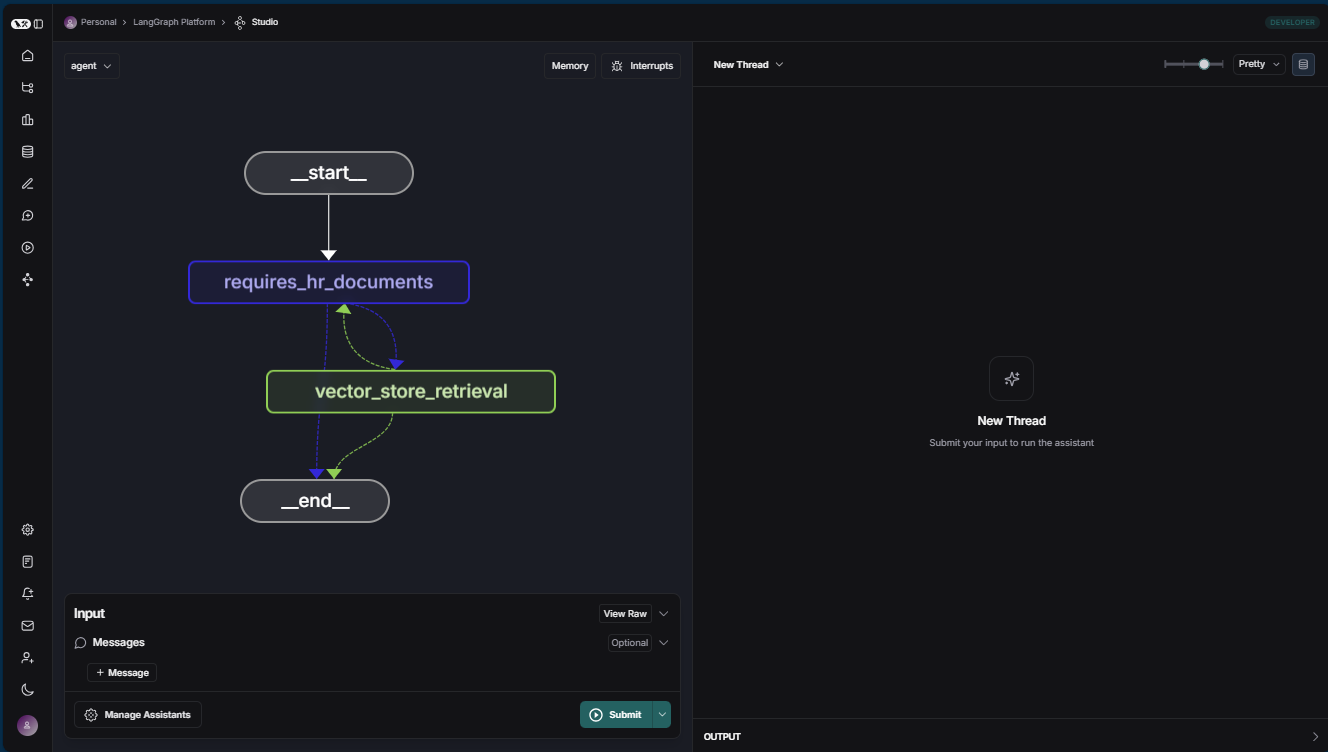
Selecteer + Bericht om een gebruikersvraag toe te voegen en selecteer Verzenden.
Vraag Relevantie voor HR-documenten Does the NorthWind Health plus plan cover eye exams?Deze vraag is relevant voor HR en over het algemeen genoeg dat de HR-documenten zoals het handboek voor werknemers, het handboek voor voordelen en de rollenbibliotheek van de werknemer deze moeten kunnen beantwoorden. What is included in the NorthWind Health plus plan that is not included in the standard?Deze vraag is relevant voor HR en over het algemeen genoeg dat de HR-documenten zoals het handboek voor werknemers, het handboek voor voordelen en de rollenbibliotheek van de werknemer deze moeten kunnen beantwoorden. How much of my perks + benefit have I spentDeze vraag is niet relevant voor de algemene, onpersoonlijke HR-documenten. Deze vraag moet worden verzonden naar een agent die toegang heeft tot werknemersgegevens. Als de vraag relevant is voor de HR-documenten, moet deze de DECISION_NODE doorlopen en vervolgens naar de ANSWER_NODE.
Bekijk de terminaluitvoer om de vraag aan de LLM en het antwoord van de LLM te zien.
Als de vraag niet relevant is voor de HR-documenten, gaat de stroom rechtstreeks naar het einde.
Wanneer de LangChain.js-agent een onjuiste beslissing neemt, kan het probleem het volgende zijn:
- LLM-model gebruikt
- Aantal documenten uit vectorwinkel
- Prompt gebruikt in het beslissingsknooppunt.
De LangChain.js-agent uitvoeren vanuit een app
Als u de LangChain.js-agent wilt aanroepen vanuit een bovenliggende toepassing, zoals een web-API, moet u de aanroep van de LangChain.js-agent opgeven.
import { HumanMessage } from "@langchain/core/messages";
import { hr_documents_answer_graph as app } from "./graph.js";
const AIMESSAGE = "aimessage";
export async function ask_agent(question: string) {
const initialState = { messages: [new HumanMessage(question)], iteration: 0 };
const finalState = await app.invoke(initialState);
return finalState;
}
export async function get_answer(question: string) {
try {
const answerResponse = await ask_agent(question);
const answer = answerResponse.messages
.filter(
(m: any) =>
m &&
m.constructor?.name?.toLowerCase() === AIMESSAGE.toLocaleLowerCase(),
)
.map((m: any) => m.content)
.join("\n");
return answer;
} catch (e) {
console.error("Error in get_answer:", e);
throw e;
}
}
De twee functies zijn:
- ask_agent: Deze functie retourneert de status, zodat u de LangChain.js-agent kunt toevoegen aan een werkstroom met meerdere agents in LangChain.
- get_answer: Met deze functie wordt alleen de tekst van het antwoord geretourneerd. Deze functie kan worden aangeroepen vanuit een API.
Probleemoplossingsproces
- Voor eventuele problemen met de procedure maakt u een probleem in de voorbeeldcodeopslagplaats
De hulpbronnen opschonen
Verwijder de resourcegroep die de Azure AI Search-resource en de Azure OpenAI-resource bevat.