Query uitvoeren op Apache Hive via het JDBC-stuurprogramma in HDInsight
Meer informatie over het gebruik van het JDBC-stuurprogramma vanuit een Java-toepassing. Apache Hive-query's verzenden naar Apache Hadoop in Azure HDInsight. De informatie in dit document laat zien hoe u programmatisch verbinding maakt en vanaf de SQuirreL SQL client.
Zie HiveJDBCInterface voor meer informatie over de Hive JDBC-interface.
Vereisten
- Een HDInsight Hadoop-cluster. Zie Aan de slag met Azure HDInsight om er een te maken. Zorg ervoor dat de service HiveServer2 wordt uitgevoerd.
- De Java Developer Kit (JDK) versie 11 of hoger.
- SQuirreL SQL. SQuirreL is een JDBC-clienttoepassing.
JDBC-verbindingsreeks
JDBC-verbindingen met een HDInsight-cluster in Azure worden gemaakt via poort 443. Het verkeer wordt beveiligd met TLS/SSL. De openbare gateway waarop de clusters zich bevinden, leidt het verkeer om naar de poort waarop HiveServer2 daadwerkelijk luistert. In de volgende verbindingsreeks ziet u de indeling die moet worden gebruikt voor HDInsight:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Vervang CLUSTERNAME door de naam van uw HDInsight-cluster.
Hostnaam in verbindingsreeks
De hostnaam 'CLUSTERNAME.azurehdinsight.net' in de verbindingsreeks is hetzelfde als de cluster-URL. U kunt het downloaden via Azure Portal.
Poort in verbindingsreeks
U kunt poort 443 alleen gebruiken om vanaf sommige locaties buiten het virtuele Azure-netwerk verbinding te maken met het cluster. HDInsight is een beheerde service, wat betekent dat alle verbindingen met het cluster worden beheerd via een beveiligde gateway. U kunt geen verbinding maken met HiveServer 2 rechtstreeks op poort 10001 of 10000. Deze poorten worden niet aan de buitenkant blootgesteld.
Verificatie
Gebruik bij het tot stand brengen van de verbinding de naam en het wachtwoord van de HDInsight-clusterbeheerder om te verifiëren. Voer vanuit JDBC-clients, zoals SQuirreL SQL, de beheerdersnaam en het wachtwoord in de clientinstellingen in.
Vanuit een Java-toepassing moet u de naam en het wachtwoord gebruiken bij het tot stand brengen van een verbinding. Met de volgende Java-code wordt bijvoorbeeld een nieuwe verbinding geopend:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Verbinding maken met SQuirreL SQL-client
SQuirreL SQL is een JDBC-client die kan worden gebruikt voor het extern uitvoeren van Hive-query's met uw HDInsight-cluster. Bij de volgende stappen wordt ervan uitgegaan dat u SQuirreL SQL al hebt geïnstalleerd.
Maak een map die bepaalde bestanden bevat die moeten worden gekopieerd uit uw cluster.
Vervang in het volgende script de
sshusernaam van het SSH-gebruikersaccount voor het cluster. Vervang doorCLUSTERNAMEde naam van het HDInsight-cluster. Wijzig vanaf een opdrachtregel de werkmap in de map die u in de vorige stap hebt gemaakt en voer vervolgens de volgende opdracht in om bestanden uit een HDInsight-cluster te kopiëren:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Start de SQuirreL SQL-toepassing. Selecteer Stuurprogramma's aan de linkerkant van het venster.

Selecteer in de pictogrammen bovenaan het dialoogvenster Stuurprogramma's het + pictogram om een stuurprogramma te maken.
Voeg in het dialoogvenster Stuurprogramma toegevoegd de volgende informatie toe:
Eigenschappen Waarde Naam Hive Voorbeeld-URL jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Extra klaspad Gebruik de knop Toevoegen om alle JAR-bestanden toe te voegen die u eerder hebt gedownload. Klassenaam org.apache.hive.jdbc.HiveDriver 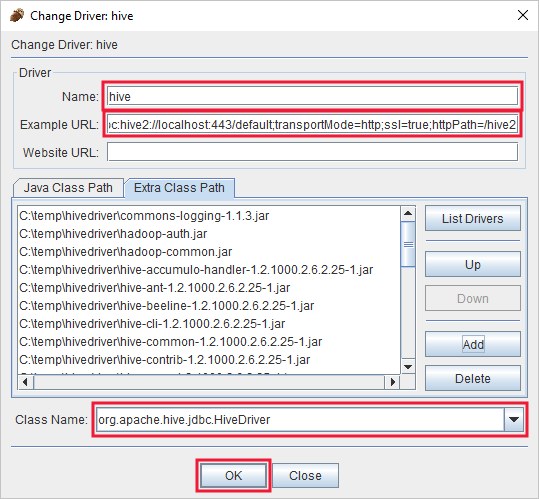
Selecteer OK om deze instellingen op te slaan.
Selecteer aan de linkerkant van het SQuirreL SQL-venster Aliassen. Selecteer vervolgens het + pictogram om een verbindingsalias te maken.

Gebruik de volgende waarden voor het dialoogvenster Alias toevoegen:
Eigenschappen Waarde Naam Hive in HDInsight Stuurprogramma Gebruik de vervolgkeuzelijst om het Hive-stuurprogramma te selecteren. URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Vervang CLUSTERNAME door de naam van uw HDInsight-cluster.Gebruikersnaam De naam van het clusteraanmeldingsaccount voor uw HDInsight-cluster. De standaardwaarde is beheerder. Wachtwoord Het wachtwoord voor het aanmeldingsaccount voor het cluster. 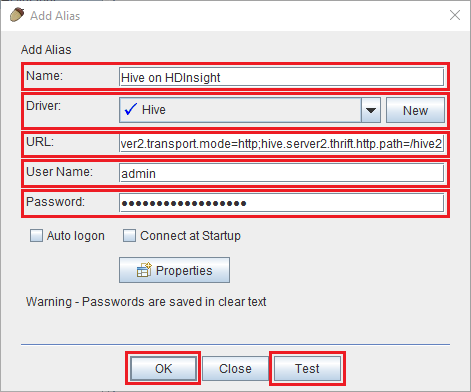
Belangrijk
Gebruik de knop Testen om te controleren of de verbinding werkt. Wanneer Verbinding maken naar: Het dialoogvenster Hive in HDInsight wordt weergegeven, selecteert u Verbinding maken om de test uit te voeren. Als de test slaagt, ziet u een dialoogvenster Verbinding maken geslaagd. Als er een fout optreedt, raadpleegt u Probleemoplossing.
Als u de verbindingsalias wilt opslaan, gebruikt u de knop OK onderaan het dialoogvenster Alias toevoegen.
Selecteer Hive in HDInsight in het Verbinding maken naar de vervolgkeuzelijst boven aan SQuirreL SQL. Selecteer Verbinding maken wanneer hierom wordt gevraagd.
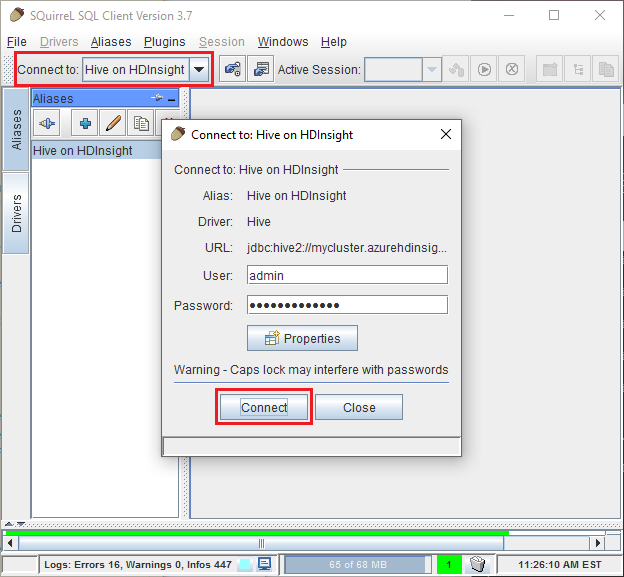
Nadat u verbinding hebt gemaakt, voert u de volgende query in het sql-querydialoogvenster in en selecteert u vervolgens het pictogram Uitvoeren (een actieve persoon). In het resultatengebied moeten de resultaten van de query worden weergegeven.
select * from hivesampletable limit 10;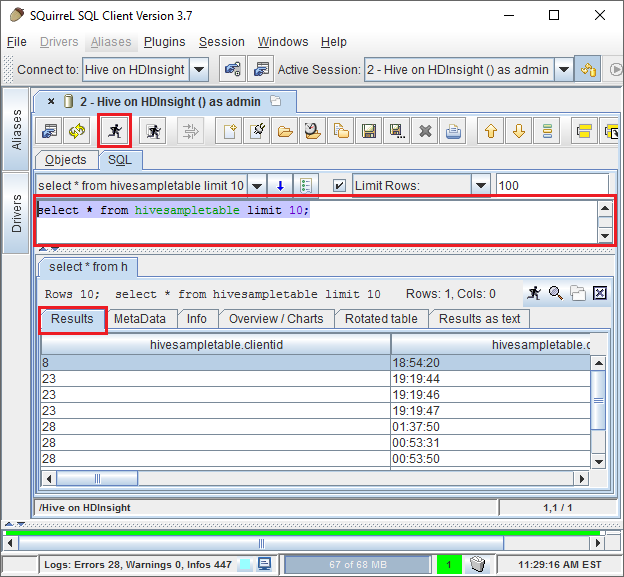
Verbinding maken uit een voorbeeld van een Java-toepassing
Een voorbeeld van het gebruik van een Java-client om een query uit te voeren op Hive in HDInsight is beschikbaar op https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Volg de instructies in de opslagplaats om het voorbeeld te bouwen en uit te voeren.
Probleemoplossing
Er is een onverwachte fout opgetreden bij het openen van een SQL-verbinding
Symptomen: Wanneer u verbinding maakt met een HDInsight-cluster dat versie 3.3 of hoger is, krijgt u mogelijk een foutmelding dat er een onverwachte fout is opgetreden. De stacktracering voor deze fout begint met de volgende regels:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Oorzaak: Deze fout wordt veroorzaakt door een oudere versie commons-codec.jar bestand dat is opgenomen in SQuirreL.
Oplossing: Gebruik de volgende stappen om deze fout op te lossen:
Sluit SQuirreL af en ga vervolgens naar de map waar SQuirreL op uw systeem is geïnstalleerd, misschien
C:\Program Files\squirrel-sql-4.0.0\lib. Vervang in de SquirreL-map onder delibmap de bestaande commons-codec.jar door de commons-codec.jar die is gedownload uit het HDInsight-cluster.Start SQuirreL opnieuw. De fout mag niet meer optreden wanneer u verbinding maakt met Hive in HDInsight.
Verbinding verbroken door HDInsight
Symptomen: HDInsight verbreekt onverwacht de verbinding bij het downloaden van een enorme hoeveelheid gegevens (bijvoorbeeld meerdere GB's) via JDBC/ODBC.
Oorzaak: De beperking op gatewayknooppunten veroorzaakt deze fout. Wanneer u gegevens ophaalt uit JDBC/ODBC, moeten alle gegevens via het gatewayknooppunt worden doorgegeven. Een gateway is echter niet ontworpen om een enorme hoeveelheid gegevens te downloaden, zodat de gateway de verbinding kan sluiten als het verkeer niet kan worden verwerkt.
Oplossing: Vermijd het gebruik van het JDBC-/ODBC-stuurprogramma om grote hoeveelheden gegevens te downloaden. Kopieer in plaats daarvan gegevens rechtstreeks vanuit blobopslag.
Volgende stappen
Nu u hebt geleerd hoe u JDBC kunt gebruiken om met Hive te werken, gebruikt u de volgende koppelingen om andere manieren te verkennen om met Azure HDInsight te werken.
- Visualiseer Apache Hive-gegevens met Microsoft Power BI in Azure HDInsight.
- Visualiseer Interactive Query Hive-gegevens met Power BI in Azure HDInsight.
- Verbinding maken Excel naar HDInsight met het ODBC-stuurprogramma van Microsoft Hive.
- Verbinding maken Excel naar Apache Hadoop met behulp van Power Query.
- Apache Hive gebruiken met HDInsight
- Apache Pig gebruiken met HDInsight
- MapReduce-taken gebruiken met HDInsight