C# gebruiken met MapReduce-streaming op Apache Hadoop in HDInsight
Meer informatie over het gebruik van C# om een MapReduce-oplossing te maken in HDInsight.
Met Apache Hadoop-streaming kunt u MapReduce-taken uitvoeren met behulp van een script of uitvoerbaar bestand. Hier wordt .NET gebruikt om de mapper en reducer te implementeren voor een oplossing voor het tellen van woorden.
.NET in HDInsight
HDInsight-clusters gebruiken Mono (https://mono-project.com) om .NET-toepassingen uit te voeren. Mono versie 4.2.1 is opgenomen in HDInsight versie 3.6. Zie Apache Hadoop-onderdelen die beschikbaar zijn in HDInsight-versies voor meer informatie over de versie van Mono die is opgenomen in HDInsight.
Zie Mono-compatibiliteit met .NET Framework-versies voor meer informatie over monocompatibiliteit.
Hoe Hadoop-streaming werkt
Het basisproces dat wordt gebruikt voor streaming in dit document is als volgt:
- Hadoop geeft gegevens door aan de mapper (mapper.exe in dit voorbeeld) op STDIN.
- De mapper verwerkt de gegevens en verzendt door tabs gescheiden sleutel-waardeparen naar STDOUT.
- De uitvoer wordt gelezen door Hadoop en vervolgens doorgegeven aan de reducer (reducer.exe in dit voorbeeld) op STDIN.
- De reducer leest de sleutel-/waardeparen met tabscheidingstekens, verwerkt de gegevens en verzendt vervolgens het resultaat als sleutel-/waardeparen met tabscheidingstekens op STDOUT.
- De uitvoer wordt gelezen door Hadoop en geschreven naar de uitvoermap.
Zie Hadoop Streaming voor meer informatie over streaming.
Vereisten
Visual Studio.
Een vertrouwdheid met het schrijven en bouwen van C#-code die is gericht op .NET Framework 4.5.
Een manier om .exe bestanden te uploaden naar het cluster. In de stappen in dit document worden de Data Lake Tools voor Visual Studio gebruikt om de bestanden te uploaden naar de primaire opslag voor het cluster.
Als u PowerShell gebruikt, hebt u de Az-module nodig.
Een Apache Hadoop-cluster in HDInsight. Zie Aan de slag met HDInsight in Linux.
Het URI-schema voor de primaire opslag voor uw clusters. Dit schema is voor
wasb://Azure Storage,abfs://voor Azure Data Lake Storage Gen2 ofadl://voor Azure Data Lake Storage Gen1. Als beveiligde overdracht is ingeschakeld voor Azure Storage of Data Lake Storage Gen2, iswasbs://de URI respectievelijk.abfss://
De mapper maken
Maak in Visual Studio een nieuwe .NET Framework-consoletoepassing met de naam mapper. Gebruik de volgende code voor de toepassing:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Nadat u de toepassing hebt gemaakt, bouwt u deze om het bestand /bin/Debug/mapper.exe in de projectmap te produceren.
De reducer maken
Maak in Visual Studio een nieuwe .NET Framework-consoletoepassing met de naam reducer. Gebruik de volgende code voor de toepassing:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Nadat u de toepassing hebt gemaakt, maakt u deze om het bestand /bin/Debug/reducer.exe in de projectmap te produceren.
Uploaden naar opslag
Vervolgens moet u de mapper - en reducer-toepassingen uploaden naar HDInsight-opslag.
Selecteer Server Explorer weergeven> in Visual Studio.
Klik met de rechtermuisknop op Azure, selecteer Verbinding maken naar Microsoft Azure-abonnement... en voltooi het aanmeldingsproces.
Vouw het HDInsight-cluster uit waarnaar u deze toepassing wilt implementeren. Er wordt een vermelding met de tekst (standaardopslagaccount) weergegeven.
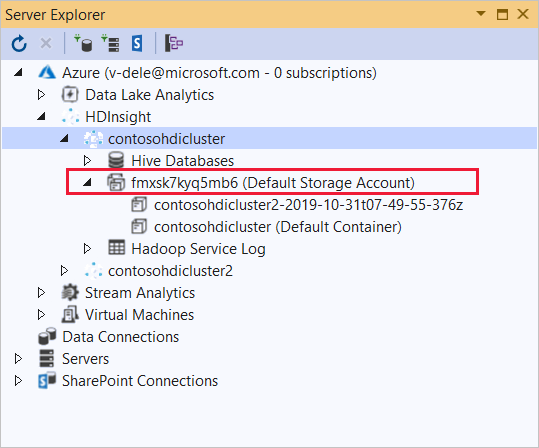
Als de vermelding (Standaardopslagaccount) kan worden uitgebreid, gebruikt u een Azure Storage-account als standaardopslag voor het cluster. Als u de bestanden in de standaardopslag voor het cluster wilt weergeven, vouwt u de vermelding uit en dubbelklikt u op (standaardcontainer).
Als de vermelding (Standaardopslagaccount) niet kan worden uitgebreid, gebruikt u Azure Data Lake Storage als de standaardopslag voor het cluster. Als u de bestanden in de standaardopslag voor het cluster wilt weergeven, dubbelklikt u op de vermelding (Standaardopslagaccount).
Gebruik een van de volgende methoden om de .exe-bestanden te uploaden:
Als u een Azure Storage-account gebruikt, selecteert u het pictogram Blob uploaden.

Selecteer Bladeren in het dialoogvenster Nieuw bestand uploaden onder Bestandsnaam. Ga in het dialoogvenster Blob uploaden naar de map bin\debug voor het mapper-project en kies vervolgens het bestand mapper.exe. Selecteer Ten slotte Openen en vervolgens OK om het uploaden te voltooien.
Voor Azure Data Lake Storage klikt u met de rechtermuisknop op een leeg gebied in de lijst met bestanden en selecteert u Uploaden. Selecteer tot slot het mapper.exe bestand en selecteer vervolgens Openen.
Zodra het uploaden van de mapper.exe is voltooid, herhaalt u het uploadproces voor het reducer.exe-bestand .
Een taak uitvoeren: Een SSH-sessie gebruiken
In de volgende procedure wordt beschreven hoe u een MapReduce-taak uitvoert met behulp van een SSH-sessie:
Gebruik de ssh-opdracht om verbinding te maken met uw cluster. Bewerk de onderstaande opdracht door CLUSTERNAME te vervangen door de naam van uw cluster. Voer vervolgens deze opdracht in:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netGebruik een van de volgende opdrachten om de MapReduce-taak te starten:
Als de standaardopslag Azure Storage is:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutAls de standaardopslag Data Lake Storage Gen1 is:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutAls de standaardopslag Data Lake Storage Gen2 is:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
In de volgende lijst wordt beschreven wat elke parameter en optie vertegenwoordigt:
Parameter Description hadoop-streaming.jar Hiermee geeft u het JAR-bestand dat de streaming MapReduce-functionaliteit bevat. -Bestanden Hiermee geeft u de mapper.exe en reducer.exe bestanden voor deze taak. De wasbs:///,adl:///ofabfs:///protocoldeclaratie voor elk bestand is het pad naar de hoofdmap van de standaardopslag voor het cluster.-Mapper Hiermee geeft u het bestand dat de mapper implementeert. -Reducer Hiermee geeft u het bestand dat de reducer implementeert. -Input Hiermee geeft u de invoergegevens op. -Output Hiermee geeft u de uitvoermap. Zodra de MapReduce-taak is voltooid, gebruikt u de volgende opdracht om de resultaten weer te geven:
hdfs dfs -text /example/wordcountout/part-00000De volgende tekst is een voorbeeld van de gegevens die door deze opdracht worden geretourneerd:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Een taak uitvoeren: PowerShell gebruiken
Gebruik het volgende PowerShell-script om een MapReduce-taak uit te voeren en de resultaten te downloaden.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Met dit script wordt u gevraagd om de naam en het wachtwoord van het clusteraanmeldingsaccount, samen met de naam van het HDInsight-cluster. Zodra de taak is voltooid, wordt de uitvoer gedownload naar een bestand met de naam output.txt. De volgende tekst is een voorbeeld van de gegevens in het output.txt bestand:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor