Apache Ambari Hive-weergave gebruiken met Apache Hadoop in HDInsight
Meer informatie over het uitvoeren van Hive-query's met behulp van de Apache Ambari Hive-weergave. Met de Hive-weergave kunt u Hive-query's maken, optimaliseren en uitvoeren vanuit uw webbrowser.
Vereisten
Een Hadoop-cluster in HDInsight. Zie Aan de slag met HDInsight in Linux.
Een Hive-query uitvoeren
Selecteer uw cluster via de Azure-portal. Zie Lijst en geef clusters weer voor instructies. Het cluster wordt geopend in een nieuwe portalweergave.
Selecteer Ambari-weergaven in clusterdashboards. Wanneer u wordt gevraagd om te verifiëren, gebruikt u de accountnaam en het wachtwoord van het cluster (standaardaccount
admin) die u hebt opgegeven toen u het cluster maakte. U kunt ook naarhttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsuw browser navigeren waarCLUSTERNAMEde naam van uw cluster is.Selecteer de Hive-weergave in de lijst met weergaven.
De Hive-weergavepagina is vergelijkbaar met de volgende afbeelding:
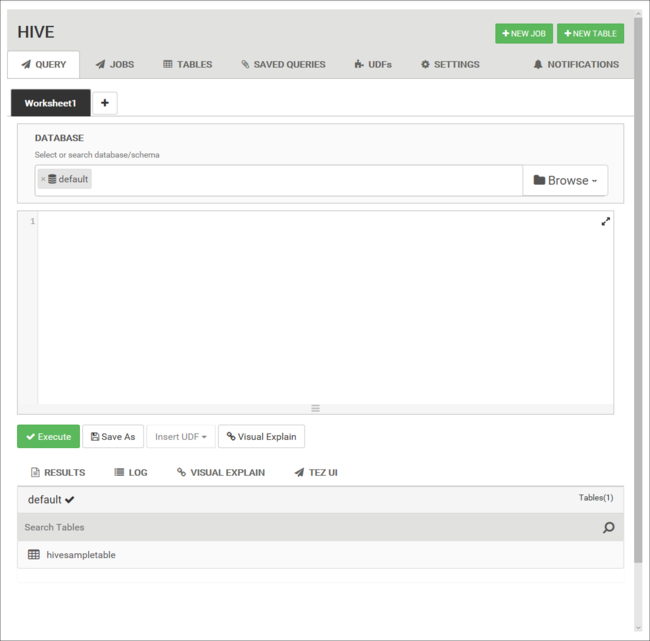
Plak op het tabblad Query de volgende HiveQL-instructies in het werkblad:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Met deze instructies worden de volgende acties uitgevoerd:
Instructie Beschrijving DROP TABLE Hiermee verwijdert u de tabel en het gegevensbestand, voor het geval de tabel al bestaat. CREATE EXTERNAL TABLE Hiermee maakt u een nieuwe externe tabel in Hive. Externe tabellen slaan alleen de tabeldefinitie op in Hive. De gegevens blijven op de oorspronkelijke locatie achter. RIJOPMAAK Hier ziet u hoe de gegevens zijn opgemaakt. In dit geval worden de velden in elk logboek gescheiden door een spatie. LOCATIE VAN OPGESLAGEN ALS TEKSTBESTAND Hier ziet u waar de gegevens zijn opgeslagen en of deze zijn opgeslagen als tekst. SELECTEREN Selecteert een telling van alle rijen waarin kolom t4 de waarde [FOUT] bevat. Belangrijk
Laat de databaseselectie standaard staan. In de voorbeelden in dit document wordt de standaarddatabase gebruikt die is opgenomen in HDInsight.
Als u de query wilt starten, selecteert u Uitvoeren onder het werkblad. De knop wordt oranje en de tekst verandert in Stoppen.
Nadat de query is voltooid, worden op het tabblad Resultaten de resultaten van de bewerking weergegeven. De volgende tekst is het resultaat van de query:
loglevel count [ERROR] 3U kunt het tabblad LOG gebruiken om de logboekgegevens weer te geven die door de taak zijn gemaakt.
Tip
Download of sla resultaten op uit de vervolgkeuzelijst Acties onder het tabblad Resultaten .
In visual wordt uitgelegd
Als u een visualisatie van het queryplan wilt weergeven, selecteert u het tabblad Visual Uitleg onder het werkblad.
De weergave Visual Uitleg van de query kan handig zijn bij het begrijpen van de stroom van complexe query's.
Tez-gebruikersinterface
Als u de Tez-gebruikersinterface voor de query wilt weergeven, selecteert u het tabblad Tez UI onder het werkblad.
Belangrijk
Tez wordt niet gebruikt om alle query's op te lossen. U kunt veel query's oplossen zonder Tez te gebruiken.
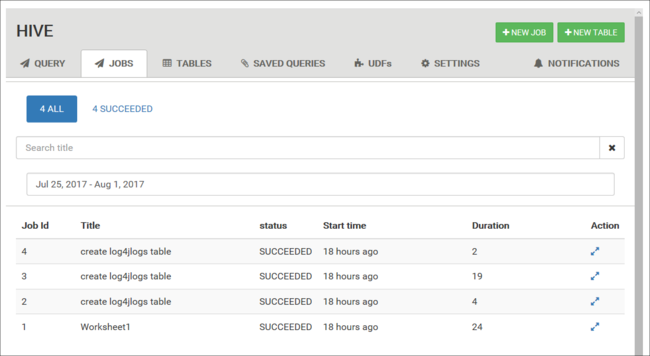
Taakgeschiedenis weergeven
Op het tabblad Taken wordt een geschiedenis van Hive-query's weergegeven.
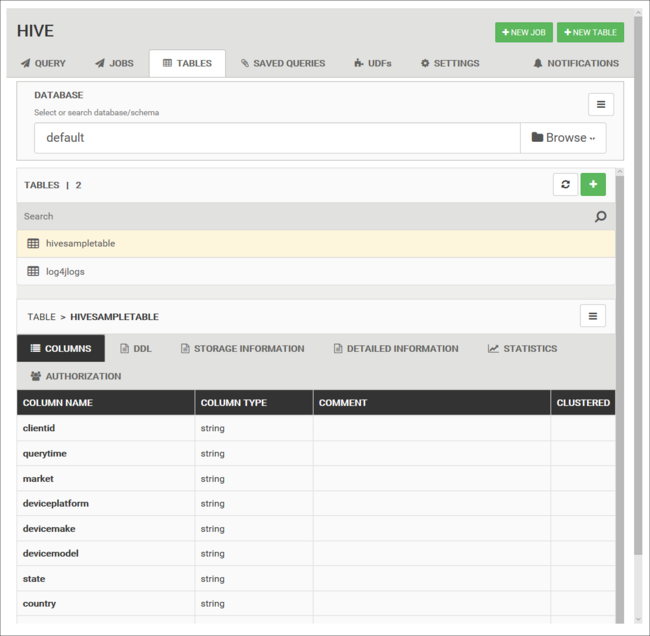
Databasetabellen
U kunt het tabblad Tabellen gebruiken om te werken met tabellen in een Hive-database.
Opgeslagen query's
Op het tabblad Query kunt u desgewenst query's opslaan. Nadat u een query hebt opgeslagen, kunt u deze opnieuw gebruiken op het tabblad Opgeslagen query's .
Tip
Opgeslagen query's worden opgeslagen in de standaardclusteropslag. U vindt de opgeslagen query's onder het pad /user/<username>/hive/scripts. Deze worden opgeslagen als tekstbestanden zonder opmaak .hql .
Als u het cluster verwijdert, maar de opslag behoudt, kunt u een hulpprogramma zoals Azure Storage Explorer of Data Lake Storage Explorer (vanuit Azure Portal) gebruiken om de query's op te halen.
Door de gebruiker gedefinieerde functies
U kunt Hive uitbreiden via door de gebruiker gedefinieerde functies (UDF). Gebruik een UDF om functionaliteit of logica te implementeren die niet eenvoudig kan worden gemodelleerd in HiveQL.
Declareer en sla een set UDF's op met behulp van het tabblad UDF boven aan de Hive-weergave. Deze UDF's kunnen worden gebruikt met de Power Query-editor.
Onder aan het Power Query-editor wordt een udfs-knop Invoegen weergegeven. In deze vermelding wordt een vervolgkeuzelijst weergegeven met de UDF's die zijn gedefinieerd in de Hive-weergave. Als u een UDF selecteert, worden HiveQL-instructies aan uw query toegevoegd om de UDF in te schakelen.
Als u bijvoorbeeld een UDF hebt gedefinieerd met de volgende eigenschappen:
Resourcenaam: myudfs
Resourcepad: /myudfs.jar
UDF-naam: myawesomeudf
UDF-klassenaam: com.myudfs.Awesome
Met de knop Udfs invoegen wordt een vermelding met de naam myudfs weergegeven, met een andere vervolgkeuzelijst voor elke UDF die voor die resource is gedefinieerd. In dit geval is het myawesomeudf. Als u deze vermelding selecteert, wordt het volgende toegevoegd aan het begin van de query:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Vervolgens kunt u de UDF in uw query gebruiken. Bijvoorbeeld: SELECT myawesomeudf(name) FROM people;.
Zie de volgende artikelen voor meer informatie over het gebruik van UDF's met Hive in HDInsight:
- Python gebruiken met Apache Hive en Apache Pig in HDInsight
- Een Java UDF gebruiken met Apache Hive in HDInsight
Hive-instellingen
U kunt verschillende Hive-instellingen wijzigen, zoals het wijzigen van de uitvoeringsengine voor Hive van Tez (de standaardinstelling) in MapReduce.
Volgende stappen
Voor algemene informatie over Hive in HDInsight:
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor