Azure Toolkit voor IntelliJ gebruiken om Apache Spark-toepassingen te maken voor HDInsight-cluster
In dit artikel wordt gedemonstreert hoe u Apache Spark-toepassingen in Azure HDInsight ontwikkelt met behulp van de invoegtoepassing Azure Toolkit voor de IntelliJ IDE. Azure HDInsight is een beheerde opensource-analyseservice in de cloud. Met de service kunt u opensource-frameworks gebruiken, zoals Hadoop, Apache Spark, Apache Hive en Apache Kafka.
U kunt de invoegtoepassing Azure Toolkit op een aantal manieren gebruiken:
- Een Scala Spark-toepassing ontwikkelen en verzenden naar een HDInsight Spark-cluster.
- Toegang tot uw Azure HDInsight Spark-clusterbronnen.
- Ontwikkel een Scala Spark-toepassing en voer deze lokaal uit.
In dit artikel leert u het volgende:
- De invoegtoepassing Azure-toolkit voor IntelliJ gebruiken
- Apache Spark-toepassingen ontwikkelen
- Een toepassing verzenden naar een Azure HDInsight-cluster
Vereisten
Een Apache Spark-cluster in HDInsight. Zie Apache Spark-clusters maken in Azure HDInsight voor instructies. Alleen HDInsight-clusters in de openbare cloud worden ondersteund, terwijl andere beveiligde cloudtypen (bijvoorbeeld overheidsclouds) niet zijn.
Oracle Java Development Kit. In dit artikel wordt Java-versie 8.0.202 gebruikt.
IntelliJ IDEA. In dit artikel wordt gebruikgemaakt van IntelliJ IDEA Community 2018.3.4.
Azure-toolkit voor IntelliJ. Zie Installing the Azure Toolkit for IntelliJ (De Azure Toolkit voor IntelliJ installeren).
Scala-invoegtoepassing voor IntelliJ IDEA installeren
Stappen voor het installeren van de Scala-invoegtoepassing:
Open IntelliJ IDEA.
Ga op het welkomstscherm naar Configure>Plugins om het venster Plugins te openen.
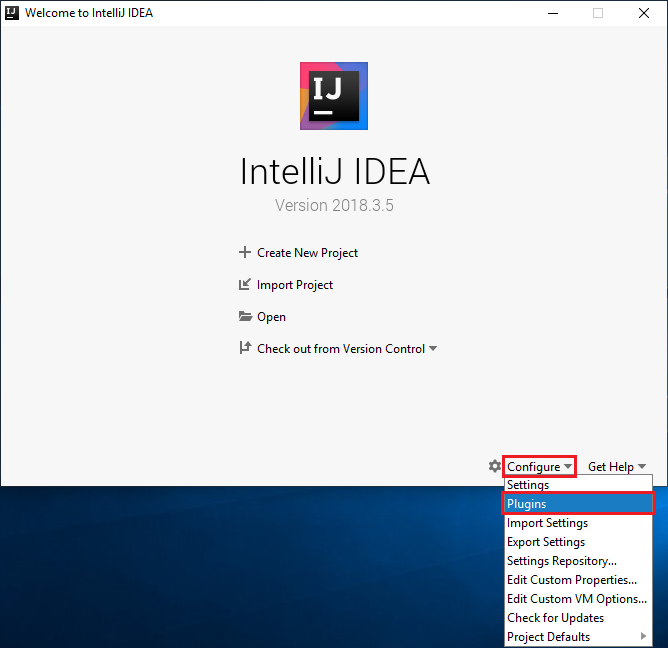
Selecteer Install voor de Scala-invoegtoepassing die in het nieuwe venster wordt weergegeven.
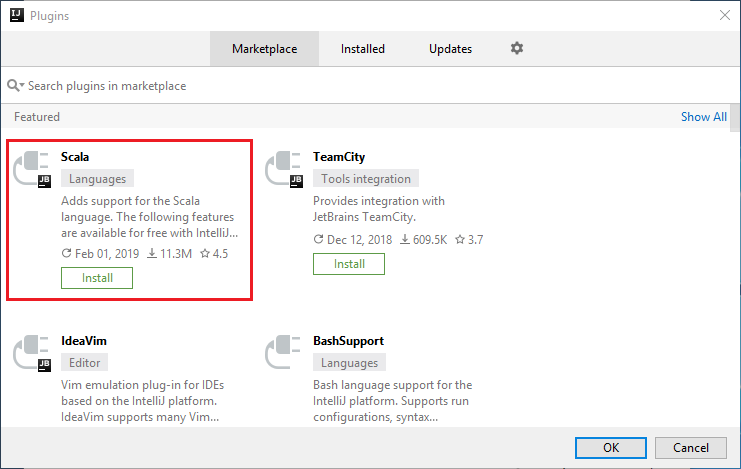
Als de invoegtoepassing is geïnstalleerd, moet u de IDE opnieuw starten.
Een Spark Scala-toepassing maken voor een HDInsight Spark-cluster
Start IntelliJ IDEA en selecteer Create New Project om het venster New Project te openen.
Selecteer Azure Spark/HDInsight in het linkerdeelvenster.
Selecteer Spark Project (Scala) in het hoofdvenster.
Selecteer in de vervolgkeuzelijst Build tool een van de volgende opties:
Maven, voor de ondersteuning van de wizard Scala-project maken.
SBT, voor het beheren van de afhankelijkheden en het maken van het Scala-project.
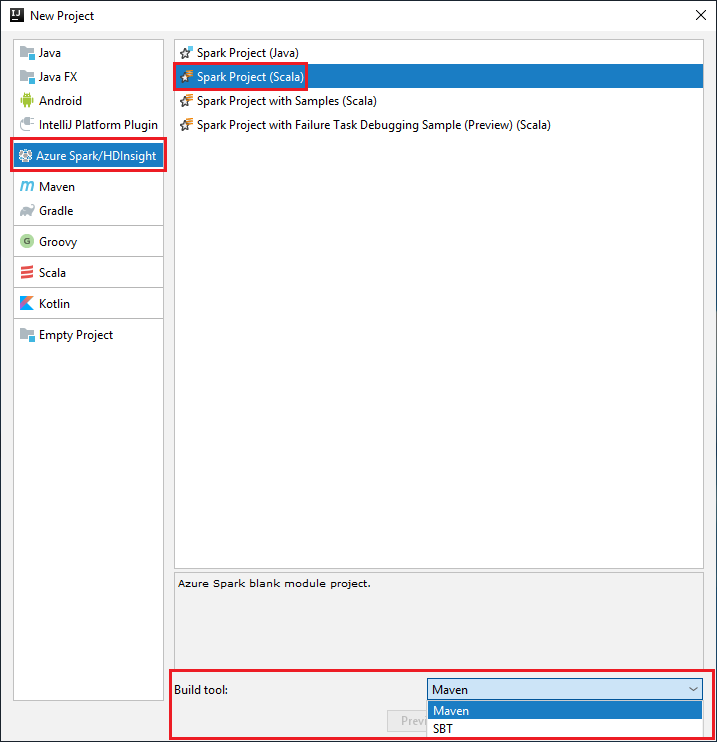
Selecteer Volgende.
Geef in het venster New project de volgende gegevens op:
Eigenschappen Beschrijving Projectnaam Voer een naam in. In dit artikel wordt gebruikgemaakt van myApp.Projectlocatie Voer de locatie in om uw project in op te slaan. Project SDK Dit veld is mogelijk leeg bij uw eerste gebruik van IDEA. Selecteer New... en ga naar uw JDK. Spark-versie De wizard voor het maken van het project integreert de juiste versie voor Spark SDK en Scala SDK. Selecteer Spark 1.x als de Spark-clusterversie ouder is dan 2.0. Selecteer anders Spark 2.x. In dit voorbeeld wordt Spark 2.3.0 (Scala 2.11.8) gebruikt. 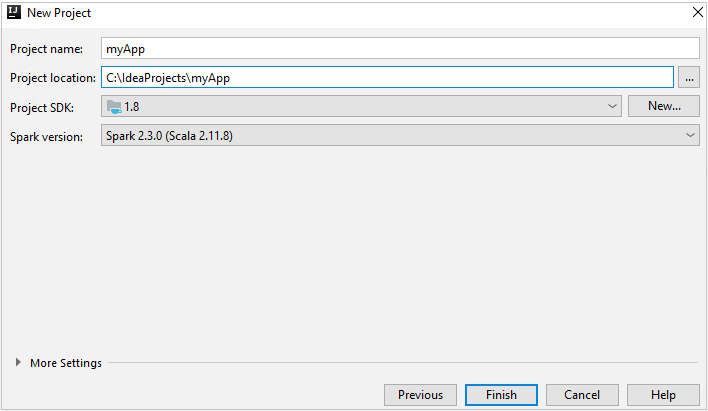
Selecteer Voltooien. Het kan enkele minuten duren voordat het project beschikbaar wordt.
Het Spark-project maakt automatisch een artefact voor u. Ga als volgt te werk om het artefact weer te geven:
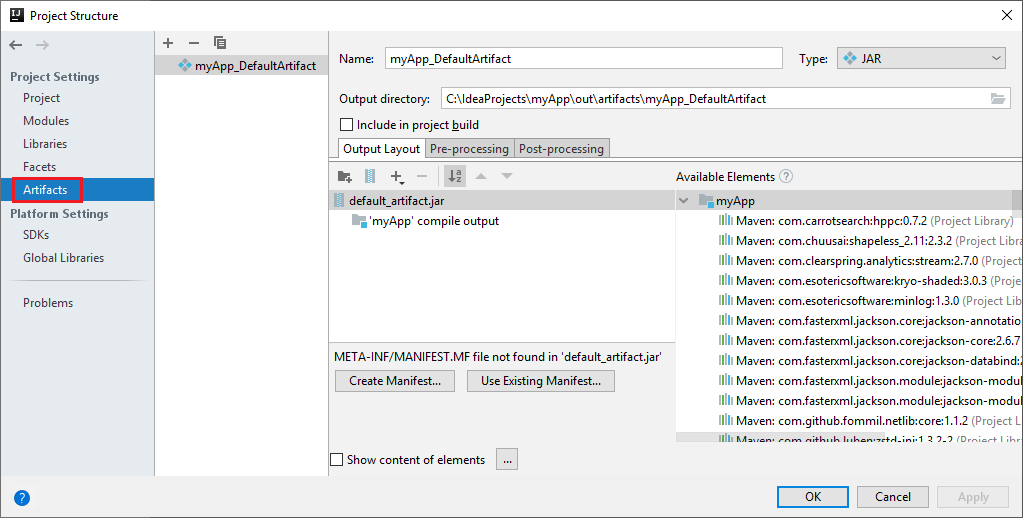
a. Navigeer in de menubalk naar Bestand>Projectstructuur....
b. Selecteer in het venster Projectstructuur de optie Artefacten.
c. Selecteer Annuleren nadat u het artefact hebt bekeken.
Voeg de broncode van uw toepassing toe door de volgende stappen uit te voeren:
a. Navigeer vanuit Project naar myApp>src>main>scala.
b. Klik met de rechtermuisknop op Scala en navigeer naar Nieuwe>Scala-klasse.
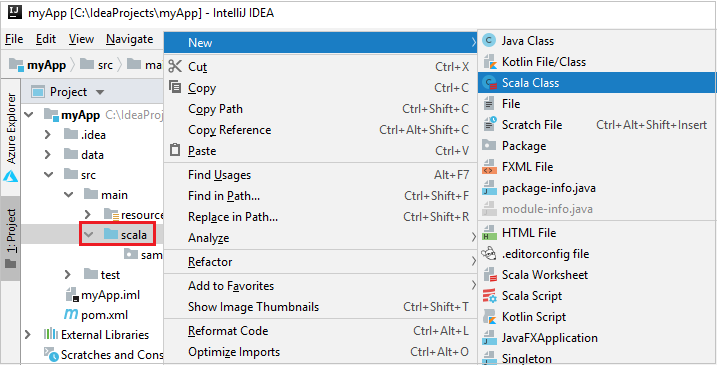
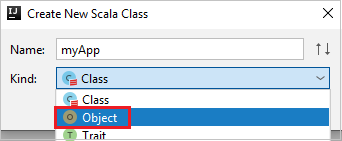
c. Geef in het dialoogvenster Nieuwe Scala-klasse maken een naam op, selecteer Object in de vervolgkeuzelijst Kind en selecteer VERVOLGENS OK.
d. Het bestand myApp.scala wordt vervolgens geopend in de hoofdweergave. Vervang de standaardcode door de onderstaande code:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }De code leest de gegevens uit HVAC.csv (beschikbaar op alle HDInsight Spark-clusters), haalt de rijen op met slechts één cijfer in de zevende kolom in het CSV-bestand en schrijft de uitvoer naar
/HVACOutonder de standaardopslagcontainer voor het cluster.
Verbinding maken naar uw HDInsight-cluster
De gebruiker kan zich aanmelden bij uw Azure-abonnement of een HDInsight-cluster koppelen. Gebruik de ambari-referenties voor gebruikersnaam/wachtwoord of domein om verbinding te maken met uw HDInsight-cluster.
Aanmelden bij uw Azure-abonnement
Navigeer in de menubalk naar Beeld>Hulpprogrammavensters>Azure Explorer.
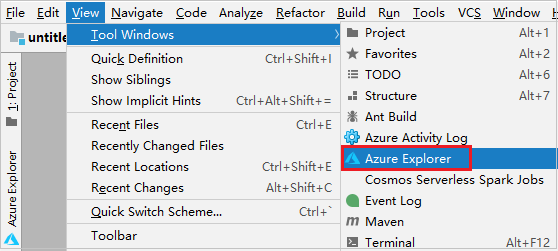
Klik in Azure Explorer met de rechtermuisknop op het knooppunt Azure en selecteer Aanmelden.
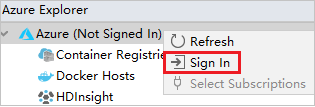
Kies in het dialoogvenster Azure-aanmelding de optie Apparaataanmelding en selecteer Aanmelden.
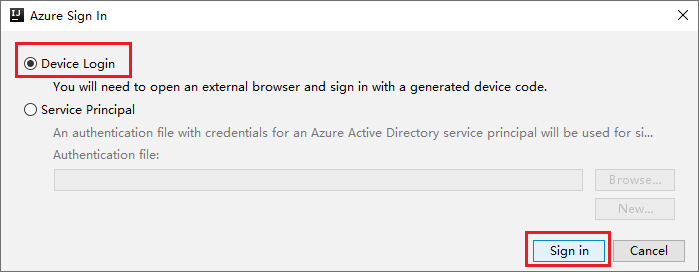
Klik in het dialoogvenster Azure-apparaataanmelding op Kopiëren en openen.
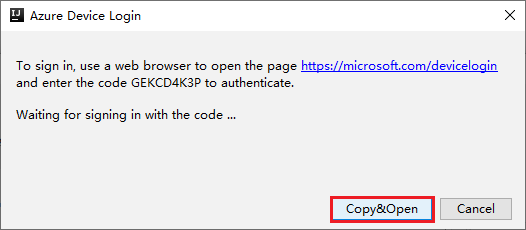
Plak de code in de browserinterface en klik op Volgende.
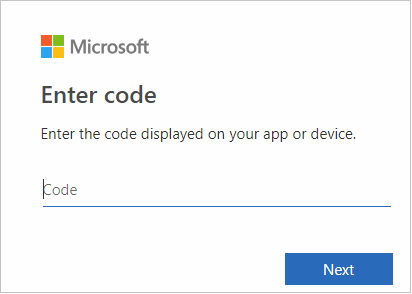
Voer uw referenties voor Azure in en sluit de browser.
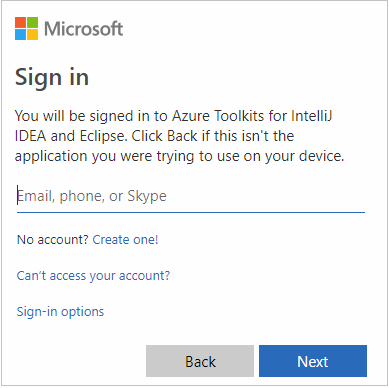
Zodra u bent aangemeld, toont het dialoogvenster Abonnementen selecteren alle Azure-abonnementen die aan de referenties zijn gekoppeld. Selecteer uw abonnement en selecteer vervolgens de knop Selecteren .
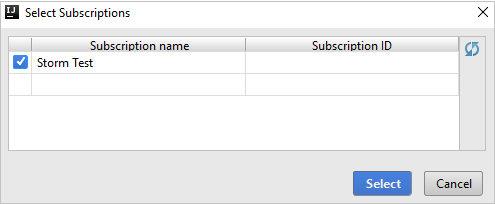
Vouw vanuit Azure Explorer HDInsight uit om de HDInsight Spark-clusters weer te geven die zich in uw abonnementen bevinden.
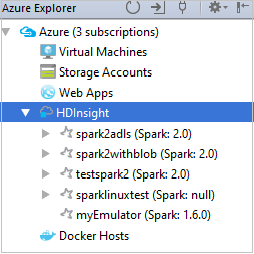
Als u de resources (bijvoorbeeld opslagaccounts) wilt weergeven die aan het cluster zijn gekoppeld, kunt u een clusternaamknooppunt verder uitbreiden.
Een cluster koppelen
U kunt een HDInsight-cluster koppelen met behulp van de door Apache Ambari beheerde gebruikersnaam. Op dezelfde manier kunt u voor een HDInsight-cluster dat lid is van een domein een koppeling maken met behulp van het domein en de gebruikersnaam, zoals user1@contoso.com. U kunt ook een Livy Service-cluster koppelen.
Navigeer in de menubalk naar Beeld>Hulpprogrammavensters>Azure Explorer.
Klik in Azure Explorer met de rechtermuisknop op het HDInsight-knooppunt en selecteer Vervolgens Een cluster koppelen.
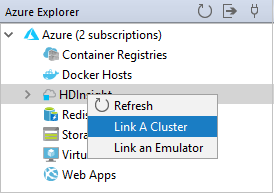
De beschikbare opties in het venster Een cluster koppelen variëren, afhankelijk van de waarde die u selecteert in de vervolgkeuzelijst Resourcetype koppelen. Voer uw waarden in en selecteer VERVOLGENS OK.
HDInsight-cluster
Eigenschappen Weergegeven als Resourcetype koppelen Selecteer HDInsight-cluster in de vervolgkeuzelijst. Clusternaam/URL Voer de clusternaam in. Verificatietype Laten staan als basisverificatie Gebruikersnaam Voer de gebruikersnaam van het cluster in, de standaardwaarde is beheerder. Wachtwoord Voer een wachtwoord in voor de gebruikersnaam. 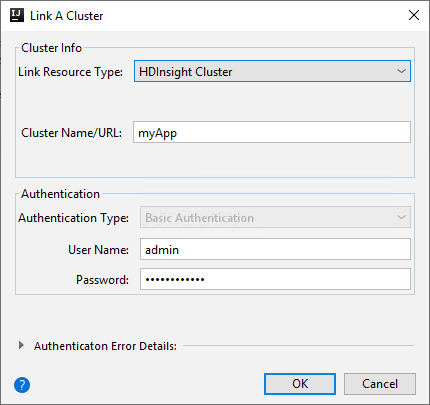
Livy Service
Eigenschappen Weergegeven als Resourcetype koppelen Selecteer Livy Service in de vervolgkeuzelijst. Livy-eindpunt Livy-eindpunt invoeren Clusternaam Voer de clusternaam in. Yarn-eindpunt Optioneel. Verificatietype Laten staan als basisverificatie Gebruikersnaam Voer de gebruikersnaam van het cluster in, de standaardwaarde is beheerder. Wachtwoord Voer een wachtwoord in voor de gebruikersnaam. 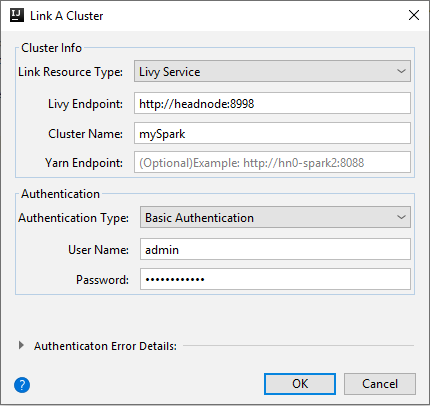
U kunt uw gekoppelde cluster zien vanaf het HDInsight-knooppunt .
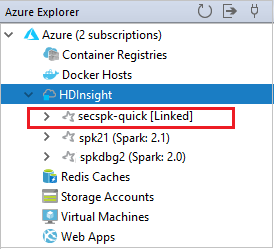
U kunt een cluster ook ontkoppelen vanuit Azure Explorer.
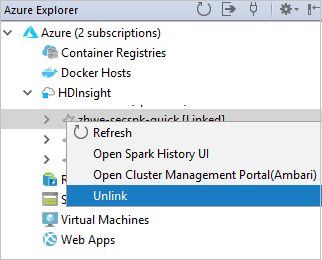
Een Spark Scala-toepassing uitvoeren op een HDInsight Spark-cluster
Nadat u een Scala-toepassing hebt gemaakt, kunt u deze verzenden naar het cluster.
Navigeer in Project naar myApp>src>main>scala>myApp. Klik met de rechtermuisknop op myApp en selecteer Spark-toepassing verzenden (deze bevindt zich waarschijnlijk onderaan de lijst).
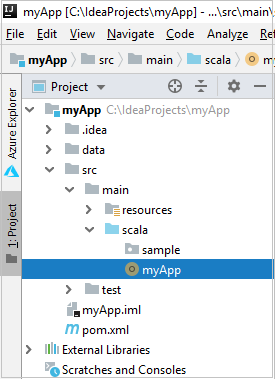
Selecteer 1 in het dialoogvenster Spark-toepassing verzenden. Spark in HDInsight.
Geef in het venster Configuratie bewerken de volgende waarden op en selecteer VERVOLGENS OK:
Eigenschappen Weergegeven als Spark-clusters (alleen Linux) Selecteer het HDInsight Spark-cluster waarop u uw toepassing wilt uitvoeren. Selecteer een artefact om te verzenden Laat de standaardinstelling staan. Hoofdklassenaam De standaardwaarde is de hoofdklasse uit het geselecteerde bestand. U kunt de klasse wijzigen door het beletselteken (...) te selecteren en een andere klasse te kiezen. Taakconfiguraties U kunt de standaardsleutels en of waarden wijzigen. Zie Apache Livy REST API voor meer informatie. Opdrachtregelargumenten U kunt voor de hoofdklasse argumenten invoeren, gescheiden door een spatie, indien nodig. JAR’s en bestanden waarnaar wordt verwezen U kunt de paden invoeren voor de JAR’s en bestanden waarnaar wordt verwezen, indien aanwezig. U kunt ook bladeren door bestanden in het virtuele Azure-bestandssysteem, dat momenteel alleen ONDERSTEUNING biedt voor ADLS Gen 2-cluster. Voor meer informatie: Apache Spark-configuratie. Zie ook het uploaden van resources naar het cluster. Opslag van taakuploads Vouw uit om aanvullende opties te onthullen. Opslagtype Selecteer Azure Blob gebruiken om te uploaden in de vervolgkeuzelijst. Opslagaccount Voer uw opslagaccount in. Opslagsleutel Voer uw opslagsleutel in. Opslagcontainer Selecteer uw opslagcontainer in de vervolgkeuzelijst zodra Opslagaccount en Opslagsleutel zijn ingevoerd. 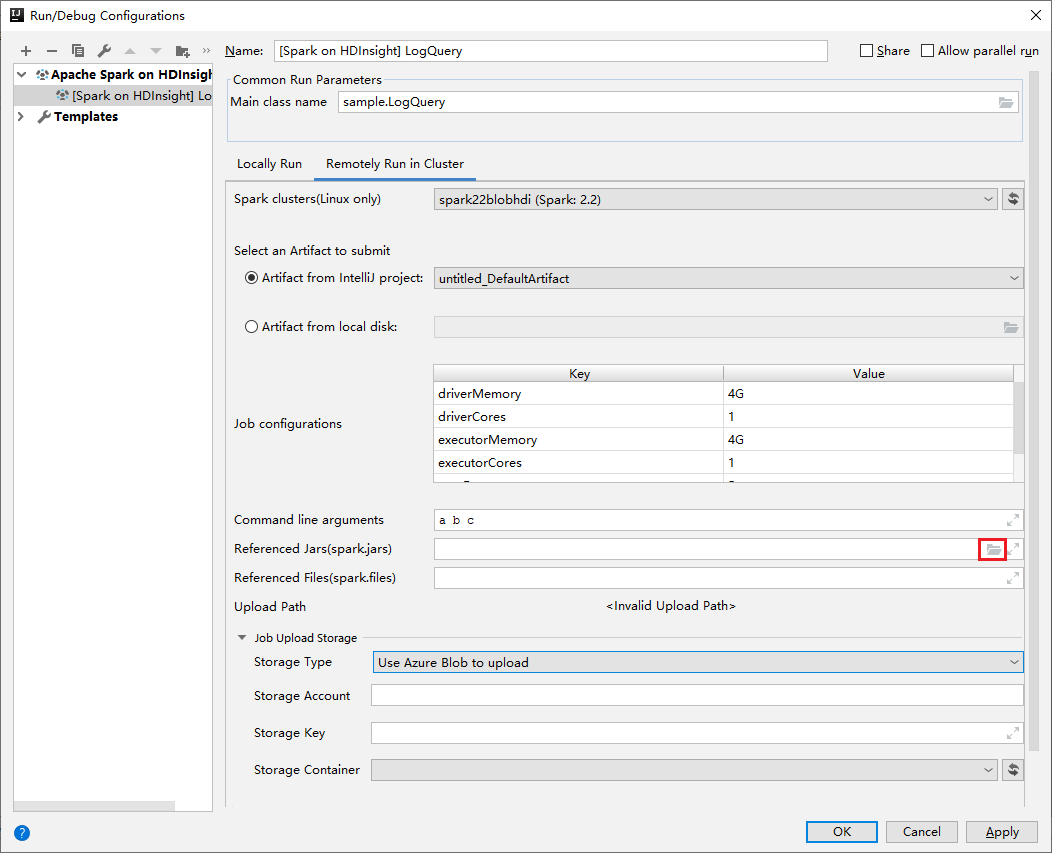
Selecteer SparkJobRun om uw project naar het geselecteerde cluster te verzenden. Onderaan het tabblad Externe Spark-taak in cluster wordt de voortgang van de taakuitvoering weergegeven. U kunt de toepassing stoppen door op de rode knop te klikken.
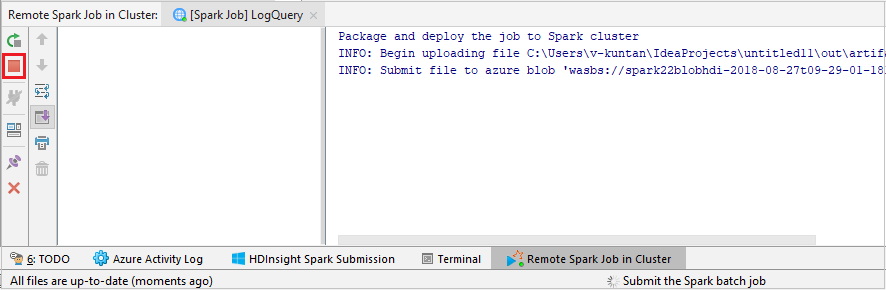
Fouten opsporen in Apache Spark-toepassingen lokaal of extern in een HDInsight-cluster
We raden ook een andere manier aan om de Spark-toepassing naar het cluster te verzenden. U kunt dit doen door de parameters in te stellen in de IDE voor uitvoeren/foutopsporingsconfiguraties . Zie Fouten opsporen in Apache Spark-toepassingen lokaal of extern op een HDInsight-cluster met Azure Toolkit voor IntelliJ via SSH.
HDInsight Spark-clusters openen en beheren met behulp van Azure Toolkit voor IntelliJ
U kunt verschillende bewerkingen uitvoeren met behulp van Azure Toolkit voor IntelliJ. De meeste bewerkingen worden gestart vanuit Azure Explorer. Navigeer in de menubalk naar Beeld>Hulpprogrammavensters>Azure Explorer.
Toegang tot de taakweergave
Navigeer vanuit Azure Explorer naar HDInsight<>Uw clustertaken.>>
In het rechterdeelvenster worden op het tabblad Spark-taakweergave alle toepassingen weergegeven die op het cluster zijn uitgevoerd. Selecteer de naam van de toepassing waarvoor u meer details wilt zien.
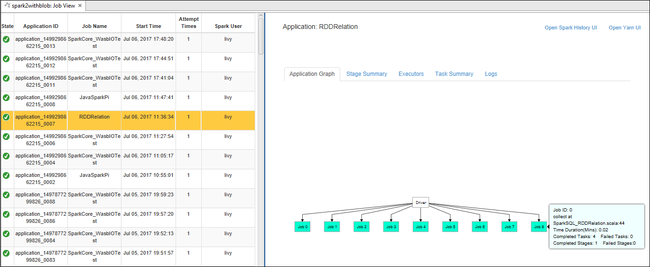
Als u algemene taakgegevens wilt weergeven, beweegt u de muisaanwijzer over de taakgrafiek. Als u de fasegrafiek en informatie wilt bekijken die door elke taak wordt gegenereerd, selecteert u een knooppunt in de taakgrafiek.
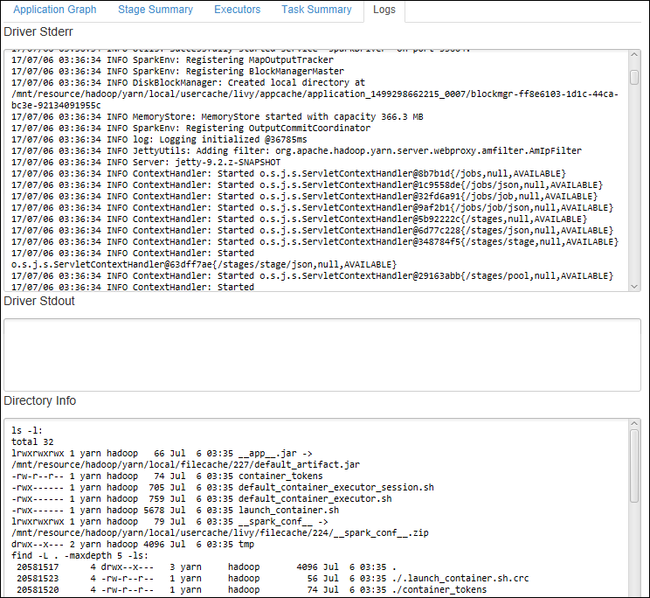
Als u veelgebruikte logboeken, zoals Driver Stderr, Driver Stdout en Directory Info, wilt weergeven, selecteert u het tabblad Logboek .
U kunt de gebruikersinterface van de Spark-geschiedenis en de YARN-gebruikersinterface bekijken (op toepassingsniveau). Selecteer een koppeling boven aan het venster.
Toegang tot de Spark-geschiedenisserver
Vouw IN Azure Explorer HDInsight uit, klik met de rechtermuisknop op de naam van uw Spark-cluster en selecteer vervolgens De gebruikersinterface voor Spark-geschiedenis openen.
Wanneer u hierom wordt gevraagd, voert u de beheerdersreferenties van het cluster in, die u hebt opgegeven bij het instellen van het cluster.
Op het dashboard van de Spark-geschiedenisserver kunt u de naam van de toepassing gebruiken om te zoeken naar de toepassing die u zojuist hebt uitgevoerd. In de voorgaande code stelt u de naam van de toepassing in met behulp van
val conf = new SparkConf().setAppName("myApp"). De naam van uw Spark-toepassing is myApp.
De Ambari-portal starten
Vouw IN Azure Explorer HDInsight uit, klik met de rechtermuisknop op de naam van uw Spark-cluster en selecteer vervolgens De Portal voor clusterbeheer (Ambari) openen.
Wanneer u hierom wordt gevraagd, voert u de beheerdersreferenties voor het cluster in. U hebt deze referenties opgegeven tijdens het installatieproces van het cluster.
Azure-abonnementen beheren
Azure Toolkit voor IntelliJ bevat standaard de Spark-clusters van al uw Azure-abonnementen. Indien nodig kunt u de abonnementen opgeven waartoe u toegang wilt krijgen.
Klik in Azure Explorer met de rechtermuisknop op het Azure-hoofdknooppunt en selecteer Vervolgens Abonnementen selecteren.
Schakel in het venster Abonnementen selecteren de selectievakjes uit naast de abonnementen die u niet wilt openen en selecteer vervolgens Sluiten.
Spark-console
U kunt de lokale Spark-console (Scala) uitvoeren of de interactieve Spark Livy-sessieconsole (Scala) uitvoeren.
Lokale Spark-console (Scala)
Verzeker dat u aan de WINUTILS.EXE-vereiste voldoet.
Navigeer in de menubalk naar Uitvoeren>Configuraties bewerken....
Navigeer in het venster Uitvoeren/foutopsporingsconfiguraties in het linkerdeelvenster naar Apache Spark in HDInsight>[Spark in HDInsight] myApp.
Selecteer het tabblad in het
Locally Runhoofdvenster.Geef de volgende waarden op en selecteer OK:
Eigenschappen Weergegeven als Hoofdklasse taak De standaardwaarde is de hoofdklasse uit het geselecteerde bestand. U kunt de klasse wijzigen door het beletselteken (...) te selecteren en een andere klasse te kiezen. Omgevingsvariabelen Verzeker dat de waarde voor HADOOP_HOME correct is. WINUTILS.exe-locatie Verzeker dat het pad correct is. 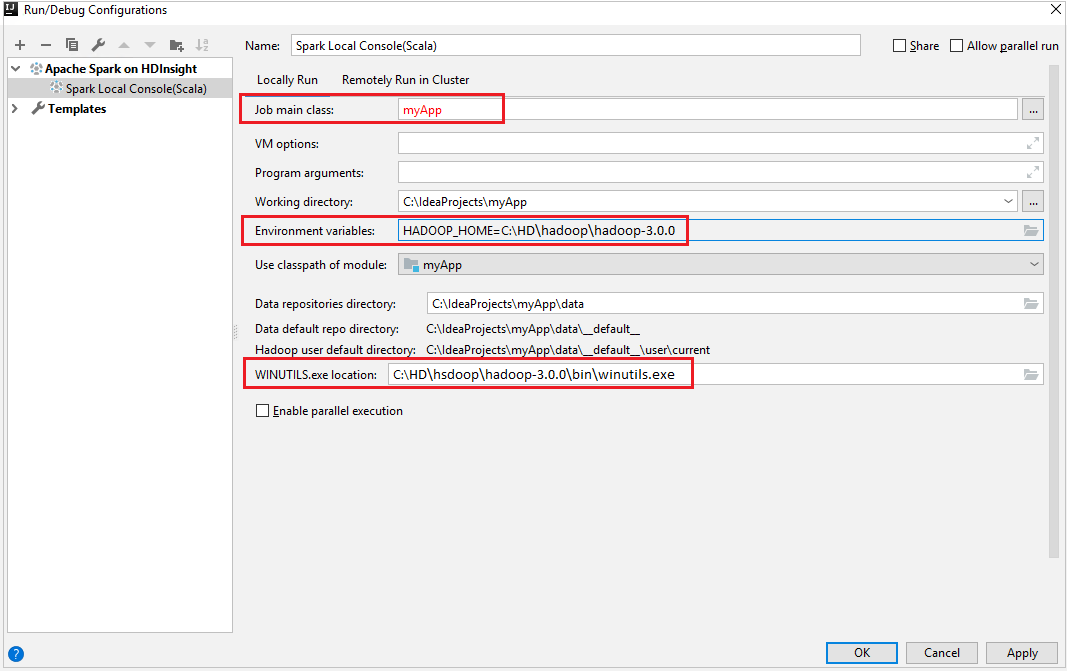
Navigeer in Project naar myApp>src>main>scala>myApp.
Navigeer in de menubalk naar De Spark-console van de Spark-console>met hulpprogramma's>, lokale Spark-console (Scala) uitvoeren.
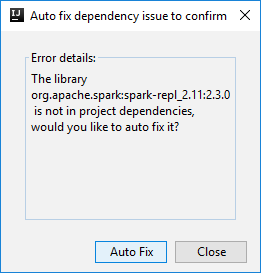
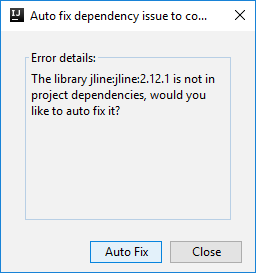
Er kunnen dan twee dialoogvensters worden weergegeven waarin u wordt gevraagd of u afhankelijkheden automatisch wilt oplossen. Als u dat wilt doen, selecteert u Automatisch oplossen.
De console moet er ongeveer uitzien zoals in de onderstaande afbeelding. Typ
sc.appNamein het consolevenster en druk op Ctrl+Enter. Het resultaat wordt weergegeven. U kunt de lokale console beëindigen door op de rode knop te klikken.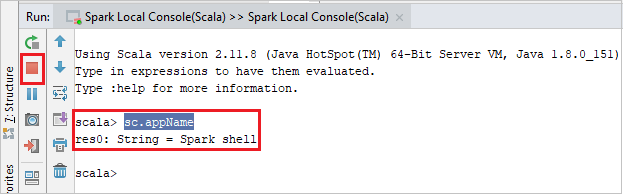
Spark Livy Interactive Session Console (Scala)
Navigeer in de menubalk naar Uitvoeren>Configuraties bewerken....
Navigeer in het venster Uitvoeren/foutopsporingsconfiguraties in het linkerdeelvenster naar Apache Spark in HDInsight>[Spark in HDInsight] myApp.
Selecteer het tabblad in het
Remotely Run in Clusterhoofdvenster.Geef de volgende waarden op en selecteer OK:
Eigenschappen Weergegeven als Spark-clusters (alleen Linux) Selecteer het HDInsight Spark-cluster waarop u uw toepassing wilt uitvoeren. Hoofdklassenaam De standaardwaarde is de hoofdklasse uit het geselecteerde bestand. U kunt de klasse wijzigen door het beletselteken (...) te selecteren en een andere klasse te kiezen. 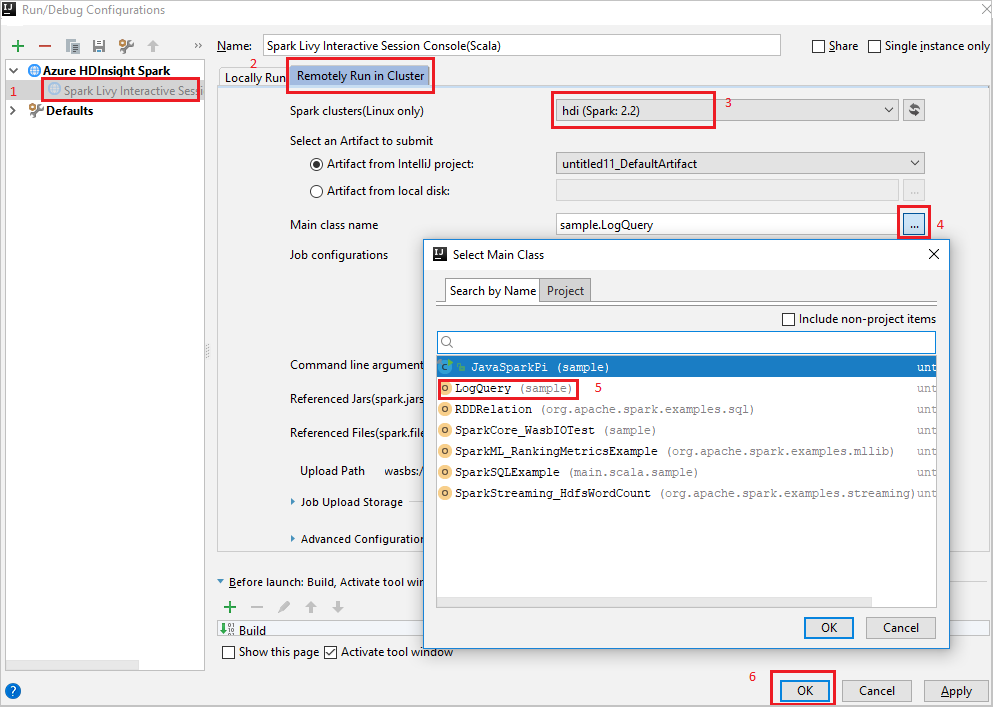
Navigeer in Project naar myApp>src>main>scala>myApp.
Navigeer in de menubalk naar Tools>Spark Console>Run Spark Livy Interactive Session Console(Scala).
De console moet er ongeveer uitzien zoals in de onderstaande afbeelding. Typ
sc.appNamein het consolevenster en druk op Ctrl+Enter. Het resultaat wordt weergegeven. U kunt de lokale console beëindigen door op de rode knop te klikken.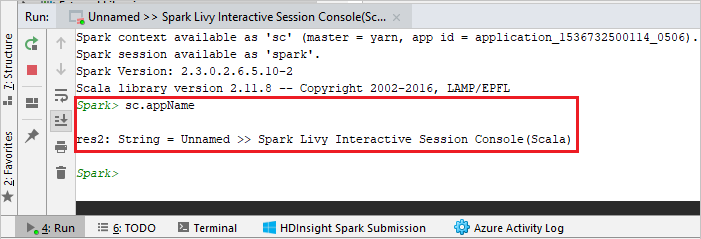
Selectie verzenden naar Spark-console
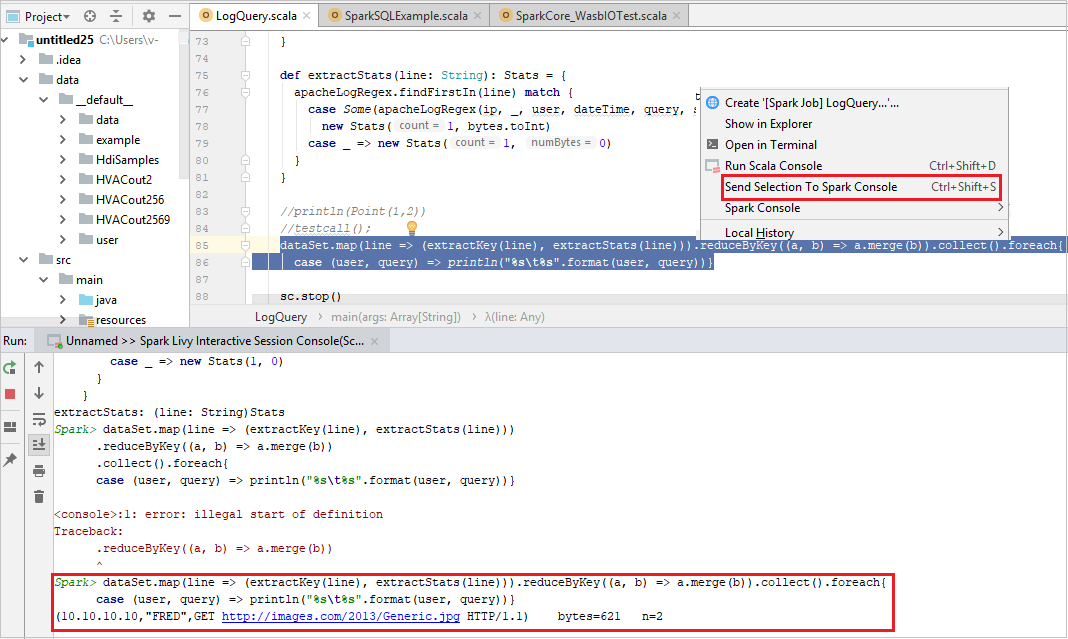
Het is handig voor u om het scriptresultaat te voorzien door wat code naar de lokale console of de interactieve Livy-sessieconsole (Scala) te verzenden. U kunt code markeren in het Scala-bestand en vervolgens met de rechtermuisknop op Selectie verzenden naar Spark-console klikken. De geselecteerde code wordt naar de console verzonden. Het resultaat wordt achter de code weergegeven in de console. De console controleert de fouten, indien aanwezig.
Integreren met HDInsight Identity Broker (HIB)
Verbinding maken naar uw HDInsight ESP-cluster met ID Broker (HIB)
U kunt de normale stappen volgen om u aan te melden bij een Azure-abonnement om verbinding te maken met uw HDInsight ESP-cluster met ID Broker (HIB). Nadat u zich hebt aangemeld, ziet u de lijst met clusters in Azure Explorer. Zie Verbinding maken naar uw HDInsight-cluster voor meer instructies.
Een Spark Scala-toepassing uitvoeren op een HDInsight ESP-cluster met ID Broker (HIB)
U kunt de normale stappen volgen om een taak naar het HDInsight ESP-cluster te verzenden met ID Broker (HIB). Raadpleeg Een Spark Scala-toepassing uitvoeren op een HDInsight Spark-cluster voor meer instructies.
We uploaden de benodigde bestanden naar een map met de naam van uw aanmeldingsaccount en u kunt het uploadpad in het configuratiebestand zien.

Spark-console op een HDInsight ESP-cluster met ID Broker (HIB)
U kunt de lokale Spark-console (Scala) uitvoeren of Spark Livy Interactive Session Console (Scala) uitvoeren op een HDInsight ESP-cluster met ID Broker (HIB). Raadpleeg de Spark-console voor meer instructies.
Notitie
Voor het HDInsight ESP-cluster met Id Broker (HIB) wordt het koppelen van een cluster en het opsporen van fouten in Apache Spark-toepassingen op afstand niet ondersteund.
Rol alleen lezer
Wanneer gebruikers een taak verzenden naar een cluster met alleen-lezenrolmachtigingen, zijn Ambari-referenties vereist.
Cluster koppelen vanuit contextmenu
Meld u aan met het rolaccount alleen-lezen.
Vouw vanuit Azure Explorer HDInsight uit om HDInsight-clusters weer te geven die zich in uw abonnement bevinden. De clusters die als Rol:Lezer zijn gemarkeerd , hebben alleen de rolmachtigingen van de lezer.
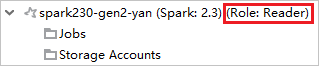
Klik met de rechtermuisknop op het cluster met de machtiging alleen-lezenrol. Selecteer Dit cluster koppelen in het contextmenu om het cluster te koppelen. Voer de Ambari-gebruikersnaam en het wachtwoord in.
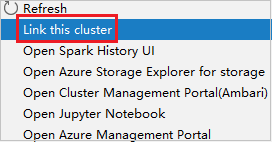
Als het cluster is gekoppeld, wordt HDInsight vernieuwd. De fase van het cluster wordt gekoppeld.
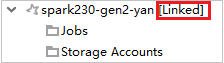
Cluster koppelen door het knooppunt Taken uit te vouwen
Klik op het knooppunt Jobs , het venster Clustertaaktoegang geweigerd wordt weergegeven.
Klik op Dit cluster koppelen om het cluster te koppelen.

Cluster koppelen vanuit het venster Uitvoeren/Foutopsporingsconfiguraties
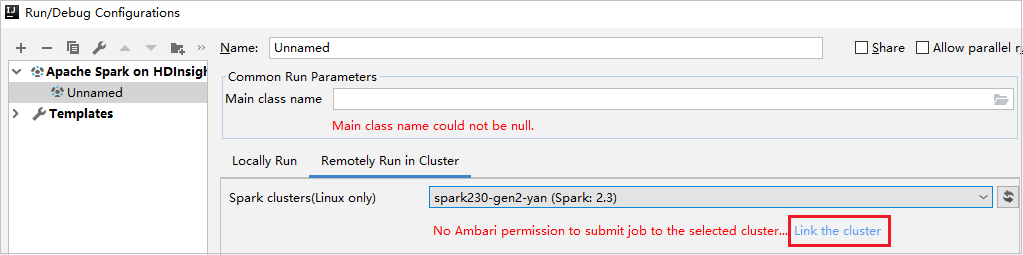
Maak een HDInsight-configuratie. Selecteer vervolgens Extern uitvoeren in cluster.
Selecteer een cluster met alleen-lezenrolmachtigingen voor Spark-clusters (alleen Linux). Waarschuwingsbericht wordt weergegeven. U kunt op Dit cluster koppelen klikken om een cluster te koppelen.
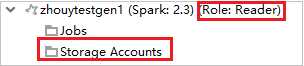
Opslagaccounts weergeven
Klik voor clusters met de machtiging alleen-lezenrol op Het knooppunt Opslagaccounts , het venster Toegang geweigerd voor opslag wordt weergegeven. U kunt op Azure Storage Explorer openen klikken om Storage Explorer te openen.

Klik voor gekoppelde clusters op het knooppunt Opslagaccounts , het venster Toegang geweigerd voor opslag wordt weergegeven. U kunt op Azure Storage openen klikken om Storage Explorer te openen.

Bestaande IntelliJ IDEA-toepassingen converteren om Azure Toolkit voor IntelliJ te gebruiken
U kunt de bestaande Spark Scala-toepassingen die u in IntelliJ IDEA hebt gemaakt, converteren om compatibel te zijn met Azure Toolkit voor IntelliJ. Vervolgens kunt u de invoegtoepassing gebruiken om de toepassingen naar een HDInsight Spark-cluster te verzenden.
Open het bijbehorende
.imlbestand voor een bestaande Spark Scala-toepassing die is gemaakt via IntelliJ IDEA.Op hoofdniveau is een module-element zoals de volgende tekst:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Bewerk het element dat u wilt toevoegen
UniqueKey="HDInsightTool", zodat het moduleelement eruitziet als de volgende tekst:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">De wijzigingen opslaan. Uw toepassing moet nu compatibel zijn met Azure Toolkit voor IntelliJ. U kunt deze testen door met de rechtermuisknop op de projectnaam in Project te klikken. Het snelmenu bevat nu de optie Spark-toepassing verzenden naar HDInsight.
Resources opschonen
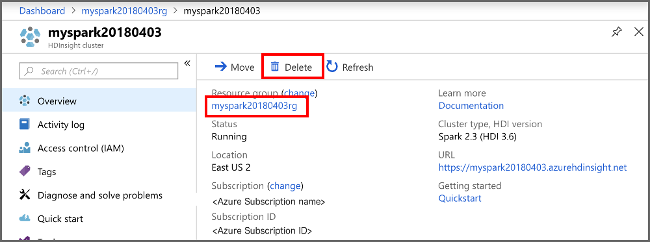
Als u deze toepassing verder niet meer gebruikt, verwijdert u het cluster dat u hebt gemaakt, via de volgende stappen:
Meld u aan bij het Azure-portaal.
Typ HDInsight in het Zoekvak bovenaan.
Selecteer onder Services de optie HDInsight-clusters.
Selecteer in de lijst met HDInsight-clusters die worden weergegeven de ... naast het cluster dat u voor dit artikel hebt gemaakt.
Selecteer Verwijderen. Selecteer Ja.
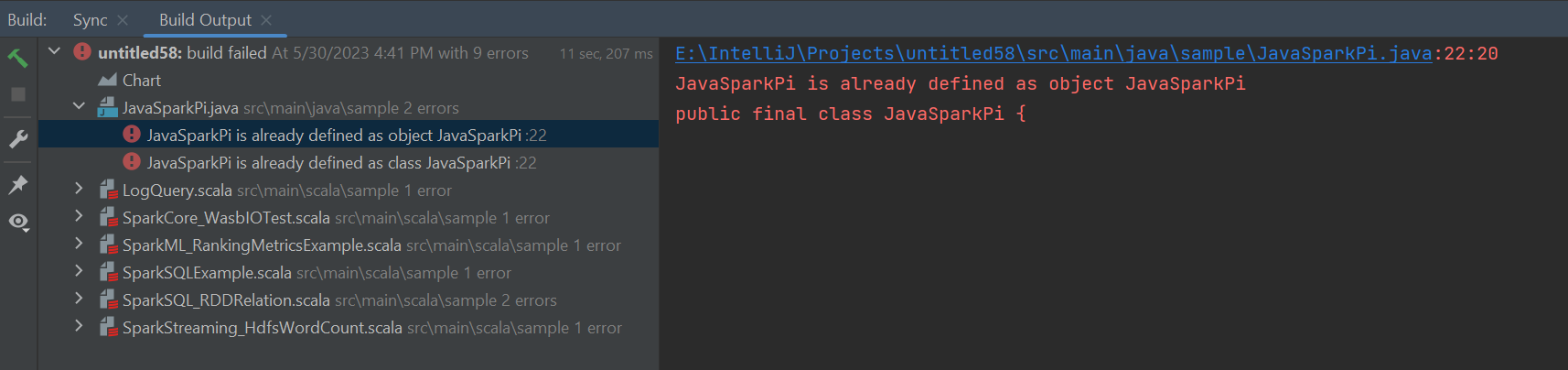
Fouten en oplossing
Maak de markering van de src-map ongedaan als bronnen als u fouten met de build mislukt krijgt, zoals hieronder:
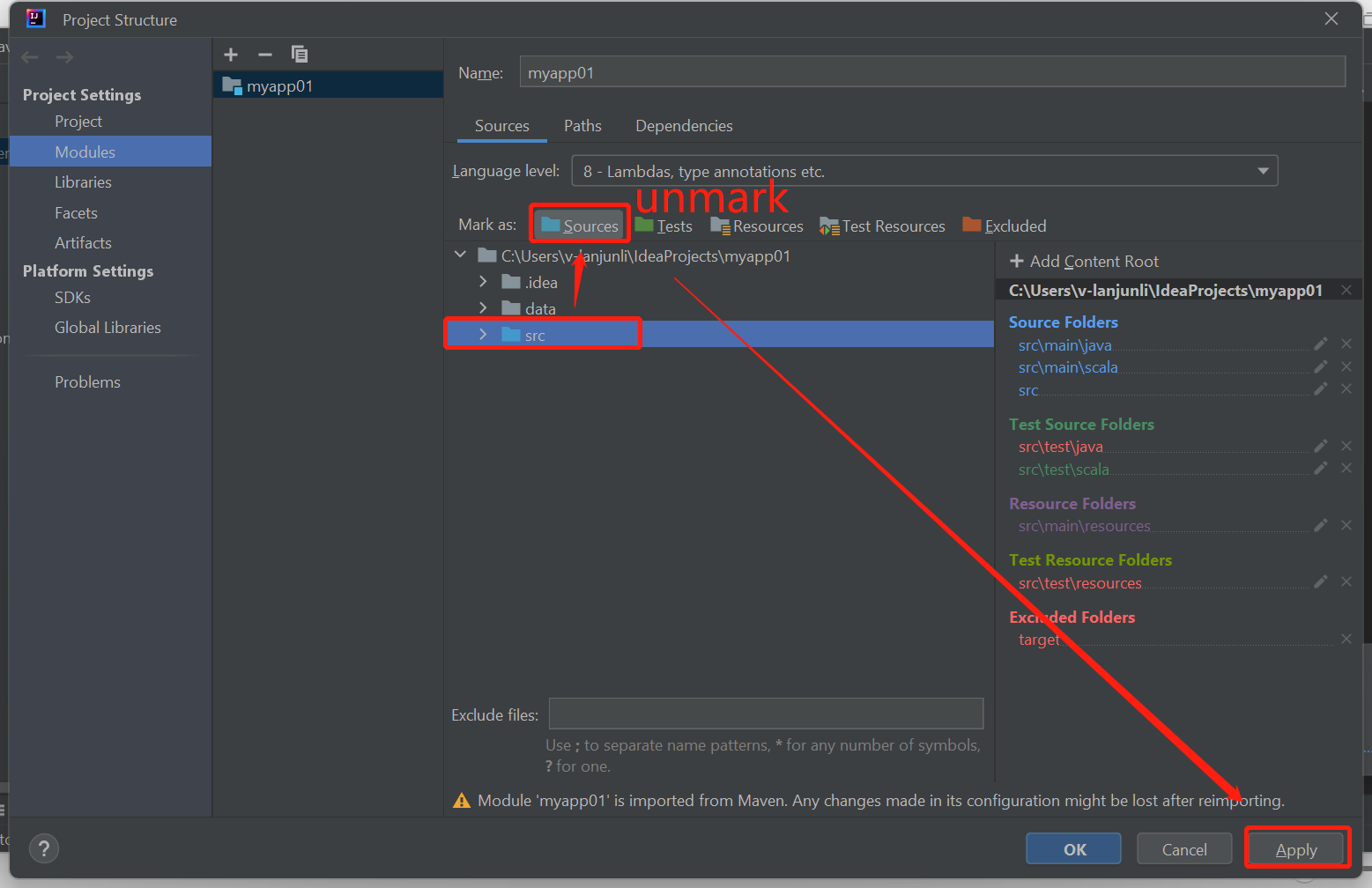
Hef de markering van de src-map op als bronnen om dit probleem op te lossen:
Navigeer naar Bestand en selecteer de projectstructuur.
Selecteer de modules onder het project Instellingen.
Selecteer het src-bestand en hef de markering op als bronnen.
Klik op De knop Toepassen en klik vervolgens op ok om het dialoogvenster te sluiten.
Volgende stappen
In dit artikel hebt u geleerd hoe u de Azure-toolkit voor IntelliJ-invoegtoepassing kunt gebruiken om Apache Spark-toepassingen te ontwikkelen die zijn geschreven in Scala. Stuur ze vervolgens rechtstreeks vanuit de IntelliJ Integrated Development Environment (IDE) naar een HDInsight Spark-cluster. Ga naar het volgende artikel om te zien hoe de gegevens die u hebt geregistreerd in Apache Spark kunnen worden overgebracht naar een BI-hulpprogramma voor analyse zoals Power BI.