Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel leert u hoe u Jupyter Notebook installeert met de aangepaste PySpark-kernels (voor Python) en Apache Spark (voor Scala) met Spark Magic. Vervolgens verbindt u het notebook met een HDInsight-cluster.
Er zijn vier belangrijke stappen betrokken bij het installeren van Jupyter en het maken van verbinding met Apache Spark in HDInsight.
- Spark-cluster configureren.
- Installeer Jupyter Notebook.
- Installeer de PySpark- en Spark-kernels met de Spark-magic.
- Spark-magic configureren voor toegang tot Spark-cluster in HDInsight.
Zie Kernels die beschikbaar zijn voor Jupyter Notebooks met Apache Spark Linux-clusters in HDInsightvoor meer informatie over aangepaste kernels en Spark-magic.
Vereiste voorwaarden
Een Apache Spark-cluster in HDInsight. Zie Apache Spark-clusters maken in Azure HDInsight voor instructies. Het lokale notebook maakt verbinding met het HDInsight-cluster.
Vertrouwd zijn met het gebruik van Jupyter Notebooks met Spark op HDInsight.
Jupyter Notebook installeren op uw computer
Installeer Python voordat u Jupyter Notebooks installeert. De Anaconda-distributie installeert zowel Python als Jupyter Notebook.
Download het Anaconda-installatieprogramma voor uw platform en voer de installatie uit. Zorg er tijdens het uitvoeren van de installatiewizard voor dat u de optie selecteert om Anaconda toe te voegen aan uw PATH-variabele. Zie ook Jupyter installeren met anaconda.
Spark-magic installeren
Voer de opdracht
pip install sparkmagic==0.13.1om Spark Magic te installeren voor HDInsight-clusters versie 3.6 en 4.0. Zie ook sparkmagic-documentatie.Zorg ervoor dat
ipywidgetsjuist is geïnstalleerd door de volgende opdracht uit te voeren:jupyter nbextension enable --py --sys-prefix widgetsnbextension
PySpark- en Spark-kernels installeren
Bepaal waar
sparkmagicis geïnstalleerd door de volgende opdracht in te voeren:pip show sparkmagicVerplaats vervolgens uw werkmap naar de locatie die met de bovenstaande opdracht is geïdentificeerd.
Voer in de nieuwe werkmap een of meer van de onderstaande opdrachten in om de gewenste kernel(s) te installeren:
Kern Opdracht Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelFacultatief. Voer de onderstaande opdracht in om de serverextensie in te schakelen:
jupyter serverextension enable --py sparkmagic
Spark-magic configureren om verbinding te maken met HDInsight Spark-cluster
In deze sectie configureert u de Spark-magic die u eerder hebt geïnstalleerd om verbinding te maken met een Apache Spark-cluster.
Start de Python-shell met de volgende opdracht:
pythonDe Configuratiegegevens van Jupyter worden doorgaans opgeslagen in de basismap van gebruikers. Voer de volgende opdracht in om de basismap te identificeren en maak een map met de naam .sparkmagic. Het volledige pad zal worden weergegeven.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()Maak in de map
.sparkmagiceen bestand met de naam config.json en voeg daarin het volgende JSON-fragment toe.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Breng de volgende wijzigingen aan in het bestand:
Sjabloonwaarde Nieuwe waarde {USERNAME} Clusteraanmelding, de standaardwaarde is admin.{CLUSTERDNSNAME} Clusternaam {BASE64ENCODEDPASSWORD} Een base64-gecodeerd wachtwoord voor uw werkelijke wachtwoord. U kunt een base64-wachtwoord genereren op https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Blijf bij het gebruik van sparkmagic 0.12.7(clusters v3.5 en v3.6). Als usparkmagic 0.2.3(clusters v3.4) gebruikt, vervangt u deze door"should_heartbeat": true.U ziet een volledig voorbeeldbestand op voorbeeldbestand config.json.
Hint
Heartbeats worden verzonden om ervoor te zorgen dat sessies niet worden gelekt. Wanneer een computer in slaapstand gaat of wordt afgesloten, wordt de heartbeat niet verzonden, waardoor de sessie wordt beëindigd. Als u dit gedrag wilt uitschakelen voor clusters v3.4, kunt u de Livy-configuratie instellen
livy.server.interactive.heartbeat.timeoutop0vanuit de Ambari-gebruikersinterface. Als u voor clusters v3.5 de bovenstaande 3.5-configuratie niet instelt, wordt de sessie niet verwijderd.Start Jupyter. Gebruik de volgende opdracht vanaf de opdrachtprompt.
jupyter notebookControleer of u de Spark-magic kunt gebruiken die beschikbaar is voor de kernels. Voltooi de volgende stappen.
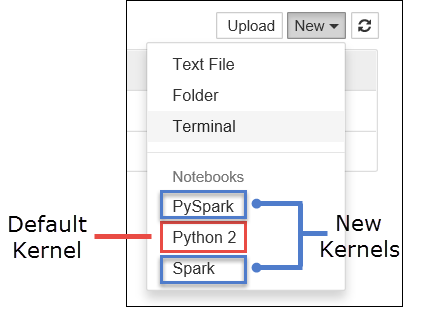
a. Maak een nieuw notitieblok. Selecteer vanuit de rechterhoek Nieuw. U ziet nu de standaardkernel Python 2 of Python 3 en de kernels die u hebt geïnstalleerd. De werkelijke waarden kunnen variëren, afhankelijk van uw installatieopties. Selecteer PySpark-.
Belangrijk
Nadat u Nieuwe hebt geselecteerd, controleert u de shell op eventuele fouten. Als u fout
TypeError: __init__() got an unexpected keyword argument 'io_loop'ziet, hebt u mogelijk te maken met een bekend probleem in bepaalde versies van Tornado. Zo ja, stop de kernel en downgrade vervolgens uw Tornado-installatie met de volgende opdracht:pip install tornado==4.5.3.b. Voer het volgende codefragment uit.
%%sql SELECT * FROM hivesampletable LIMIT 5Als u de uitvoer kunt ophalen, wordt de verbinding met het HDInsight-cluster getest.
Als u de notebookconfiguratie wilt bijwerken om verbinding te maken met een ander cluster, werkt u de config.json bij met de nieuwe set waarden, zoals wordt weergegeven in stap 3 hierboven.
Waarom moet ik Jupyter installeren op mijn computer?
Redenen om Jupyter op uw computer te installeren en deze vervolgens te verbinden met een Apache Spark-cluster in HDInsight:
- Biedt u de mogelijkheid om uw notebooks lokaal te maken, uw toepassing te testen op een actief cluster en vervolgens de notebooks naar het cluster te uploaden. Als u de notebooks wilt uploaden naar het cluster, kunt u ze uploaden met behulp van het Jupyter Notebook dat wordt uitgevoerd of het cluster, of deze opslaan in de map
/HdiNotebooksin het opslagaccount dat is gekoppeld aan het cluster. Zie Waar worden Jupyter Notebooks opgeslagenvoor meer informatie over hoe notebooks worden opgeslagen in het cluster? - Als de notebooks lokaal beschikbaar zijn, kunt u verbinding maken met verschillende Spark-clusters op basis van uw toepassingsvereiste.
- U kunt GitHub gebruiken om een broncodebeheersysteem te implementeren en versiebeheer voor de notebooks te hebben. U kunt ook een samenwerkingsomgeving hebben waarin meerdere gebruikers met hetzelfde notitieblok kunnen werken.
- U kunt lokaal met notebooks werken zonder dat u een cluster hebt. U hebt alleen een cluster nodig om uw notebooks te testen, niet om uw notebooks of een ontwikkelomgeving handmatig te beheren.
- Het kan eenvoudiger zijn om uw eigen lokale ontwikkelomgeving te configureren dan het configureren van de Jupyter-installatie op het cluster. U kunt profiteren van alle software die u lokaal hebt geïnstalleerd zonder een of meer externe clusters te configureren.
Waarschuwing
Als Jupyter is geïnstalleerd op uw lokale computer, kunnen meerdere gebruikers hetzelfde notebook tegelijkertijd op hetzelfde Spark-cluster uitvoeren. In een dergelijke situatie worden meerdere Livy-sessies gemaakt. Als u een probleem tegenkomt en dat wilt opsporen, is het een complexe taak om bij te houden welke Livy-sessie bij welke gebruiker hoort.