Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
HDInsight Spark-clusters bieden kernels die u kunt gebruiken met Jupyter Notebook in Apache Spark voor het testen van uw toepassingen. Een kernel is een programma dat uw code uitvoert en interpreteert. De drie kernels zijn:
- PySpark : voor toepassingen die zijn geschreven in Python2. (Alleen van toepassing op Spark 2.4-versieclusters)
- PySpark3 : voor toepassingen die zijn geschreven in Python3.
- Spark : voor toepassingen die zijn geschreven in Scala.
In dit artikel leert u hoe u deze kernels en de voordelen van het gebruik ervan kunt gebruiken.
Vereisten
Een Apache Spark-cluster in HDInsight. Zie Apache Spark-clusters maken in Azure HDInsight voor instructies.
Een Jupyter-notebook maken in Spark HDInsight
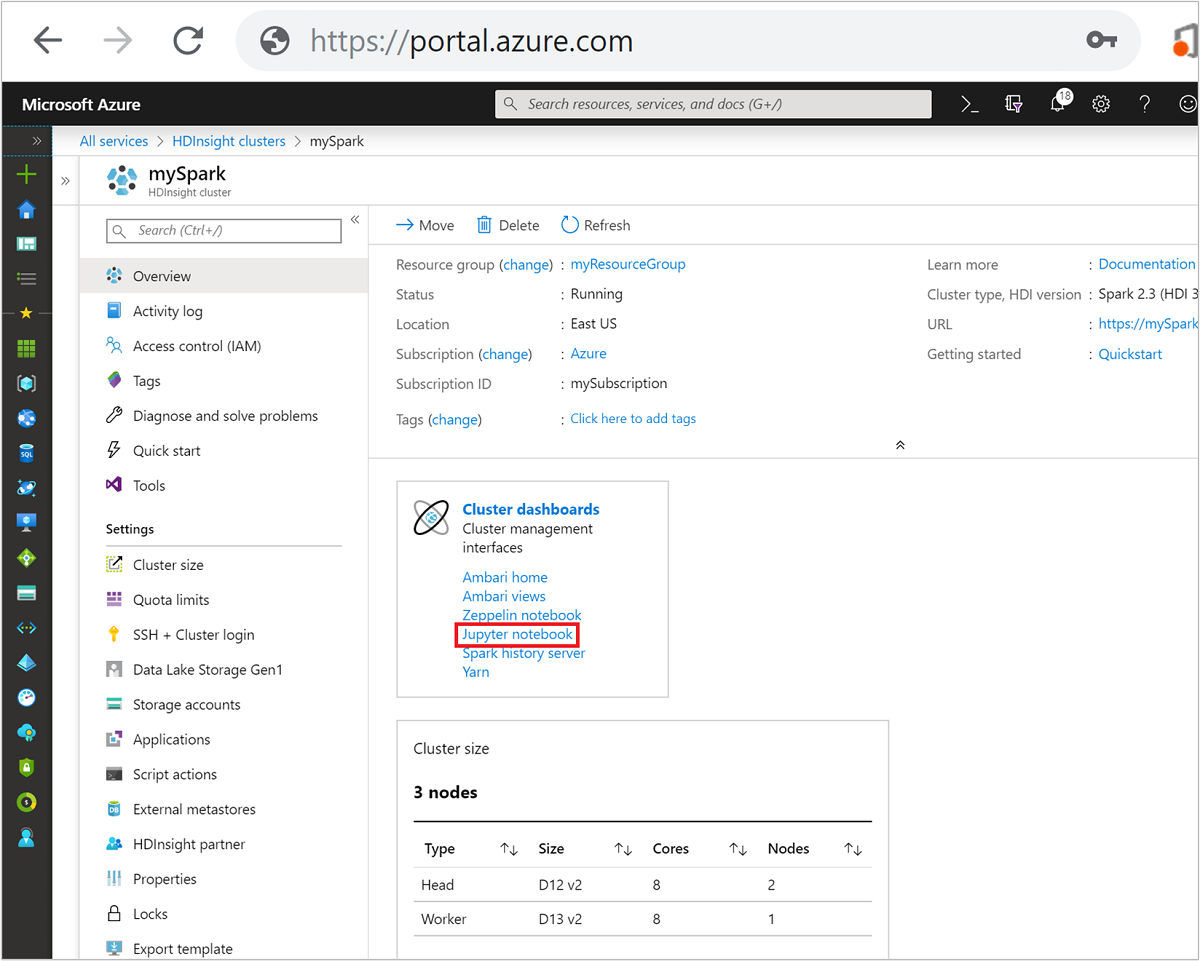
Selecteer uw Spark-cluster in Azure Portal. Zie Lijst en clusters weergeven voor de instructies. De weergave Overzicht wordt geopend.
Selecteer Jupyter Notebook in de weergave Overzicht in het vak Clusterdashboards. Voer de beheerdersreferenties voor het cluster in als u daarom wordt gevraagd.
Notitie
U kunt ook het Jupyter Notebook in Spark-cluster bereiken door de volgende URL in uw browser te openen. Vervang CLUSTERNAME door de naam van uw cluster.
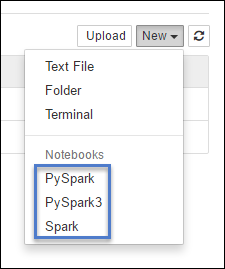
https://CLUSTERNAME.azurehdinsight.net/jupyterSelecteer Nieuw en selecteer vervolgens Pyspark, PySpark3 of Spark om een notebook te maken. Gebruik de Spark-kernel voor Scala-toepassingen, PySpark-kernel voor Python2-toepassingen en PySpark3-kernel voor Python3-toepassingen.
Notitie
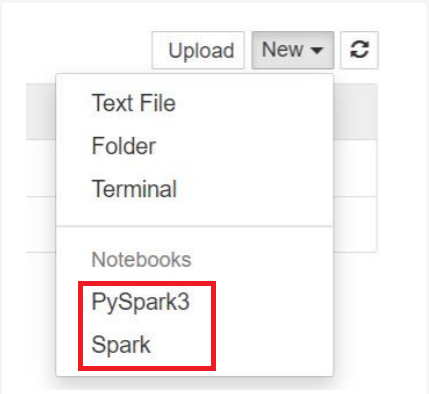
Voor Spark 3.1 is alleen PySpark3 of Spark beschikbaar.
- Er wordt een notebook geopend met de kernel die u hebt geselecteerd.
Voordelen van het gebruik van de kernels
Hier volgen enkele voordelen van het gebruik van de nieuwe kernels met Jupyter Notebook in Spark HDInsight-clusters.
Vooraf ingestelde contexten. Met PySpark, PySpark3 of de Spark-kernels hoeft u de Spark- of Hive-contexten niet expliciet in te stellen voordat u met uw toepassingen aan de slag gaat. Deze contexten zijn standaard beschikbaar. Het betreft deze contexten:
sc - voor Spark-context
sqlContext : voor Hive-context
U hoeft dus geen instructies zoals het volgende uit te voeren om de contexten in te stellen:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)In plaats daarvan kunt u de vooraf ingestelde contexten in uw toepassing rechtstreeks gebruiken.
Celmagieën. De PySpark-kernel biedt een aantal vooraf gedefinieerde 'magics', die speciale opdrachten zijn waarmee u kunt aanroepen
%%(bijvoorbeeld%%MAGIC<args>). De magic-opdracht moet het eerste woord in een codecel zijn en meerdere regels inhoud toestaan. Het magische woord moet het eerste woord in de cel zijn. Het toevoegen van iets voor de magie, zelfs opmerkingen, veroorzaakt een fout. Voor meer informatie over magie, zie hier.De volgende tabel bevat de verschillende magics die beschikbaar zijn via de kernels.
Magie Voorbeeld Beschrijving help %%helpHiermee wordt een tabel gegenereerd met alle beschikbare magics met voorbeeld en beschrijving Info %%infoGeeft sessie-informatie voor het huidige Livy-eindpunt weer configureren %%configure -f
{"executorMemory": "1000M",
"executorCores": 4}Hiermee configureert u de parameters voor het maken van een sessie. De force-flag ( -f) is verplicht als er al een sessie is gemaakt, zodat de sessie wordt beëindigd en opnieuw gecreëerd. Bekijk de POST/sessions Request Body van Livy voor een lijst met geldige parameters. Parameters moeten worden doorgegeven als een JSON-tekenreeks en moeten zich op de volgende regel na de magie bevinden, zoals wordt weergegeven in de voorbeeldkolom.sql %%sql -o <variable name>
SHOW TABLESVoert een Hive-query uit op sqlContext. Als de -oparameter wordt doorgegeven, wordt het resultaat van de query behouden in de context van %%local Python als een Pandas-dataframe .lokaal %%locala=1Alle code in latere regels wordt lokaal uitgevoerd. Code moet geldige Python2-code zijn, ongeacht welke kernel u gebruikt. Dus zelfs als u PySpark3- of Spark-kernels hebt geselecteerd tijdens het maken van het notebook, moet die cel alleen geldige Python2-code hebben als u de %%localmagie in een cel gebruikt.logboeken %%logsDe logs voor de huidige Livy-sessie worden weergegeven. verwijderen %%delete -f -s <session number>Hiermee verwijdert u een specifieke sessie van het huidige Livy-eindpunt. U kunt de sessie die is gestart voor de kernel zelf niet verwijderen. opruimen %%cleanup -fHiermee verwijdert u alle sessies voor het huidige Livy-eindpunt, inclusief de sessie van dit notitieblok. De forcevlag -f is verplicht. Notitie
Naast de magie die is toegevoegd door de PySpark-kernel, kunt u ook de ingebouwde IPython-magics gebruiken, waaronder
%%sh. U kunt de%%shmagie gebruiken om scripts en codeblokken uit te voeren op het hoofdknooppunt van het cluster.Automatische visualisatie. De Pyspark-kernel visualiseert automatisch de uitvoer van Hive- en SQL-query's. U kunt kiezen uit verschillende typen visualisaties, waaronder Tabel, Cirkel, Lijn, Gebied, Balk.
Parameters die worden ondersteund met %%sql magic
De %%sql magic ondersteunt verschillende parameters die u kunt gebruiken om het type uitvoer te bepalen dat u ontvangt wanneer u query's uitvoert. De volgende tabel bevat de uitvoer.
| Parameter | Voorbeeld | Beschrijving |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Gebruik deze parameter om het resultaat van de query als een Pandas-gegevensframe in de %%locale Python-context te behouden. De naam van de dataframevariabele is de naam van de variabele die u opgeeft. |
| -q | -q |
Gebruik deze parameter om visualisaties voor de cel uit te schakelen. Als u de inhoud van een cel niet automatisch wilt visualiseren en deze alleen wilt vastleggen als een gegevensframe, gebruikt u -q -o <VARIABLE>. Als u visualisaties wilt uitschakelen zonder de resultaten vast te leggen (bijvoorbeeld voor het uitvoeren van een SQL-query, zoals een CREATE TABLE instructie), gebruikt -q u deze zonder een -o argument op te geven. |
| -m | -m <METHOD> |
Waarbij METHOD wordt genomen of voorbeeld (standaard wordt genomen). Als de methode take is, kiest de kernel elementen uit de bovenste rijen van de resultatenset die is opgegeven door MAXROWS (verderop in deze tabel beschreven). Als de methode sample is, selecteert de kernel willekeurig elementen van de gegevensset volgens de parameter, zoals in de volgende tabel wordt beschreven. |
| -r | -r <FRACTION> |
Hier is FRACTION een drijvendekommagetal tussen 0,0 en 1,0. Als de voorbeeldmethode voor de SQL-query is sample, steekt de kernel willekeurig het opgegeven deel van de elementen van de resultatenset voor u uit. Als u bijvoorbeeld een SQL-query met de argumenten -m sample -r 0.01uitvoert, worden 1% van de resultaatrijen willekeurig gesampleerd. |
| -n | -n <MAXROWS> |
MAXROWS is een geheel getal. De kernel beperkt het aantal uitvoerrijen tot MAXROWS. Als MAXROWS een negatief getal is, zoals -1, is het aantal rijen in de resultatenset niet beperkt. |
Voorbeeld:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
De bovenstaande uitspraak voert de volgende acties uit:
- Hiermee selecteert u alle records uit hivesampletable.
- Omdat we -q gebruiken, wordt automatischvisualisatie uitgeschakeld.
- Omdat we gebruiken
-m sample -r 0.1 -n 500, wordt willekeurig 10% van de rijen in het hivesampletable gesamplet en wordt de grootte van de resultatenset beperkt tot 500 rijen. - Ten slotte, omdat we deze ook hebben gebruikt
-o query2, wordt de uitvoer opgeslagen in een dataframe met de naam query2.
Overwegingen bij het gebruik van de nieuwe kernels
Welke kernel u ook gebruikt, notebooks die blijven draaien verbruiken de clusterbronnen. Met deze kernels, omdat de contexten vooraf zijn ingesteld, wordt de context niet gedood door de notebooks af te sluiten. En dus blijven de clusterbronnen in gebruik. Een goede gewoonte is om de optie Sluiten en stoppen te gebruiken in het menu Bestand van het notitieblok wanneer u klaar bent met het notitieblok. De sluiting beëindigt de context en sluit vervolgens het notitieblok af.
Waar worden de notebooks opgeslagen?
Als uw cluster Gebruikmaakt van Azure Storage als het standaardopslagaccount, worden Jupyter Notebooks opgeslagen in het opslagaccount onder de map /HdiNotebooks . Notebooks, tekstbestanden en mappen die u vanuit Jupyter maakt, zijn toegankelijk vanuit het opslagaccount. Als u bijvoorbeeld Jupyter gebruikt om een map myfolder en een notebook myfolder/mynotebook.ipynb te maken, kunt u via het opslagaccount toegang krijgen tot dat notitieblok in /HdiNotebooks/myfolder/mynotebook.ipynb. Het omgekeerde is ook waar, dus als u een notebook rechtstreeks uploadt naar uw opslagaccount op /HdiNotebooks/mynotebook1.ipynb, is het notebook ook zichtbaar vanuit Jupyter. Notebooks blijven in het opslagaccount, zelfs nadat het cluster is verwijderd.
Notitie
HDInsight-clusters met Azure Data Lake Storage als standaardopslag slaan geen notebooks op in de gekoppelde opslag.
De manier waarop notebooks worden opgeslagen in het opslagaccount, is compatibel met Apache Hadoop HDFS. Als u SSH in het cluster gebruikt, kunt u de opdrachten voor bestandsbeheer gebruiken:
| Opdracht | Beschrijving |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Vermeld alles in de hoofdmap : alles in deze map is zichtbaar voor Jupyter vanaf de startpagina |
hdfs dfs –copyToLocal /HdiNotebooks |
# De inhoud van de map HdiNotebooks downloaden |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Upload een notebook example.ipynb naar de hoofdmap, zodat deze zichtbaar is vanuit Jupyter |
Of het cluster nu Gebruikmaakt van Azure Storage of Azure Data Lake Storage als het standaardopslagaccount, de notebooks worden ook opgeslagen op het hoofdknooppunt van het cluster op /var/lib/jupyter.
Ondersteunde browser
Jupyter Notebooks in Spark HDInsight-clusters worden alleen ondersteund in Google Chrome.
Suggesties
De nieuwe kernels zijn in ontwikkeling en worden na verloop van tijd volwassen. De API's kunnen dus veranderen naarmate deze kernels volwassen worden. We waarderen alle feedback die u hebt tijdens het gebruik van deze nieuwe kernels. De feedback is nuttig bij het vormgeven van de definitieve release van deze kernels. U kunt uw opmerkingen/feedback onder aan dit artikel achterlaten in de sectie Feedback .