Externe pakketten gebruiken met Jupyter Notebooks in Apache Spark-clusters in HDInsight
Meer informatie over het configureren van een Jupyter Notebook in Een Apache Spark-cluster in HDInsight voor het gebruik van externe, door de community bijgedragen Apache Maven-pakketten die niet standaard in het cluster zijn opgenomen.
U kunt in de Maven-opslagplaats zoeken naar de volledige lijst met beschikbare pakketten. U kunt ook een lijst met beschikbare pakketten ophalen uit andere bronnen. Er is bijvoorbeeld een volledige lijst met door de community bijgedragen pakketten beschikbaar op Spark-pakketten.
In dit artikel leert u hoe u het spark-CSV-pakket gebruikt met de Jupyter Notebook.
Vereisten
Een Apache Spark-cluster in HDInsight. Zie Apache Spark-clusters maken in Azure HDInsight voor instructies.
Weten hoe u Jupyter Notebooks gebruikt met Apache Spark on HDInsight. Zie Zelfstudie: Gegevens laden en query's uitvoeren in een Apache Spark-cluster in Azure HDInsight voor meer informatie.
Het URI-schema voor de primaire opslag voor uw clusters. Dit is
wasb://voor Azure Storage,abfs://voor Azure Data Lake Storage Gen2. Als beveiligde overdracht is ingeschakeld voor Azure Storage of Data Lake Storage Gen2, iswasbs://abfss://de URI respectievelijk ook veilige overdracht.
Externe pakketten gebruiken met Jupyter Notebooks
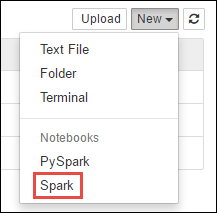
Navigeer naar
https://CLUSTERNAME.azurehdinsight.net/jupyterde locatie vanCLUSTERNAMEuw Spark-cluster.Maak een nieuwe notebook. Selecteer Nieuw en selecteer Vervolgens Spark.
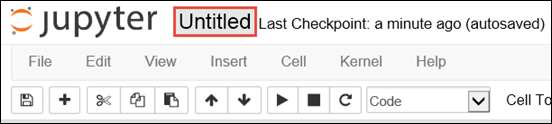
Er wordt een nieuwe notebook gemaakt en geopend met de naam Untitled.pynb. Selecteer de naam van het notitieblok bovenaan en voer een beschrijvende naam in.
U gebruikt de
%%configuremagic om het notebook te configureren voor het gebruik van een extern pakket. Zorg ervoor dat u de magie in de%%configureeerste codecel aanroept in notebooks die gebruikmaken van externe pakketten. Dit zorgt ervoor dat de kernel is geconfigureerd voor het gebruik van het pakket voordat de sessie wordt gestart.Belangrijk
Als u vergeet de kernel in de eerste cel te configureren, kunt u de
%%configureparameter-fgebruiken, maar die start de sessie opnieuw op en alle voortgang gaat verloren.HDInsight-versie Opdracht Voor HDInsight 3.5 en HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Voor HDInsight 3.3 en HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }In het bovenstaande fragment worden de maven-coördinaten voor het externe pakket in de centrale Opslagplaats van Maven verwacht. In dit fragment
com.databricks:spark-csv_2.11:1.5.0is de maven-coördinaat voor spark-csv-pakket . U maakt als volgt de coördinaten voor een pakket.a. Zoek het pakket in de Maven-opslagplaats. Voor dit artikel gebruiken we spark-csv.
b. Verzamel in de opslagplaats de waarden voor GroupId, ArtifactId en Version. Zorg ervoor dat de waarden die u verzamelt overeenkomen met uw cluster. In dit geval gebruiken we een Scala 2.11- en Spark 1.5.0-pakket, maar mogelijk moet u verschillende versies selecteren voor de juiste Scala- of Spark-versie in uw cluster. U vindt de Scala-versie op uw cluster door uit te voeren
scala.util.Properties.versionStringop de Spark Jupyter-kernel of op Spark submit. U vindt de Spark-versie op uw cluster door uit te voerensc.versionop Jupyter Notebooks.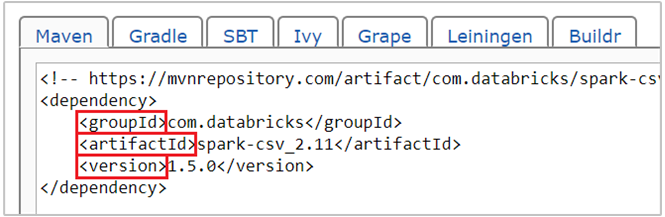
c. Voeg de drie waarden samen, gescheiden door een dubbele punt (:).
com.databricks:spark-csv_2.11:1.5.0Voer de codecel uit met de
%%configuremagie. Hiermee configureert u de onderliggende Livy-sessie voor het gebruik van het pakket dat u hebt opgegeven. In de volgende cellen in het notebook kunt u nu het pakket gebruiken, zoals hieronder wordt weergegeven.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Voor HDInsight 3.4 en lager moet u het volgende codefragment gebruiken.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Vervolgens kunt u de fragmenten uitvoeren, zoals hieronder wordt weergegeven, om de gegevens te bekijken uit het dataframe dat u in de vorige stap hebt gemaakt.
df.show() df.select("Time").count()
Zie ook
Scenario's
- Apache Spark met BI: Interactieve gegevensanalyse uitvoeren met Spark in HDInsight met BI-hulpprogramma's
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken voor het analyseren van de gebouwtemperatuur met behulp van HVAC-gegevens
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken om resultaten van voedselinspectie te voorspellen
- Analyse van websitelogboeken met Apache Spark in HDInsight
Toepassingen maken en uitvoeren
- Een zelfstandige toepassing maken met behulp van Scala
- Apache Livy gebruiken om taken op afstand uit te voeren in een Apache Spark-cluster
Tools en uitbreidingen
- Externe Python-pakketten gebruiken met Jupyter Notebooks in Apache Spark-clusters in HDInsight Linux
- De invoegtoepassing HDInsight Tools for IntelliJ IDEA gebruiken om Spark Scala-toepassingen te maken en in te dienen
- De invoegtoepassing HDInsight Tools voor IntelliJ IDEA gebruiken om op afstand fouten in Apache Spark-toepassingen op te sporen
- Apache Zeppelin-notebooks gebruiken met een Apache Spark-cluster in HDInsight
- Kernels beschikbaar voor Jupyter Notebook in Apache Spark-cluster voor HDInsight
- Jupyter op uw computer installeren en verbinding maken met een HDInsight Spark-cluster